

python3笔记九:python数据类型-String字符串
一:学习内容
- 字符串概念
- 字符串运算
- 字符串函数:eval()、len()、lower()、upper()、swapcase()、capitalize()、title()、center()、ljust()、rjust()、zfill()、count()、find()、rfind()、index()、rindex()、lstrip()、rstrip()、strip()、ord()、chr()、split()、splitlines()、join()、max()、min()、replace()、startswith()、endswith()、encode()、decode()、isalpha()、isalnum()、isdigit()、isupper()、islower()、istitle()、isspace()
二:字符串概念
1. 字符串是以单引号或双引号括起来的任意文本
'abc'
"abc"
2.创建字符串
str1 = "learn python3!"
三:字符串运算
1. 字符串连接
str2 = "hello "
str3 = "world!"
str4 = str2 + str3
print("str4 =", str4)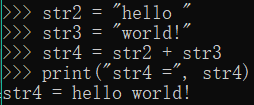
2.输出重复字符串
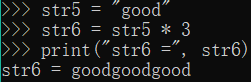
str5 = "good"
str6 = str5 * 3
print("str6 =", str6)
3.访问字符串中的某一个字符
#通过索引下标查找字符,索引从0开始
#字符串名[下标]
str7 = "test is a good girl!"
print(str7[1])

str7[1] = "a" #字符串不可变
print(str7)

4.截取字符串中的一部分
#字符串名[开始下标:结束下标],属于闭开区间
str7 = "test is a good girl!"
str8 = str7[7:16]
print("str8 =", str8)
#从头截取到给定下标之前,不包括结束下标
str9 = str7[0:6] #str7[:6]
print("str9 =", str9)
#从给定下标处开始截取到结尾
str10 = str7[17:] #str7[:6]
print("str10 =", str10)

5.判断给出的字符串是否存在
str11 = "test is a good girl"
print("good" in str11)
print("good1" not in str11)

6.格式化输出
# %d %s %f 占位符
print("test is a good girl")
num = 10
print("num =", num)
print("num = %d" % num)

str12 = "test"
f = 10.1234567890
#%.2f精确到小数点后3位,会四舍五入
print("num = %d, str12 = %s, f = %.2f" % (num, str12, f))

四:字符串函数
1. eval(str)函数
功能:将字符串str当成有效的表达式来求值并返回计算结果
num1 = eval("123")
print("num1的值为:%d" % num1)
print(type(num1))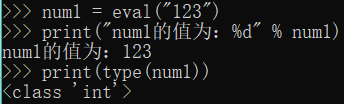
print(eval("-123"))
print(eval("12-3"))
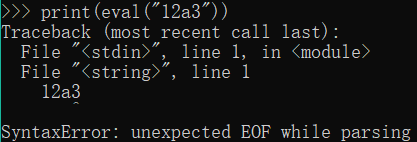
print(eval("12a3"))
2.len(str)函数
功能:返回字符串的长度(字符个数,不是字节数,一个中文是一个字符)
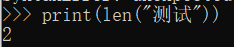
print(len("测试"))
3.str.lower()函数
功能:转换字符串中大写字母为小写字母,原字符串不变
str13 = "TEST is A GooD GirL"
print(str13.lower())
print(str13)

4.str.upper()函数
功能:转换字符串中小写字母为大写字母,原字符串不变
str14 = "TEST is A GooD GirL!测试"
print(str14.upper())
print(str14)

5.str.swapcase()
功能:转换字符串中小写字母为大写字母,大写变小写,原字符串不变
str15 = "Test Is A Good Girl!测试"
print(str15.swapcase())

6.str.capitalize()
功能:首字母大写,其他小写,原字符串不变
str16 = "test is a good girl!测试"
print(str16.capitalize())

7.str.title()
功能:每个单词的首字母大写,其他小写,原字符串不变
str17 = "test is a good girl"
print(str17.title())

8.str.center(width[,fillchar])
功能:返回一个指定宽度的居中字符串,fillchar为填充的字符串,默认是空格填充
str18 = "test is a good girl"
print(str18.center(40,"*"))

9.str.ljust(width[,fillchar])
功能:返回一个指定宽度的左对齐字符串,fillchar为填充的字符串,默认是空格填充
str19 = "test is a good girl"
print(str19.ljust(40,"*"))

10.str.rjust(width[,fillchar])
功能:返回一个指定宽度的右对齐字符串,fillchar为填充的字符串,默认是空格填充
str19 = "test is a good girl"
print(str19.rjust(40,"*"))

11.str.zfill(width)
功能:返回一个指定宽度的字符串,左侧用0填充
str20 = "test is a good girl"
print(str20.zfill(40))

12.str.count(s[,start][,end])
功能:返回str字符串中s字符串出现的次数,可以指定一个范围,不指定范围默认从头到尾
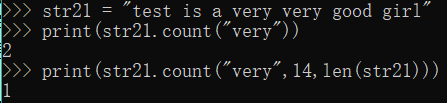
str21 = "test is a very very good girl"
print(str21.count("very"))
print(str21.count("very",14,len(str21)))
13.str.find(s[,start][,end])
功能:从左向右检测s字符串是否包含在字符串中,可以指定范围,不指定范围默认从头到尾
返回的结果是s字符串第一次出现的开始下标,没有则返回-1
str22 = "test is a very very good girl"
print(str22.find("very"))
print(str22.find("very",14,len(str22)))
print(str22.find("ddd")) #返回-1

14.str.rfind(s[,start][,end])
功能:从右向左检测s字符串是否包含在字符串中,可以指定范围,不指定范围默认从头到尾
返回的结果是s字符串第一次出现的开始下标,没有则返回-1
str23 = "test is a very very good girl"
print(str23.rfind("very"))
print(str23.rfind("very",0,15))
print(str23.rfind("ddd")) #返回-1

15.str.index(s[,start][,end])
跟find()一样,只不过如果s不存在的时候会报异常
功能:从左向右检测s字符串是否包含在字符串中,可以指定范围,不指定范围默认从头到尾
返回的结果是s字符串第一次出现的开始下标
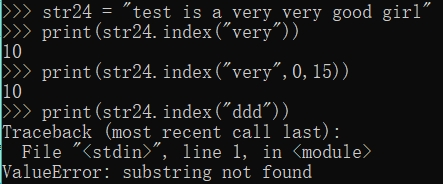
str24 = "test is a very very good girl"
print(str24.index("very"))
print(str24.index("very",0,15))
print(str24.index("ddd")) #找不到会报错,报错
16.str.rindex(s[,start][,end])
跟rfind()一样,只不过如果s不存在的时候会报异常
功能:从右向左检测s字符串是否包含在字符串中,可以指定范围,不指定范围默认从头到尾
返回的结果是s字符串第一次出现的开始下标
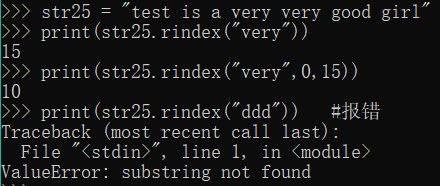
str25 = "test is a very very good girl"
print(str25.rindex("very"))
print(str25.rindex("very",0,15))
print(str25.rindex("ddd")) #报错
17.str.lstrip(s)
功能:截取str左侧的指定的字符,默认为空格
str26 = " test is a very good girl"
print(str26.lstrip())
str26 = "*****test is a very good girl"
print(str26.lstrip("*"))

18.str.rstrip(s)
功能:截取str右侧的指定的字符,默认为空格
str27 = "test is a very good girl "
print(str27.rstrip())
str27 = "*****test is a very good girl*****"
print(str27.rstrip("*"))

19.str.strip(s)
功能:截取str左右两侧的指定的字符,默认为空格
str28 = "****test is a very good girl****"
print(str28.strip("*"))
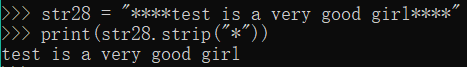
20.ord(s)、chr(97)
ord(s)功能:返回字符的ASCII码值
chr(97)功能:返回ASCII码值对应的字母
str29 = "z"
print(ord(str29))
print(chr(90))

21.字符串比较大小
#从第一个字符开始比较比较谁的ASCII码值大,谁就大
#如果第一个字符相等,则比较第二个以此类推
print("baaa" > "azzz")

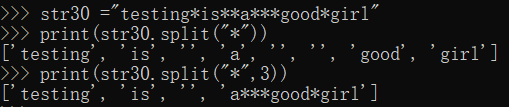
22.split(str="",num)
#以str为分隔符截取字符串,指定num,则仅截取num个字符串
str30 ="testing*is**a***good*girl"
print(str30.split("*"))
print(str30.split("*",3)) #值截取3次,剩余部分是一个整体
23.splitlines([keepends]) 按照(\r \n \r\n)分隔,按行切割
#keeppends == True 会保留换行符,默认是False
str31 =''' testing is a good girl!
testing is a nice girl!
testing is a handsome girl!'''
print(str31.splitlines())
print(str31.splitlines(True))

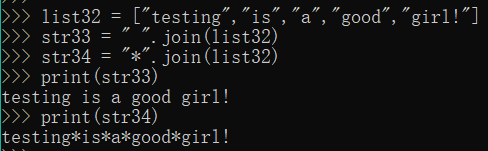
24."".join(seq),以指定的字符串分隔符,将seq中的所有元素组合成一个字符串
list32 = ["testing","is","a","good","girl!"]
str33 = " ".join(list32)
str34 = "*".join(list32)
print(str33)
print(str34)
25.max(str),求字符串最大的元素
str35 = "testing is a nice girl!"
print(max(str35))

26.min(str),求字符串最小的元素,按Ascii来比较的,最小的是个空格所以看着像没打印一样
str36 = "testing is a nice girl!"
print(min(str36))

27.replace(old,new,num)将字符串num个的old替换成new,num不写默认为全部
str37 = "testing is a good good good girl!"
str38 = str37.replace("good","nice") #全部替换
print(str37)
print(str38)
str39 = str37.replace("good","nice", 1) #只替换一次
print(str39)

28.startswith(str[,start=0][end=len(str)]),在给定的范围内判断是否是以给定的字符串开头,默认整个字符串
str43 = "testing is a good girl!"
print(str43.startswith("testing"))
print(str43.startswith("tester"))
print(str43.startswith("testing",5,16))

29.endswith(str[,start=0][end=len(str)]),在给定的范围内判断是否是以给定的字符串结尾,默认整个字符串
str44 = "testing is a good girl!"
print(str44.endswith("girl"))
print(str44.endswith("tester"))
print(str44.endswith("girl",5,16))

30.编码
#encode(encoding="utf-8",errors="strict")
#encode(encoding="utf-8",errors="ignore"),ignore代表处理不处理
str45 = "testing is a good 测试!"
data46 = str45.encode()
print(data46)
print(type(data46))

31.解码
#decode(encoding="utf-8",errors="strict")
#decode(encoding="utf-8",errors="ignore"),ignore代表处理不处理
str47 = data46.decode("utf-8") #这里要与编码时的encoding一致
print(str47)

str48 = data46.decode("gbk",errors="ignore") #这里要与编码时的encoding一致,不一致会报错但是我的errors="ignore",即不处理错误,这样就会解码出乱码
print(str48)

32.isalpha():全是字母
#如果字符串中至少有一个字符,且所有字符都是字母返回True,否则返回False
str48 = "testing is a good girl"
print(str48.isalpha()) #返回False,因为有空格
str48 = "testingisagoodgirl"
print(str48.isalpha())

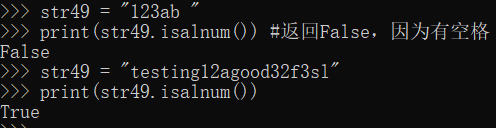
33.isalnum():全是数字和字母
#如果字符串中至少有一个字符,且所有字符都是字母或者数字返回True,否则返回False
str49 = "123ab "
print(str49.isalnum()) #返回False,因为有空格
str49 = "testing12agood32f3sl"
print(str49.isalnum())
34.isdigit():全是数字
#如果字符串只包含数字返回Ture,否则返回False
print("123".isdigit()) #返回True
print("123a".isdigit()) #返回False,因为有字母

35.isupper():如果是字母必须是大写
#如果字符串中至少有一个英文字符,且所有英文字符都是大写的,数字和其他字符没关系返回True,否则返回False
str50 = "Ad"
print(str50.isupper()) #返回False,因为小写字母
str50 = "22ADF"
print(str50.isupper()) #返回True

36.islower():如果是字母必须是小写
#如果字符串中至少有一个英文字符,且所有英文字符都是小写的,数字和其他字符没关系返回True,否则返回False
str51 = "Ad"
print(str51.islower()) #返回False,因为大写字母
str51 = "123#"
print(str51.islower()) #返回False,因为没有一个小写字母
str51 = "22adf#@"
print(str51.islower()) #返回True

37.istitle():标题化(每个单词的首字母大写)
#如果字符串是标题化的,返回True,否则返回False
print("Test Is".istitle()) #返回True
print("Test is".istitle()) #返回False,因为有一个单词的首字母没有大写
print("testing is".istitle()) #返回False,因为单词的首字母没有大写

38.isspace():只包含空白符(空格、\t、\n、\r、\r\n)
#如果字符串中只包含空白符则返回True,否则返回False
print(" ".isspace()) #返回True
print(" ".isspace()) #返回True
print("\t".isspace()) #返回True,因为\t出来是4个空格
print("\n".isspace()) #返回True
print("\r".isspace()) #返回True
print("\r\n".isspace()) #返回True




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!