
C#实现前向最大匹配、字典树(分词、检索)
场景:现在有一个错词库,维护的是错词和正确词对应关系。比如:错词“我门”对应的正确词“我们”。然后在用户输入的文字进行错词校验,需要判断输入的文字是否有错词,并找出错词以便提醒用户,并且可以显示出正确词以便用户确认,如果是错词就进行替换。
首先想到的就是取出错词List放在内存中,当用户输入完成后用错词List来foreach每个错词,然后查找输入的字符串中是否包含错词。这是一种有效的方法,并且能够实现。问题是错词的数量比较多,目前有10多万条,将来也会不断更新扩展。所以pass了这种方案,为了让错词查找提高速度就用了字典树来存储错词。
字典树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
通常字典树的查询时间复杂度是O(logL),L是字符串的长度。所以效率还是比较高的。而我们上面说的foreach循环则时间复杂度为O(n),根据时间复杂度来看,字典树效率应该是可行方案。
字典树原理
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
比如现在有错词:“我门”、“旱睡”、“旱起”。那么字典树如下图
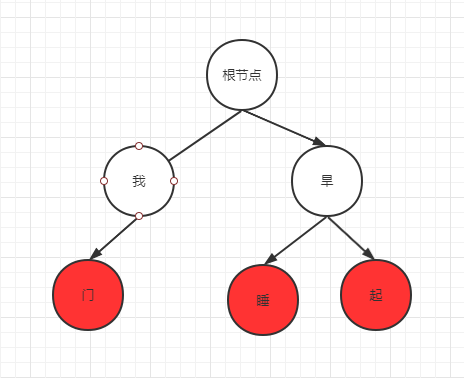
其中红色的点就表示词结束节点,也就是从根节点往下连接成我们的词。
实现字典树:

1 public class Trie
2 {
3 private class Node
4 {
5 /// <summary>
6 /// 是否单词根节点
7 /// </summary>
8 public bool isTail = false;
9
10 public Dictionary<char, Node> nextNode;
11
12 public Node(bool isTail)
13 {
14 this.isTail = isTail;
15 this.nextNode = new Dictionary<char, Node>();
16 }
17 public Node() : this(false)
18 {
19 }
20 }
21
22 /// <summary>
23 /// 根节点
24 /// </summary>
25 private Node rootNode;
26 private int size;
27 private int maxLength;
28
29 public Trie()
30 {
31 this.rootNode = new Node();
32 this.size = 0;
33 this.maxLength = 0;
34 }
35
36 /// <summary>
37 /// 字典树中存储的单词的最大长度
38 /// </summary>
39 /// <returns></returns>
40 public int MaxLength()
41 {
42 return maxLength;
43 }
44
45 /// <summary>
46 /// 字典树中存储的单词数量
47 /// </summary>
48 public int Size()
49 {
50 return size;
51 }
52
53 /// <summary>
54 /// 获取字典树中所有的词
55 /// </summary>
56 public List<string> GetWordList()
57 {
58 return GetStrList(this.rootNode);
59 }
60
61 private List<string> GetStrList(Node node)
62 {
63 List<string> wordList = new List<string>();
64
65 foreach (char nextChar in node.nextNode.Keys)
66 {
67 string firstWord = Convert.ToString(nextChar);
68 Node childNode = node.nextNode[nextChar];
69
70 if (childNode == null || childNode.nextNode.Count == 0)
71 {
72 wordList.Add(firstWord);
73 }
74 else
75 {
76
77 if (childNode.isTail)
78 {
79 wordList.Add(firstWord);
80 }
81
82 List<string> subWordList = GetStrList(childNode);
83 foreach (string subWord in subWordList)
84 {
85 wordList.Add(firstWord + subWord);
86 }
87 }
88 }
89
90 return wordList;
91 }
92
93 /// <summary>
94 /// 向字典中添加新的单词
95 /// </summary>
96 /// <param name="word"></param>
97 public void Add(string word)
98 {
99 //从根节点开始
100 Node cur = this.rootNode;
101 //循环遍历单词
102 foreach (char c in word.ToCharArray())
103 {
104 //如果字典树节点中没有这个字母,则添加
105 if (!cur.nextNode.ContainsKey(c))
