数据分析初步(jupyter常用快捷键,numpy,pandas,matplotlib常用用法)
Jupyter 快捷键(命令模式下按h即可查看所有的快捷键)
Ctrl + Enter 运行代码
'''
命令和编辑两种键盘输入模式。
'''
#命令模式是将键盘和笔记本层面的命令绑定起来,并且由带有蓝色左边距的灰色单元边框表示。
#编辑模式则让你可以在活动单元中输入文本(或代码),用绿色单元边框表示。
Esc和Enter用于切换命令模式和编辑模式
###############
####命令模式####
###############
a.会在活跃单元之上插入一个新的单元。
b.会在活跃单元之下插入一个新单元
dd.可以删除一个单元
y.将当前活跃单元变成一个代码单元
shift + 上/下箭头.可以选择多个单元
shift + M.多选模式下可以合并选择的代码块
F.会弹出‘查找和替换’菜单
###############
####编辑模式####
###############
ctrl + home.到达单元起始位置。
ctrl + s.保存进度。
ctrl + enter.运行单元块。
alt + enter.先运行单元块,然后在下面添加一个新单元。
ctrl + shift + f.打开命令面板。
numpy
python的zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
简介:
Numpy是高性能科学计算和数据分析的基础包。它也是pandas等其他数据分析的工具的基础,基本所有数据分析的包都用过它。NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组。
ndarray -多维数组对象
#生成对象
import numpy as np
li = [1, 2, 3]
np.array(li)
##注意(和python中列表的区别)
'''
数组对象内的元素类型必须相同
数组大小不可修改
'''
#常用属性
T.转置
dtype.数组元素的数据类型
size.数组元素的个数
ndim.数组的维数
shape.数组的维度大小(以元组形式)
#数组类型
布尔,整型,无符号整型,浮点型,复数型。
可以用astype()方法修改数组的数据类型
#######内置方法
1、arange():
np.arange(1.2,10,0.4)
执行结果:
array([1.2, 1.6, 2. , 2.4, 2.8, 3.2, 3.6, 4. , 4.4, 4.8, 5.2, 5.6, 6. ,
6.4, 6.8, 7.2, 7.6, 8. , 8.4, 8.8, 9.2, 9.6])
# 在进行数据分析的时候通常我们遇到小数的机会远远大于遇到整数的机会,这个方法与Python内置的range的使用方法一样
-----------------------------------------------------------------
2、linspace()
np.linspace(1,10,20)
执行结果:
array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684,
3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
# 这个方法与arange有一些区别,arange是顾头不顾尾,而这个方法是顾头又顾尾,在1到10之间生成的二十个数每个数字之间的距离相等的,前后两个数做减法肯定相等
----------------------------------------------------------------
3、zeros()
np.zeros((3,4))
执行结果:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
# 会用0生成三行四列的一个多维数组
---------------------------------------------------------------------
4、ones()
np.ones((3,4))
执行结果:
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
# 会用1生成三行四列的一个多维数组
------------------------------------------------------------------------
5、empty()
np.empty(10)
执行结果:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
# 这个方法只申请内存,不给它赋值
-----------------------------------------------------------------------
6、eye()
np.eye(5)
执行结果:
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
#######切片和索引
1.数组和标量(数字)之间的运算
li1 = [
[1,2,3],
[4,5,6]
]
a = np.array(li1)
a * 2
运行结果:
array([[ 2, 4, 6],
[ 8, 10, 12]])
2.同样大小数组之间的运算
# l2数组
l2 = [
[1,2,3],
[4,5,6]
]
a = np.array(l2)
# l3数组
l3 = [
[7,8,9],
[10,11,12]
]
b = np.array(l3)
a + b # 计算
执行结果:
array([[ 8, 10, 12],
[14, 16, 18]])
3.索引
# 将一维数组变成二维数组
arr = np.arange(30).reshape(5,6) # 后面的参数6可以改为-1,相当于占位符,系统可以自动帮忙算几列
arr
# 将二维变一维
arr.reshape(30)
# 索引使用方法
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]])
现在有这样一组数据,需求:找到20
列表写法:arr[3][2]
数组写法:arr[3,2] # 中间通过逗号隔开就可以了
##布尔型索引
现在有这样一个需求:给一个数组,选出数组种所有大于5的数。
'''
li = [random.randint(1,10) for _ in range(30)]
a = np.array(li)
