
Clumper尝鲜
Clumper可以用来处理嵌套样式的json数据结构。
安装
!pip3 install clumper
为了展示Clumper如何工作,我准备了pokemon.json, 由列表组成(该列表由多个字典组成),下面是pokemon.json部分内容
import json
with open('pokemon.json') as jsonf:
pokemon = json.loads(jsonf.read())
pokemon[:2]
[{'name': 'Bulbasaur',
'type': ['Grass', 'Poison'],
'total': 318,
'hp': 45,
'attack': 49},
{'name': 'Ivysaur',
'type': ['Grass', 'Poison'],
'total': 405,
'hp': 60,
'attack': 62}]
我们准备的pokemon.json列表中大概有800个字典,数量级刚刚好,不会因为太大导致电脑无法运行数据分析,也不会太小导致手动操作性价比更高。
基本操作
from clumper import Clumper
list_of_dicts = [
{'a': 7, 'b': 2},
{'a': 2, 'b': 4},
{'a': 3, 'b': 6}
]
(Clumper(list_of_dicts)
.mutate(c=lambda d: d['a']+d['b'])
.sort(lambda d: d['c'])
.collect()
)
[{'a': 2, 'b': 4, 'c': 6},
{'a': 7, 'b': 2, 'c': 9},
{'a': 3, 'b': 6, 'c': 9}]
代码解析
Step1
首先使用mutate方法,该方法可以在每条记录中生成新变量。
first-mutate.png)
结算结果仍为Clumper类
Step2
接下来对mutate之后的数据进行排序
then-sort.png)
得到的结果仍为Clumper类。
从上面的小代码案例中,可以看到整套流程像是一个流水线车间,每一行就是一个生成环节,生产环节之间使用.连接起来。
from clumper import Clumper
(Clumper(pokemon)
.keep(lambda d: len(d['type'])==1) #保留type长度为1的字典
.mutate(type=lambda d: d['type'][0], #type值从列表变为字符串
ratio=lambda d: d['attack']/d['hp']) #新建ratio
.select('name', 'type', 'ratio') #字典最后只保留name, type, ratio三个字段
.sort(lambda d: d['ratio'], reverse=True) #按照ratio降序排列
.head(5) #只保留前5个
.collect() #转成列表显示
)
[{'name': 'Diglett', 'type': 'Ground', 'ratio': 5.5},
{'name': 'DeoxysAttack Forme', 'type': 'Psychic', 'ratio': 3.6},
{'name': 'Krabby', 'type': 'Water', 'ratio': 3.5},
{'name': 'DeoxysNormal Forme', 'type': 'Psychic', 'ratio': 3.0},
{'name': 'BanetteMega Banette', 'type': 'Ghost', 'ratio': 2.578125}]
Keep
keep函数可以从原始数据中抽取符合指定条件的子集。
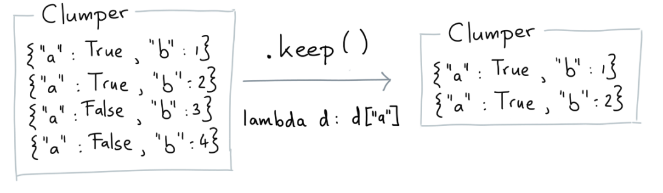
from clumper import Clumper
list_dicts = [{'a': 1},
{'a': 2},
{'a': 3},
{'a': 4}]
(Clumper(list_dicts)
.keep(lambda d: d['a'] >= 3)
.collect() #试一试去掉.collect()后的效果
)
[{'a': 3},
{'a': 4}]
可以实现缺失值处理,以不同的方式实现pandas的.dropna()的功能。
from clumper import Clumper
data = [
{"a": 1, "b": 4},
{"a": 2, "b": 3},
{"a": 3, "b": 2},
{"a": 4},
]
#只保留含有b的字段
(Clumper(data)
.keep(lambda d: 'b' in d.keys())
.collect()
)
[{'a': 1, 'b': 4},
{'a': 2, 'b': 3},
{'a': 3, 'b': 2}]Mutate
mutate可以在每条记录中,创建新字段、改写旧字段。

