Householder transformation
Householder transformation
Wiki: Householder transformation is a linear transformation that reflect vector \(x\) about a hyperplane to obtain \(x^{\prime}\).
Please refer the these video1 and video2 for detailed deductions.
In order to obtain vector \(x^\prime\) which is the reflection of vector \(x\) with respect to the hyperplane of which the normal vector is denoted as \(u\), we follows the procedures below:
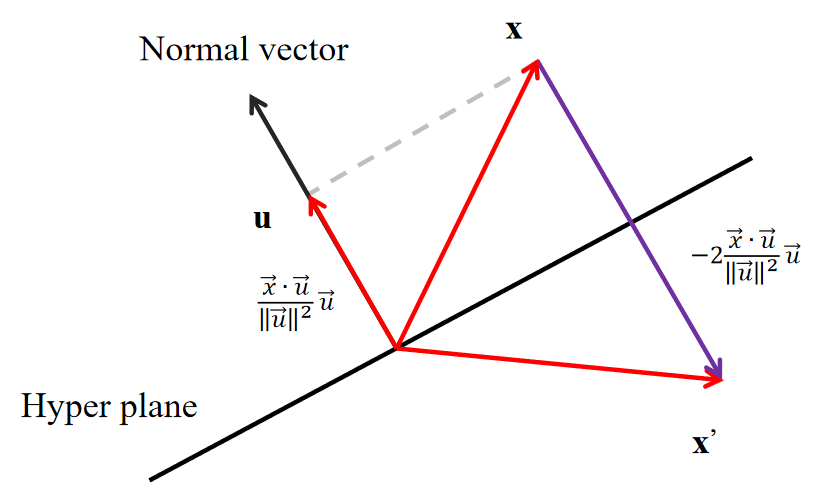
Here we define the following as the householder matrix:
And:
Let's look into an example to see how householder transformation is related to QR decomposition.
Consider the following matrix \(B\):
So matrix \(B\) represents a space which is spanned by those column vectors.
We choose \(x_1\), and we imagine that after reflection, \(x_1\) is laid on the first basis vector \(e_1=\begin{bmatrix}1,0,\cdots,0\end{bmatrix}^T\) , which means that \(x_1^{\prime}=\|x_1\|e_1\). So we can easily obtain \(v_1\) (normalized normal vector), which is:
Then the householder matrix for \(x_1\) is:
Therefore:
And we also define:
Note that after the reflection of \(x_1\), the resultant entries of first column of \(R_1\) is all zero below the diagonal. This is because the \(H_1\) linear operation rotate the whole space and results in that \(x_1\) is located on the first basis vector \(e_1\). And the values on the diagonal is its norm.
Since the \(H_1\) is perform on the whole matrix, which means that the other vectors besides \(x_1\) will also rotate. Once we finish \(H_1\), we can continue to perform \(H_2,H_3,\cdots\) etc.
For example, we choose the second column of \(R_1\). Since vector \(x_2\) may not be complely orthogonal to vector \(x_1^{\prime}\), which means vector \(x_2\) may have some projection part on \(x_1^{'}\) and this refers to the \((1,2)\) entry. But we can neglact this and only focus on those components that are perpendicular to \(x_1^{\prime}\). That's why we choose \(x_2\) to be:
in which the \((1,2)\) entry is set to zero.
And following the same algorithm, we obtain:
Take a close look at \(R_2\), it is not surprising that becomes an upper triangular matrix. Focus on the second column, as we metioned before, the \(H_2\) operation only makes the perpendicular part of \(x_2\) with respect to \(x_1^{\prime}\) rotates to the direction of the second basic vector \(e_2\). Therefore, if we just focus on the rows below the diagonal, we find that it is the same with that of \(x_1^{\prime}\) with the diagonal entry \((2,2)\) displaying the norm.
And the repetitive householder transformation operations finally leads to the QR decomposition. What a coincidence. Cool!
