19.Linux系统总结(2)
查找文件
locate
搜索包含关键字的所有文件和目录。后接需要查找的文件名,也可以用正则表达式。
安装 locate
yum -y install mlocate --> 安装包
updatedb --> 更新数据库
[注意] locate 命令会去文件数据库中查找命令,而不是全磁盘查找,因此刚创建的文件并不会更新到数据库中,所以无法被查找到,可以执行 updatedb 命令去更新数据库。
find
用于查找文件,它会去遍历你的实际硬盘进行查找,而且它允许我们对每个找到的文件进行后续操作,功能非常强大。
find <何处> <何物> <做什么>
- 何处:指定在哪个目录查找,此目录的所有子目录也会被查找。
- 何物:查找什么,可以根据文件的名字来查找,也可以根据其大小来查找,还可以根据其最近访问时间来查找。
- 做什么:找到文件后,可以进行后续处理,如果不指定这个参数,
find命令只会显示找到的文件。
根据文件名查找
find -name "file.txt" --> 当前目录以及子目录下通过名称查找文件
find . -name "syslog" --> 当前目录以及子目录下通过名称查找文件
find / -name "syslog" --> 整个硬盘下查找syslog
find /var/log -name "syslog" --> 在指定的目录/var/log下查找syslog文件
find /var/log -name "syslog*" --> 查找syslog1、syslog2 ... 等文件,通配符表示所有
find /var/log -name "*syslog*" --> 查找包含syslog的文件
[注意] find 命令只会查找完全符合 “何物” 字符串的文件,而 locate 会查找所有包含关键字的文件。
根据文件大小查找
find /var -size +10M --> /var 目录下查找文件大小超过 10M 的文件
find /var -size -50k --> /var 目录下查找文件大小小于 50k 的文件
find /var -size +1G --> /var 目录下查找文件大小查过 1G 的文件
find /var -size 1M --> /var 目录下查找文件大小等于 1M 的文件
根据文件最近访问时间查找
find -name "*.txt" -atime -7 --> 近 7天内访问过的.txt结尾的文件
仅查找目录或文件
find . -name "file" -type f --> 只查找当前目录下的file文件
find . -name "file" -type d --> 只查找当前目录下的file目录
操作查找结果
find -name "*.txt" -printf "%p - %u\n" --> 找出所有后缀为txt的文件,并按照 %p - %u\n 格式打印,其中%p=文件名,%u=文件所有者
find -name "*.jpg" -delete --> 删除当前目录以及子目录下所有.jpg为后缀的文件,不会有删除提示,因此要慎用
find -name "*.c" -exec chmod 600 {} \; --> 对每个.c结尾的文件,都进行 -exec 参数指定的操作,{} 会被查找到的文件替代,\; 是必须的结尾
find -name "*.c" -ok chmod 600 {} \; --> 和上面的功能一直,会多一个确认提示
软件仓库
Linux 下软件是以包的形式存在,一个软件包其实就是软件的所有文件的压缩包,是二进制的形式,包含了安装软件的所有指令。Red Hat 家族的软件包后缀名一般为 .rpm , Debian 家族的软件包后缀是 .deb 。
Linux 的包都存在一个仓库,叫做软件仓库,它可以使用 yum 来管理软件包, yum 是 CentOS 中默认的包管理工具,适用于 Red Hat 一族。可以理解成 Node.js 的 npm 。
yum 常用命令
yum update | yum upgrade更新软件包yum search xxx搜索相应的软件包yum install xxx安装软件包yum remove xxx删除软件包
切换 CentOS 软件源
有时候 CentOS 默认的 yum 源不一定是国内镜像,导致 yum 在线安装及更新速度不是很理想。这时候需要将 yum 源设置为国内镜像站点。国内主要开源的镜像站点是网易和阿里云。
1、首先备份系统自带 yum 源配置文件 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2、下载阿里云的 yum 源配置文件到 /etc/yum.repos.d/CentOS7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3、生成缓存
yum makecache
阅读手册
Linux 命令种类繁杂,我们凭借记忆不可能全部记住,因此学会查用手册是非常重要的。
man
安装更新 man
sudo yum install -y man-pages --> 安装sudo mandb --> 更新
man 手册种类
- 可执行程序或
Shell命令; - 系统调用(
Linux内核提供的函数); - 库调用(程序库中的函数);
- 文件(例如
/etc/passwd); - 特殊文件(通常在
/dev下); - 游戏;
- 杂项(
man(7),groff(7)); - 系统管理命令(通常只能被
root用户使用); - 内核子程序。
man + 数字 + 命令
输入 man + 数字 + 命令 / 函数,可以查到相关的命令和函数,若不加数字, man 默认从数字较小的手册中寻找相关命令和函数
man 3 rand --> 表示在手册的第三部分查找 rand 函数man ls --> 查找 ls 用法手册
man 手册核心区域解析:(以 man pwd 为例)
NAME # 命令名称和简单描述 pwd -- return working directory name
SYNOPSIS # 使用此命令的所有方法 pwd [-L | -P]
DESCRIPTION # 包括所有参数以及用法 The pwd utility writes the absolute pathname of the current working directory to the standard output.