a[a>5]
执行结果:
array([10, 7, 7, 9, 7, 9, 10, 9, 6, 8, 7, 6])
----------------------------------------------
原理:
a>5会对a中的每一个元素进行判断,返回一个布尔数组
a > 5的运行结果:
array([False, True, False, True, True, False, True, False, False,
False, False, False, False, False, False, True, False, True,
False, False, True, True, True, True, True, False, False,
False, False, True])
----------------------------------------------
布尔型索引:将同样大小的布尔数组传进索引,会返回一个有True对应位置的元素的数组
'''
4.切片
arr数组
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]])
arr[1:4,1:4] # 切片方式
执行结果:
array([[ 7, 8, 9],
[13, 14, 15],
[19, 20, 21]])
##切片不会拷贝,直接使用的原视图,如果硬要拷贝,需要在后面加.copy()方法
'''
arr = np.arange(10) #随机生成一个一维数组
arr
b = arr[5:] # 切片 5以后的
b
b[0] = 10 #修改切片之后的数据
arr
运行结果是,
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
'''
## 最后会发现修改切片后的数据影响的依然是原数据,是同一块内存地址,因此属于可变对象。
常见函数
## 一元函数
'''
函数 功能
abs、fabs 分别是计算整数和浮点数的绝对值
sqrt 计算各元素的平方根
square 计算各元素的平方
exp 计算各元素的指数e**x
log 计算自然对数
sign 计算各元素的正负号
ceil 计算各元素的ceiling值
floor 计算各元素floor值,即小于等于该值的最大整数
rint 计算各元素的值四舍五入到最接近的整数,保留dtype
modf 将数组的小数部分和整数部分以两个独立数组的形式返回,与Python的divmod方法类似
isnan 计算各元素的正负号
isinf 表示那些元素是无穷的布尔型数组
cos,sin,tan 普通型和双曲型三角函数
'''
## 二元函数
'''
函数 功能
add 将数组中对应的元素相加
subtract 从第一个数组中减去第二个数组中的元素
multiply 数组元素相乘
divide、floor_divide 除法或向下圆整除法(舍弃余数)
power 对第一个数组中的元素A,根据第二个数组中的相应元素B计算A**B
maximum,fmax 计算最大值,fmax忽略NAN
miximum,fmix 计算最小值,fmin忽略NAN
mod 元素的求模计算(除法的余数)
'''
补充内容:浮点数特殊值
浮点数:float
浮点数有两个特殊值:
1、nan(Not a Number):不等于任何浮点数(nan != nan)
---------------------------------------------
2、inf(infinity):比任何浮点数都大
---------------------------------------------
Numpy中创建特殊值:np.nan、np.inf
数据分析中,nan常被用作表示数据缺失值
## 数学统计方法
函数 功能
sum 求和
cumsum 求前缀和
mean 求平均数
std 求标准差
var 求方差
min 求最小值
max 求最大值
argmin 求最小值索引
argmax 求最大值索引
## 随机数
随机数生成函数在np.random的子包当中
函数 功能
rand 给定形状产生随机数组(0到1之间的数)
randint 给定形状产生随机整数
chocie 给定形状产生随机选择
shuffle 与random.shuffle相同
uniform 给定形状产生随机数组
Pandas
简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
主要功能
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
1、创建方法
第一种:
pd.Series([4,5,6,7,8])
执行结果:
0 4
1 5
2 6
3 7
4 8
dtype: int64
# 将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取值,跟之前学过的数组和列表一样
-----------------------------------------------
第二种:
c = pd.Series([4,5,6,7,8],index=['a','b','c','d','e'])
执行结果:
a 4
b 5
c 6
d 7
e 8
dtype: int64
# 自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
c[0] = c['a'] = 4
-----------------------------------------------
第三种:
pd.Series({"a":1,"b":2})
执行结果:
a 1
b 2
dtype: int64
# 指定索引
-----------------------------------------------
第四种:
pd.Series(0,index=['a','b','c'])
执行结果:
a 0
b 0
c 0
dtype: int64
# 创建一个值都是0的数组
-----------------------------------------------
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series
2、缺失数据
- dropna() # 过滤掉值为NaN的行
- fill() # 填充缺失数据
- isnull() # 返回布尔数组,缺失值对应为True
- notnull() # 返回布尔数组,缺失值对应为False