What would happen if we apply the householder transformations repetitively on a symmetric matrix from both sides? Like:
From our intuition, we might think that the combinition of \(H_1\) and \(H_1^T\) for example, will make the entries of the first column and first row to zeros except for the diagonal entry. And the repetitive procedures might result in a diagonal matrix. However, this does not actually hold as indicated by the test below:
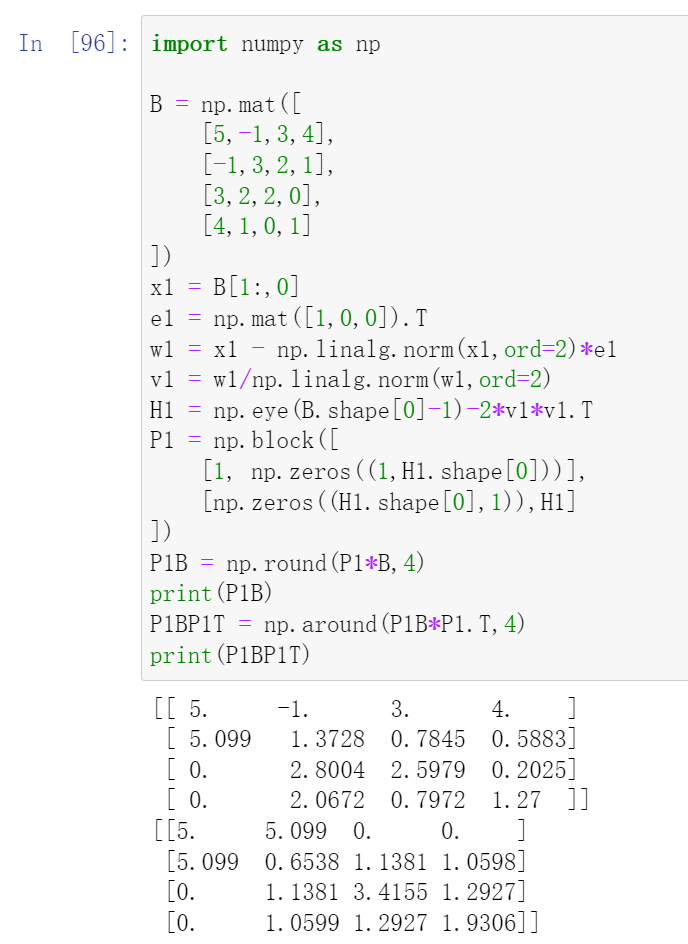
Instead we will try to construct another householder matrix \(P\), and after applying \(P\) and its transpose \(P^T\) on matrix \(B\) repetitively, we end with a tridiagonal matrix.
For \(P_1\), it is represented by the following block matrix:
And \(H_1\) here is no longer a householder transformation matrix that applies to the first column vector. Instead, it applies to all the entries in the first column that are situated below the diagonal entry.
So the symmetric matrix \(B\) is:
Following the similar procedures, we have:
After we apply \(P_1\) to \(B\), we get all entries below the subdiagonal in the first column become zero. And by symmetry, when we continue to apply the transpose \(P_1^T\) rom right, we succeed to get all entries above the superdiagonal in the first row become zero. Take a close look at the following code:
And if we continue to do this, we will end up with a tridiagonal matrix:
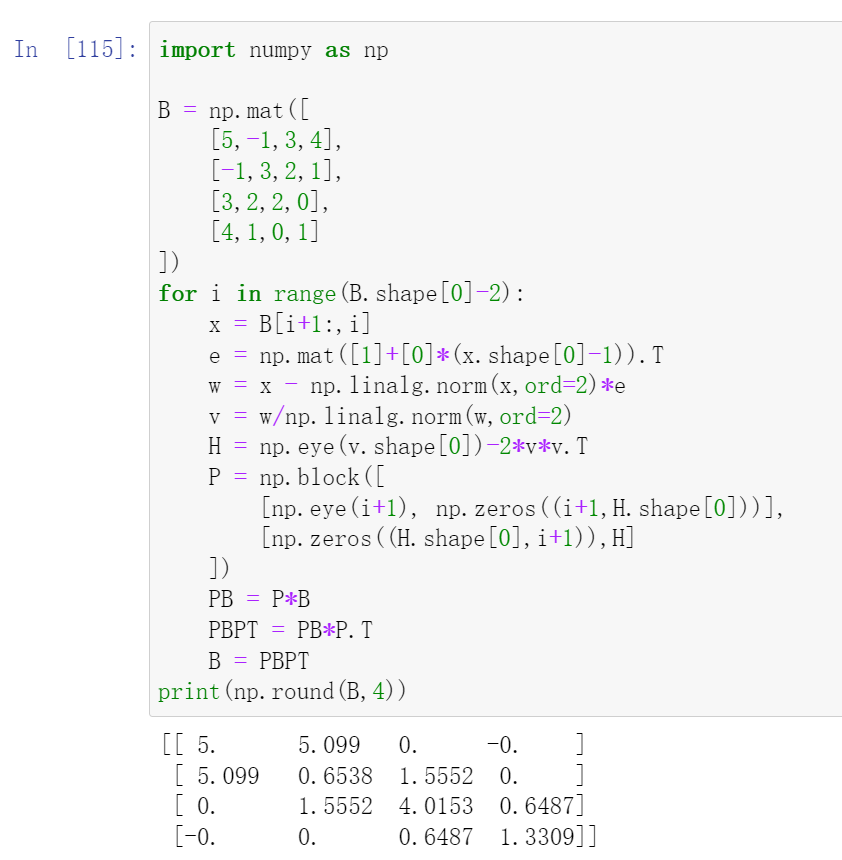
For a more general case: