
数据结构与算法: 基础知识
数据结构
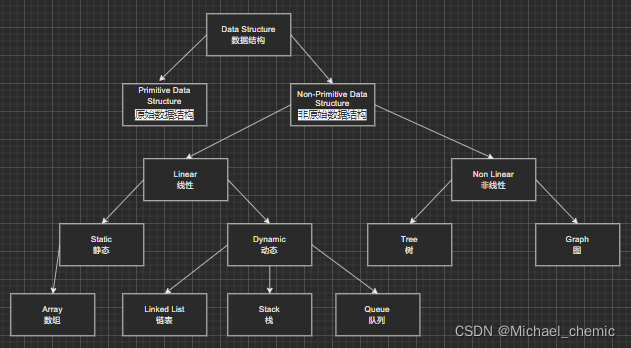
栈(Stack):栈是一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。
队列(Queue):队列和栈类似,也是一种特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作。
数组(Array):数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。
链表(Linked List):链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。
树(Tree):树是典型的非线性结构,它是包括,2 个结点的有穷集合 K。
图(Graph):图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。
堆(Heap):堆是一种特殊的树形数据结构,一般讨论的堆都是二叉堆。
散列表(Hash table):散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
使用数据结构的好处
效率:如果选择用于实现特定ADT的数据结构是正确的,则使程序在时间和空间方面非常有效。
可重用:数据结构提供的可重用性意味着多个客户端程序可以使用该数据结构。
抽象化:ADT 指定的数据结构还提供抽象级别。客户端看不到数据结构的内部工作,因此不必担心实现部分。客户端只能看到接口。
基本术语
Data: Data can be defined as an elementary value or the collection of values
Group Items: Data items which have subordinate data items are called Group item
Record: Record can be defined as the collection of various data items
File: A File is a collection of various records of one type of entity
Attribute and Entity: An entity represents the class of certain objects. it contains various attributes. Each attribute represents the particular property of that entity.
Field: Field is a single elementary unit of information representing the attribute of an entity.
算法
数据结构研究的内容:就是如何按一定的逻辑结构,把数据组织起来,并选择适当的存储表示方法把逻辑结构组织好的数据存储到计算机的存储器里。算法研究的目的是为了更有效的处理数据,提高数据运算效率。数据的运算是定义在数据的逻辑结构上,但运算的具体实现要在存储结构上进行。一般有以下几种常用运算:
检索:检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。我们可以搜索数据结构中的任何元素。
插入:往数据结构中增加新的节点,在数据结构中插入新元素。
删除:把指定的结点从数据结构中删除。
更新:改变指定节点的一个或多个字段的值。即用另一个元素替换该元素。
排序:把节点按某种指定的顺序重新排列。例如递增或递减。我们可以按升序或降序对数据结构的元素进行排序。
算法特征
输入:算法具有一些输入值。
输出:我们将在算法结束时获得 1 个或更多输出。
明确性:算法应该是明确的,这意味着算法中的指令应该是清晰和简单的。
有限性:算法应该具有有限性。
有效性:算法应该是有效的,因为算法中的每条指令都会影响整个过程。
与编程语言无关:算法必须与语言无关,以便算法中的指令可以用具有相同输出的任何语言实现。
算法的因素
以下是我们在设计算法时需要考虑的因素:
模块性:如果给出了任何问题,我们可以将该问题分解为小-小模块或小-小步骤,这是算法的基本定义,这意味着该功能已为算法完美设计。
正确性:算法的正确性被定义为给定输入何时产生所需的输出,这意味着该算法已被设计为算法。算法的分析已正确完成。
可维护性:在这里,可维护性意味着算法应该以非常简单的结构化方式进行设计,以便在我们重新定义算法时,不会对算法进行重大更改。
功能性:它考虑了解决现实世界问题的各种逻辑步骤。
鲁棒性:鲁棒性意味着算法如何清楚地定义我们的问题。
对用户友好:如果算法不对用户友好,那么设计人员将无法向程序员解释它。
简单:如果算法很简单,那么它很容易理解。
可扩展:如果任何其他算法设计人员或程序员想要使用您的算法,那么它应该是可扩展的。
算法方法
以下是在考虑了设计算法的理论和实践重要性后使用的方法:
暴力破解算法:应用一般逻辑结构来设计算法。它也被称为详尽的搜索算法,用于搜索提供所需解决方案的所有可能性。此类算法有两种类型:
- 优化:找到问题的所有解决方案,然后取出最佳解决方案,或者如果知道最佳解决方案的价值,那么如果知道最佳解决方案,它将终止。
- 牺牲:一旦找到最佳解决方案,它就会停止。
分而治之:它是算法的实现。它允许您以分步变化的形式设计算法。它分解算法以不同的方法解决问题。它允许您将问题分解为不同的方法,并为有效输入生成有效输出。此有效输出将传递给其他某个函数。
贪婪算法:它是一种算法范式,可以在每次迭代时做出最佳选择,以期获得最佳解决方案。它易于实现,执行时间更快。但是,在极少数情况下,它提供了最佳解决方案。
动态规划:它通过存储中间结果使算法更有效。它遵循五个不同的步骤来找到问题的最佳解决方案:
- 它将问题分解为一个子问题,以找到最佳解决方案。
- 分解问题后它会从这些子问题中找到最佳解决方案。
- 存储子问题的结果称为记忆。
- 重用结果,以便无法针对相同的子问题重新计算结果。
- 它计算复杂程序的结果。
分支和绑定算法:分支和绑定算法只能应用于整数规划问题。这种方法将所有可行解决方案集划分为更小的子集。进一步评估这些子集以找到最佳解决方案。
随机算法:正如我们在常规算法中看到的那样,我们有预定义的输入和所需的输出。那些具有一些定义的输入和所需输出集并遵循一些所述步骤的算法称为确定性算法。在随机算法中引入随机变量时会发生什么?在随机算法中,算法引入一些随机位,并添加到输入中以产生输出,这在本质上是随机的。随机算法比确定性算法更简单、更高效。
回溯:回溯是以递归方式解决问题,并在不满足问题约束时删除解决方案。
算法分析
该算法可以分为两个层次进行分析,即第一个是在创建算法之前,第二个是在创建算法之后。以下是对算法的两种分析:
- 先验分析:在这里,先验分析是在实现算法之前完成的算法的理论分析。在实现算法之前,可以考虑各种因素,例如处理器速度,这对实现部分没有影响。
- 后验分析:在这里,后验分析是对算法的实用分析。实际分析是通过使用任何编程语言实现算法来实现的。该分析基本上评估了算法占用了多少运行时间和空间。
算法复杂性
该算法的性能可以通过两个因素来衡量:
时间复杂度
时间复杂度:算法的时间复杂度是完成执行所需的时间量。算法的时间复杂度由大 O 表示法表示。在这里,大 O 表示法是表示时间复杂度的渐近表示法。时间复杂度主要通过计算完成执行的步骤数来计算。
🎈大O符号(Big O notation)是用于描述函数渐近行为的数学符号。更确切地说,它是用另一个(通常更简单的)函数来描述一个函数数量级的渐近上界。在数学中,它一般用来刻画被截断的无穷级数尤其是渐近级数的剩余项;在计算机科学中,它在分析算法复杂性的方面非常有用。
sum=0;
假设我们必须计算 n 个数字的总和。
for i=1 to n
sum=sum+i;
当循环结束时,总和保持n个数字的总和
return sum;
在上面的代码中,循环语句的时间复杂度至少为n,如果n的值增加,那么时间复杂度也会增加。虽然代码的复杂性,即返回总和将是恒定的,因为它的值不依赖于n的值,并且仅在一个步骤中提供结果。我们通常考虑最差时间复杂性,因为它是任何给定输入大小所花费的最长时间。

空间复杂度
算法的空间复杂度是解决问题和产生输出所需的空间量。与时间复杂度类似,空间复杂度也用大O表示法表示。
对于算法,需要空间用于以下目的:
- 存储程序说明
- 存储常量值
- 存储变量值
- 跟踪函数调用、跳转语句等。
辅助空间:算法所需的额外空间(不包括输入大小)称为辅助空间。空间复杂度既考虑空间,即辅助空间,也考虑输入使用的空间。
即:空间复杂度 = 辅助空间 + 输入大小。
算法类型
搜索算法Search Algorithm
排序算法Sort Algorithm
搜索算法
每一天,我们都在日常生活中寻找一些东西。同样,对于计算机,大量数据存储在计算机中,每当用户要求任何数据时,计算机就会在内存中搜索该数据并将该数据提供给用户。主要有两种技术可用于搜索数组中的数据:
- 线性搜索Linear search
- 二进制搜索Binary search
线性搜索
线性搜索是一种非常简单的算法,它从数组的开头开始搜索元素或值,直到找不到所需的元素。它将要搜索的元素与数组中的所有元素进行比较,如果找到匹配项,则返回元素的索引,否则返回 -1。此算法可以在未排序列表上实现。
二进制搜索
二进制算法是最简单的算法,可以非常快速地搜索元素。它用于从排序列表中搜索元素。必须按顺序或排序方式存储元素才能实现二进制算法。如果元素以随机方式存储,则无法实现二进制搜索。它用于查找列表的中间元素。
排序算法
排序算法用于按升序或降序重新排列数组或给定数据结构中的元素。比较运算符决定元素的新顺序。
为什么我们需要排序算法?
需要一种有效的排序算法来优化其他算法(如二进制搜索算法)的效率,因为二进制搜索算法需要按特定顺序(主要是按升序)对数组进行排序。
它按排序顺序生成信息,这是一种人类可读的格式。
在排序列表中搜索特定元素比搜索未排序列表更快。
posted on 2022-04-16 09:47 Michael_chemic 阅读(126) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号