18.4 SQL Server事务与锁详解之(锁篇)
SQL Server事务与锁详解之(下篇)- 锁
简介
SQL Server中的锁是用来同步用户对数据的访问的。
大家在多线程编程时,当多个线程要访问同一个资源时,一般都需要对资源进行加锁,保证线程一个一个的访问数据,即线程同步,这样就可以保证多个线程对资源的访问是安全的。
SQL Server中的锁也是这样的,每个用户查询对应一个线程,当多个用户要访问同一个数据时,就需要对数据进行加锁,这样就可以保证多个用户对数据的访问是安全的。本文将介绍SQL Server中的锁的相关知识。
事务在访问数据之前,为了保证不受其他事务的干扰,需要请求对数据进行锁定。
锁有多种类型,比如共享锁和排他锁。如果一个事务已经获得了数据上某特定的锁,那么其他事务就不能再获得会与该锁发生冲突的锁,直到该事务释放了该锁,这个叫锁的兼容性。
当事务修改某数据时,无论什么隔离级别,都会持有保护它修改数据的锁,直到事务提交或回滚。事务的隔离级别决定了事务持有保护读取数据的锁的时间。
我们的应用程序一般不直接请求锁,锁是由SQL Server的锁管理器自动管理的。当执行一个事务时,SQL Server查询处理器先确定要访问的资源,然后会根据事务的隔离级别、SQL语句访问类型向锁管理器请求适当的锁,如果请求的锁与其他事务持有的锁不会发生冲突,则授予该锁,若发生冲突,则会被阻塞。
锁粒度和层次结构
SQL Server可以让事务锁定不同的资源,比如表、行、页、键范围、索引等。
锁的粒度越小,锁的数量越多,并发越高,但是锁的开销也就越大,比如锁定在较小粒度的行上,如果一个SQL需要访问很多行,则需要持有大量的锁,每把锁的开销大概是96kb,如果需要访问10000行,则需要持有10000+
把锁,这样就会消耗很多的内存。
锁的粒度越大,锁的数量越少,但是并发就会降低,比如锁定在较大粒度的表上,因为锁住整个表导致了其他事务对表中任意部分的访问。 但开销较低,因为需要维护的锁较少。
什么是锁的层次结构呢?
SQL Server通常需要获取多个级别的锁才能完全保护资源, 这组多粒度级别上的锁就称为锁层次结构。
比如,当一个事务要更新一个表中的一行时,SQL Server会先获取表上的意向排他锁(IX),然后再获取行级别上的排他锁(X),还要获取索引上行的排他锁等,最后才能更新数据。
SQL Server可以锁定的资源如下:
| 名称 | 资源 | 格式 | 说明 |
|---|---|---|---|
| 数据行 | RID | File:Page:RowId 如: 1:6666:2 | 表示堆中的单个数据行,表没建立聚集索引时,通过锁住RID锁行,否则锁索引键 |
| 索引键 | KEY | 哈希值 如:fb00a499286b | 表示索引中的单个行,通过锁住KEY锁行 |
| 页 | PAGE | File:Page 如: 1:6666 | 表示数据页或索引页,一页8kb |
| 范围 | extent | File:Pages 如: 1:6666-6673 | 表示一组页,一般是8页,就是64kb |
| 堆或者B树 | HoBT(Heap or a B-tree) | 堆或 B 树。 用于保护没有聚集索引的表中的 B 树(索引)或堆数据页的锁。 | |
| 表 | object | objectId 如: 1256745671 | 表示整个表(包含所有数据和索引) |
| 文件 | file | FileId 如: 1 | 表示数据库文件,比如创建、增加和删除文件等操作会锁表 |
| 数据库 | database | databaseId 如: 3 | 表示整个数据库,比如修改数据库选项时,会锁数据库 |
我们可以通过查询sys.dm_tran_locks视图或sp_lock来查看当前事务锁定的资源。
比如通过sys.dm_tran_locks:
USE SampleDb;
GO
begin tran
update account set Money=1000 where id=1
--insert into account values(2000,'赵六')
select * from sys.dm_tran_locks where request_session_id=@@SPID
commit tran
执行结果如下:
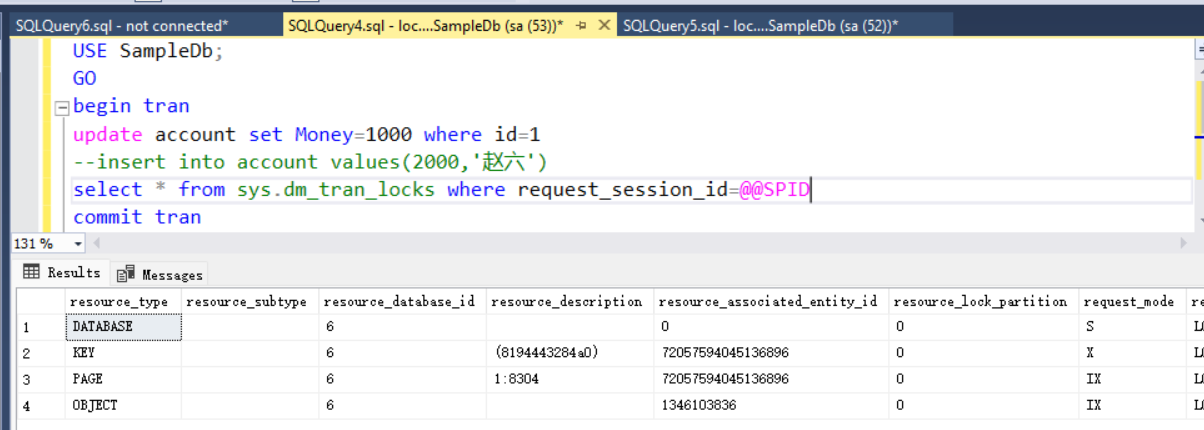
我们更新了一行数据,可以看到,事务在表(OBJECT)和页(PAGE)上各加了一把意向排他锁(IX),因为表account有主键聚集索引,所以通过在索引的键(KEY)上加了一把排他锁(X)锁住行,否则就锁住堆中的数据行(RID)。
或者:
USE SampleDb;
GO
begin tran
update account set Money=1000 where id=1
--insert into account values(2000,'赵六')
select tl.resource_type AS '锁资源类型',
OBJECT_NAME(p.object_id) AS '锁的对象',
p.partition_id AS '锁的分区ID',
tl.request_mode AS '请求模式',
tl.request_type AS '请求类型',
tl.request_status AS '请求状态' from sys.dm_tran_locks AS tl
INNER JOIN sys.partitions AS p ON tl.resource_associated_entity_id = p.hobt_id where request_session_id=@@SPID
commit tran
锁模式
SQL Server中的锁模式有以下几种:
| 锁模式 | 说明 |
|---|---|
| S | 共享锁,允许其他事务读取数据,但不允许修改数据,用于不更改或不更新数据的读取操作,如 SELECT 语句。 |
| X | 排他锁,不允许其他事务读取和修改数据,用于更新数据的操作,如 UPDATE、DELETE、INSERT 语句。确保多个事务不会同时对同一资源进行多重更新修改 |
| U | 更新锁,它是S与X锁的混合,更新实际操作是先查出所需的数据,此时为S锁,为了保护这数据不会被其它事务修改,加上U锁,在真正开始更新时,自动转成X锁。U锁和S锁兼容, 但X锁和U锁不兼容。 |
| 意向锁 | 用于建立锁的层次结构。 意向锁包含三种类型:意向共享 (IS)、意向排他 (IX) 和意向排他共享 (SIX)。 |
| 架构锁 | 用于保护数据库架构的锁。 |
| 大容量更新 (BU) | 用于保护大容量更新的锁。在将数据大容量复制到表中且指定了 TABLOCK 提示时使用。 |
| 键范围锁 | 当使用串行化(Serializable) 事务隔离级别时保护查询读取的行的范围。 确保再次运行查询时其他事务无法插入符合串行化事务的查询的行。 |
共享锁(S)
共享锁(S 锁)允许并发事务在并发控制下读取 (SELECT) 资源。 资源上存在共享锁(S 锁)时,任何其他事务都不能修改数据。
读取操作一完成,就立即释放资源上的共享锁(S 锁),除非将事务隔离级别设置为可重复读或更高级别,或者在事务持续时间内用锁定提示保留共享锁(S 锁),比如:
begin tran
SELECT * FROM table_name WITH (HOLDLOCK)
--其他SQL
commit tran
这样事务从开始到结束都会持有表上的共享锁(S 锁),这相当于串行化隔离级别。
排他锁(X)
排他锁(X 锁)允许并发事务在并发控制下修改 (UPDATE、DELETE、INSERT) 资源。 资源上存在排他锁(X 锁)时,任何其他事务都不能修改数据。仅在使用 NOLOCK 提示或未提交读隔离级别时才会进行读取操作,因为此时的读取操作不会加锁,也就不会与资源上的排他锁冲突。
更新锁(U)
更新锁(U 锁)是共享锁(S 锁)和排他锁(X 锁)的混合。更新锁(U 锁)允许并发事务在并发控制下读取 (SELECT) 资源。 资源上存在更新锁(U 锁)时,任何其他事务都不能修改数据。
更新锁(U 锁)的使用场景是:先查出所需的数据,此时为共享锁(S 锁),为了保护这数据不会被其它事务修改,加上更新锁(U 锁),在真正开始更新时,自动转成排他锁(X 锁)。更新锁(U 锁)和共享锁(S 锁)兼容, 但排他锁(X 锁)和更新锁(U 锁)不兼容。
更新锁可以防止常见的死锁,比如在可重复读和串行化隔离级别下,事务 A 读取数据(S锁),事务 B 读取同一数据(S锁),事务 A 更新数据需要申请排他锁(U锁),但是数据上存在事务B的S锁,S锁与X锁冲突,所以事务B会被阻塞,事务 B 更新数据也要申请排他锁(U锁),也被阻塞,这时事务 A 和事务 B 都会相互阻塞,等待对方释放锁,造成死锁。
上述发生死锁示例SQL:
事务1:先执行如下事务1,10秒内执行事务2
set transaction isolation level Repeatable Read--设置事务隔离级别为可重复读
begin tran
SELECT * FROM account where Id=1--读取数据,申请共享锁(S 锁)
waitfor delay '00:00:10'--等待10秒,等待事务2执行查询
Update account set UserName='张三' where Id=1--更新数据,试图将S锁转换成排他锁(X 锁)
--其他SQL
commit tran
事务2:
set transaction isolation level Repeatable Read--设置事务隔离级别为可重复读
begin tran
SELECT * FROM account where Id=1--读取数据,申请共享锁(S 锁)
waitfor delay '00:00:10'--等待10秒
Update account set UserName='张三' where Id=1--更新数据,试图将S锁转换成排他锁(X 锁)
commit tran
执行顺序:
| 事务1 | 事务2 |
|---|---|
| 读取数据,申请共享锁(S 锁) | |
| 读取数据,申请共享锁(S 锁) | |
| 更新数据,试图将S锁转换成排他锁(X 锁),被事务2阻塞 | |
| 更新数据,试图将S锁转换成排他锁(X 锁),被事务1阻塞 | |
| 相互阻塞,造成死锁 |
若在类似要先读取数据再更新数据的事务中,使用了更新锁(U 锁),则不会发生死锁:
事务1:
set transaction isolation level Repeatable Read--设置事务隔离级别为可重复读
begin tran
SELECT * FROM account with (updlock) where Id=1--读取数据,申请更新锁(U 锁),此时为S锁
waitfor delay '00:00:10'--等待10秒,等待事务2执行查询
Update account set UserName='张三' where Id=1--此时将S锁转换成排他锁(X 锁)
commit tran
事务2:
set transaction isolation level Repeatable Read--设置事务隔离级别为可重复读
begin tran
SELECT * FROM account with (updlock) where Id=1--读取数据,申请更新锁(U 锁),此时为S锁
waitfor delay '00:00:10'--等待10秒
Update account set UserName='张三' where Id=1--此时将S锁转换成排他锁(X 锁)
commit tran
执行顺序:
| 事务1 | 事务2 |
|---|---|
| 读取数据,申请更新锁(U 锁),此时为S锁(其他事务可以读取数据) | |
| 读取数据,尝试申请更新锁(U 锁),与事务1的更新锁不兼容,被阻塞 | |
| 更新数据,将S锁转换成排他锁(X 锁) | |
| 提交事务,释放持有的锁 | |
| 成功申请到更新锁(U锁) | |
| 更新数据,将S锁转换成排他锁(X 锁) | |
| 提交事务,释放持有的锁 |
这样一来,事务2就会等到事务1执行完毕再执行,就不会发生死锁了。
意向锁(I)
意向锁(I 锁)是为了用来保护将共享锁(S锁)或排他锁(X锁)放置锁层次结构中较低资源上的锁。相当于只是一种标志,不是真正的锁。
根据名字“意向锁”,用大白话来说就是“我想要锁住这个资源,但是我还没有锁住,所以我先标记一下,其他事务看到这个标记,就不会做一些冲突的操作了”。
比如,我想在表中某些行上加排他锁(X锁),我在行上加排他锁之前,我先在表上加个意向锁排他锁(IX锁),表示我有将表里边数据加排他锁(X锁)的意向,然后再在行上加排他锁(X锁),其他事务如果想要在表上加共享锁或者排他锁甚至修改表结构之类的冲突操作,看到表上有我的意向排他锁(IX锁),就知道表中的数据有被上X锁,因此不需要去检查表中的行有没有被锁,这样也就提高了效率。
所以意向锁有两个作用:
- 防止其他事务以会使较低级别的锁无效的方式修改较高级别资源。
- 提高SQL Server数据库引擎在更高粒度级别检测锁冲突的效率。
意向锁主要有如下几种:
| 锁模式 | 说明 |
|---|---|
| 意向共享(IS) | 用于保护层次结构中较低级别资源获取共享锁(S锁) |
| 意向排他(IX) | 用于保护层次结构中较低级别资源获取排他锁(X锁)和共享锁(S锁) |
| 意向排他共享(SIX) | 保护锁层次结构中某些低层资源请求或获取共享锁以及针对某些低层资源请求或获取意向排他锁。顶级资源允许使用并发IS锁。例如,获取表上的SIX锁也将获取正在修改的页上的意向排他锁以及修改的行上的排他锁。虽然每个资源在一段时间内只能有一个 SIX锁,以防止其他事务对资源进行更新,但是其他事务可以通过获取表级的IS锁来读取层次结构中的低层资源。 |
| 意向更新(IU) | 用于保护层次结构中较低级别资源获取更新锁(U锁),仅在页资源上使用 IU 锁。 如果进行了更新操作,IU 锁将转换为 IX 锁。 |
架构锁
SQL Server数据库引擎在表数据定义语言 (DDL) 操作(例如添加列或删除表)期间会使用架构修改 (Sch-M) 锁。 持有锁期间,Sch-M 锁将阻止其他用户对表进行并发访问。 这意味着 Sch-M 锁在释放前将阻止所有外围操作。