# 第一步,创建一个字典,通过Series方式创建一个Series对象
st = {"sean":18,"yang":19,"bella":20,"cloud":21}
obj = pd.Series(st)
obj
运行结果:
sean 18
yang 19
bella 20
cloud 21
dtype: int64
------------------------------------------
# 第二步
a = {'sean','yang','cloud','rocky'} # 定义一个索引变量
------------------------------------------
#第三步
obj1 = pd.Series(st,index=a)
obj1 # 将第二步定义的a变量作为索引传入
# 运行结果:
rocky NaN
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
# 因为rocky没有出现在st的键中,所以返回的是缺失值
通过上面的代码演示,对于缺失值已经有了一个简单的了解,接下来就来看看如何判断缺失值
1、
obj1.isnull() # 是缺失值返回Ture
运行结果:
rocky True
cloud False
sean False
yang False
dtype: bool
2、
obj1.notnull() # 不是缺失值返回Ture
运行结果:
rocky False
cloud True
sean True
yang True
dtype: bool
3、过滤缺失值 # 布尔型索引
obj1[obj1.notnull()]
运行结果:
cloud 21.0
yang 19.0
sean 18.0
dtype: float64
3、Series特性
- 从ndarray创建Series:Series(arr)
- 与标量(数字):sr * 2
- 两个Series运算
- 通用函数:np.ads(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()、sum()、cumsum()
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:'a'in sr、for x in sr
- 键索引:sr['a'],sr[['a','b','d']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default=0)等
4、整数索引
pandas当中的整数索引对象可能会让初次接触它的人很懵逼,接下来通过代码演示:
sr = pd.Series(np.arange(10))
sr1 = sr[3:].copy()
sr1
运行结果:
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
# 到这里会发现很正常,一点问题都没有,可是当使用整数索引取值的时候就会出现问题了。因为在pandas当中使用整数索引取值是优先以标签解释的,而不是下标
sr1[1]
解决方法:
- loc属性 # 以标签解释
- iloc属性 # 以下标解释
sr1.iloc[1] # 以下标解释
sr1.loc[3] # 以标签解释
5、Series数据对齐
pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1 + sr2
运行结果:
a 33
c 32
d 45
dtype: int64
# 可以通过这种索引对齐直接将两个Series对象进行运算
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1 + sr3
运行结果:
a 33.0
b NaN
c 32.0
d 45.0
dtype: float64
# sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0:
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1.add(sr3,fill_value=0)
运行结果:
a 33.0
b 14.0
c 32.0
d 45.0
dtype: float64
# 将缺失值设为0,所以最后算出来b索引对应的结果为14
灵活的算术方法:add,sub,div,mul
DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式:
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种:
pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
# 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列
运行结果:
one two
0 1 4
1 2 3
2 3 2
3 4 1
> 指定列
可以通过columns参数指定顺序排列
data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
pd.DataFrame(data,columns=['one','two'])
# 打印结果会按照columns参数指定顺序
第二种:
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])})
运行结果:
one two
a 1 2
b 2 1
c 3 3
以上创建方法简单了解就可以,因为在实际应用当中更多是读数据,不需要自己手动创建
查看数据
常用属性和方法:
- index 获取行索引
- columns 获取列索引
- T 转置
- columns 获取列索引
- values 获取值索引
- describe 获取快速统计
one two
a 1 2
b 2 1
c 3 3
# 这样一个数组df
-----------------------------------------------------------------------------
df.index
运行结果:
Index(['a', 'b', 'c'], dtype='object')
----------------------------------------------------------------------------
df.columns
运行结果:
Index(['one', 'two'], dtype='object')