Some shells may provide a builtin pwd command which is similar or identical to this utility. Consult the builtin(1) manual page.
The options are as follows:
-L Display the logical current working directory.
-P Display the physical current working directory (all symbolic links resolved).
If no options are specified, the -L option is assumed.
SEE ALSO # 扩展阅读相关命令 builtin(1), cd(1), csh(1), sh(1), getcwd(3)
help
man命令像新华词典一样可以查询到命令或函数的详细信息,但其实我们还有更加快捷的方式去查询,command --help或command -h,它没有man命令显示的那么详细,但是它更加易于阅读。
Linux 进阶
文本操作
grep
全局搜索一个正则表达式,并且打印到屏幕。简单来说就是,在文件中查找关键字,并显示关键字所在行。
基础语法
grep text file # text代表要搜索的文本,file代表供搜索的文件
# 实例
[root@lion ~]# grep path /etc/profile
pathmunge () {pathmunge /usr/sbinpathmunge /usr/local/sbinpathmunge /usr/local/sbin afterpathmunge /usr/sbin after
unset -f pathmunge
常用参数
-i忽略大小写,grep -i path /etc/profile-n显示行号,grep -n path /etc/profile-v只显示搜索文本不在的那些行,grep -v path /etc/profile-r递归查找,grep -r hello /etc,Linux 中还有一个 rgrep 命令,作用相当于grep -r
高级用法
grep 可以配合正则表达式使用。
grep -E path /etc/profile --> 完全匹配path
grep -E ^path /etc/profile --> 匹配path开头的字符串
grep -E [Pp]ath /etc/profile --> 匹配path或Path
sort
对文件的行进行排序。
基础语法
sort name.txt # 对name.txt文件进行排序
实例用法
为了演示方便,我们首先创建一个文件 name.txt ,放入以下内容:
Christopher
Shawn
Ted
Rock
Noah
Zachary
Bella
执行 sort name.txt 命令,会对文本内容进行排序。
常用参数
-o将排序后的文件写入新文件,sort -o name_sorted.txt name.txt;-r倒序排序,sort -r name.txt;-R随机排序,sort -R name.txt;-n对数字进行排序,默认是把数字识别成字符串的,因此 138 会排在 25 前面,如果添加了-n数字排序的话,则 25 会在 138 前面。
wc
word count 的缩写,用于文件的统计。它可以统计单词数目、行数、字符数,字节数等。
基础语法
wc name.txt # 统计name.txt
实例用法
[root@lion ~]# wc name.txt 13 13 91 name.txt
- 第一个 13,表示行数;
- 第二个 13,表示单词数;
- 第三个 91,表示字节数。
常用参数
-l只统计行数,wc -l name.txt;-w只统计单词数,wc -w name.txt;-c只统计字节数,wc -c name.txt;-m只统计字符数,wc -m name.txt。
uniq
删除文件中的重复内容。
基础语法
uniq name.txt # 去除name.txt重复的行数,并打印到屏幕上
uniq name.txt uniq_name.txt # 把去除重复后的文件保存为 uniq_name.txt