SQL Server数据库引擎在编译和执行查询时, 使用架构稳定 锁(Sch-S)。 Sch-S 锁不会阻止某些事务锁,其中包括排他 (X) 锁。 因此,在编译查询的过程中,其他事务(包括那些针对表使用 X 锁的事务)将继续运行。 但是,无法针对表执行获取 Sch-M 锁的并发 DDL 操作和并发 DML 操作。
大容量更新锁
大容量更新锁(Bulk Update Lock),允许多个线程将数据并发地大容量加载到同一表,同时防止其他不进行大容量加载数据的进程访问该表。 当以下两个条件都成立时,SQL Server数据库引擎使用此锁。
- 使用
BULK INSERT语句将或者OPENROWSET(BULK)函数,或者使用大容量插入API命令,比如 .Net的SqlBulkCopy,OLEDB的Fast Load APIs等等。 - 指定了
TABLOCK表提示或者使用sp_tableoption设置了table lock on bulk load选项。
键范围锁
键范围锁在使用串行化事务隔离级别时,保护由 T-SQL 语句读取的记录集中隐式包含的行范围。 键范围锁可防止虚拟读取。 通过保护行之间键的范围,它还防止对事务访问的记录集进行虚拟插入或删除。
详情请参见:键范围锁
锁兼容性
在 SQL Server 中,锁兼容性是指在同一资源上可以同时存在的锁的类型。
例如,如果一个事务在表上持有共享锁(S锁),另一个事务可以在表上持有共享锁(S锁),和更新锁(U锁),但不能持有排他锁(X锁)。
排他锁与任何锁都不兼容,因此如果一个事务在表上持有排他锁,另一个事务不能在表上持有任何锁。
下表是常见的锁兼容性。
| 资源上现有的锁类型 | IS | S | U | IX | SIX | X |
|---|---|---|---|---|---|---|
| 请求的锁类型 | ||||||
| 意向共享(IS) | Y | Y | Y | Y | Y | X |
| 共享(S) | Y | Y | Y | X | X | X |
| 更新(U) | Y | Y | X | X | X | X |
| 意向排他(IX) | Y | X | X | Y | X | X |
| 意向共享排他(SIX) | Y | X | X | X | X | X |
| 排他(U) | X | X | X | X | X | X |
注意,意向排他锁(IX)与意向排他锁兼容(IX),因为IX只打算更新部分行而不是所有行,还允许其他事务读取或更新其他部分行。如果两个事务尝试更新同一行,两个事务都会在表级和页级上IX锁,但是只有一个事务会在行级上X锁,另一个事务会必须等待这个行上X锁释放。
事务隔离级别与锁
首先,要记住一点,无论什么隔离级别,即使是最低的读未提交(Read Uncommitted),亦或者是快照隔离级别,事务在更新或者删除数据时(Update,delete),都会在数据上加排他锁,并且持续到事务结束。这样可以防止其他事务同时在这个数据上进行更新或者删除。
然后不同的隔离级别,会对读操作加不同的共享锁,以保证读到的数据是符合隔离级别要求的。
可以使用如下语句查看当前事务占用的锁
select * from sys.dm_tran_locks where request_session_id=@@SPID
比如:
USE SampleDb;
GO
SET TRANSACTION ISOLATION LEVEL repeatable read;--设置事务的隔离级别为可重复读
begin tran
select * from account where Id=1
update account set Money=1500 where Id=2;
select * from sys.dm_tran_locks where request_session_id=@@SPID--查看当前事务占用的锁
rollback tran

下面是不同隔离级别下,读操作加的锁。
读未提交(Read Uncommitted)
读未提交(Read Uncommitted)是最低的隔离级别,这个隔离界别下,事务对数据的读取(SELECT)是不会加共享锁(S锁)的。因此可以读取几乎任何状态的数据,比如可以读取有排他锁(X锁)的数据,也可以读取有共享锁(S锁)的数据。这样就会导致脏读(Dirty Read)的问题。
演示:
一个窗口执行如下事务1,先不提交:
use SampleDb
Go
begin tran
update account set Money=1500 where Id=1--更新account表的Id=1的行,添加排他锁(X锁)
select * from sys.dm_tran_locks where request_session_id=@@SPID--查看当前事务占用的锁

可以看到,事务获取了account表行1的排他锁(X锁)。以及表和页上的意向排他锁(IX锁)。
另一个窗口执行如下事务2进行查询:
use SampleDb
Go
set transaction isolation level Read UnCommitted--设置事务的隔离级别为读未提交
begin tran
select * from account where Id=1--查询account表的Id=1的行
select * from sys.dm_tran_locks where request_session_id=@@SPID--查看当前事务占用的锁
commit

可以看到,事务成功读取到了数据,没有被阻塞。
因为这个隔离级别下的事务,读取数据根本就不加共享锁。
最后提交事务1:
commit
读已提交(Read Committed)
读已提交(Read Committed)是默认的隔离级别,这个隔离级别下,事务对数据的读取(SELECT)会申请共享锁(S锁),但是一旦读取完成,即SELECT语句执行完,就会立即释放这个共享锁(S锁)。
如果其他事务对这个数据进行了更新(UPDATE,DELETE),那么,在其他事务提交之前,数据上就会有其他事务的排他锁,该读取数据的事务要申请相同数据的共享锁(S锁)就会被阻塞,这样就可以避免脏读(Dirty Read)的问题。
演示:
一个窗口执行如下事务1,先不提交:
use SampleDb
Go
begin tran
update account set Money=1500 where Id=1
select * from sys.dm_tran_locks where request_session_id=@@SPID
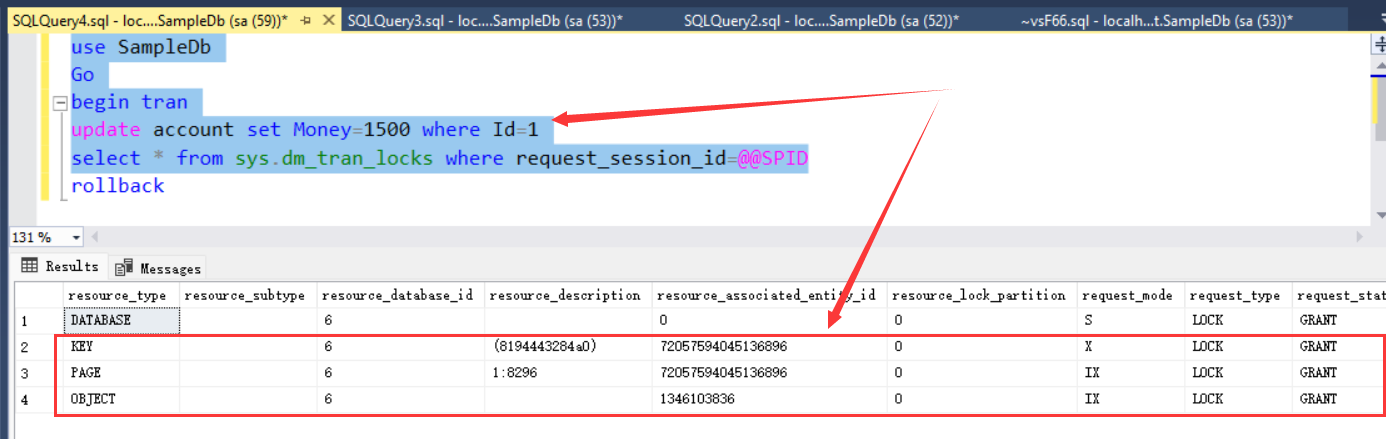
同样可以看到,事务获取了account表行1的排他锁(X锁)。
另一个窗口执行如下事务2进行查询:
use SampleDb
Go
set transaction isolation level Read Committed--设置事务的隔离级别为读已提交
begin tran
select * from account where Id=1--查询account表的Id=1的行,申请共享锁(S锁),被阻塞
select * from sys.dm_tran_locks where request_session_id=@@SPID