--------------------------------------------------------------------------
df.T
运行结果:
a b c
one 1 2 3
two 2 1 3
-------------------------------------------------------------------------
df.values
运行结果:
array([[1, 2],
[2, 1],
[3, 3]], dtype=int64)
------------------------------------------------------------------------
df.describe()
运行结果:
one two
count 3.0 3.0
mean 2.0 2.0
std 1.0 1.0
min 1.0 1.0
25% 1.5 1.5
50% 2.0 2.0
75% 2.5 2.5
max 3.0 3.0
## 注释:
对于数值数据,结果的索引将包括计数,平均值,标准差,最小值,最大值以及较低的百分位数和50。默认情况下,较低的百分位数为25,较高的百分位数为75.50百分位数与中位数相同。
索引和切片
- DataFrame有行索引和列索引。
- DataFrame同样可以通过标签和位置两种方法进行索引和切片。
DataFrame使用索引切片:
- 方法1:两个中括号,先取列再取行。 df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
- loc属性:解释为标签
- iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)
时间对象处理
时间序列类型
- 时间戳:特定时刻
- 固定时期:如2019年1月
- 时间间隔:起始时间-结束时间
Python库:datatime
- date、time、datetime、timedelta
- dt.strftime()
- strptime()
灵活处理时间对象:dateutil包
- dateutil.parser.parse()
import dateutil
dateutil.parser.parse("2019 Jan 2nd") # 这中间的时间格式一定要是英文格式
运行结果:
datetime.datetime(2019, 1, 2, 0, 0)
成组处理时间对象:pandas
- pd.to_datetime(['2018-01-01', '2019-02-02'])
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
运行结果:
DatetimeIndex(['2018-03-01', '2019-02-03', '2019-08-12'], dtype='datetime64[ns]', freq=None) # 产生一个DatetimeIndex对象
# 转换时间索引
ind = pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
sr = pd.Series([1,2,3],index=ind)
sr
运行结果:
2018-03-01 1
2019-02-03 2
2019-08-12 3
dtype: int64
通过以上方式就可以将索引转换为时间
补充:
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019']).to_pydatetime()
运行结果:
array([datetime.datetime(2018, 3, 1, 0, 0),
datetime.datetime(2019, 2, 3, 0, 0),
datetime.datetime(2019, 8, 12, 0, 0)], dtype=object)
# 通过to_pydatetime()方法将其转换为array数组
产生时间对象数组:data_range
- start 开始时间
- end 结束时间
- periods 时间长度
- freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
pd.date_range("2019-1-1","2019-2-2")
运行结果:
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08',
'2019-01-09', '2019-01-10', '2019-01-11', '2019-01-12',
'2019-01-13', '2019-01-14', '2019-01-15', '2019-01-16',
'2019-01-17', '2019-01-18', '2019-01-19', '2019-01-20',
'2019-01-21', '2019-01-22', '2019-01-23', '2019-01-24',
'2019-01-25', '2019-01-26', '2019-01-27', '2019-01-28',
'2019-01-29', '2019-01-30', '2019-01-31', '2019-02-01',
'2019-02-02'],
dtype='datetime64[ns]', freq='D')
时间序列
时间序列就是以时间对象为索引的Series或DataFrame。datetime对象作为索引时是存储在DatetimeIndex对象中的。
# 转换时间索引
dt = pd.date_range("2019-01-01","2019-02-02")
a = pd.DataFrame({"num":pd.Series(random.randint(-100,100) for _ in range(30)),"date":dt})
# 先生成一个带有时间数据的DataFrame数组
a.index = pd.to_datetime(a["date"])
# 再通过index修改索引
特殊功能:
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
- 丰富的函数支持:resample(), strftime(), ……
- 批量转换为datetime对象:to_pydatetime()
a.resample("3D").mean() # 计算每三天的均值
a.resample("3D").sum() # 计算每三天的和
...
