
第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业

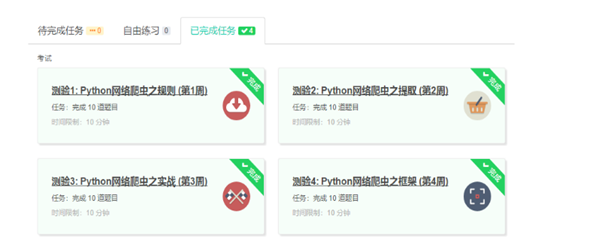
4.提供图片或网站显示的学习进度,证明学习的过程。

5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过对该课程的学习,我更深一步地了解了Python爬虫的功能和应用场景。在大数据越来越重要的今天,网络爬虫的应用也越来越多,由于在互联网中的数据是巨大的,当我们想要对有用和想要的信息进行提取时,爬虫的作用就得以体现出来了,能够高效以及自动化的对我们想要的数据信息进行收集。而课程中也提到,未来更多的数据和信息会被保存在网页之中,那么学习Python爬虫对将来的学习或者工作中能够得到非常高效的帮助。
而在对课程的学习中,认识到了Python爬虫中一个重要的第三方库——requests库,也是当前最流行,最简便的获取用于网络信息的一个库,使用requests库,可以使用数行代码实现自动化的http操作。而requests有七个主要方法。get方法是其中最常用到的,最通常的方法是通过r=request.get(url)构造一个向服务器请求资源的url对象。这个对象是Request库内部生成的。这时候的r返回的是一个包含服务器资源的Response对象。而之后介绍了当requests库产生异常的各种情况,例如requests.Connection 网络连接错误异常,如DNS查询失败、拒绝连接等。同时讲解了各种异常处理的各种方法,其中就有查看其状态码是否为200来查看情况,或者使用代码框架来抛出异常。
之后在讲解beautiful soup库时,了解到它是一个可以对HTML、LXML格式进行解析,并且能对你给的文档进行数形解析。在选择元素的时候直接对调用标签的名字进行选择节点,还可以使用attrs进行查看标签属性,且调用string属性可以获取标签内的文本,这种选择方式非常快,如果单个标签结构层次非常清晰,可以选用这种方式进行解析。在老师对beautiful soup库进行介绍时,认知到了如何对网页数据与HTML的各节点进行分析和提取。进一步的对爬取网页信息有所学习。
而scrapy是一种非常好的应用框架,用于爬取网站数据,提取结构性数据而编写的,可应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中,比如对股票的数据进行采集。Scrapy会实例化数个下载器以并发的方式进行请求的发送,除此之外其他部分组件均为同步顺序执行,因此在组件中尽可能的避免会导致频繁阻塞的代码可以避免影响框架的运行效率。
未来爬虫的应用将会越来越广,就目前来说,python对爬取数据的类型以及多种多样,当从课程中的来看,例如淘宝网上商品价格数据以及股票相关数据,这与我们的生活有很多的关联,对目前学习的python爬虫来讲,在今后的使用中要会灵活应用仍需要不断地练习。
