
让你的AI模型尽可能的靠近数据源
来源:Redislabs
作者:Pieter Cailliau、LucaAntiga
翻译:Kevin (公众号:中间件小哥)
简介
今天我们发布了一个 RedisAI 的预览版本,预集成了[tensor]werk组件。RedisAI 是一个可以服务 tensors 任务和执行深度学习任务的 Redis 模块。在这篇博客中,我们将介绍这个新模块的功能,并解释我们为什么会认为它能颠覆机器学习(ML)、深度学习(DL)的解决方案。
RedisAI 的产生有两大原因:首先,把数据迁移到执行 AI 模型的主机上成本很高,并且对实时性的体验很大的影响;其次,Serving 模型一直以来都是 AI 领域中 DevOps 的挑战。我们构建 RedisAI 的目的,是让用户可以在不搬迁Redis 多节点数据的情况下,也能很好地服务、更新并集成自己的模型。
数据位置很重要

为了证明运行机器学习、深度学习模型中数据位置的重要性,我们举一个聊天机器人的例子。聊天机器人通常使用递归神经网络模型(RNN),来解决一对一(seq2seq)用户问答场景。更高级的模型使用两个输入向量、两个输出向量,并以数字中间状态向量的方式来保存对话的上下文。模型使用用户最后的消息作为输入,中间状态代表对话的历史,而它的输出是对用户消息和新中间状态的响应。
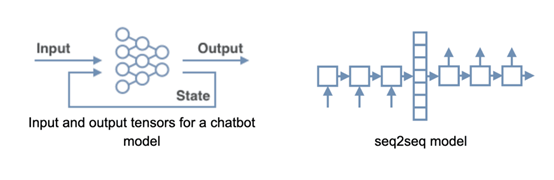
为了支持用户自定义的交互,这个中间状态必须要保存在数据库中,所以 Redis +RedisAI是一个非常好的选择,这里将传统方案和 RedisAI 方案做一个对比。
1、传统方案
使用 Flask 应用或其它方案,集成 Spark 来构建一个聊天机器人。当收到用户对话消息时,服务端需要从 Redis 中获取到中间的状态。因为在 Redis 中没有原生的数据类型可用于 tensor,因此需要先进行反序列化,并且在运行递归神经网络模型(RNN)之后,保证实时的中间状态可以再序列化后保存到 Redis 中。
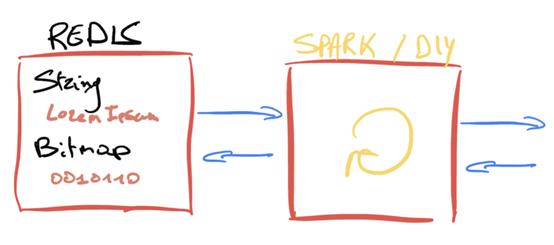
考虑到 RNN 的时间复杂度,数据序列化/反序列化上 CPU 的开销和巨大的网络开销,我们需要一个更优的解决方案来保证用户体验。
2、RedisAI 方案
在 RedisAI 中,我们提供了一种叫 Tensor 的数据类型,只需使用一系列简单的命令,即可在主流的客户端中对 Tensor向量进行操作。同时,我们还为模型的运行时特性提供了另外两种数据类型:Models 和 Scripts。

Models 命令与运行的设备(CPU 或 GPU)和后端自定义的参数有关。RedisAI 内置了主流的机器学习框架,如 TensorFlow、Pytorch 等,并很快能够支持 ONNX Runtime 框架,同时增加了对传统机器学习模型的支持。然而,很棒的是,执行 Model 的命令对其后端是不感知的:
| AI.MODELRUN model_key INPUTS input_key1 … OUTPUTS output_key1 .. |
这允许用户将后端选择(通常由数据专家来决定)和应用服务解耦合开来,置换模型只需要设置一个新的键值即可,非常简单。RedisAI 管理所有在模型处理队列中的请求,并在单独的线程中执行,这样保障了 Redis依然可以响应其它正常的请求。Scripts 命令可以在 CPU 或GPU 上执行,并允许用户使用 TorchScript 来操作Tensors 向量,TorchScript 是一个可操作 Tensors 向量的类 Python 自定义语言。这可以帮助用户在执行模型前对数据进行预处理,也可以用在对结果进行后处理的场景中,例如通过集成不同的模型来提高性能。
我们计划未来通过 DAG 命令支持批量执行命令,这会允许用户在一个原子性操作中批量执行多个 RedisAI 命令。例如在不同的设备上运行一个模型的不同实例,通过脚本对执行结果做平均预测。使用 DAG 命令,就可并行地进行计算,再执行聚合操作。如果需要全量且更深的特性列表,可以访问 redisai.io。新的架构可以简化为: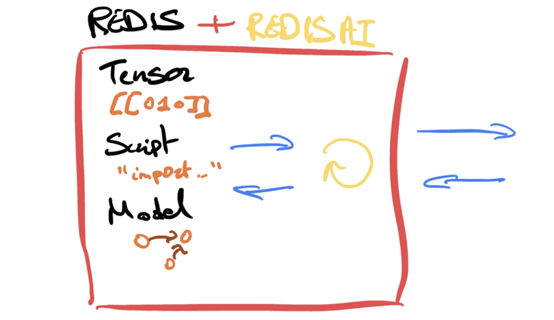
模型服务可以更简单
在生产环境中,使用 Jupyter notebooks 来编写代码并将其部署在Flask 应用并不是最优方案。用户如何确定自己的资源是最佳的呢?如果用户主机宕机之后,上述聊天机器人的中间状态会发生什么呢?用户可能会重复造轮子,实现已有的 Redis 功能来解决问题。另外,由于组合方案的复杂度往往超出预期,固执地坚持原有的解决方案也会非常有挑战性。RedisAI 通过 Redis 企业级的数据存储方案,支持深度学习所需要的 Tensors、Models 和 Scripts等数据类型,很好的实现了 Redis 和 AI 模型的深度整合。如果需要扩展模型的计算能力,只需要简单的对Redis 集群进行扩容即可,所以用户可以在生产环境中增加尽可能多的模型,从而降低基础设施成本和总体成本。最后,RedisAI 很好地适应了现有的 Redis 生态,允许用户执行脚本来预处理、后处理用户数据,可使用 RedisGear 对数据结构做正确的转换,可使用RedisGraph 来保持数据处于最新的状态。
结论和后续计划
1、短期内,我们希望使用RedisAI 在支持 3 种主流后端(Tensorflow、Pytorch 和 ONNX Runtime)的情况下,尽快稳定下来并达到稳定状态。
2、我们希望可以动态加载这些后端,用户可以自定义的加载指定的后端。例如,这将允许用户使用Tensorflow Lite 处理边缘用例。3、计划实现自动调度功能,可以实现在同一模型中实现不同队列的自动合并。4、RedisAI会统计模型的运行数据,用于衡量模型的执行情况。
5、完成上文中解释的DAG 特性。
更多优质中间件技术资讯/原创/翻译文章/资料/干货,请关注“中间件小哥”公众号!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号