数据分组和聚合
在数据分析当中,我们有时需要将数据拆分,然后在每一个特定的组里进行运算,这些操作通常也是数据分析工作中的重要环节。
本章学习内容:
- 分组(GroupBY机制)
- 聚合(组内应用某个函数)
- apply
- 透视表和交叉表
5.1、分组(GroupBY机制)
pandas对象(无论Series、DataFrame还是其他的什么)当中的数据会根据提供的一个或者多个键被拆分为多组,拆分操作实在对象的特定轴上执行的。就比如DataFrame可以在他的行上或者列上进行分组,然后将一个函数应用到各个分组上并产生一个新的值。最后将所有的执行结果合并到最终的结果对象中。
分组键的形式:
- 列表或者数组,长度与待分组的轴一样
- 表示DataFrame某个列名的值。
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或者索引中的各个标签吗
后三种只是快捷方式,最终仍然是为了产生一组用于拆分对象的值。
首先,通过一个很简单的DataFrame数组尝试一下:
df = pd.DataFrame({'key1':['x','x','y','y','x',
'key2':['one','two','one',',two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
运行结果:
key1 key2 data1 data2
0 x one 0.951762 1.632336
1 x two -0.369843 0.602261
2 y one 1.512005 1.331759
3 y ,two 1.383214 1.025692
4 x one -0.475737 -1.182826
访问data1,并根据key1调用groupby:
f1 = df['data1'].groupby(df['key1'])
f1
运行结果:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x00000275906596D8>
上述运行是没有进行任何计算的,但是我们想要的中间数据已经拿到了,接下来,就可以调用groupby进行任何计算
f1.mean() # 调用mean函数求出平均值
运行结果:
key1
x 0.106183
y 2.895220
Name: data1, dtype: float64
以上数据经过分组键(一个Series数组)进行了聚合,产生了一个新的Series,索引就是key1列中的唯一值。这些索引的名称就为key1。接下来就尝试一次将多个数组的列表传进来
f2 = df['data1'].groupby([df['key1'],df['key2']])
f2.mean()
运行结果:
key1 key2
x one 0.083878
two 0.872437
y one -0.665888
two -0.144310
Name: data1, dtype: float64
传入多个数据之后会发现,得到的数据具有一个层次化的索引,key1对应的x\y;key2对应的one\two.
f2.mean().unstack()
运行结果:
key2 one two
key1
x 0.083878 0.872437
y -0.665888 -0.144310
# 通过unstack方法就可以让索引不堆叠在一起了
补充:
- 1、分组键可以是任意长度的数组
- 2、分组时,对于不是数组数据的列会从结果中排除,例如key1、key2这样的列
- 3、GroupBy的size方法,返回一个含有分组大小的Series
# 以上面的f2测试
f2.size()
运行结果:
key1 key2
x one 2
two 1
y one 1
two 1
Name: data1, dtype: int64
5.2、聚合(组内应用某个函数)
聚合是指任何能够从数组产生标量值的数据转换过程。刚才上面的操作会发现使用GroupBy并不会直接得到一个显性的结果,而是一个中间数据,可以通过执行类似mean、count、min等计算得出结果,常见的还有一些:
| 函数名 | 描述 | |
|---|---|---|
| sum | 非NA值的和 | |
| median | 非NA值的算术中位数 | |
| std、var | 无偏(分母为n-1)标准差和方差 | |
| prod | 非NA值的积 | |
| first、last | 第一个和最后一个非NA值 |
自定义聚合函数
不仅可以使用这些常用的聚合运算,还可以自己自定义。
# 使用自定义的聚合函数,需要将其传入aggregate或者agg方法当中
def peak_to_peak(arr):
return arr.max() - arr.min()
f1.aggregate(peak_to_peak)
运行结果:
key1
x 3.378482
y 1.951752
Name: data1, dtype: float64
多函数聚合:
f1.agg(['mean','std'])
运行结果:
mean std
key1
x -0.856065 0.554386
y -0.412916 0.214939
最终得到的列就会以相应的函数命名生成一个DataFrame数组
5.3、apply
GroupBy当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将它们组合到一起。
df.apply(
['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', '**kwds']
func:传入一个自定义函数
axis:函数传入参数当axis=1就会把一行数据作为Series的数据
# 分析NBA总冠军
import pandas as pd
url = "https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin" #nba总冠军
nba_champions = pd.read_html(url) #获取数据
a1 = nba_champions[0] #取出历史上的总冠军名单
a1.columns = a1.loc[0] #使用第一行数据替换为默认的横向索引
a1.drop(0, inplace=True) #将第一行数据删除
a1.drop('比赛日期', axis=1, inplace=True)
# a1.head()
# a1.tail()
a1
a1.groupby('冠军').groups #按冠军分组,给索引
a1.groupby('冠军').size().sort_values() #默认按冠军次数升序
a1.groupby('冠军').size().sort_values(ascending=False) #按冠军次数降序
a1.groupby(['冠军', 'FMVP']).size() # 按冠军和FMVP进行分组
其他常用方法
pandas常用方法(适用Series和DataFrame)
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis, …, ascending) # 按行或列索引排序
- sort_values(by, axis, ascending) # 按值排序
- apply(func, axis=0) # 将自定义函数应用在各行或者各列上,func可返回标量或者Series
- applymap(func) # 将函数应用在DataFrame各个元素上
- map(func) # 将函数应用在Series各个元素上
Matplotlib(绘图和可视化)
简介
Matplotlib是一个强大的Python绘图和数据可视化的工具包。数据可视化也是我们数据分析的最重要的工作之一,可以帮助我们完成很多操作,例如:找出异常值、必要的一些数据转换等。完成数据分析的最终结果也许就是做一个可交互的数据可视化。
简单绘制线形图
plt.plot() # 绘图函数
plt.show() # 显示图像
在jupyter notebook中不执行这条语句也是可以将图形展示出来
import matplotlib.pyplot as plt
import numpy as np
data = np.arange(10)
plt.plot(data)
plt.show() # 显示图像,在notebook中不执行这一句也可以
执行结果:
虽然seaborn这些库和pandas的内置绘图函数能够处理许多普通的绘图任务,如果需要自定义一些高级功能的话就必须要matplotlib API.
plot函数
plot函数:绘制折线图
- 线型linestyle(-,-.,--,..)
- 点型marker(v,^,s,*,H,+,X,D,O,...)
- 颜色color(b,g,r,y,k,w,...)