【注意】它只能去除连续重复的行数。
常用参数
-c统计重复行数,uniq -c name.txt;-d只显示重复的行数,uniq -d name.txt。
cut
剪切文件的一部分内容。
基础语法
cut -c 2-4 name.txt # 剪切每一行第二到第四个字符
常用参数
-d用于指定用什么分隔符(比如逗号、分号、双引号等等)cut -d , name.txt;-f表示剪切下用分隔符分割的哪一块或哪几块区域,cut -d , -f 1 name.txt。
重定向 管道 流
在 Linux 中一个命令的去向可以有 3 个地方:终端、文件、作为另外一个命令的入参。
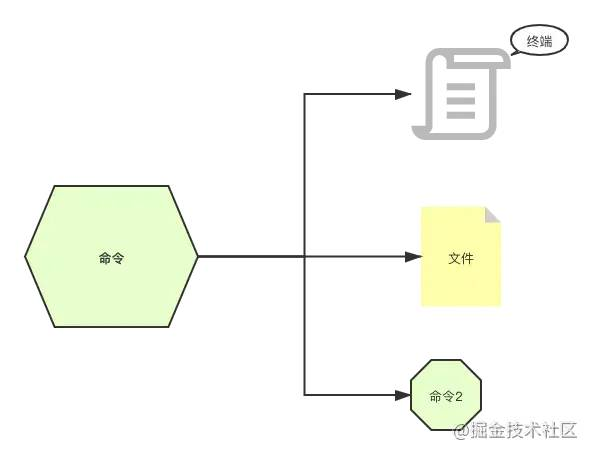
命令一般都是通过键盘输入,然后输出到终端、文件等地方,它的标准用语是 stdin 、 stdout 以及 stderr 。
- 标准输入
stdin,终端接收键盘输入的命令,会产生两种输出; - 标准输出
stdout,终端输出的信息(不包含错误信息); - 标准错误输出
stderr,终端输出的错误信息。
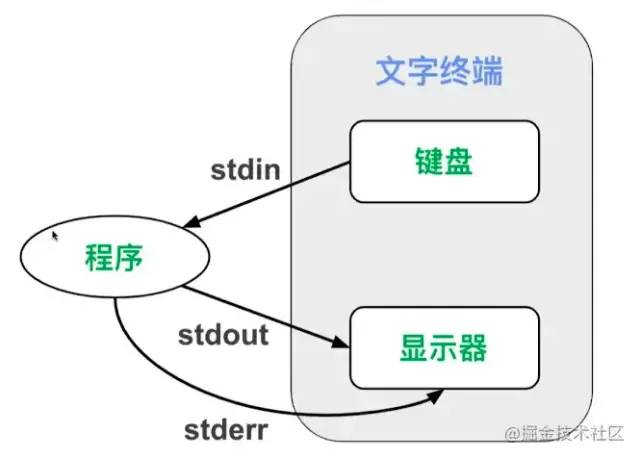
重定向
把本来要显示在终端的命令结果,输送到别的地方(到文件中或者作为其他命令的输入)。
输出重定向 >
> 表示重定向到新的文件, cut -d , -f 1 notes.csv > name.csv ,它表示通过逗号剪切 notes.csv 文件(剪切完有 3 个部分)获取第一个部分,重定向到 name.csv 文件。
我们来看一个具体示例,学习它的使用,假设我们有一个文件 notes.csv ,文件内容如下:
Mark1,951/100,很不错1Mark2,952/100,很不错2Mark3,953/100,很不错3Mark4,954/100,很不错4Mark5,955/100,很不错5Mark6,956/100,很不错6
执行命令:cut -d , -f 1 notes.csv > name.csv 最后输出如下内容:
Mark1Mark2Mark3Mark4Mark5Mark6
【注意】使用 > 要注意,如果输出的文件不存在它会新建一个,如果输出的文件已经存在,则会覆盖。因此执行这个操作要非常小心,以免覆盖其它重要文件。
输出重定向 >>
表示重定向到文件末尾,因此它不会像 > 命令这么危险,它是追加到文件的末尾(当然如果文件不存在,也会被创建)。
再次执行 cut -d , -f 1 notes.csv >> name.csv ,则会把名字追加到 name.csv 里面。
Mark1
Mark2
Mark3
Mark4
Mark5
Mark6
Mark1
Mark2
Mark3
Mark4
Mark5
Mark6
我们平时读的 log 日志文件其实都是用这个命令输出的。
输出重定向 2>
标准错误输出
cat not_exist_file.csv > res.txt 2> errors.log
- 当我们
cat一个文件时,会把文件内容打印到屏幕上,这个是标准输出; - 当使用了
> res.txt时,则不会打印到屏幕,会把标准输出写入文件res.txt文件中; 2> errors.log当发生错误时会写入errors.log文件中。
输出重定向 2>>
标准错误输出(追加到文件末尾)同 >> 相似。
输出重定向 2>&1
标准输出和标准错误输出都重定向都一个地方
cat not_exist_file.csv > res.txt 2>&1 # 覆盖输出
cat not_exist_file.csv >> res.txt 2>&1 # 追加输出
目前为止,我们接触的命令的输入都来自命令的参数,其实命令的输入还可以来自文件或者键盘的输入。
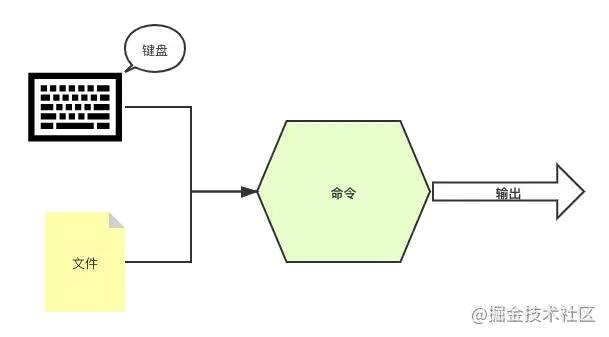
未命名文件 (2).png
输入重定向 <
< 符号用于指定命令的输入。
cat < name.csv # 、指定命令的输入为 name.csv
虽然它的运行结果与 cat name.csv 一样,但是它们的原理却完全不同。
cat name.csv表示cat命令接收的输入是notes.csv文件名,那么要先打开这个文件,然后打印出文件内容。cat < name.csv表示cat命令接收的输入直接是notes.csv这个文件的内容,cat命令只负责将其内容打印,打开文件并将文件内容传递给cat命令的工作则交给终端完成。