from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
#新建了c和s字段
(Clumper(list_dicts)
.mutate(c=lambda d: d['a'] + d['b'],
s=lambda d: d['a'] + d['b'] + d['c'])
.collect()
)
[{'a': 1, 'b': 2, 'c': 3, 's': 6},
{'a': 2, 'b': 3, 'c': 5, 's': 10},
{'a': 1, 'b': 6, 'c': 7, 's': 14}]Sort
sort可以实现排序
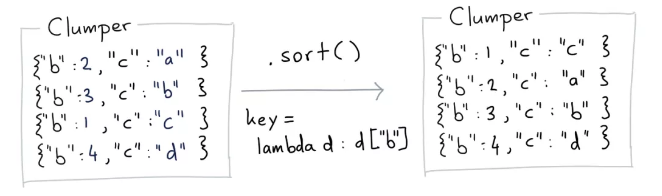
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 3, 'b': 3},
{'a': 2, 'b': 1}]
(Clumper(list_dicts)
.sort(lambda d: d['b']) #默认升序
.collect()
)
[{'a': 2, 'b': 1},
{'a': 1, 'b': 2},
{'a': 3, 'b': 3}]Select
select挑选每条记录中的某个(些)字段
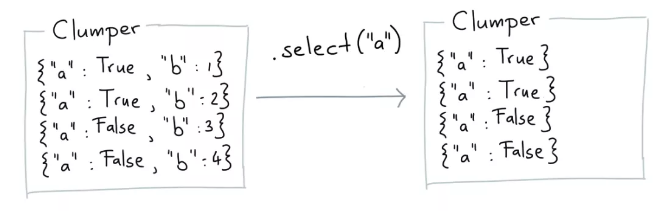
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
(Clumper(list_dicts)
.select('a')
.collect()
)
[{'a': 1},
{'a': 2},
{'a': 1}]Drop
剔除某个(些)字段。

from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
(Clumper(list_dicts)
.drop('c')
.collect()
)
[{'a': 1, 'b': 2},
{'a': 2, 'b': 3},
{'a': 1, 'b': 6}]GroupBy
根据某个(些)字段对数据集进行分组,得到不同Group类的集合。一般与.agg()方法联合使用。

from clumper import Clumper
grade_dicts = [
{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.group_by("gender")
.groups==('gender', )
)
TrueUngroup
GroupBy的反操作

from clumper import Clumper
grade_dicts = [
{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.group_by("gender")
.ungroup().groups == tuple()
)
True
Agg
聚合描述性统计方法
agg如下图,可以理解成三个步骤,即group->split->summary
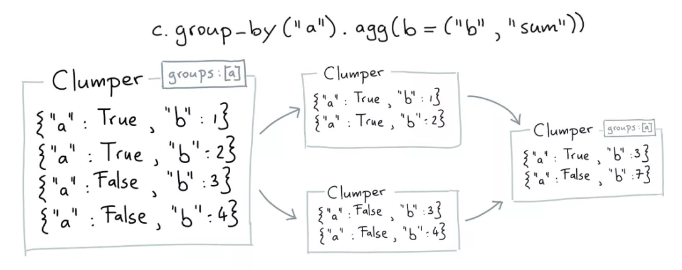
常用的描述性统计函数有:mean、count、unqiue、n_unique、sum、min和max
求学生的平均成绩、最优和最差成绩
from clumper import Clumper
grade_dicts = [{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.agg(mean_grade=('grade', 'mean'),
max_grade=('grade', 'max'),
min_grade=('grade', 'min'))
.collect()
)
[{'mean_grade': 85.75, 'max_grade': 99, 'min_grade': 58}]
求男生和女生各自的平均成绩、最优和最差成绩
from clumper import Clumper
grade_dicts = [{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.group_by('gender')
.agg(mean_grade=('grade', 'mean'),
max_grade=('grade', 'max'),
min_grade=('grade', 'min'))
.collect())
[{'gender': '男', 'mean_grade': 78, 'max_grade': 98, 'min_grade': 58},
{'gender': '女', 'mean_grade': 93.5, 'max_grade': 99, 'min_grade': 88}]
Collect
一般Clumper函数返回的结果显示为Clumper类,是看不到具体内容的。
collect作用主要是展开显示。