commit

可以看到,事务被阻塞了,因为事务1还没有提交,资源上存在事务1的排他锁(X锁),因此事务2申请共享锁(S锁)被阻塞了。
直到事务1提交事务,然后释放account表行1的排他锁(X锁),事务2才能成功获取account表行1的共享锁(S锁),最终结束阻塞,读取到数据。
可重复读(Repeatable Read)
可重复读(Repeatable Read)隔离级别下,事务对数据的查询(SELECT)会申请共享锁(S锁),但是查询完成后,不会立即释放这个共享锁(S锁),而是在事务提交之前一直持有这个共享锁(S锁)。这样在事务提交之前,其他事务就不能修改同一数据,修改同一数据的事务需要申请排他锁(X锁),就会被阻塞,不可重复读(Nonrepeatable Read)的问题,同时也避免脏读问题。
演示:
一个窗口执行如下事务1:
use SampleDb
Go
set transaction isolation level Repeatable Read--设置事务的隔离级别为可重复读
begin tran
select * from account where Id=1--查询account表的Id=1的行,申请共享锁(S锁)
waitfor delay '00:00:02'--等待2秒
commit
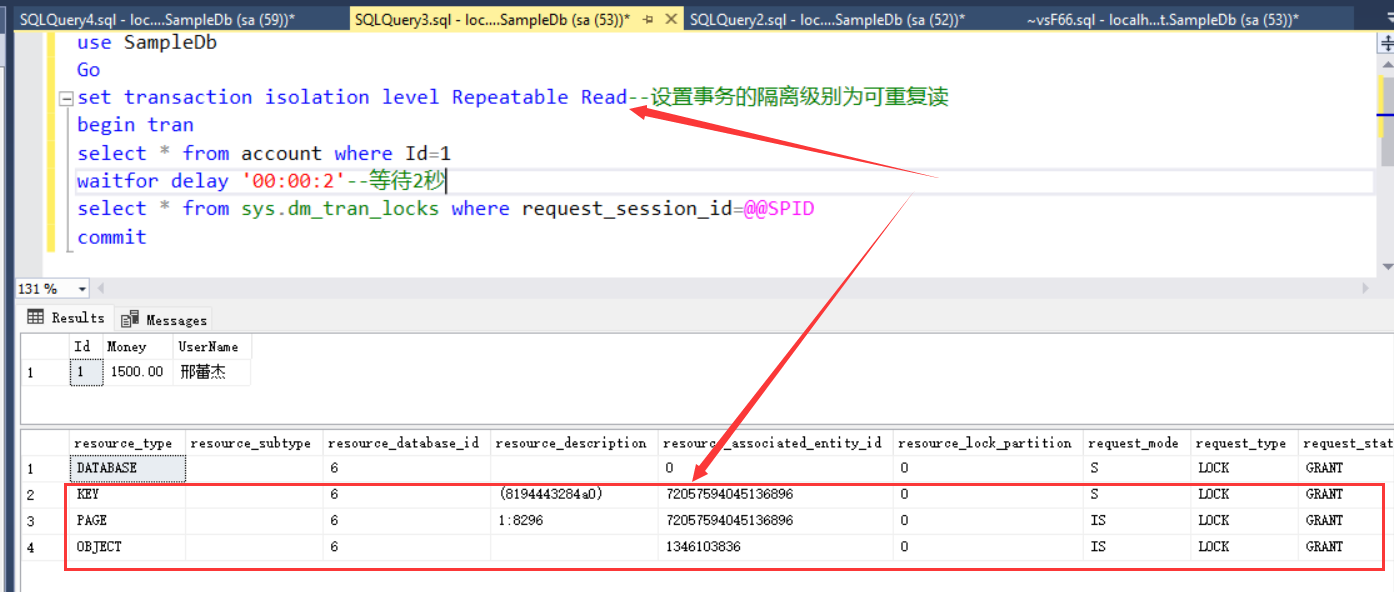
可以看到,事务在读取数据后,不会立即释放共享锁(S锁),而是在事务提交之前一直持有这个共享锁(S锁)。
串行化(Serializable)
串行化(Serializable)隔离级别下,事务对数据的查询(SELECT)会申请键范围共享锁(RangS-S),也会持续到事务提交之前。
键范围会锁定一个范围内的所有行,比如:
use SampleDb
Go
set transaction isolation level Serializable--设置事务的隔离级别为串行化
begin tran
select * from account where Id <100--查询account表的Id<100的行,申请共享锁(S锁)和键范围锁(Key Range Lock)
waitfor delay '00:00:05'--等待5秒
select * from account where Id <100--再次查询到的数据还是一样的。
commit
上面查询语句中,where Id<100会使用键范围锁(Key Range Lock)锁定Id小于100的所有行,假设只有50行,在事务等待的5秒钟之类,如果其他事务想要插入Id小于100的行,就会被阻塞,直到该事务提交,因此解决了幻读(多次读取数据条数不一致)问题,但是其他事务可以插入Id>=100的行。
演示:
执行如下事务1:
use SampleDb
Go
set transaction isolation level Serializable--设置事务的隔离级别为可重复读
begin tran
select * from account where Id<10
select * from sys.dm_tran_locks where request_session_id=@@SPID
commit
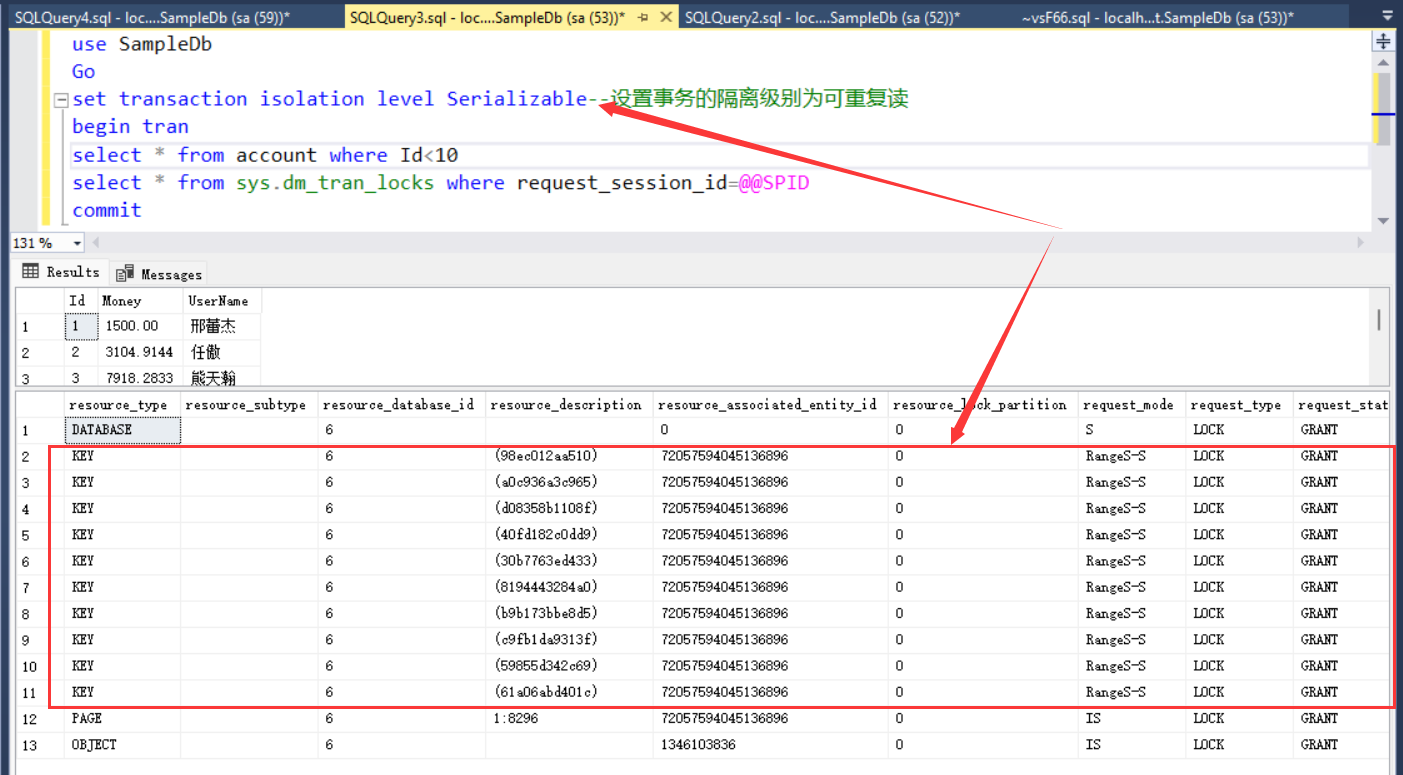
可以看到事务对Id<10的行申请了键范围锁(Key Range Lock)。
关于键范围锁详细介绍可以参考:SQL Server 键范围锁(Key Range Lock)
锁升级
简介
锁升级是将大量细粒度的锁升级为数量少的较粗粒度的锁。使用低级锁(如行锁)可以降低两个事务同时在相同数据块上请求锁的可能性,从而提高并发性。使用低级锁还会增加锁的数量以及管理锁所需的资源。升级为高级表锁或页锁可以减少开销,但代价是降低了并发性,一旦升级为表级X锁,其他任何事务都不能访问表了。
当需要锁升级时,SQL Server会尝试将表上的意向锁更改为相应的完整锁,比如将表上的意向共享锁(IS)更改为共享锁(S)。一旦升级成功,获取了全表锁,将释放事务在行级、页级以及索引上的所有锁。如果当时无法升级,SQL Server会继续获取细粒度的锁,后续还会继续尝试升级。
SQL Server会直接将行锁和键范围锁升级为表锁,而不是先升级为页锁,页锁也直接升级为表锁。
锁升级阈值
默认情况下,满足下列任一条件,将自动触发锁升级:
- 单个T-SQL语句在单个非分区表或索引上获取至少5000个锁。
- 单个T-SQL语句在分区表的单个分区上获取了至少5000个锁。并且
ALTER TABLE SET LOCK_ESCALATION选项设置为AUTO。 - SQL Server实例中的锁对象使用的内存超过内存或配置阈值,默认是数据库引擎使用内存的24%。
如果由于并发事务的锁冲突而无法升级锁,SQL Server会定期在每获取 1250 个新锁时触发锁升级。
注意,只有当一个SQL语句在单个表上引用了超过5000个锁,才会触发锁升级。如果一个SQL语句在A表上引用了4000个锁,而在B表上引用了4000个锁,这个时候不会触发锁升级。
减少锁和锁升级
在大部分情况下,使用SQL Server默认设置就可以了。如果数据库中生成了大量的锁,并且看到频繁的锁升级,或者特殊情况需要阻止锁升级,可以考虑以下几种方法:
1)使用乐观并发隔离级别
对于数据读取操作,使用不会生成共享锁的隔离级别:读已提交快照(READ UNCOMMITTED SNAPSHOT)或快照(SNAPSHOT)。
2)使用更低的隔离级别
使用尽量低的隔离级别,比如允许脏读时,使用读未提交(READ UNCOMMITTED)。
3)通过表提示来使用更粗粒度的锁
使用PAGLOCK或TABLOCK表提示,来使用页、堆或者索引锁而不是大量的行锁,但是这样降低了并发,对于并发较多的系统,不推荐这个。
4)禁用锁升级或者修改锁升级到HoBT粒度而不是表
对于已经分区的表,使用 ALTER TABLE的LOCK_ESCALATION选项将锁升级到 HoBT 级别而不是表级别,或者禁用锁升级,不推荐禁用锁升级。
5)拆分大批量的操作(推荐)
将大批量的操作拆分成小批量的操作,比如将大批量的UPDATE操作拆分成小批量的UPDATE操作,这样减少单次SQL获取锁的数量至小于5000,避免锁升级。
比如删除account表中前8000条数据(Id从1-8000连续):
DELETE FROM account WHERE Id <= 8000;
根据前面的分析,这个语句会生成8000个行锁,会触发锁升级。实际上在行锁数量大于阈值的时候就触发升级了,所以这个语句会将行锁升级为表锁:
通过监控扩展事件lock_escalation可以查看执行此语句时锁升级的详细信息:
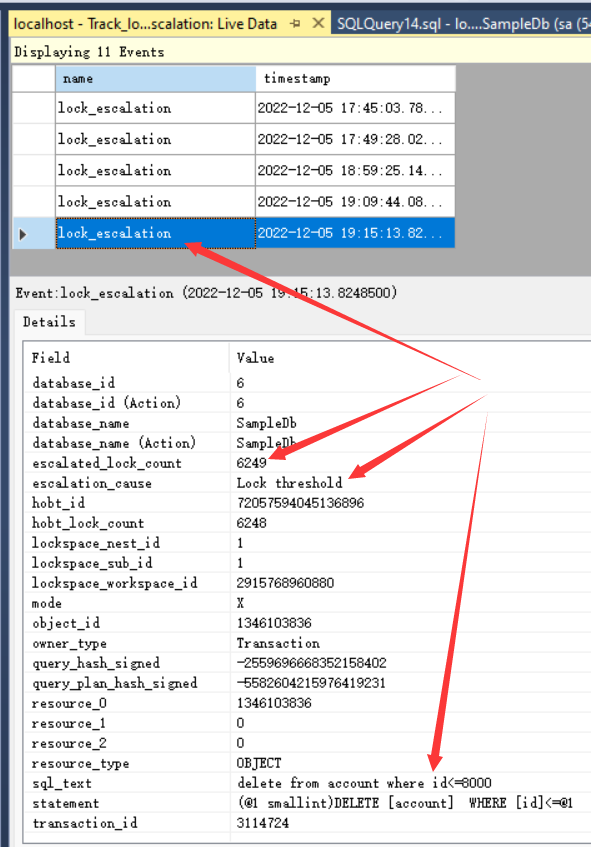
可以看到,锁升级,是发生在持有6249个锁(行锁+页锁)的时候,并不一定刚好是超过5000哈,大家可以在自己服务器上试试,然后锁升级的原因是Lock threshold(锁阈值)。然后下面的 statement是触发锁升级的SQL语句。
此扩展事件创建SQL:
-- Session creates a histogram of the number of lock escalations per database
CREATE EVENT SESSION [Track_lock_escalation] ON SERVER
ADD EVENT sqlserver.lock_escalation(SET collect_database_name=(1),collect_statement=(1)
ACTION(sqlserver.database_id,sqlserver.database_name,sqlserver.query_hash_signed,sqlserver.query_plan_hash_signed,sqlserver.sql_text,sqlserver.username))
ADD TARGET package0.histogram(SET source=N'sqlserver.database_id')
GO
关于扩展事件的使用参考:SQL Server 中的扩展事件。
通过如下方式:
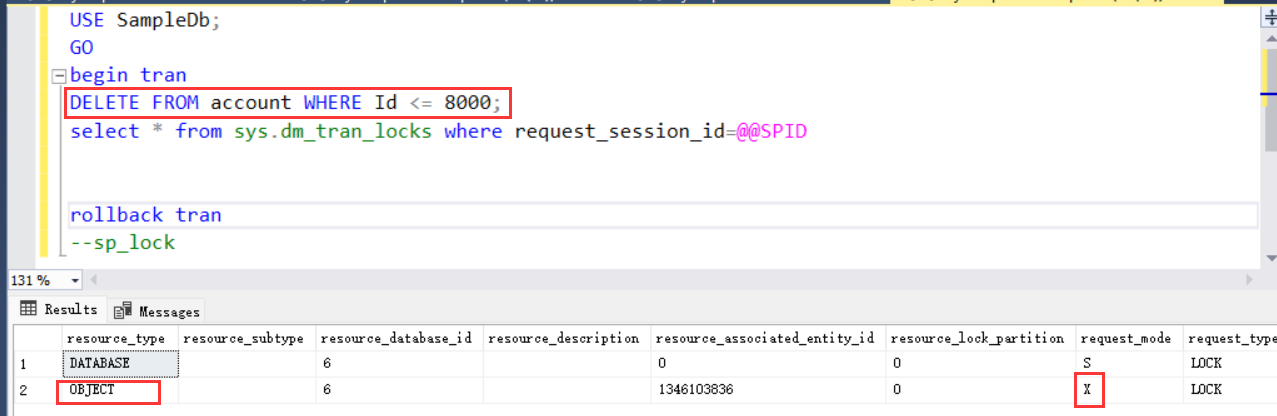
也可以看到,事务已经发生锁升级了,只有一把表上的排他锁了,而不是8000个行锁。
要避免这种情况的锁升级,可以分成两次删除,第一次删除Id小于4000的数据,第二次删除Id大于4000小于8000的数据。
DELETE FROM account WHERE Id <= 4000;
DELETE FROM account WHERE Id > 4000 AND Id <= 8000;
测试一下:
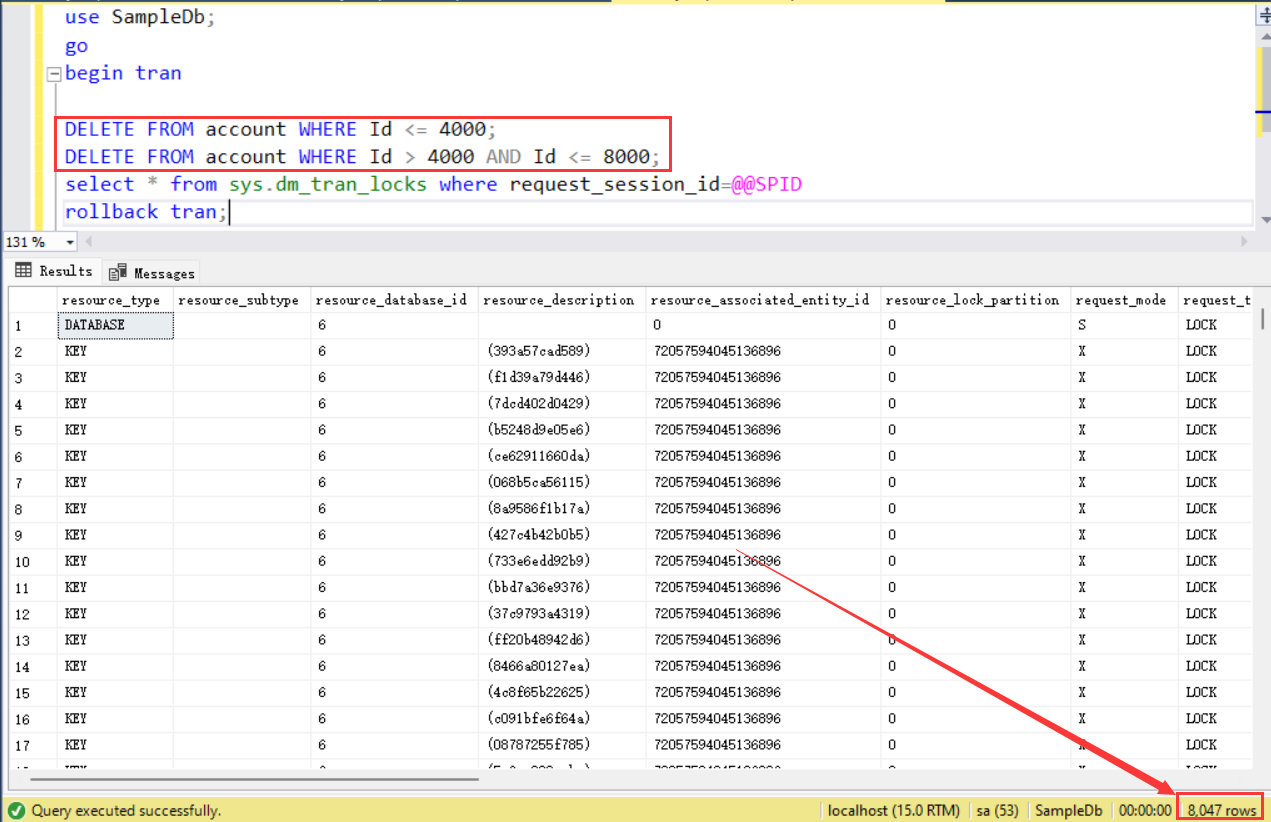
可以看到,这次没有发生锁升级,而是生成8000个行(KEY)锁和46个页(PAGE)锁,还有一个是数据库(DATABASE)共享锁,所以其实单个DELETE语句获取的锁的数量大概只有4000多,因此不会发生锁升级。
注意,是单个T-SQL获取同一张表上锁的数量大于5000才会发生锁升级,而不是事务获取锁的数量。
通用方式:
SET ROWCOUNT 1000--设置处理的行数,每次处理1000行
delete_more:
DELETE FROM account WHERE Id <= 8000--删除前8000条数据,已经限制单次处理的行数为1000,所以即使有更多满足条件的数据,这句SQL也只会删除1000行
IF @@ROWCOUNT > 0 GOTO delete_more--如果处理的行数大于0,继续处理
SET ROWCOUNT 0--恢复默认值
或者:
DECLARE @done bit = 0;
WHILE (@done = 0)
BEGIN
DELETE TOP(1000) FROM account WHERE Id <= 8000;
IF @@rowcount < 1000 SET @done = 1;
END;
这样就不会触发锁升级了,因为每次删除的数据量都小于5000,每次删除都只会获取低于5000个行锁。
6)查询优化
合理创建索引,优化SQL,减少索引扫描和全表扫描,最好是索引查找,但是这个短时间不能搞定。
7)通过其他事务持有不兼容表锁(推荐)
其他事务持有不兼容的表锁,也不会发生锁升级。比如有事务持有表上的意向更新锁(IX),虽然意向更新锁不会锁定任何行,但是与其他事务想要升级成的S锁和X锁不兼容,因此就能阻止不兼容的锁升级。
比如,有如下案例:
有一个批处理作业要修改或删除表中大量行,锁升级为表上的排他锁(X锁),导致其他所有用户都查询不了此表中的数据(读未提交隔离级别的事务除外)。如果知道该批处理能在一小时内执行完。就可以在批处理作业执行前几分钟执行以下SQL代码:
BEGIN TRAN
SELECT * FROM account WITH (UPDLOCK, HOLDLOCK) WHERE 1=0--获取表上的意向排他锁并持续到事务结束。
WAITFOR DELAY '1:00:00'
COMMIT TRAN
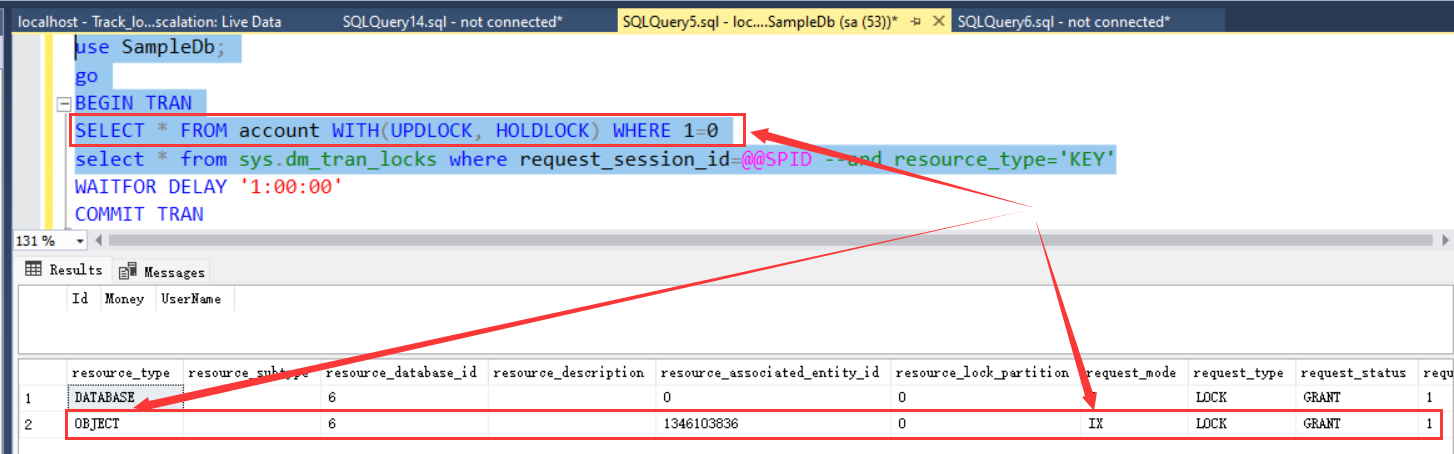
可以看到这个查询将获取account上的意向排他锁(IX),并持续一个小时,因此会阻止在这一个小时内的锁升级(除非其他查询使用TABLOCK提示强制执行表锁,或者管理员已使用 sp_indexoption 存储过程禁用了页锁
或行锁)。
表提示
简介
表提示用于替代查询优化器的默认行为,可以用于控制查询的执行方式,比如:使用索引、锁定表、锁定行、不使用锁等。表提示可以在SELECT、UPDATE、DELETE、INSERT语句中使用。
注意:由于 SQL Server 查询优化器通常会为查询选择最佳执行计划,如非迫不得已,不要使用表提示
语法:
SELECT * FROM table_name WITH (table_hint)
其中table_hint可以是以下值:
| 提示 | 说明 |
|---|---|
| NOLOCK | 不使用任何锁 |
| HOLDLOCK | 获取表上的共享锁(S锁),并持续到事务结束 |
| UPDLOCK | 获取表上的排他锁(X锁),并持续到事务结束 |
| TABLOCK | 获取表上的表锁(T锁),并持续到事务结束 |
| TABLOCKX | 获取表上的表锁(T锁),并持续到事务结束 |
| READCOMMITTED | 使用读已提交隔离级别 |
锁提示
锁提示属于表提示
可以在SELECT、INSERT、UPDATE及DELETE语句中为单个表使用锁提示,锁提示指定当前SQL语句对说操作数据使用的锁的类型。
注意:SQL Server数据库引擎几乎总是选择正确的锁定级别。 建议只在必要时才使用表级锁提示来更改默认的锁行为。
表提示会覆盖事务默认的锁行为
比如:
use SampleDb
Go
set transaction isolation level Serializable--设置事务的隔离级别为可重复读
begin tran
select * from account with (NOLOCK) where Id<10
select * from sys.dm_tran_locks where request_session_id=@@SPID
commit
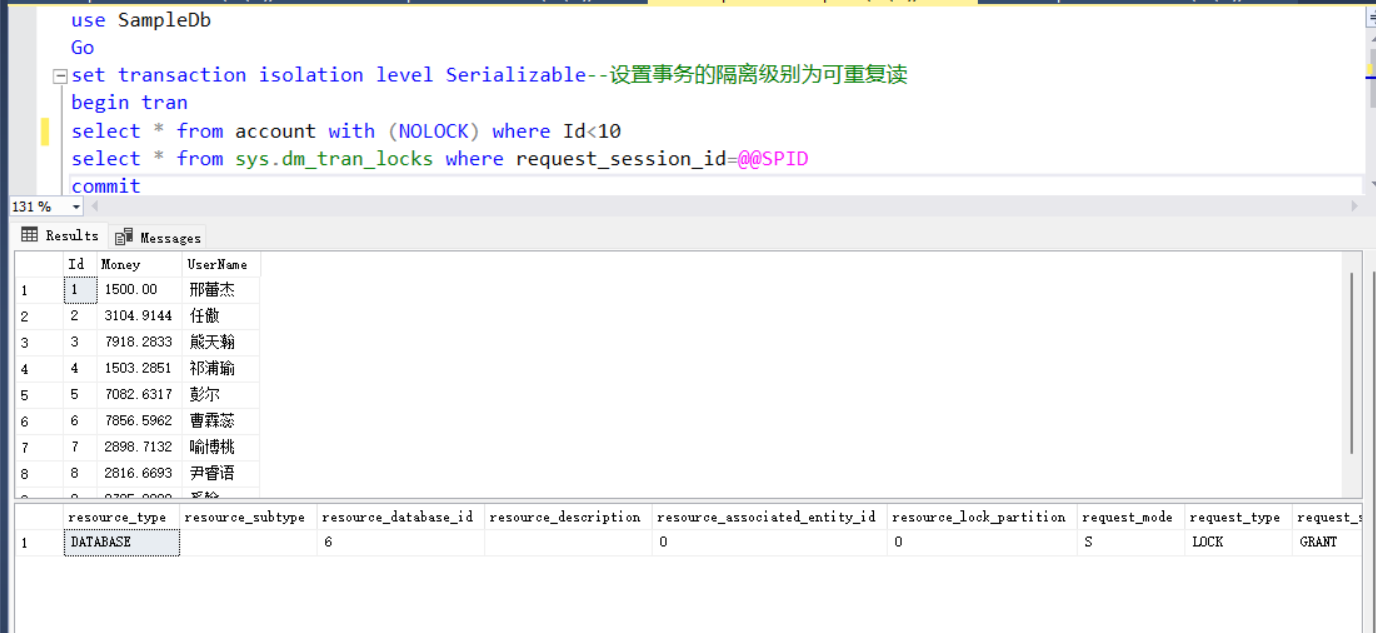
可以看到,上面的事务设置的隔离级别为可序列化读(Serializable),但是其中的查询并没有使用键范围锁,这是因为使用了锁提示with (NOLOCK)。NOLOCK锁提示使该查询语句不使用锁。
常见锁提示
NOLOCK
使查询不使用锁,等效于读已提交(READUNCOMMITTED)事务隔离级别,用于SELECT语句,使用NOLOCK提示的查询可以读取到其他事务修改但未提交的数据,即脏读。
HOLDLOCK
将持有的共享锁保持到事务结束。等效于串行化(SERIALIZABLE)隔离级别。
比如:
use SampleDb
Go
begin tran
select * from SampleDb with(HOLDLOCK) where id=1--持有共享锁并持续到事务结束
commit