plt.plot([0,3,9,15,30],linestyle = '-.',color = 'r',marker = 'o')
图像标注
| 方法 | 描述 | |
|---|---|---|
| plt.title() | 设置图像标题 | |
| plt.xlabel() | 设置x轴名称 | |
| plt.ylabel() | 设置y轴名称 | |
| plt.xlim() | 设置x轴范围 | |
| plt.ylim() | 设置y轴范围 | |
| plt.xticks() | 设置x轴刻度 | |
| plt.yticks() | 设置y轴刻度 | |
| plt.legend() | 设置曲线图例 |
plt.plot([0,3,9,15,30],linestyle = '-.',color = 'r',marker = 'o',label="A")
plt.plot([1,3,16,23,30],[30,23,13,25,30],label='B')
#第一个数组是index,第二个数组是values
#设置字体(在同一个文件夹下面)
#font1 = matplotlib.font_manager.FontProperties(fname='msyh.ttc')
plt.title("Title", fontproperties=font1, fontsize=100) # 标题,设置字体样式和字体大小
plt.xlabel('X') # x轴名称
plt.ylabel('Y') # y轴名称
plt.xticks(np.arange(0,10,2)) # x轴刻度
plt.xlim(-0,2,10) # x轴范围
plt.legend() # 曲线图例
运行图例:
绘制数学函数
使用Matplotlib模块在一个窗口中绘制数学函数y=x, y=x**2,y=sinx的图像,使用不同颜色的线加以区别,并使用图例说明各个线代表什么函数。
x = np.arange(-100,100)
y1 = x
y2 = x ** 2
y3 = np.sin(x)
-----------------------
plt.plot(x,y1,label="y=x")
plt.plot(x,y2,label="y=x^2")
plt.plot(x,y3,label="y=sin(x)")
plt.ylim(-100,100)
plt.legend()
4、支持的图类型
| 函数 | 说明 | |
|---|---|---|
| plt.plot(x,y,fmt) | 坐标系 | |
| plt.boxplot(data,notch,position) | 箱型图 | |
| plt.bar(left,height,width,bottom) | 柱状图 | |
| plt.barh(width,bottom,left,height) | 横向柱状图 | |
| plt.polar(theta,r) | 极坐标系 | |
| plt.pie(data,explode) | 饼图 | |
| plt.psd(x,NFFT=256,pad_to,Fs) | 功率谱密度图 | |
| plt.specgram(x,NFFT=256,pad_to,F) | 谱图 | |
| plt.cohere(x,y,NFFT=256,Fs) | X-Y相关性函数 | |
| plt.scatter(x,y) | 散点图 | |
| plt.step(x,y,where) | 步阶图 | |
