

第一次个人编程作业
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。(3')
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 90 | 150 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 10 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 5 | 5 |
| · 合计 | 390 | 570 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
敏感词类MGC://存储输入的敏感词信息,按词存储
包括:敏感词序号,敏感词本身的字符串,长度(utf-8码的长度,一个汉字占3个字节),敏感词类型(中文|英文),敏感词总数
行类HANG://存储需要检测的文本,按行存储
包括:行序号,行本身的字符串;长度(同上),行总数
答案类ANS://将得到的结果按行存储
包括:敏感词序号,行序号,对应行的字段定位(便于输出问题字段),答案总条数
检测函数search://对敏感词检测,是程序的核心算法,也是难度最高,占用资源最多的部分
void search(MGC &M,HANG &H)//输入对应的敏感词和行,不破坏行和词本身,检测到敏感字段即存入答案类
{
int i = 0, j = 0, head;
if (M.k == 1)//敏感词为汉字
{
//连续3个字节相同,则进行匹配;若敏感词长度为n字节,则需匹配n/3次才算完成
for (; j < H.l; j++) if (H.s[j] == M.w[i]&& H.s[j+1] == M.w[i+1]&& H.s[j+2] == M.w[i+2])
{
if (i == 0) head = j;//第一次匹配时,对文章对应位置定位
i += 3;
j += 2;
if (i == M.l)//匹配完成,记录信息,从当前位置继续查找该敏感词
{
i = 0;
Ans[Ans_num].mgc_num = M.num;
Ans[Ans_num].hang_num = H.num;
Ans[Ans_num].h = head;
Ans[Ans_num++].e = j;
}
}
}
else//敏感词为英文
{
//不区分大小写,相同则匹配;若敏感单词长度为m字节,则匹配m次
for (; j < H.l; j++) if ((H.s[j] == M.w[i]) || (H.s[j] - M.w[i] == 32 && M.w[i] <= 'Z') || (M.w[i] - H.s[j] == 32 && M.w[i] >= 'a'))
{
if (i == 0) head = j;
i++;
if (i == M.l)//匹配完成,记录信息,从当前位置继续查找该敏感词
{
i = 0;
Ans[Ans_num].mgc_num = M.num;
Ans[Ans_num].hang_num = H.num;
Ans[Ans_num].h = head;
Ans[Ans_num++].e = j;
}
}
}
}
输出函数ANS_print: //输出优先级:将答案类ANS输出到指定路径,行序号优先;同行时按敏感词序号优先;对于行号和词号一致的语句,看两者在对应行的出现顺序
思路:
分别读入敏感词文件f1、待检测文本f2,存储到对应的类中;
检测函数search:我的做法是将字符串的ASCII码与敏感词的ASCII码进行匹配(虽然能很快查找到正常情况下的敏感字段,但对同音字和拆边旁的情况存在很大的困难)能找到多少找多少,存入对应的类中
最后由对应的函数将结果输出
流程图:
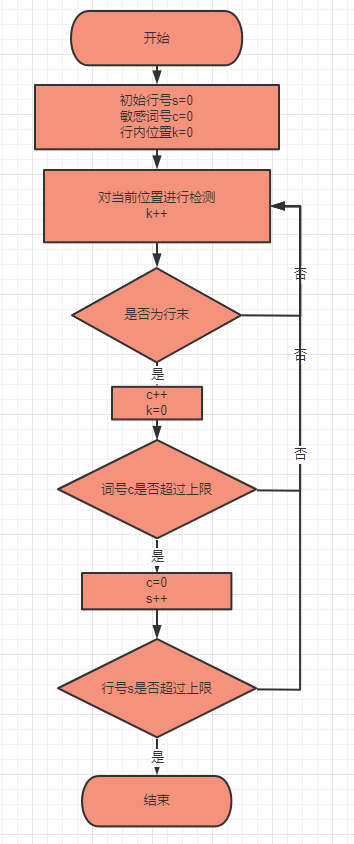
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
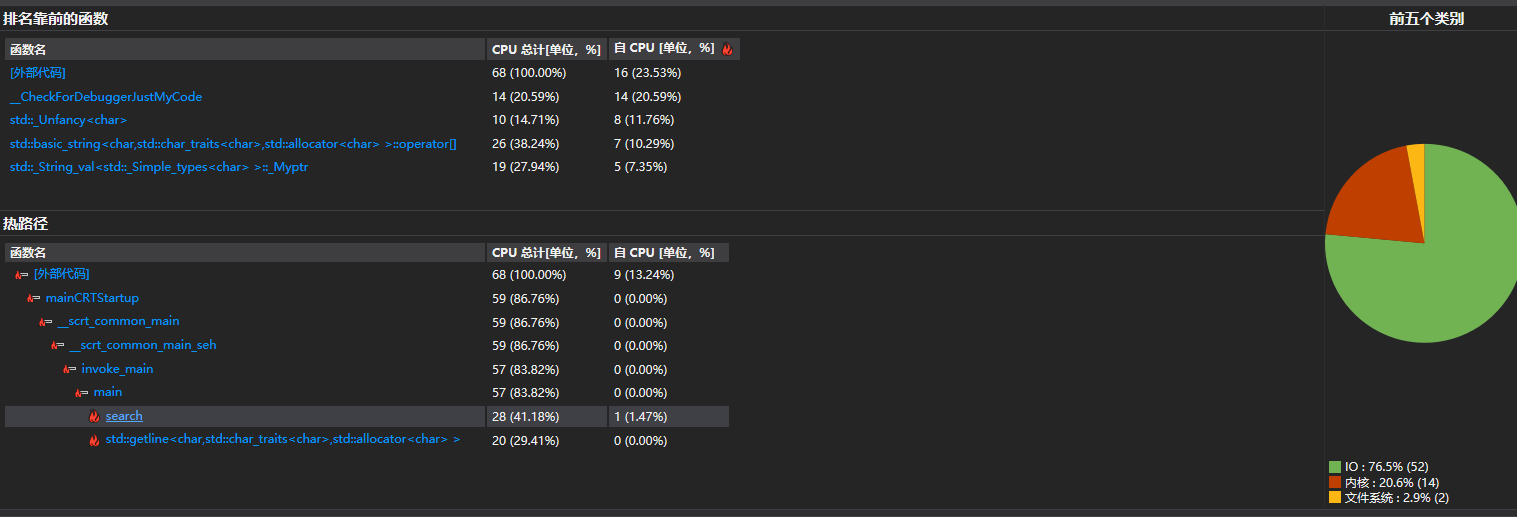

以上是用范例测试后得到的结果,其中检测函数search占了40%以上的cpu时间,占比最大;另外输入数据的处理也要花费不少的cpu时间;
结果与预想差不多,毕竟整个程序的核心算法就是敏感词的检测函数search,并且按我的算法,search的时间复杂度与(敏感词数*文本行数)成正比,当样例的敏感词数增加时,search消耗的cpu占比或许再度增加;
虽然占比较高,但实质消耗的时间相对合理,也没有改进的思路,故没对其进行改进;
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
测试1:(即作业给出的范例)
输入对应的3个地址:
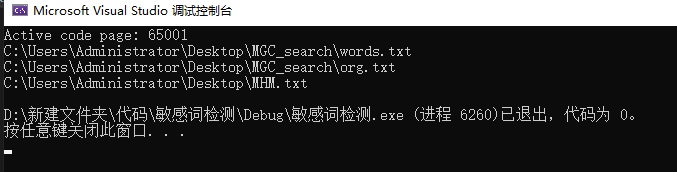
我输出的答案:
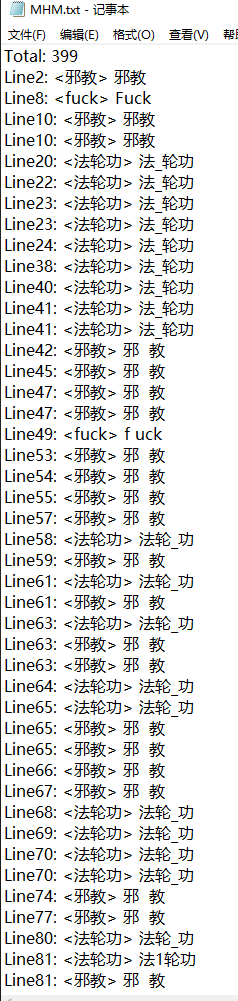
示例给出的答案:

(我只找出了400个,主要是目前的进展对同音字和边旁还不能很好的解决)
测试2:分别给出(敏感词a,文章b, 答案c)

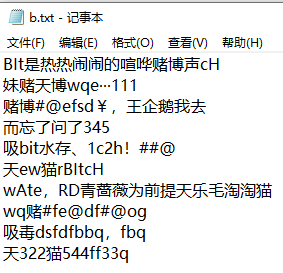
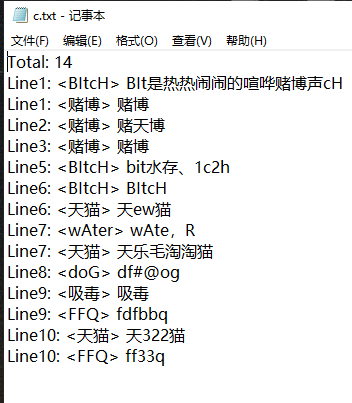
测试3:分别给出(敏感词a,文章b, 答案c)

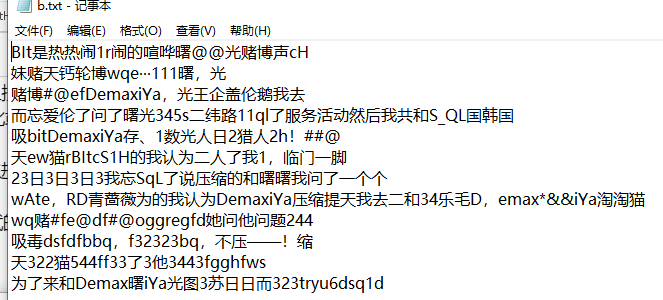
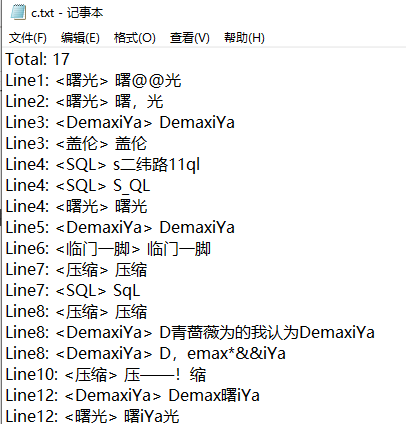
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
//读入敏感词文件f1,并放入敏感词类的数组(Mgc[])中
cin >> dz;
ifstream f1(dz);
if (!f1) cout << "open error!" << endl;
。。。。。
当读入文件出现问题时,输出
open error!
例如:

当输入正确的路径时,不会报错:

三、心得
(4.1)在完成本次作业过程的心得体会(3')
开发思路及遇到的困难:
1.用c++读写文件时遇到困难,学习了fstream等知识,掌握基本的读写文件流;
2.用DevC++和VS测试txt文件的读写功能时,发现中文的乱码现象;经学习和查阅资料,问题在于txt文件默认用utf-8编码,而Windows控制台默认用ANSI(GBK)编码,故控制台会出现中文的乱码,虽不影响该次作业生成的txt文件结果,但给开发、测试及维护过程造成了许多的不方便;
解决方法:将VS设置成utf-8编码,并且在main函数开始处加入语句:system("chcp 65001"),语句功能为将控制台修改为utf-8编码;使程序全程使用utf-8编码,便于编写和维护;
3.对程序进行测试,测试过程中遇到输入的路径打不开的现象,发现路径中包含了中文,改为英文后此问题便没再发生
总结:学了许多知识,但离完全攻下此题还有很大的差距,还要再努力呀