106 {
107 cur.nextNode.Add(c, new Node());
108 }
109 cur = cur.nextNode[c];
110 }
111 cur.isTail = true;
112
113 if (word.Length > this.maxLength)
114 {
115 this.maxLength = word.Length;
116 }
117 size++;
118 }
119
120 /// <summary>
121 /// 查询字典中某单词是否存在
122 /// </summary>
123 /// <param name="word"></param>
124 /// <returns></returns>
125 public bool Contains(string word)
126 {
127 return Match(rootNode, word);
128 }
129
130 /// <summary>
131 /// 查找匹配
132 /// </summary>
133 /// <param name="node"></param>
134 /// <param name="word"></param>
135 /// <returns></returns>
136 private bool Match(Node node, string word)
137 {
138 if (word.Length == 0)
139 {
140 if (node.isTail)
141 {
142 return true;
143 }
144 else
145 {
146 return false;
147 }
148 }
149 else
150 {
151 char firstChar = word.ElementAt(0);
152 if (!node.nextNode.ContainsKey(firstChar))
153 {
154 return false;
155 }
156 else
157 {
158 Node childNode = node.nextNode[firstChar];
159 return Match(childNode, word.Substring(1, word.Length - 1));
160 }
161 }
162 }
163 }
测试下:

现在我们有了字典树,然后就不能以字典树来foreach,字典树用于检索。我们就以用户输入的字符串为数据源,去字典树种查找是否存在错词。因此需要对输入字符串进行取词检索。也就是分词,分词我们采用前向最大匹配。
前向最大匹配
我们分词的目的是将输入字符串分成若干个词语,前向最大匹配就是从前向后寻找在词典中存在的词。
例子:我们假设maxLength= 3,即假设单词的最大长度为3。实际上我们应该以字典树中的最大单词长度,作为最大长度来分词(上面我们的字典最大长度应该是2)。这样效率更高,为了演示匹配过程就假设maxLength为3,这样演示的更清楚。
用前向最大匹配来划分“我们应该早睡早起” 这句话。因为我是错词匹配,所以这句话我改成“我门应该旱睡旱起”。
第一次:取子串 “我门应”,正向取词,如果匹配失败,每次去掉匹配字段最后面的一个字。
“我门应”,扫描词典中单词,没有匹配,子串长度减 1 变为“我门”。
“我门”,扫描词典中的单词,匹配成功,得到“我门”错词,输入变为“应该旱”。
第二次:取子串“应该旱”
“应该旱”,扫描词典中单词,没有匹配,子串长度减 1 变为“应该”。
“应该”,扫描词典中的单词,没有匹配,输入变为“应”。
“应”,扫描词典中的单词,没有匹配,输入变为“该旱睡”。
第三次:取子串“该旱睡”
“该旱睡”,扫描词典中单词,没有匹配,子串长度减 1 变为“该旱”。
“该旱”,扫描词典中的单词,没有匹配,输入变为“该”。
“该”,扫描词典中的单词,没有匹配,输入变为“旱睡旱”。
第四次:取子串“旱睡旱”
“旱睡旱”,扫描词典中单词,没有匹配,子串长度减 1 变为“旱睡”。
“旱睡”,扫描词典中的单词,匹配成功,得到“旱睡”错词,输入变为“早起”。
以此类推,我们得到错词 我们/旱睡/旱起。
因为我是结合字典树匹配错词所以一个字也可能是错字,则匹配到单个字,如果只是分词则上面的到一个字的时候就应该停止分词了,直接字符串长度减1。
这种匹配方式还有后向最大匹配以及双向匹配,这个大家可以去了解下。
实现前向最大匹配,这里后向最大匹配也可以一起实现。
1 public class ErrorWordMatch
2 {
3 private static ErrorWordMatch singleton = new ErrorWordMatch();
4 private static Trie trie = new Trie();
5 private ErrorWordMatch()
6 {
7
8 }
9
10 public static ErrorWordMatch Singleton()
11 {
12 return singleton;
13 }
14
15 public void LoadTrieData(List<string> errorWords)
16 {
17 foreach (var errorWord in errorWords)
18 {
19 trie.Add(errorWord);
20 }
21 }
22
23 /// <summary>
24 /// 最大 正向/逆向 匹配错词
25 /// </summary>
26 /// <param name="inputStr">需要匹配错词的字符串</param>