ROWLOCK
强制使用行锁
PAGELOCK
此选项为默认选项, 当被选中时,SQL Server 使用共享页锁。
TABLOCK
指定在表级别获取锁,获取锁的类型取决于正在执行的语句,比如SELECT语句就会获取共享锁,UPDATE语句就会获取排他锁,使用TABLOCK就会将锁应用到整个表,而不是行或页级别。
如果同时指定了HOLDLOCK(持有锁),则会一直持有表锁,直至事务结束。
如:
use SampleDb
Go
begin tran
select * from SampleDb with (TABLOCK,HOLDLOCK) where Id<3--持有表上的共享锁并持续到事务结束
commit
TABLOCKX
此选项被选中时,SQL Server将在整个表上置排它锁直至该命令或事务结束。可以防止其他事务读取或修改表中的数据。
UPDLOCK(更新锁-U)
UPDLOCK指定语句采用更新锁并保持到事务完成。 UPDLOCK 仅对行级别或页级别的读操作采用更新锁。 如果将 UPDLOCK 与 TABLOCK 组合使用或出于一些其他原因采用表级锁,将采用表上的排他 (X) 锁。
如果一个事务中会同时涉及先读取数据,然后再修改数据的操作,使用更新锁会在一定程度上减少死锁。
XLOCK
指定采用排他锁并保持到事务完成。 如果同时指定了 ROWLOCK、PAGLOCK 或 TABLOCK,则排他锁将应用于相应的粒度级别。
死锁
简介
在多线程系统中,两个或多个任务(线程、会话、事务)因为资源(数据库对象、内存等)抢占而相互阻塞造成的永久阻塞情况。
如图:
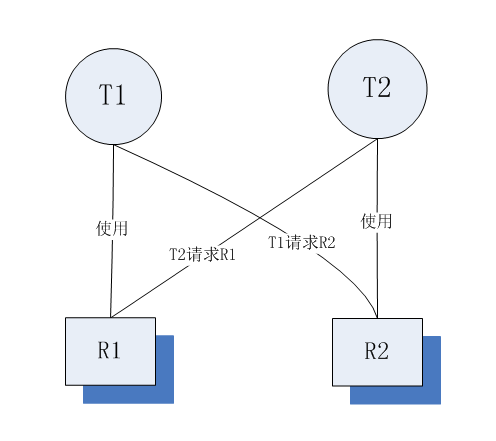
其中:
任务T1占用着资源R1,又需要请求资源R2。
任务T2占用着资源R2,又需要请求资源R1。
任务T1和T2都是正常推进,谁也不让谁,形成死锁。
比如:
- 事务A获取了行1的排他锁
- 事务B获取了行2的排他锁
- 事务A请求行2的锁,由于行2被事务B锁住了,所以被事务B阻塞。
- 事务B请求行1的锁,由于行1被事务A锁住了,所以被事务A阻塞。
- 相互阻塞形成死锁。
举个通俗易懂的例子:
两个人,一双筷子,一碗面,一开始一人拿到了一根筷子,但是都不愿意放下筷子,这样就形成了死锁。
死锁中的事务,会一直阻塞下去,直到锁超时(如果设置了LOCK_TIMEOUT的情况下)或者其中一个被数据库引擎杀死,被杀死的事务称为死锁牺牲者。
检测和结束死锁
数据库引擎会定期检测死锁,默认每隔5秒检测一次,如果死锁发生频率高,会自动缩短检测时间间隔最低至100毫秒,如果长时间没发现死锁,又会恢复至5秒。
如果发现死锁,会选择回退代价最低的事务进行回滚,也可以使用SET DEADLOCK_PRIORITY指定死锁优先级,可以是LOW、NORMAL、HIGH,默认是NORMAL,也可以将其设置为范围(-10 到 10)间的任一整数值。
如果两个事务的死锁优先级不同,则会选择优先级较低的事务作为牺牲者。 如果两个事务的死锁优先级相同,则会选择回滚开销最低的事务作为死锁牺牲者。 如果死锁事务的死锁优先级和开销都相同,则会随机选择死锁牺牲品。
被杀死的事务会抛出1205错误,并将有关信息记录在错误日志中,同时释放所有的锁以使陷入死锁的其他事务可以正常完成。客户端收到1205错误后,可以根据需要进行重试。
查看死锁信息
SQL Server可以通过system_health xEvent会话(死锁扩展事件)、跟踪1204和1222两个标志、以及最原始的SQL Profiler中的死锁图事件来查看死锁信息。
死锁扩展事件(xml_deadlock_report)
介绍
从SQL Server 2012 (11.x) 开始,就应该使用system_health会话中的xml_deadlock_report事件、或者单独建一个包含xml_deadlock_report事件的会话来查看死锁信息,而不是跟踪SQL标志和SQL Profiler中的死锁图事件来查看死锁信息。
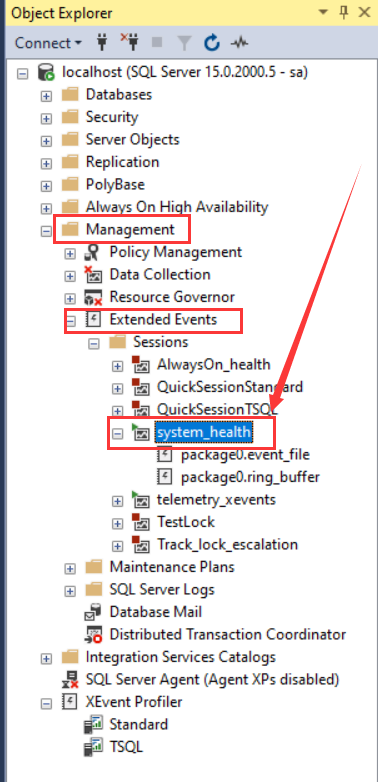
system_health会话是SQL Server默认包含的扩展事件会话。随数据库启动时启动。该会话会记录一些系统事件,可用于以后数据库性能分析和故障排除,其中就包括死锁事件(xml_deadlock_report),因此就不需要再单独配置一个会话来捕获死锁信息了。
如下目录下就可以看到system_health会话:
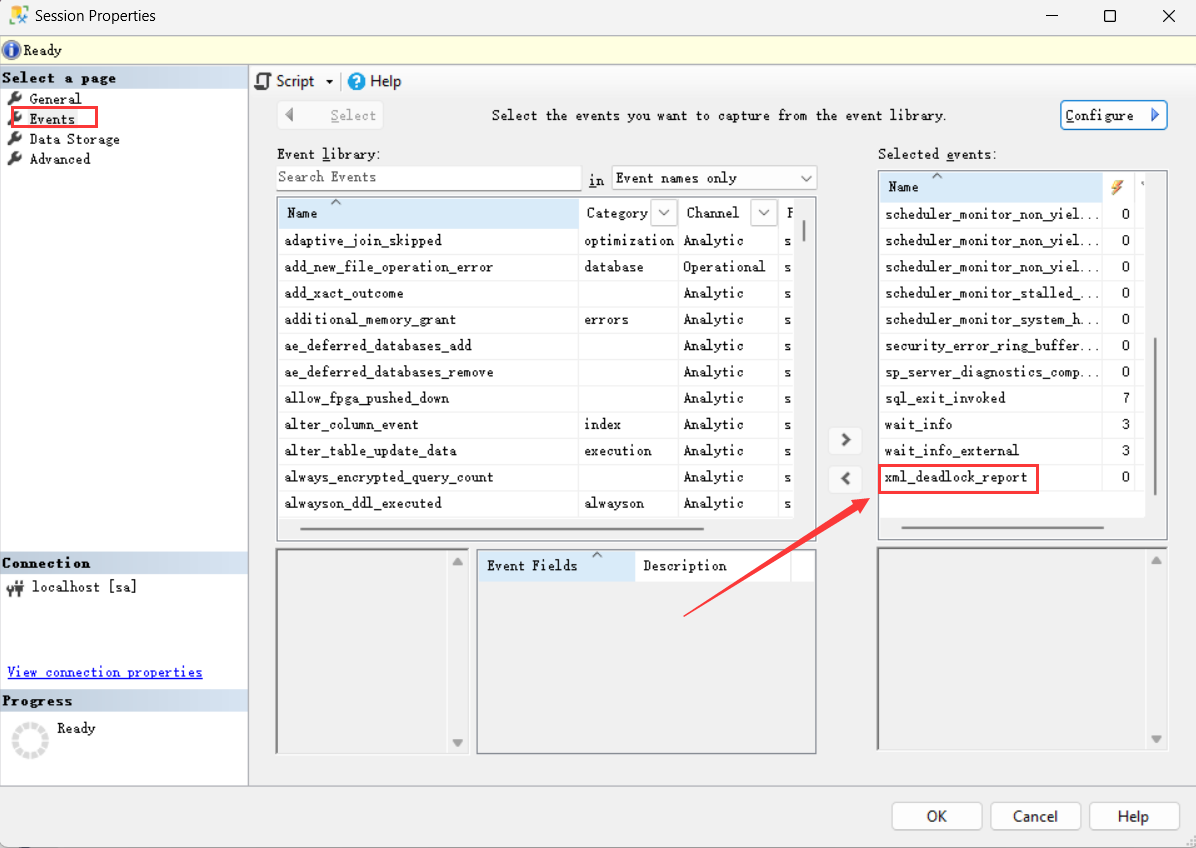
右击system_health会话,选择Properties,在Events选项卡中,可以看到xml_deadlock_report事件:
使用
右击system_health会话,选择Watch Live Data,就可以查看system_health会话记录的实时数据了:
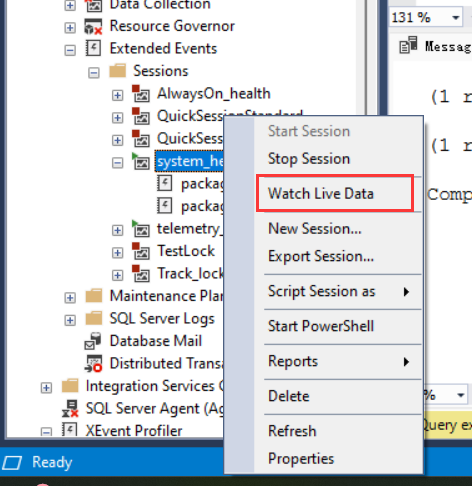
然后在五秒钟内分别在两个窗口执行如下事务:
事务1
USE SampleDb;
GO
begin tran
update account set Money=1500 where Id=2;
waitfor delay '00:00:05';
update account set Money=1500 where Id=1;
rollback tran
5秒内执行事务2
USE SampleDb;
GO
begin tran
update account set Money=1000 where Id=1;
waitfor delay '00:00:05';
update account set Money=1000 where Id=2;
rollback tran
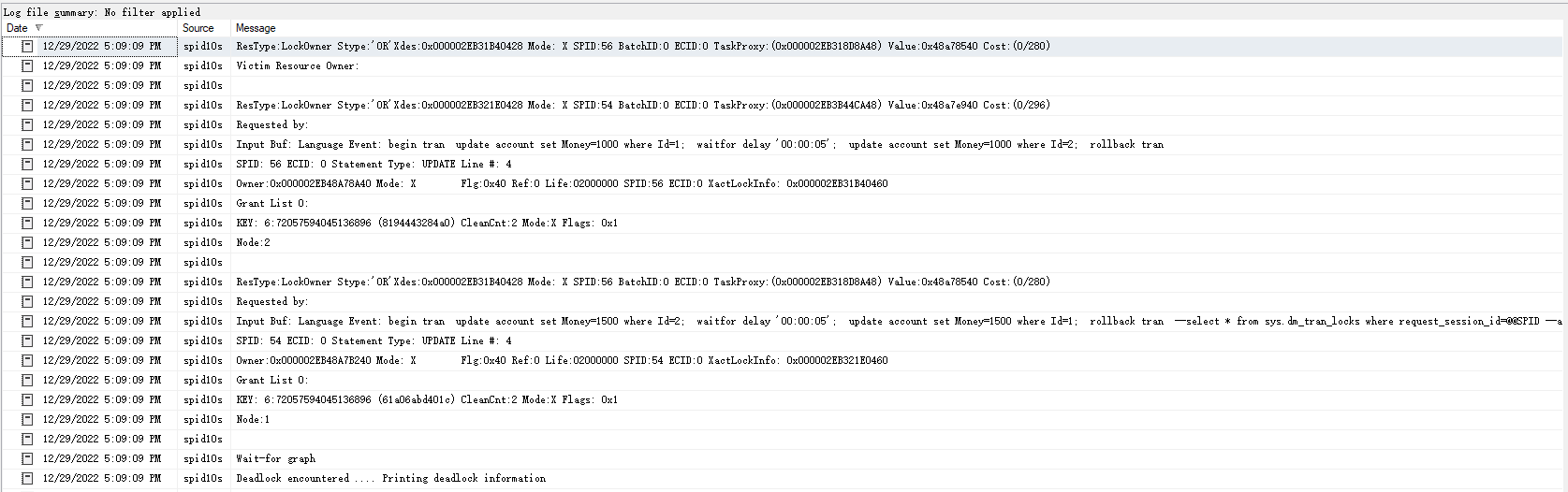
执行这两个会产生死锁,然后在system_health会话中就可以看到死锁信息了:
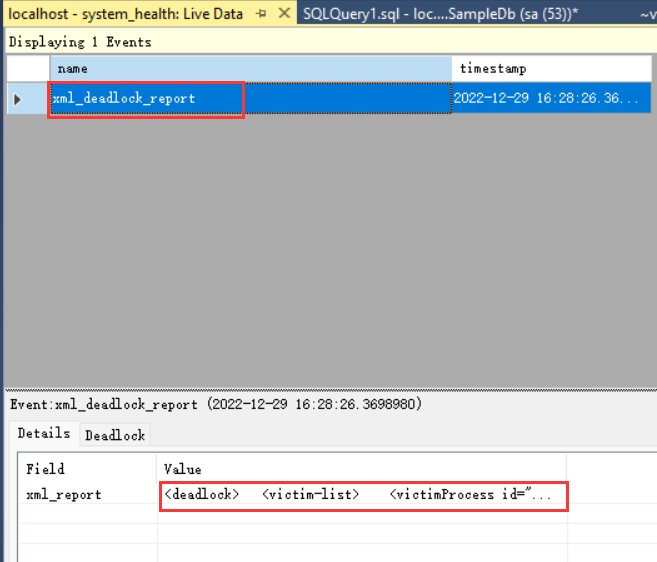
双击value列中的xml数据,就可以看到死锁详细信息了:
<deadlock>
<victim-list>
<victimProcess id="process2eb3e6b9088" />
</victim-list>
<process-list>
<process id="process2eb3e6b9088" taskpriority="0" logused="280" waitresource="KEY: 6:72057594045136896 (61a06abd401c)" waittime="2234" ownerId="3277896" transactionname="user_transaction" lasttranstarted="2022-12-29T16:28:19.130" XDES="0x2eb31b40428" lockMode="X" schedulerid="2" kpid="18356" status="suspended" spid="56" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-12-29T16:28:19.130" lastbatchcompleted="2022-12-29T16:28:19.130" lastattention="1900-01-01T00:00:00.130" clientapp="Microsoft SQL Server Management Studio - Query" hostname="DESKTOP-NAS85BQ" hostpid="32196" loginname="sa" isolationlevel="read committed (2)" xactid="3277896" currentdb="6" currentdbname="SampleDb" lockTimeout="4294967295" clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="4" stmtstart="38" stmtend="132" sqlhandle="0x02000000b642122a34c7fa5dff25ac992cb09388e4ad74de0000000000000000000000000000000000000000">
unknown </frame>
<frame procname="adhoc" line="4" stmtstart="164" stmtend="242" sqlhandle="0x02000000a5e24c03367138f465d49ed5a64c0eccc4a35f750000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
begin tran
update account set Money=1000 where Id=1;
waitfor delay '00:00:05';
update account set Money=1000 where Id=2;
rollback tran
</inputbuf>
</process>
<process id="process2eb3ed9c8c8" taskpriority="0" logused="296" waitresource="KEY: 6:72057594045136896 (8194443284a0)" waittime="4424" ownerId="3277872" transactionname="user_transaction" lasttranstarted="2022-12-29T16:28:16.940" XDES="0x2eb321e0428" lockMode="X" schedulerid="1" kpid="6700" status="suspended" spid="54" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-12-29T16:28:16.940" lastbatchcompleted="2022-12-29T16:28:16.940" lastattention="1900-01-01T00:00:00.940" clientapp="Microsoft SQL Server Management Studio - Query" hostname="DESKTOP-NAS85BQ" hostpid="32196" loginname="sa" isolationlevel="read committed (2)" xactid="3277872" currentdb="6" currentdbname="SampleDb" lockTimeout="4294967295" clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="4" stmtstart="38" stmtend="132" sqlhandle="0x02000000b642122a34c7fa5dff25ac992cb09388e4ad74de0000000000000000000000000000000000000000">
unknown </frame>
<frame procname="adhoc" line="4" stmtstart="164" stmtend="242" sqlhandle="0x0200000073193e03e19d89b38a979fcada3479a02c41eaac0000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
begin tran
update account set Money=1500 where Id=2;
waitfor delay '00:00:05';
update account set Money=1500 where Id=1;
rollback tran
--select * from sys.dm_tran_locks where request_session_id=@@SPID --and resource_type='KEY'
--sp_lock
</inputbuf>
</process>
</process-list>
<resource-list>
<keylock hobtid="72057594045136896" dbid="6" objectname="SampleDb.dbo.account" indexname="PK_account" id="lock2eb3e8ef600" mode="X" associatedObjectId="72057594045136896">
<owner-list>
<owner id="process2eb3ed9c8c8" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process2eb3e6b9088" mode="X" requestType="wait" />
</waiter-list>
</keylock>
<keylock hobtid="72057594045136896" dbid="6" objectname="SampleDb.dbo.account" indexname="PK_account" id="lock2eb48a15300" mode="X" associatedObjectId="72057594045136896">
<owner-list>
<owner id="process2eb3e6b9088" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process2eb3ed9c8c8" mode="X" requestType="wait" />
</waiter-list>
</keylock>
</resource-list>
</deadlock>
或者通过如下查询也可以查看system_health记录的死锁信息:
SELECT xdr.value('@timestamp', 'datetime') AS [Date],
xdr.query('.') AS [Event_Data]
