java -> HttpServletResponse
HttpServletResponse
HttpServletResponse概述
我们在创建Servlet时会覆盖service()方法,或doGet()/doPost(),这些方法都有两个参数,一个为代表请求的request和代表响应response。
service方法中的response的类型是ServletResponse,而doGet/doPost方法的response的类型是HttpServletResponse,HttpServletResponse是ServletResponse的子接口,功能和方法更加强大,今天我们学习HttpServletResponse。
response的运行流程
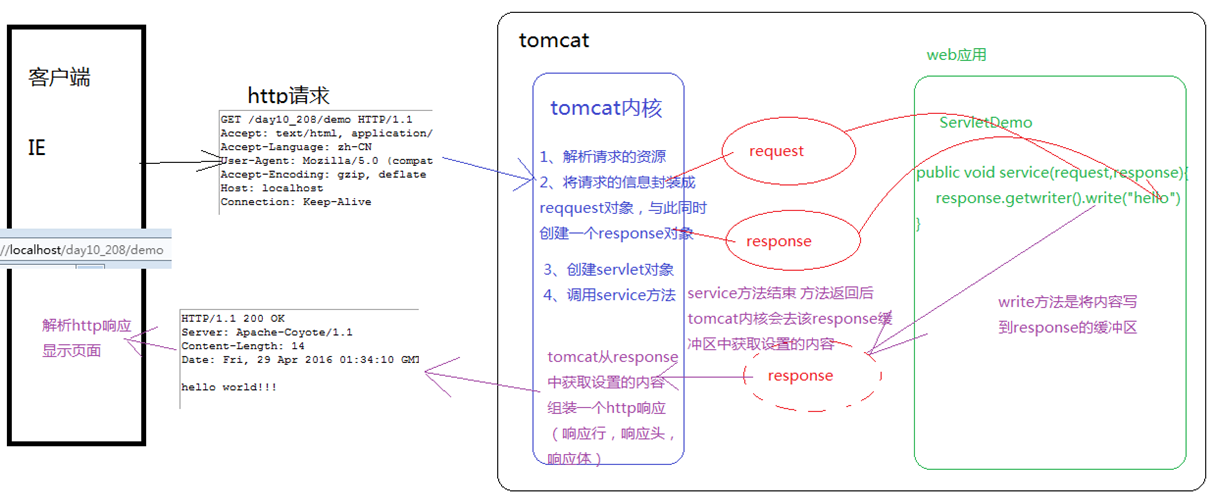
通过抓包工具抓取Http响应
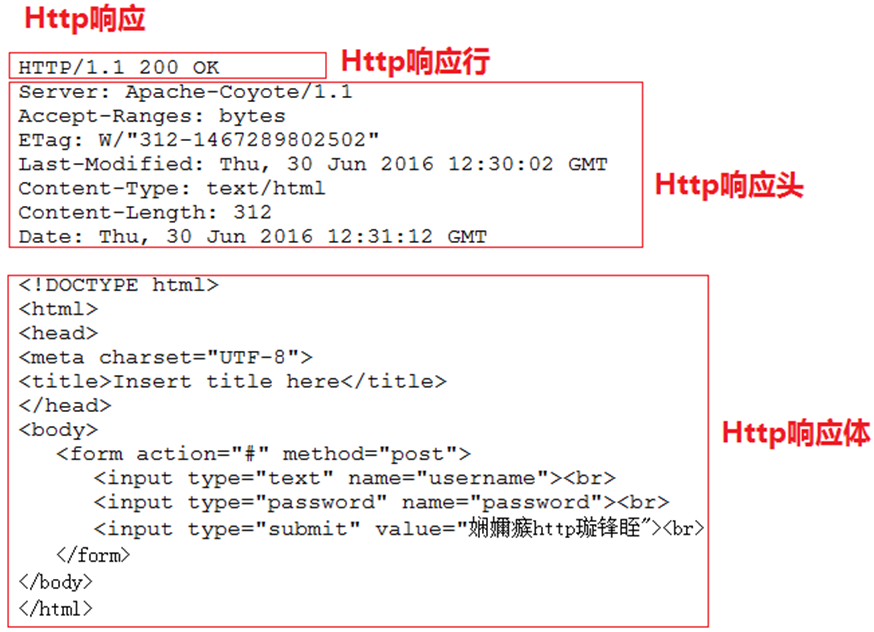
因为response代表响应,所以我们可以通过该对象分别设置Http响应的响应行,响应头和响应体
通过response设置响应行
设置响应行的状态码
setStatus(int sc)
通过response设置响应头
addHeader(String name, String value)
addIntHeader(String name, int value)
addDateHeader(String name, long date)
setHeader(String name, String value)
setDateHeader(String name, long date)
setIntHeader(String name, int value)
其中,add表示添加,而set表示设置
重定向需要:1.状态码:302
2.响应头:location 代表重定向地址
通过response设置响应体
response.setHeader("refresh","5;url=http://www.baidu.com");//五秒循环刷新url地址
response.setStatus(302);//更改状态码为302
response.setHeader("Location","MyServlet04");//更改响应头Location参数
response.sendRedirect("MyServlet04");//等于上面两行
响应体设置文本
获得字符流,通过字符流的write(String s)方法可以将字符串设置到response 缓冲区中,随后Tomcat会将response缓冲区中的内容组装成Http响应返回给浏览器端。
关于设置中文的乱码问题
原因:response缓冲区的默认编码是iso8859-1,此码表中没有中文,可以通过response的setCharacterEncoding(String charset) 设置response的编码
但我们发现客户端还是不能正常显示文字
原因:我们将response缓冲区的编码设置成UTF-8,但浏览器的默认编码是本地系统的编码,因为我们都是中文系统,所以客户端浏览器的默认编码是GBK,我们可以 手动修改浏览器的编码是UTF-8。
我们还可以在代码中指定浏览器解析页面的编码方式,
通过response的setContentType(String type)方法指定页面解析时的编码是UTF-8
response.setContentType("text/html;charset=UTF-8");
上面的代码不仅可以指定浏览器解析页面时的编码,同时也内含 setCharacterEncoding的功能,所以在实际开发中只要编写 response.setContentType("text/html;charset=UTF-8");就可以解决页面输出中文乱码问题。
响应头设置字节
ServletOutputStream getOutputStream()
获得字节流,通过该字节流的write(byte[] bytes)可以向response缓冲区中写入字节,在由Tomcat服务器将字节内容组成Http响应返回给浏览器。
案例-完成文件下载
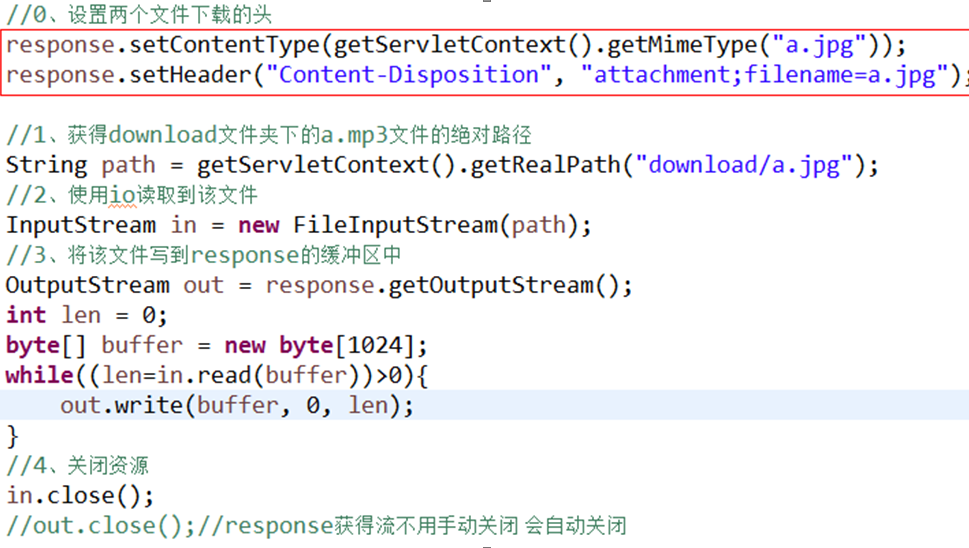
文件下载的实质就是文件拷贝,将文件从服务器端拷贝到浏览器端。所以文件下载需要IO技术将服务器端的文件使用InputStream读取到,在使用 ServletOutputStream写到response缓冲区中
代码如下:

上述代码可以将图片从服务器端传输到浏览器,但浏览器直接解析图片显示在页面上, 而不是提供下载,我们需要设置两个响应头,告知浏览器文件的类型和文件的打开方式。
1)告知浏览器文件的类型:response.setContentType(文件的MIME类型);
2)告示浏览器文件的打开方式是下载:
response.setHeader("Content-Disposition","attachment;filename=文件名称");
代码如下:
但是,如果下载中文文件,页面在下载时会出现中文乱码或不能显示文件名的情况,原因是不同的浏览器默认对下载文件的编码方式不同,ie是UTF-8编码方式,而火狐 浏览器是Base64编码方式。所里这里需要解决浏览器兼容性问题,解决浏览器兼容性问题的首要任务是要辨别访问者是ie还是火狐(其他),通过Http请求体中的一个属性可以辨别

解决乱码方法如下(不要记忆--了解):
//获取指定的头中用户浏览器信息
String agent = request.getHeader("User-Agent");
if (agent.contains("MSIE")) {
// IE浏览器
filename = URLEncoder.encode(filename, "utf-8");
filename = filename.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filename = URLEncoder.encode(filename, "utf-8");
}
其中agent就是请求头User-Agent的值

response细节点:
- response获得的流不需要手动关闭,web容器(tomcat容器)会帮助我们关闭,
- getWriter和getOutputStream不能同时调用
- 重定向语句一般作为终结代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号