【ShoppingWebCrawler】-C#开发的基于Webkit内核开源爬虫蜘蛛引擎
概述
在各个电商平台发展日渐成熟的今天。很多时候,我们需要一些平台上的基础数据。比如:商品分类,分类下的商品详细,甚至业务订单数据。电商平台大多数提供了相应的业务接口。允许ISV接入,用来扩展自身平台的不足,更好的为使用者提供服务。但是平台的ISV接入门槛现在越来越高,审核也越来越严格。拿不到接口SDK的密钥,就只能望洋兴叹。
针对这种情况,有时候就需要采取一些另类手段-蜘蛛爬虫。 模拟正常的客户端请求,对获取响应的内容进行解析,从内容提取关键内容。
蜘蛛爬虫的核心就是:发送http请求,获取响应。
万变不离其宗。使用python的做的爬虫比较多,相应的工具包也比较丰富。比如大名鼎鼎的 scrapy。但是这种单纯的发送请求 ,获取响应的引擎,有时候很难在响应式交互页面就显得捉鸡。大把大把的js ajax请求,让响应的内容并不是想要的结果。让蜘蛛引擎搭配浏览器内核,看起来是个不错的选择。尤其是对js H5支持较好的webkit内核,再好不过。
pthon 爬虫的典型:
scrapy + selenium + PhantomJS + libcef作为C#的拥趸者,我们用C# 来实现上面的引擎机制。ShoppingWebCrawler 就是在这种背景下诞生的。
项目github地址:ShoppingWebCrawler
开发语言:C#
开发工具:Visual Studio 2015 +.Net Framework4.0
运行平台:Windows
支持集群:是
可视化工具:支持;可视化工具目前有针对蜘蛛的web浏览器工具,用来进行登录授权,进程共享cookie。ShoppingPeeker 项目用来实现对蜘蛛数据的可视化操作。
承载方式:Windows 服务。
支持高效TCP通信
支持集群部署
支持Windows 服务+Headless
支持会话可靠性 登录状态保持
支持模拟 Chrome 请求发送解析响应
内置libcef 支持V8 解析JS
姊妹篇同步发行
【ShoppingPeeker】-基于Webkit内核的爬虫蜘蛛引擎 ShoppingWebCrawler的姊妹篇-可视化任务Web管理
ShoppingWebCrawler
This Project is a WebCrawler build by .net framework . 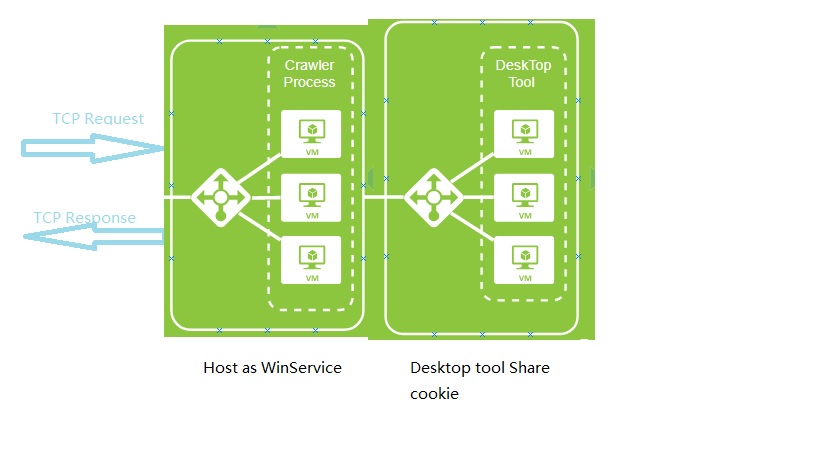
本项目是一个基于使用微软.net framework 结合Google的webkit内核做的蜘蛛采集工具。 支持多进程的集群模式。实现高性能的蜘蛛采集!
项目概述
使用此工具,进行电商平台的数据采集。 本项目已经实现可以采集淘宝、天猫、京东、拼多多、一号店、国美、苏宁等主流电商平台的网页数据。
实现核心
1、使用基于 Xilium.CefGlue 的libcef绑定,实现C#操作webkit。进行可视化的登陆授权。不定时刷新,进行登陆状态的模拟和守护。
2、使用Topshelf+libcef的Headless 模式(无头模式),进行windows 服务承载。对蜘蛛进程进行挂载守护。
3、使用log4net进行日志记录
4、使用Quartz.Net 进行定时任务Schduler。
5、服务进程使用自定义高性能Socket(NTCPMessage)进行网络通信。对来自服务Client的请求进行请求应答。
6、集群模式,使用简易的多进程实现集群。开启不同的监听端口,实现采集任务的负载均衡,进而大幅度提升硬件服务器的使用效率。
Xilium.CefGlue 简介
Xilium.CefGlue是对CEF项目的.net的包装,它是用P/Invoke的方式来调用CEF类库的,请参见:https://bitbucket.org/xilium/xilium.cefglue/wiki/Home。 使用Xilium.CefGlue 可以实现.net 操作Chrome浏览器内核。进而实现浏览器网页加载,js V8的实现。
Topshelf简介
Topshelf是创建Windows服务的一种方法。Topshelf是一个开源的跨平台的宿主服务框架,支持Windows和Mono,只需要几行代码就可以构建一个很方便使用的服务宿主。
引用安装 1、官网:http://topshelf-project.com/ 这里面有详细的文档及下载
安装:TopshelfDemo.exe install
启动:TopshelfDemo.exe start
重启:TopshelfDemo.exe restart
卸载:TopshelfDemo.exe uninstall
什么是Headless浏览器?
简单的说就是一个没有UI界面的浏览器。使用命令行进行代码控制浏览器行为,常见于自动化单元测试。
如何使用?
1、下载源码到本地。比如:d:\src
2、使用visual studio2015 打开项目并编译。
3、配置Redis 环境。本项目使用redis 进行进程间的cookie共享,从而实现登录凭据cookie的跨进程共享。在UI进程和Heaadless进程间进行Cookie共享。
4、运行 ShoppingWebCrawler.Host 项目,即可运行。
如何使用界面工具进行请求的可视化?
编译 ShoppingWebCrawler.Host.DeskTop ,得到UI 工具,可以对打开一个网址。比如登录淘宝,就可以在本地进程间共享淘宝登录凭据。从而实现 特定的蜘蛛采集任务。比如:采集某个类目的商品。采集商品优惠券。
如何在Windows 服务进行承载?
编译项目ShoppingWebCrawler.Host.WindowService,然后去项目的输出目录,在cmd 、powershell 定位到此目录。执行:
ShoppingWebCrawler.Host.WindowService.exe install 即可。如果想卸载,那么执行指令:ShoppingWebCrawler.Host.WindowService.exe uninstall .
参考topshelf的命令。
如何开启集群模式?
在项目ShoppingWebCrawler.Host 的app.config文件中
<!--是否开启集群模式-->
<add key="ClusteringMode" value="true"/>
<!--集群子节点数量-->
<add key="ClusterNodeCount" value="3"/>
联系作者
MyBlog:http://www.cnblogs.com/micro-chen/
QQ:1021776019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号