FROM (SELECT CAST([target_data] AS XML) AS Target_Data
FROM sys.dm_xe_session_targets AS xt
INNER JOIN sys.dm_xe_sessions AS xs ON xs.address = xt.event_session_address
WHERE xs.name = N'system_health'
AND xt.target_name = N'ring_buffer'
) AS XML_Data
CROSS APPLY Target_Data.nodes('RingBufferTarget/event[@name="xml_deadlock_report"]') AS XEventData(xdr)
ORDER BY [Date] DESC;
结果如下:
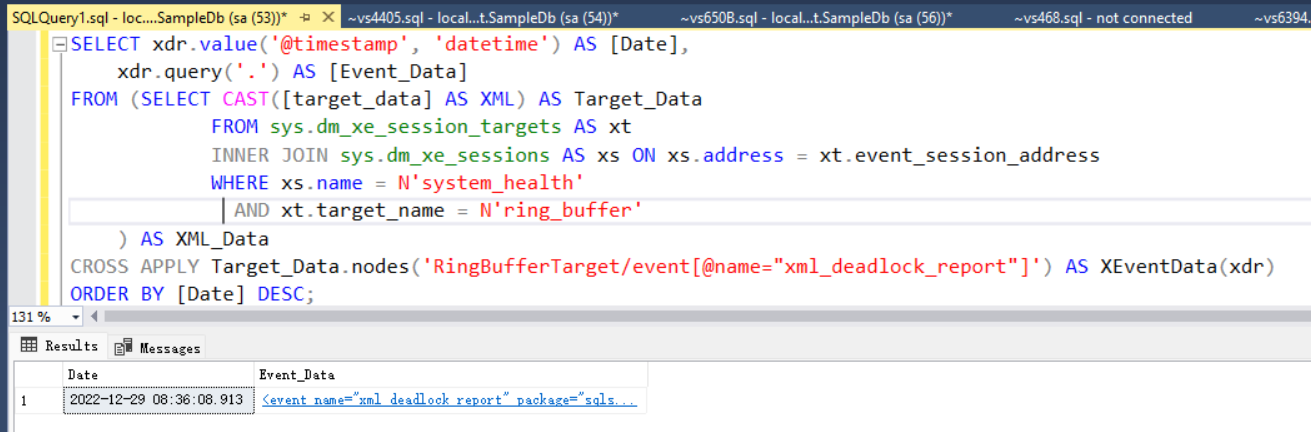
点击Event_Data同样可以查看详细的死锁信息。
跟踪标志1204和1222(不建议)
启用1204和1222跟踪标志可以跟踪死锁,但是这两个跟踪标志会影响性能,不建议使用。
语法
启用:
DBCC TRACEON(1204,-1)
DBCC TRACEON(1222,-1)
--或者
DBCC TRACEON(1204,1222,-1)
关闭:
DBCC TRACEOFF(1204,1222, -1)
跟踪标志1204示例
第一步:启用1204跟踪标志
DBCC TRACEON(1204,-1)
查看跟踪标志:
DBCC TRACESTATUS
结果如下:
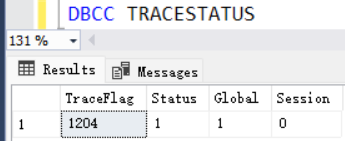
启用1204跟踪日志后,发生死锁后,会在错误日志中记录死锁信息,如下:
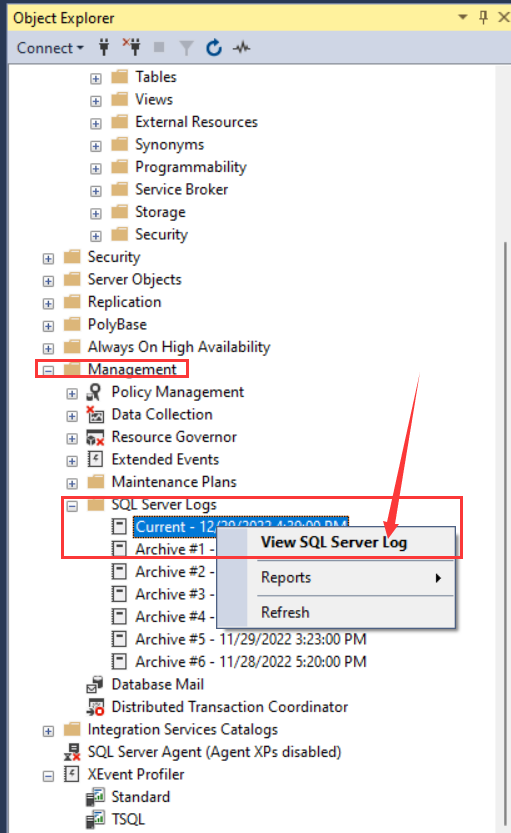
跟踪标志1222就不示例了,跟踪标志1204和1222的区别就是1204只记录死锁信息,1222会记录死锁信息和死锁链路信息。
Profiler死锁属性事件类
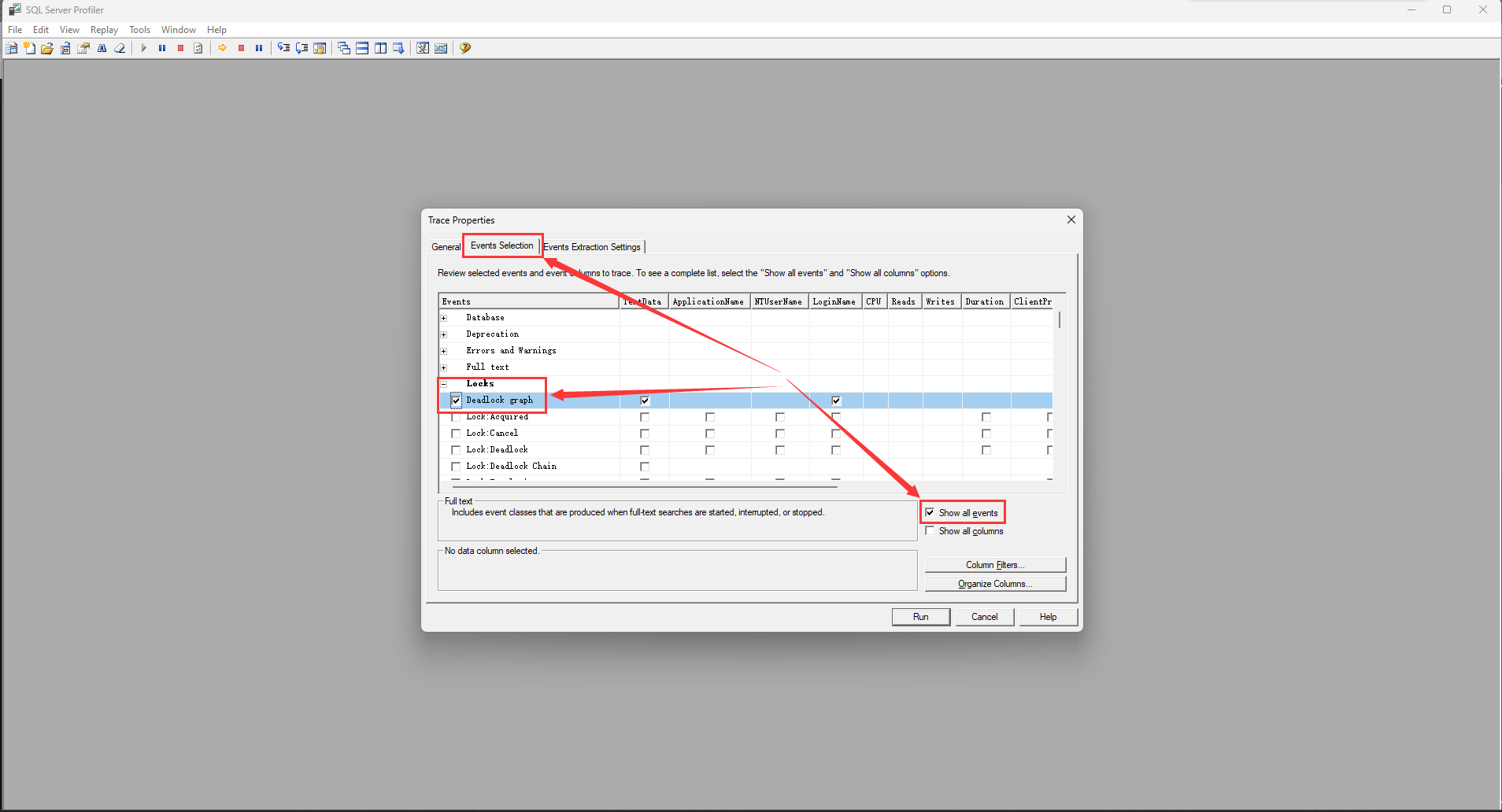
第一步
第一步,打开Profiler,选择模板
第二部,点击Events Selection,勾中Show all events。
第三步,展开Locks节点,勾中Deadlock Graph。
然后,点击 Run,如图:
Profiler跟踪运行起来过后,分别在两个会话中分别执行如下两个事务:
事务1
USE SampleDb;
GO
begin tran
update account set Money=1500 where Id=1;
waitfor delay '00:00:05';
update UserInfo set username=N'平元兄' where Id=1;
commit
5秒内执行事务2
USE SampleDb;
GO
begin tran
update UserInfo set username=N'平元兄' where Id=1;
waitfor delay '00:00:05';
update account set Money=1500 where Id=1;
commit
整个过程是,事务1先获取表account行1的排他锁,然后等待5秒,事务2先获取表UserInfo行1的排他锁,然后等待,此时事务1想获取表UserInfo行1的排他锁,事务2想获取表account行1的排他锁,这时候就发生死锁了。
5秒后,事务2执行完毕,事务1执行完毕,这时候,会发生死锁,Profiler会记录死锁信息,如下:
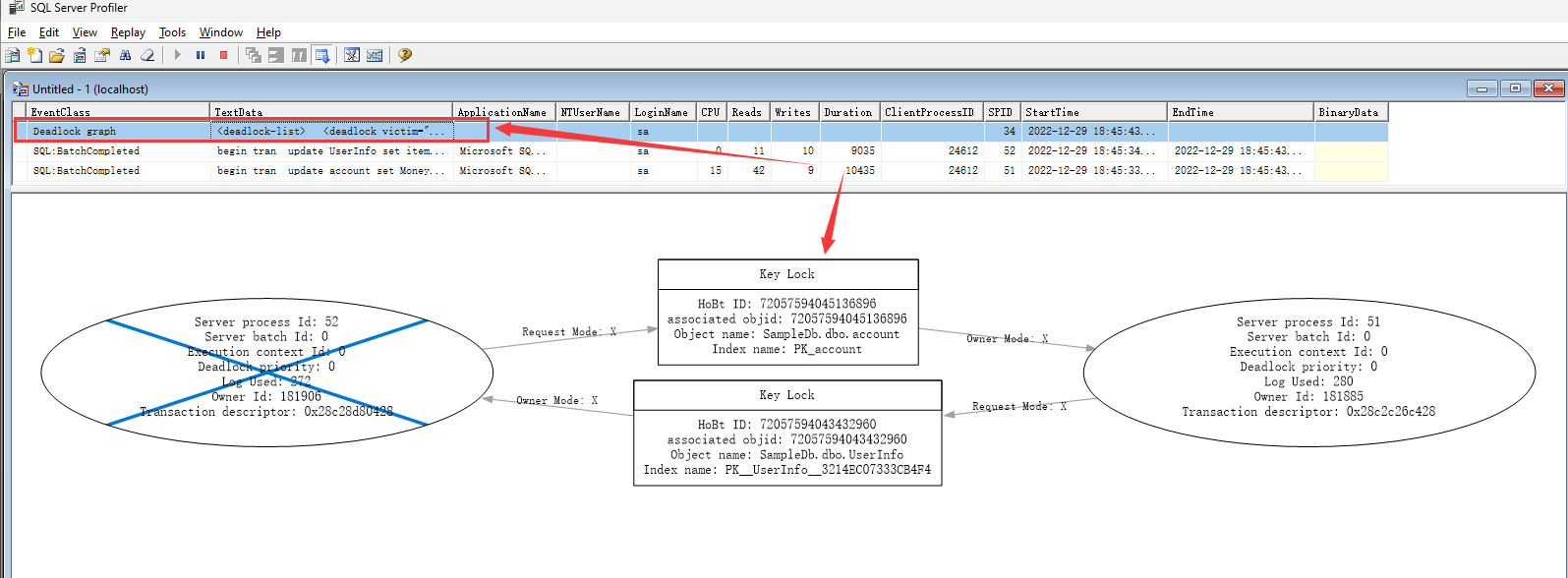
图形两边的椭圆代表两个事务,中间上下两个长方形代表两个资源,里边信息是表的标识,Owner Mode箭头代表已经获取的锁,Request Mode箭头代表请求获取的锁。
从图中可以看到会话Id为52的事务被干掉,会话Id为51的成功执行。
客服端处理死锁
被杀死的事务会终止后续批处理并回滚事务。然后抛出一个编号为1205的错误,错误信息如下:
Your transaction (process ID #52) was deadlocked on {lock | communication buffer | thread} resources with another process and has been chosen as the deadlock victim. Rerun your transaction.
如果客户端程序不处理1205错误,也不知道自己的事务一技能被回滚并且报错,然后继续操作,这有肯能发生一些不可预料的错误。
正确的做法应该是,客户端捕获1205错误,采取一些补救措施,比如自动重新执行事务,这样用户也不会感觉到事务被回滚了。
但是不应该立即重新提交该事务,而是应该短暂暂停一下,让前面一起陷入死锁的事务释放锁,然后再重新提交事务,降低再次跟前面的事务一起陷入死锁的可能性。
减少死锁的发生
由于陷入死锁的事务必须等待锁超时,或者被数据库引擎检测到,然后结束其中一个事务,这个过程会非常耗时,所以,我们应该尽量减少死锁的发生。
1.按照相同的顺序访问资源
大多数死锁都是由于事务按照不同的顺序访问资源导致的,所以,我们应该尽量按照相同的顺序访问资源。
比如两个事务,都是先更新表UserInfo,然后再更新表account,在其中一个事务结束之前,另一个事务直接被阻塞,不会获取任何表上的锁,这样就不会发生死锁。
2.避免事务中的用户交互
记住,一定不要在事务中有用户交互,比如事务在执行到一半的时候,弹出一个对话框,让用户输入一些信息给事务,然后事务再继续执行。
这里的问题就很明显了,首先用户输入对于一个事务来说本来就是个耗时操作,而且如果用户在输入的时候,突然有事情要离开,如果没有设置锁超时,那这个事务就会一直占用锁,直到用户回来,导致其他以相斥锁访问同一资源的事务统统被阻塞。同时,一个事务占用锁的时间越长,死锁的可能性就越大。
3.保持事务简短并处于一个批处理中
事务越长,它持有排他锁或更新锁的时间也就越长,死锁的可能性就越大,所以,应该尽量保持事务简短,同时避免在事务中有耗时的计算操作。
同时,应该尽量把多个事务放在一个批处理中,这样,减少了网络通信的次数,由于每次传输都带有网络延迟,因此也减少了事务持有锁的时间。
4.使用较低的事务隔离级别
越低的事务隔离级别,事务持有共享锁的时间就越短,死锁的可能性就越小,应该尽量使用较低的事务隔离级别。
5.使用基于行版本快照控制的隔离级别
比如,基于行版本控制的读已提交快照(READ_COMMITTED_SNAPSHOT)隔离级别,和快照(SNAPSHOT)隔离级别,这两个隔离级别都是基于行版本和快照控制的,他们不会通过加锁来控制并发,这样以来就大大降低了死锁的可能性。
6.使用绑定连接
使用绑定连接,同一应用程序打开的两个或多个连接可以相互合作。 可以像主连接获取的锁那样持有次级连接获取的任何锁,反之亦然。 这样它们就不会互相阻塞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号