数据的预处理(标准化、归一化)
在机器学习回归问题,以及训练神经网络过程中,通常需要对原始数据进行中心化(零均值化)与标准化(归一化)处理。
1背景
在数据挖掘数据处理过程中,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
2目的
通过中心化和标准化处理,最终得到均值为0,标准差为1的服从标准正态分布的数据。可以取消由于量纲不同、自身变异或者数值相差较大所引起的误差。
3原理
中心化(又叫零均值化):是指变量减去它的均值。其实就是一个平移的过程,平移后所有数据的中心是(0,0)。
标准化(又叫归一化): 是指数值减去均值,再除以标准差。
4意义 - 为何需要这些预处理
在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。比如在预测房价的问题中,影响房价的因素(特征)有房子面积、卧室数量等,很显然,这些特征的量纲和数值得量级都是不一样的,在预测房价时,如果直接使用原始的数据值,那么他们对房价的影响程度将是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
下图中以二维数据为例:左图表示的是原始数据;中间的是中心化后的数据,数据被移动大原点周围;右图将中心化后的数据除以标准差,得到为标准化的数据,可以看出每个维度上的尺度是一致的(红色线段的长度表示尺度)。
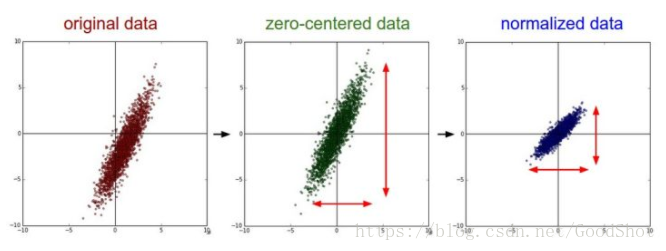
其实,在不同的问题中,中心化和标准化有着不同的意义,比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。对数据进行中心化预处理,这样做的目的是要增加基向量的正交性。
5标准化(归一化)优点及其方法
标准化(归一化)两个优点:
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度。
标准化(归一化)两种方法:
1)min-max标准化(Min-MaxNormalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到 [0 - 1] 之间。转换函数如下:
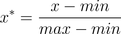
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
2)Z-score标准化(0-1标准化)方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。
转化函数为:
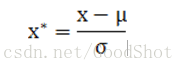
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
6中心化 -PCA示例
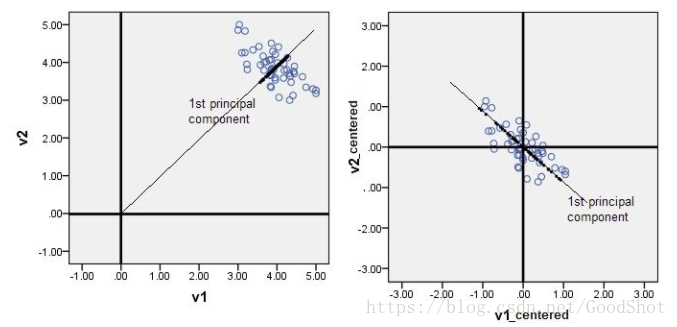
在做PCA的时候,我们需要找出矩阵的特征向量,也就是主成分(PC)。比如说找到的第一个特征向量是a = [1, 2],a在坐标平面上就是从原点出发到点 (1,2)的一个向量。
如果没有对数据做中心化,那算出来的第一主成分的方向可能就不是一个可以“描述”(或者说“概括”)数据的方向(看图)。
黑色线就是第一主成分的方向。只有中心化数据之后,计算得到的方向才能比较好的“概括”原来的数据(图2)。
转 王强

 浙公网安备 33010602011771号
浙公网安备 33010602011771号