输入重定向 <<
将键盘的输入重定向为某个命令的输入。
sort -n << END # 输入这个命令之后,按下回车,终端就进入键盘输入模式,其中END为结束命令(这个可以自定义)
wc -m << END # 统计输入的单词
管道 |
把两个命令连起来使用,一个命令的输出作为另外一个命令的输入,英文是 pipeline ,可以想象一个个水管连接起来,管道算是重定向流的一种。

未命名文件 (1).png
举几个实际用法案例:
cut -d , -f 1 name.csv | sort > sorted_name.txt
# 第一步获取到的 name 列表,通过管道符再进行排序,最后输出到sorted_name.txt
du | sort -nr | head
# du 表示列举目录大小信息
# sort 进行排序,-n 表示按数字排序,-r 表示倒序
# head 前10行文件
grep log -Ir /var/log | cut -d : -f 1 | sort | uniq
# grep log -Ir /var/log 表示在log文件夹下搜索 /var/log 文本,-r 表示递归,-I 用于排除二进制文件
# cut -d : -f 1 表示通过冒号进行剪切,获取剪切的第一部分
# sort 进行排序
# uniq 进行去重
流
流并非一个命令,在计算机科学中,流
stream的含义是比较难理解的,记住一点即可:流就是读一点数据, 处理一点点数据。其中数据一般就是二进制格式。 上面提及的重定向或管道,就是把数据当做流去运转的。
到此我们就接触了,流、重定向、管道等
Linux高级概念及指令。其实你会发现关于流和管道在其它语言中也有广泛的应用。Angular中的模板语法中可以使用管道。Node.js中也有stream流的概念。
查看进程
在 Windows 中通过 Ctrl + Alt + Delete 快捷键查看软件进程。
w
帮助我们快速了解系统中目前有哪些用户登录着,以及他们在干什么。
[root@lion ~]# w
06:31:53 up 25 days, 9:53, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 118.31.243.53 05:56 1.00s 0.02s 0.00s w
06:31:53:表示当前时间
up 25 days, 9:53:表示系统已经正常运行了“25天9小时53分钟”
1 user:表示一个用户
load average: 0.00, 0.01, 0.05:表示系统的负载,3个值分别表示“1分钟的平均负载”,“5分钟的平均负载”,“15分钟的平均负载”
USER:表示登录的用于
TTY:登录的终端名称为pts/0
FROM:连接到服务器的ip地址
LOGIN@:登录时间
IDLE:用户有多久没有活跃了
JCPU:该终端所有相关的进程使用的 CPU 时间,每当进程结束就停止计时,开始新的进程则会重新计时
PCPU:表示 CPU 执行当前程序所消耗的时间,当前进程就是在 WHAT 列里显示的程序
WHAT:表示当下用户正运行的程序是什么,这里我运行的是 w
ps
用于显示当前系统中的进程,
ps命令显示的进程列表不会随时间而更新,是静态的,是运行ps命令那个时刻的状态或者说是一个进程快照。
基础语法
[root@lion ~]# ps
PID TTY TIME CMD
1793 pts/0 00:00:00 bash
4756 pts/0 00:00:00 ps
PID:进程号,每个进程都有唯一的进程号
TTY:进程运行所在的终端
TIME:进程运行时间
CMD:产生这个进程的程序名,如果在进程列表中看到有好几行都是同样的程序名,那么就是同样的程序产生了不止一个进程
常用参数
-ef列出所有进程;-efH以乔木状列举出所有进程;-u列出此用户运行的进程;-aux通过CPU和内存使用来过滤进程ps -aux | less;-aux --sort -pcpu按CPU使用降序排列,-aux --sort -pmem表示按内存使用降序排列;-axjf以树形结构显示进程,ps -axjf它和pstree效果类似。
top
获取进程的动态列表。