27 /// <param name="leftToRight">true为从左到右分词,false为从右到左分词</param>
28 /// <returns>匹配到的错词</returns>
29 public List<string> MatchErrorWord(string inputStr, bool leftToRight)
30 {
31 if (string.IsNullOrWhiteSpace(inputStr))
32 return null;
33 if (trie.Size() == 0)
34 {
35 throw new ArgumentException("字典树没有数据,请先调用 LoadTrieData 方法装载字典树");
36 }
37 //取词的最大长度
38 int maxLength = trie.MaxLength();
39 //取词的当前长度
40 int wordLength = maxLength;
41 //分词操作中,处于字符串中的当前位置
42 int position = 0;
43 //分词操作中,已经处理的字符串总长度
44 int segLength = 0;
45 //用于尝试分词的取词字符串
46 string word = "";
47
48 //用于储存正向分词的字符串数组
49 List<string> segWords = new List<string>();
50 //用于储存逆向分词的字符串数组
51 List<string> segWordsReverse = new List<string>();
52
53 //开始分词,循环以下操作,直到全部完成
54 while (segLength < inputStr.Length)
55 {
56 //如果剩余没分词的字符串长度<取词的最大长度,则取词长度等于剩余未分词长度
57 if ((inputStr.Length - segLength) < maxLength)
58 wordLength = inputStr.Length - segLength;
59 //否则,按最大长度处理
60 else
61 wordLength = maxLength;
62
63 //从左到右 和 从右到左截取时,起始位置不同
64 //刚开始,截取位置是字符串两头,随着不断循环分词,截取位置会不断推进
65 if (leftToRight)
66 position = segLength;
67 else
68 position = inputStr.Length - segLength - wordLength;
69
70 //按照指定长度,从字符串截取一个词
71 word = inputStr.Substring(position, wordLength);
72
73
74 //在字典中查找,是否存在这样一个词
75 //如果不包含,就减少一个字符,再次在字典中查找
76 //如此循环,直到只剩下一个字为止
77 while (!trie.Contains(word))
78 {
79 //如果最后一个字都没有匹配,则把word设置为空,用来表示没有匹配项(如果是分词直接break)
80 if (word.Length == 1)
81 {
82 word = null;
83 break;
84 }
85
86 //把截取的字符串,最边上的一个字去掉
87 //从左到右 和 从右到左时,截掉的字符的位置不同
88 if (leftToRight)
89 word = word.Substring(0, word.Length - 1);
90 else
91 word = word.Substring(1);
92 }
93
94 //将分出匹配上的词,加入到分词字符串数组中,正向和逆向不同
95 if (word != null)
96 {
97 if (leftToRight)
98 segWords.Add(word);
99 else
100 segWordsReverse.Add(word);
101 //已经完成分词的字符串长度,要相应增加
102 segLength += word.Length;
103 }
104 else
105 {
106 //没匹配上的则+1,丢掉一个字(如果是分词 则不用判断word是否为空,单个字也返回)
107 segLength += 1;
108 }
109 }
110
111 //如果是逆向分词,对分词结果反转排序
112 if (!leftToRight)
113 {
114 for (int i = segWordsReverse.Count - 1; i >= 0; i--)
115 {
116 //将反转的结果,保存在正向分词数组中 以便最后return 同一个变量segWords
117 segWords.Add(segWordsReverse[i]);
118 }
119 }
120
121 return segWords;
122 }
123 }
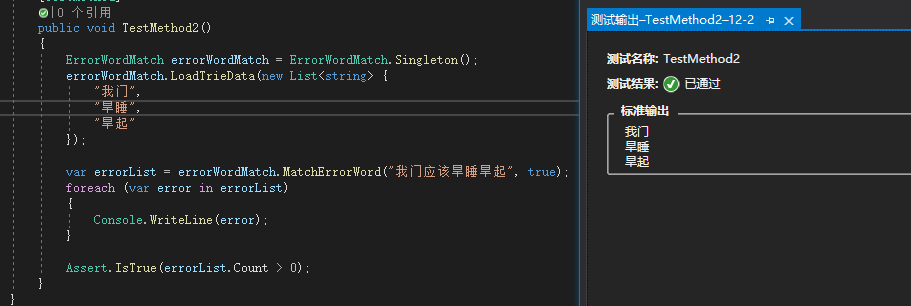
这里使用了单例模式用来在项目中共用,在第一次装入了字典树后就可以在其他地方匹配错词使用了。
这个是结合我具体使用,简化了些代码,如果只是分词的话就是分词那个实现方法就行了。最后分享就到这里吧,如有不对之处,请加以指正。
作者:孙泉
出处:https://www.cnblogs.com/SunSpring/p/12891504.html
如果你喜欢文章欢迎点击推荐,你的鼓励对我很有用!
本文版权归作者所有,转载需在文章页面明显位置给出原文链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号