剔除重复
剔除重复内容
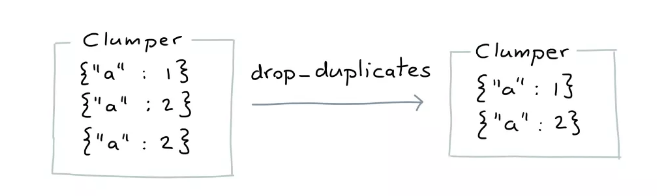
from clumper import Clumper
data = [{"a": 1}, {"a": 2}, {"a": 2}]
(Clumper(data)
.drop_duplicates()
.collect()
)
[{'a': 1}, {'a': 2}]
什么是Group?
from clumper import Clumper
list_dicts = [
{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'},
{'a': 5, 'grp': 'a'}
]
(Clumper(list_dicts)
.group_by('grp')
)
<Clumper groups=('grp',) len=5 @0x103cb0290>
当前的group以grp作为关键词
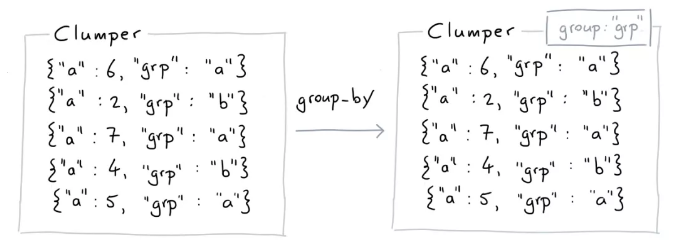
现在经过 .group_by('grp')操作后,说明你对每个grp组感兴趣。具体一点,一个组是{'grp': 'a'}, 另一个组是{'grp': 'b'}.
Agg
without groups
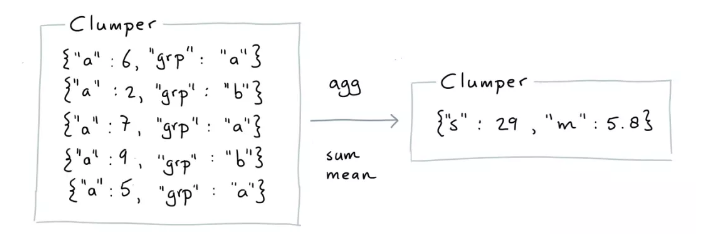
from clumper import Clumper
list_dicts = [
{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'},
{'a': 5, 'grp': 'a'}
]
(Clumper(list_dicts)
.agg(s=('a', 'sum'),
m=('a', 'mean'))
.collect())
[{'s': 29, 'm': 5.8}]
with groups
分别计算组grp=a、组grp=b的sum和mean
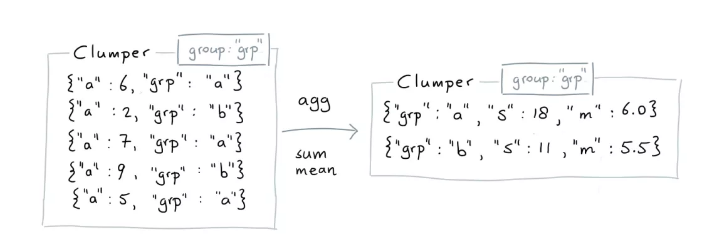
from clumper import Clumper
list_dicts = [
{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'},
{'a': 5, 'grp': 'a'}
]
(Clumper(list_dicts)
.group_by('grp')
.agg(s=('a', 'sum'),
m=('a', 'mean'))
.collect())
[{'grp': 'a', 's': 18, 'm': 6},
{'grp': 'b', 's': 11, 'm': 5.5}]
agg内置的统计函数名
内置的统计函数,可直接通过字符串调用
{
"mean": mean,
"count": lambda d: len(d),
"unique": lambda d: list(set(d)),
"n_unique": lambda d: len(set(d)),
"sum": sum,
"min": min,
"max": max,
"median": median,
"var": variance,
"std": stdev,
"values": lambda d: d,
"first": lambda d: d[0],
"last": lambda d: d[-1],
}
Transform
.transform()与.agg()类似。主要的区别是transform处理过程中,记录数和字段数不会出现压缩。
without groups

from clumper import Clumper
data = [{"a": 6, "grp": "a"},
{"a": 2, "grp": "b"},
{"a": 7, "grp": "a"},
{"a": 9, "grp": "b"},
{"a": 5, "grp": "a"}]
(Clumper(data)
.transform(s=("a", "sum"),
u=("a", "unique"))
.collect())
[{'a': 6, 'grp': 'a', 's': 29, 'u': [2, 5, 6, 7, 9]},
{'a': 2, 'grp': 'b', 's': 29, 'u': [2, 5, 6, 7, 9]},
{'a': 7, 'grp': 'a', 's': 29, 'u': [2, 5, 6, 7, 9]},
{'a': 9, 'grp': 'b', 's': 29, 'u': [2, 5, 6, 7, 9]},
{'a': 5, 'grp': 'a', 's': 29, 'u': [2, 5, 6, 7, 9]}]
with groups

from clumper import Clumper
data = [
{"a": 6, "grp": "a"},
{"a": 2, "grp": "b"},
{"a": 7, "grp": "a"},
{"a": 9, "grp": "b"},
{"a": 5, "grp": "a"}
]
(Clumper(data)
.group_by("grp")
.transform(s=("a", "sum"),
u=("a", "unique"))
.collect()
)
[{'a': 6, 'grp': 'a', 's': 18, 'u': [5, 6, 7]},
{'a': 7, 'grp': 'a', 's': 18, 'u': [5, 6, 7]},
{'a': 5, 'grp': 'a', 's': 18, 'u': [5, 6, 7]},
{'a': 2, 'grp': 'b', 's': 11, 'u': [9, 2]},
{'a': 9, 'grp': 'b', 's': 11, 'u': [9, 2]}]
Mutate
clumper库中的row_number可以给每条记录显示索引位置(第几个)。
without groups

from clumper import Clumper
from clumper.sequence import row_number
list_dicts = [
{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 4, 'grp': 'b'},
{'a': 5, 'grp': 'a'}
]
(Clumper(list_dicts)
.mutate(index=row_number())
.collect()
)
[{'a': 6, 'grp': 'a', 'index': 1},
{'a': 2, 'grp': 'b', 'index': 2},
{'a': 7, 'grp': 'a', 'index': 3},
{'a': 4, 'grp': 'b', 'index': 4},
{'a': 5, 'grp': 'a', 'index': 5}]
with groups

from clumper import Clumper
from clumper.sequence import row_number
list_dicts = [
{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 4, 'grp': 'b'},
{'a': 5, 'grp': 'a'}
]
(Clumper(list_dicts)
.group_by('grp')
.mutate(index=row_number())
.collect()
)
[{'a': 6, 'grp': 'a', 'index': 1},
{'a': 7, 'grp': 'a', 'index': 2},
{'a': 5, 'grp': 'a', 'index': 3},
{'a': 2, 'grp': 'b', 'index': 1},
{'a': 4, 'grp': 'b', 'index': 2}]
Sort
排序, 默认升序
without groups
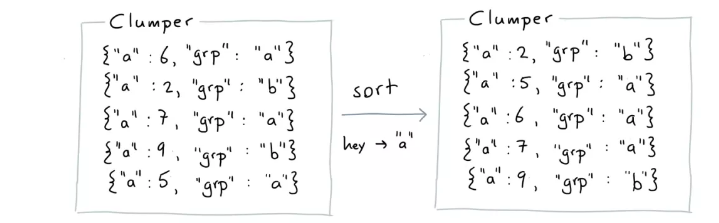
from clumper import Clumper
list_dicts = [{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'},
{'a': 5, 'grp': 'a'}]
(Clumper(list_dicts) #根据字段a进行排序
.sort(key=lambda d: d['a'])
.collect())
[{'a': 2, 'grp': 'b'},
{'a': 5, 'grp': 'a'},
{'a': 6, 'grp': 'a'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'}]
with groups
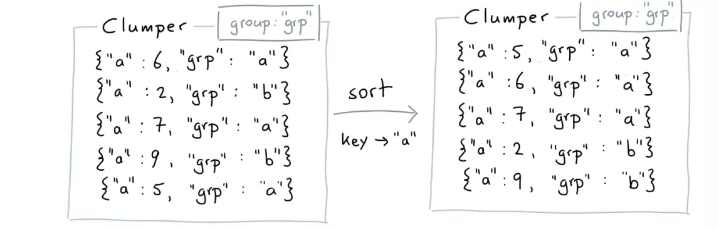
from clumper import Clumper
list_dicts = [{'a': 6, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 7, 'grp': 'a'},
{'a': 9, 'grp': 'b'},
{'a': 5, 'grp': 'a'}]
(Clumper(list_dicts)
.group_by('grp')
.sort(key=lambda d: d['a'])
.collect())
[{'a': 5, 'grp': 'a'},
{'a': 6, 'grp': 'a'},
{'a': 7, 'grp': 'a'},
{'a': 2, 'grp': 'b'},
{'a': 9, 'grp': 'b'}]
Ungroup
最后,如果你已经进行完了分组计算,想再次整合起来,取消分组状态,可以使用.ungroup()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人