

前言
背景:httprunner底层也是request,所以同样存在乱码问题
步骤:
1.响应正文乱码,先从报表中查看响应头中的encoding
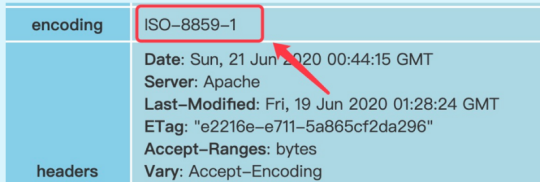
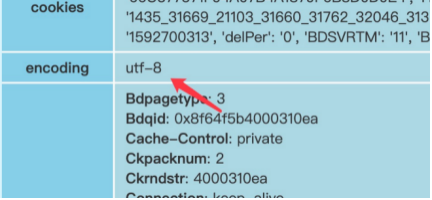
2.搜索相关编码转换的代码
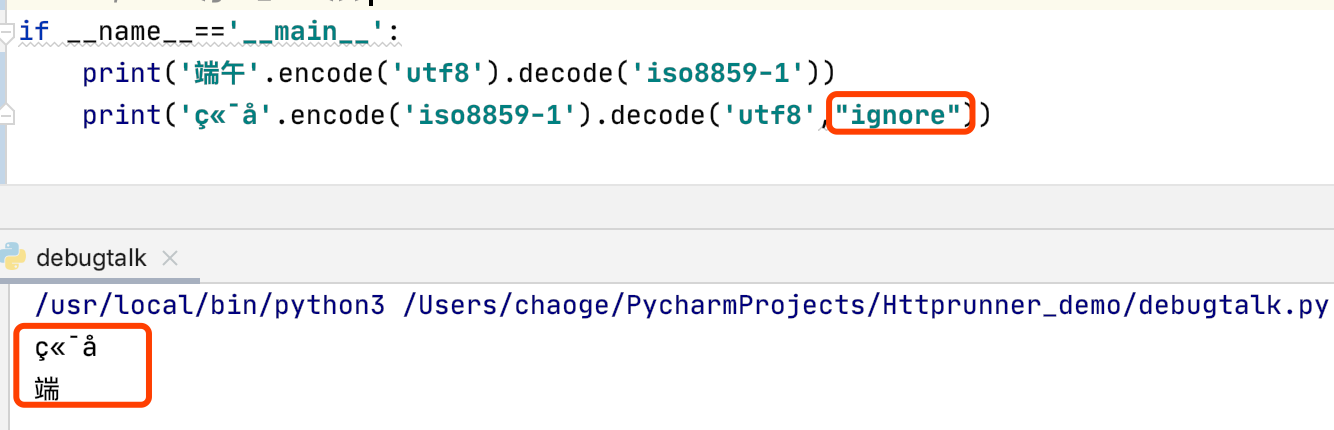
if __name__=='__main__':
print('端午'.encode('utf8').decode('iso8859-1'))
print('端å'.encode('iso8859-1').decode('utf8')) #此句报错,如下
报错信息:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 3: unexpected end of data
百度🉐️:修改字符集参数,一般这种情况出现得较多是在国标码(GBK)和utf8之间选择出现了问题。
出现异常报错是由于设置了decode()方法的第二个参数errors为严格(strict)形式造成的,因为默认就是这个参数,将其更改为ignore等即可。
decode("utf8","ignore")
3.在debugtalk.py中编写函数

实战:
思路一:响应正文出现的乱码不处理,假设httprunner要做中文断言,可对期望结果进行转码处理。
- config:
name: 'open hnxmxit mainpage'
base_url: 'http://www.hnxmxit.com'
- test:
name: 'open hnxmxit mainpage'
variables:
- temp_except: '新梦想IT教育_软件测试培训_Java培训_Python培训_长沙良心IT教育'
- except: ${decode_utf8($temp_except)}
request:
url: /
method: GET
extract:
- temp_title: <title>(.+?)</title>
validate:
- eq: ['status_code',200]
- eq: [$temp_title,$except]
思路二:转换实际结果
#乱码问题实战,思路二:转换实际结果
- config:
name: 'open hnxmxit mainpage'
base_url: 'http://www.hnxmxit.com'
- test:
name: 'open hnxmxit mainpage'
request:
url: /
method: GET
extract:
- temp_title: <title>(.+?)</title>
validate:
- eq: ['status_code',200]
- eq: ['${decode_utf8($temp_title)}','新梦想IT教育_软件测试培训_Java培训_Python培训_长沙良心IT教育']
思路三:由于extract中不能调用debugtalk的函数,所以放到测试步骤中转码
#乱码问题实战,思路三:测试步骤中转换
- config:
name: 'open hnxmxit mainpage'
base_url: 'http://www.hnxmxit.com'
- test:
name: 'open hnxmxit mainpage'
variables:
- except: '新梦想IT教育_软件测试培训_Java培训_Python培训_长沙良心IT教育'
- title: ${decode_utf8($temp_title)}
request:
url: /
method: GET
extract:
- temp_title: <title>(.+?)</title>
validate:
- eq: ['status_code',200]
- eq: [$title,'新梦想IT教育_软件测试培训_Java培训_Python培训_长沙良心IT教育']