top - 07:20:07 up 25 days, 10:41, 1 user, load average: 0.30, 0.10, 0.07
Tasks: 67 total, 1 running, 66 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1882072 total, 552148 free, 101048 used, 1228876 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1594080 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
956 root 10 -10 133964 15848 10240 S 0.7 0.8 263:13.01 AliYunDun 1 root 20 0 51644 3664 2400 S 0.0 0.2 3:23.63 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd 4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
top - 07:20:07 up 25 days, 10:41, 1 user, load average: 0.30, 0.10, 0.07相当w命令的第一行的信息。- 展示的这些进程是按照使用处理器
%CPU的使用率来排序的。
kill
结束一个进程, kill + PID 。
kill 956 # 结束进程号为956的进程
kill 956 957 # 结束多个进程
kill -9 7291 # 强制结束进程
管理进程
进程状态
主要是切换进程的状态。我们先了解下
Linux下进程的五种状态:
- 状态码
R:表示正在运行的状态; - 状态码
S:表示中断(休眠中,受阻,当某个条件形成后或接受到信号时,则脱离该状态); - 状态码
D:表示不可中断(进程不响应系统异步信号,即使用 kill 命令也不能使其中断); - 状态码
Z:表示僵死(进程已终止,但进程描述符依然存在,直到父进程调用wait4()系统函数后将进程释放); - 状态码
T:表示停止(进程收到SIGSTOP、SIGSTP、SIGTIN、SIGTOU等停止信号后停止运行)。
前台进程 & 后台进程
默认情况下,用户创建的进程都是前台进程,前台进程从键盘读取数据,并把处理结果输出到显示器。例如运行
top命令,这就是一个一直运行的前台进程。
后台进程的优点是不必等待程序运行结束,就可以输入其它命令。在需要执行的命令后面添加
&符号,就表示启动一个后台进程。
&
启动后台进程,它的缺点是后台进程与终端相关联,一旦关闭终端,进程就自动结束了。
cp name.csv name-copy.csv &
nohup
使进程不受挂断(关闭终端等动作)的影响。
nohup cp name.csv name-copy.csv
nohup 命令也可以和 & 结合使用。
nohup cp name.csv name-copy.csv &
bg
使一个 “后台暂停运行” 的进程,状态改为“后台运行”。
bg %1 # 不加任何参数的情况下,bg命令会默认作用于最近的一个后台进程,如果添加参数则会作用于指定标号的进程
实际案例 1:
1. 执行 grep -r "log" / > grep_log 2>&1 命令启动一个前台进程,并且忘记添加 & 符号
2. ctrl + z 使进程状态转为后台暂停
3. 执行 bg 将命令转为后台运行
实际案例 2:
前端开发时我们经常会执行 yarn start 启动项目
此时我们执行 ctrl + z 先使其暂停
然后执行 bg 使其转为后台运行
这样当前终端就空闲出来可以干其它事情了,如果想要唤醒它就使用 fg 命令即可(后面会讲)
jobs
显示当前终端后台进程状态。
[root@lion ~]# jobs
[1]+ Stopped top
[2]- Running grep --color=auto -r "log" / > grep_log 2>&1 &
fg
fg 使进程转为前台运行,用法和 bg 命令类似。
我们用一张图来表示前后台进程切换:
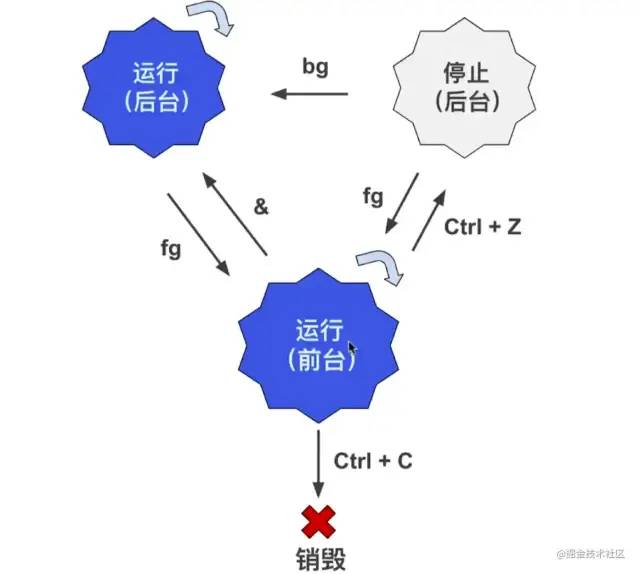
我们可以使程序在后台运行,成为后台进程,这样在当前终端中我们就可以做其他事情了,而不必等待此进程运行结束。
守护进程
一个运行起来的程序被称为进程。在 Linux 中有些进程是特殊的,它不与任何进程关联,不论用户的身份如何,都在后台运行,这些进程的父进程是 PID 为 1 的进程, PID 为 1 的进程只在系统关闭时才会被销毁。它们会在后台一直运行等待分配工作。我们将这类进程称之为守护进程 daemon 。
守护进程的名字通常会在最后有一个 d ,表示 daemon 守护的意思,例如 systemd 、httpd 。
systemd
systemd 是一个 Linux 系统基础组件的集合,提供了一个系统和服务管理器,运行为 PID 1 并负责启动其它程序。
[root@lion ~]# ps -auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.2 51648 3852 ? Ss Feb01 1:50 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
通过命令也可以看到 PID 为 1 的进程就是 systemd 的系统进程。
systemd 常用命令(它是一组命令的集合):
systemctl start nginx # 启动服务
systemctl stop nginx # 停止服务
systemctl restart nginx # 重启服务
systemctl status nginx # 查看服务状态
systemctl reload nginx # 重载配置文件(不停止服务的情况)
systemctl enable nginx # 开机自动启动服务
systemctl disable nginx # 开机不自动启动服务
systemctl is-enabled nginx # 查看服务是否开机自动启动
systemctl list-unit-files --type=service # 查看各个级别下服务的启动和禁用情况
文件压缩解压
- 打包:是将多个文件变成一个总的文件,它的学名叫存档、归档。
- 压缩:是将一个大文件(通常指归档)压缩变成一个小文件。
我们常常使用
tar将多个文件归档为一个总的文件,称为archive。然后用gzip或bzip2命令将archive压缩为更小的文件
tar
创建一个 tar 归档。
基础用法
tar -cvf sort.tar sort/ # 将sort文件夹归档为sort.tar
tar -cvf archive.tar file1 file2 file3 # 将 file1 file2 file3 归档为archive.tar
常用参数
-cvf表示create(创建)+verbose(细节)+file(文件),创建归档文件并显示操作细节;-tf显示归档里的内容,并不解开归档;-rvf追加文件到归档,tar -rvf archive.tar file.txt;-xvf解开归档,tar -xvf archive.tar。
gzip / gunzip
“压缩 / 解压” 归档,默认用 gzip 命令,压缩后的文件后缀名为 .tar.gz 。
gzip archive.tar # 压缩gunzip archive.tar.gz # 解压
tar 归档 + 压缩
可以用 tar 命令同时完成归档和压缩的操作,就是给 tar 命令多加一个选项参数,使之完成归档操作后,还是调用 gzip 或 bzip2 命令来完成压缩操作。
tar -zcvf archive.tar.gz archive/ # 将archive文件夹归档并压缩
tar -zxvf archive.tar.gz # 将archive.tar.gz归档压缩文件解压
zcat、zless、zmore
之前讲过使用 cat less more 可以查看文件内容,但是压缩文件的内容是不能使用这些命令进行查看的,而要使用 zcat、zless、zmore 进行查看。
zcat archive.tar.gz
zip/unzip
“压缩 / 解压” zip 文件( zip 压缩文件一般来自 windows 操作系统)。
命令安装
# Red Hat 一族中的安装方式
yum install zip
yum install unzip
基础用法
unzip archive.zip # 解压 .zip 文件