| plt.hist(x,bins,normed) | 直方图 |
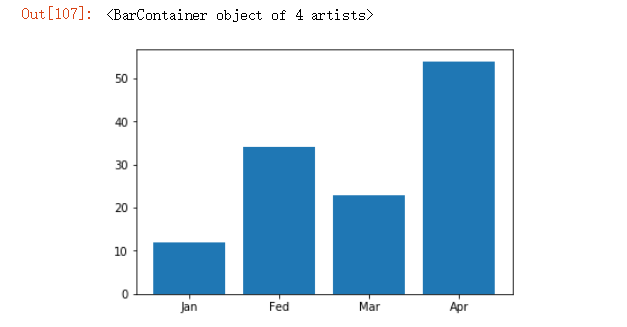
# 柱状图
data = [12,34,23,54]
labels = ['Jan','Fed','Mar','Apr']
plt.xticks([0,1,2,3],labels) # 设置x轴刻度
plt.bar([0,1,2,3],data)
# 横向柱状图
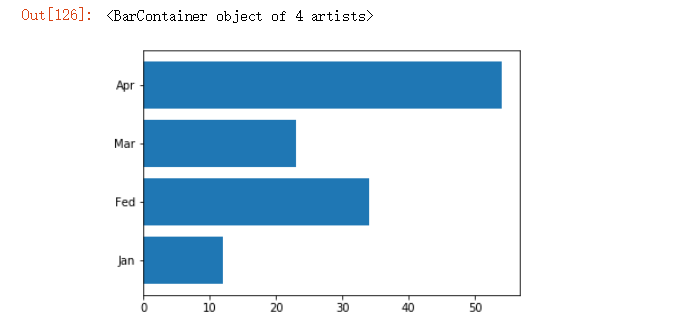
data = [12,34,23,54]
labels = ['Jan','Fed','Mar','Apr']
plt.yticks([0,1,2,3],labels)
plt.barh([0,1,2,3],data)
# DataFrame数组图
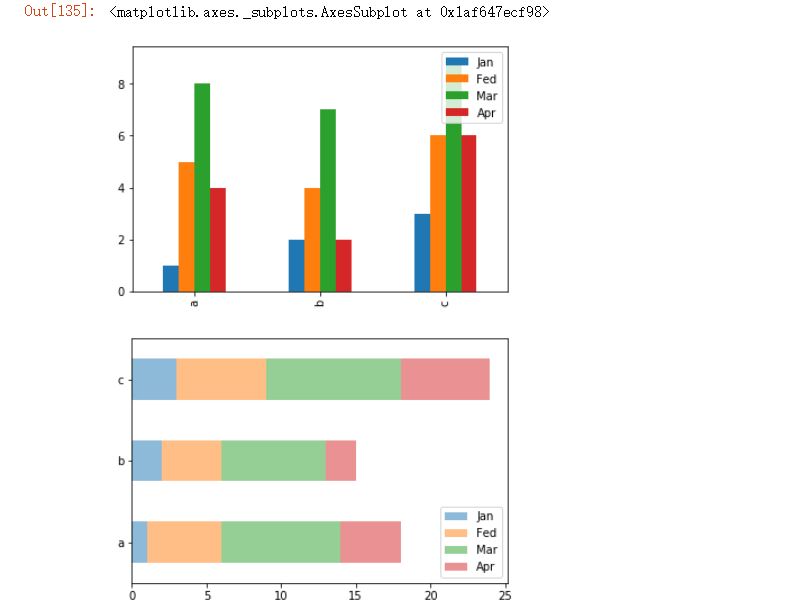
df = pd.DataFrame({
'Jan':pd.Series([1,2,3],index=['a','b','c']),
'Fed':pd.Series([4,5,6],index=['b','a','c']),
'Mar':pd.Series([7,8,9],index=['b','a','c']),
'Apr':pd.Series([2,4,6],index=['b','a','c'])
})
df.plot.bar() # 水平柱状图,将每一行中的值分组到并排的柱子中的一组
df.plot.barh(stacked=True,alpha=0.5) # 横向柱状图,将每一行的值堆积到一起,#前者控制是否堆积在同一行,后者控制透明度
# 饼图
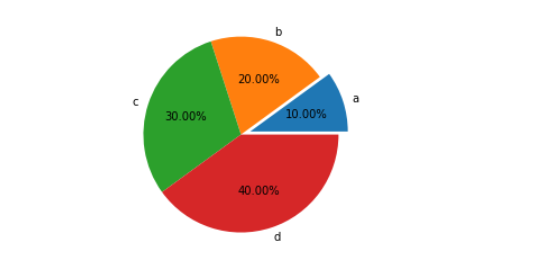
plt.pie([10,20,30,40],labels=list('abcd'),autopct="%.2f%%",explode=[0.1,0,0,0]) # 饼图,第一个字母(即‘a’)突出0.1
plt.axis("equal")#控制是个正圆,否则是一个椭圆
plt.show()
# 散点图
import random
x = np.random.randn(100)
y = np.random.randn(100)
plt.scatter(x,y)
5、保存图表到文件
plt.savafig('文件名.拓展名')
文件类型是通过文件扩展名推断出来的。因此,如果你使用的是.pdf,就会得到一个PDF文件。
plt.savefig('123.pdf')
savefig并非一定要写入磁盘,也可以写入任何文件型的对象,比如BytesIO:
from io import BytesIO
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
| 参数 | 说明 | |
|---|---|---|
| fname | 含有文件路径的字符串或者Python的文件型对象。 | |
| dpi | 图像分辨率,默认为100 | |
| format | 显示设置文件格式("png","jpg","pdf","svg","ps",...) | |
| facecolor、edgecolor | 背景色,默认为"W"(白色) | |
| bbox_inches | 图表需要保存的部分。设置为”tight“,则尝试剪除图表周围空白部分 |