unzip -l archive.zip # 不解开 .zip 文件,只看其中内容
zip -r sort.zip sort/ # 将sort文件夹压缩为 sort.zip,其中-r表示递归编译安装软件
之前我们学会了使用 yum 命令进行软件安装,如果碰到 yum 仓库中没有的软件,我们就需要会更高级的软件安装 “源码编译安装”。
编译安装
简单来说,编译就是将程序的源代码转换成可执行文件的过程。大多数 Linux 的程序都是开放源码的,可以编译成适合我们的电脑和操纵系统属性的可执行文件。
基本步骤如下:
- 下载源代码
- 解压压缩包
- 配置
- 编译
- 安装
实际案例
1、下载
我们来编译安装 htop 软件,首先在它的官网下载源码:bintray.com/htop/source…[1]
下载好的源码在本机电脑上使用如下命令同步到服务器上:
scp 文件名 用户名@服务器ip:目标路径
scp ~/Desktop/htop-3.0.0.tar.gz root@121.42.11.34:.
也可以使用 wegt 进行下载:
wegt+下载地址
wegt https://bintray.com/htop/source/download_file?file_path=htop-3.0.0.tar.gz
2、解压文件
tar -zxvf htop-3.0.0.tar.gz # 解压cd htop-3.0.0 # 进入目录
3、配置
执行 ./configure ,它会分析你的电脑去确认编译所需的工具是否都已经安装了。
4、编译
执行 make 命令
5、安装
执行 make install 命令,安装完成后执行 ls /usr/local/bin/ 查看是否有 htop 命令。如果有就可以执行 htop 命令查看系统进程了。
网络
ifconfig
查看 ip 网络相关信息,如果命令不存在的话, 执行命令 yum install net-tools 安装。
[root@lion ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.31.24.78 netmask 255.255.240.0 broadcast 172.31.31.255 ether 00:16:3e:04:9c:cd txqueuelen 1000 (Ethernet) RX packets 1592318 bytes 183722250 (175.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 1539361 bytes 154044090 (146.9 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
参数解析:
eth0对应有线连接(对应你的有线网卡),就是用网线来连接的上网。eth是Ethernet的缩写,表示 “以太网”。有些电脑可能同时有好几条网线连着,例如服务器,那么除了eht0,你还会看到eth1、eth2等。lo表示本地回环(Local Loopback的缩写,对应一个虚拟网卡)可以看到它的ip地址是127.0.0.1。每台电脑都应该有这个接口,因为它对应着 “连向自己的链接”。这也是被称之为“本地回环” 的原因。所有经由这个接口发送的东西都会回到你自己的电脑。看起来好像并没有什么用,但有时为了某些缘故,我们需要连接自己。例如用来测试一个网络程序,但又不想让局域网或外网的用户查看,只能在此台主机上运行和查看所有的网络接口。例如在我们启动一个前端工程时,在浏览器输入127.0.0.1:3000启动项目就能查看到自己的web网站,并且它只有你能看到。wlan0表示无线局域网(上面案例并未展示)。
host
ip 地址和主机名的互相转换。
软件安装
yum install bind-utils
基础用法
[root@lion ~]# host github.com
baidu.com has address 13.229.188.59
[root@lion ~]# host 13.229.188.59
59.188.229.13.in-addr.arpa domain name pointer ec2-13-229-188-59.ap-southeast-1.compute.amazonaws.com.
ssh 连接远程服务器
通过非对称加密以及对称加密的方式(同 HTTPS 安全连接原理相似)连接到远端服务器。
ssh 用户@ip:port
1、ssh root@172.20.10.1:22 # 端口号可以省略不写,默认是22端口
2、输入连接密码后就可以操作远端服务器了
配置 ssh
config 文件可以配置 ssh ,方便批量管理多个 ssh 连接。
配置文件分为以下几种:
- 全局
ssh服务端的配置:/etc/ssh/sshd_config; - 全局
ssh客户端的配置:/etc/ssh/ssh_config(很少修改); - 当前用户
ssh客户端的配置:~/.ssh/config。
【服务端 config 文件的常用配置参数】
| 服务端 config 参数 | 作用 |
|---|---|
| Port | sshd 服务端口号(默认是 22) |
| PermitRootLogin | 是否允许以 root 用户身份登录(默认是可以) |
| PasswordAuthentication | 是否允许密码验证登录(默认是可以) |
| PubkeyAuthentication | 是否允许公钥验证登录(默认是可以) |
| PermitEmptyPasswords | 是否允许空密码登录(不安全,默认不可以) |
[注意] 修改完服务端配置文件需要重启服务 systemctl restart sshd
【客户端 config 文件的常用配置参数】
| 客户端 config 参数 | 作用 |
|---|---|
| Host | 别名 |
| HostName | 远程主机名(或 IP 地址) |
| Port | 连接到远程主机的端口 |
| User | 用户名 |
配置当前用户的 config :
# 创建config
vim ~/.ssh/config
# 填写一下内容
Host lion # 别名
HostName 172.x.x.x # ip 地址
Port 22 # 端口
User root # 用户
这样配置完成后,下次登录时,可以这样登录 ssh lion 会自动识别为 root 用户。
[注意] 这段配置不是在服务器上,而是你自己的机器上,它仅仅是设置了一个别名。
免密登录
ssh 登录分两种,一种是基于口令(账号密码),另外一种是基于密钥的方式。
基于口令,就是每次登录输入账号和密码,显然这样做是比较麻烦的,今天主要学习如何基于密钥实现免密登录。
基于密钥验证原理
客户机生成密钥对(公钥和私钥),把公钥上传到服务器,每次登录会与服务器的公钥进行比较,这种验证登录的方法更加安全,也被称为 “公钥验证登录”。
具体实现步骤
1、在客户机中生成密钥对(公钥和私钥) ssh-keygen(默认使用 RSA 非对称加密算法)
运行完 ssh-keygen 会在 ~/.ssh/ 目录下,生成两个文件:
id_rsa.pub:公钥id_rsa:私钥
2、把客户机的公钥传送到服务
执行 ssh-copy-id root@172.x.x.x(ssh-copy-id 它会把客户机的公钥追加到服务器 ~/.ssh/authorized_keys 的文件中)。
执行完成后,运行 ssh root@172.x.x.x 就可以实现免密登录服务器了。
配合上面设置好的别名,直接执行 ssh lion 就可以登录,是不是非常方便。
wget
可以使我们直接从终端控制台下载文件,只需要给出文件的 HTTP 或 FTP 地址。
wget [参数][URL地址]wget http://www.minjieren.com/wordpress-3.1-zh_CN.zip
wget 非常稳定,如果是由于网络原因下载失败, wget 会不断尝试,直到整个文件下载完毕。
常用参数
-c继续中断的下载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号