redis-4.0.14 cluster 配置实战
1.操作系统配置
切换到root用户修改配置sysctl.conf
vim /etc/sysctl.conf # 添加配置: vm.max_map_count=655360 vm.overcommit_memory=1 net.core.somaxconn= 32767 fs.file-max=65535 # ulimit -n 最大文件描述符 65536 vim /etc/security/limits.conf # 添加 * soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536 vi /etc/security/limits.d/20-nproc.conf #加大普通用户限制,也可以改为 unlimited * soft nproc 40960 root soft nproc unlimited
reboot或者重新登录
主节点平均分配到不同的机器上,否则容易造成单点故障以及复制风暴。
操作系统关闭THP:
vim /etc/rc.d/rc.local if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
然后给rc.local添加可执行权限:
chmod +x /etc/rc.d/rc.local
重启生效
2.redis安装准备
yum -y install gcc gcc-* automake autoconf libtool make zlib zlib-devel glibc-* tcl tree
2.1 redis下载及安装
# 创建安装目录: mkdir /usr/local/redis-4.0.14 # 创建软连接: ln -s /usr/local/redis-4.0.14 /usr/local/redis # 官网 wget http://download.redis.io/releases/redis-4.0.14.tar.gz -P /opt
2.2 安装redis(在三个服务器分别依次执行如下命令)
cd /opt tar xzf redis-4.0.14.tar.gz cd redis-4.0.14 cd src make && echo $? make test && echo $? # 这里如果报错,可以重新执行一遍就好了,有点莫名其妙的 make MALLOC=libc echo $? make PREFIX=/usr/local/redis install && echo $?
3. redis 基本配置
3.1 配置文件修改
创建目录:
mkdir -p /usr/local/redis/{conf,data,logs}
bind 0.0.0.0 # 测试环节,任何地址都可连接
port 6379 # 修改成对应的端口号
daemonize yes # 后台运行
pidfile /var/run/redis_6379.pid # pid文件
logfile "./redis.log" # 日志
dir /usr/local/redis/data # 设置文件数据存储路径
rename-command FLUSHALL adminFLUSHALL # 禁止危险命令
rename-command FLUSHDB adminFLUSHDB # 禁止危险命令
# rename-command KEYS adminKEYS # 禁止危险命令
rename-command SCAN adminSCAN # 禁止危险命令
rename-command CONFIG "" # 信息安全:防止redis被非法连接后,使用config命令对操作系统进行控制;另:要求redis使用非root帐号运行
maxclients 100000 # 集群支持的最大连接
timeout 60 # 设置空闲连接超时时间
maxmemory 6000M # Redis默认无限使用服务器内存,为防止极端情况下导致系统内存耗 尽,建议所有的Redis进程都要配置maxmemory, 要保证机器本身有30%左右的闲置内存
maxmemory-policy volatile-lru # 内存剔除策略logfile “” 默认为空,则在控制台打印,否则输出日志到指定的log文件
save "" # 通用配置,关闭RDB持久化,只使用AOF。
appendonly yes # 开启 aop 备份
masterauth 0NZcyqRqLUteci7D # 设置 master 节点的认证密码
requirepass 0NZcyqRqLUteci7D # 设置 redis 连接密码
appendfilename "appendonly-8379.aof" # 设置持久化文件名称
appendfsync always # 每写一条 备份 一次
cluster-enabled yes # 开启 Redis Cluster
cluster-config-file nodes-6379.conf # 记录集群信息,不用手动维护,Redis Cluster 会自动维护
cluster-node-timeout 2000 # Cluster 集群节点连接超时时间,如果集群规模小,都在同一个网络环境下,可以配置的短些,更快的做故障转移。
cluster-require-full-coverage no # 设置为no,默认为yes,故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法容忍这种情况,因此要设置为no,当主节点故障时只影 响它负责槽的相关命令执行,不会影响其他主节点的可用性。只要有结点宕机导致16384个槽没全被覆盖,整个集群就全部停止服务,所以一定要改为no
no-appendfsync-on-rewrite yes # 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,提高redis写入性能
protected-mode no # 允许外部主机访问
slowlog-log-slower-than 1000 # 慢查询日志,用于性能分析,生产环境可设置为1000(微妙)
slowlog-max-len 1000 # 保存慢查询的队列长度 ,设置为1000
cluster-slave-validity-factor 0 # 设置为0,如果master slave都挂掉, slave跟master失联又超过这个数值*timeout的数值, 就不会发起选举了。如果设置为0,就是永远都会尝试发起选举,尝试从slave变为mater
==================================================================================================================
vim /usr/local/redis/conf/redis-8379.conf
bind 0.0.0.0
port 8379
daemonize yes
pidfile /var/run/redis_8379.pid
logfile "/usr/local/redis/logs/redis.log"
dir /usr/local/redis/data
rename-command FLUSHALL adminFLUSHALL
rename-command FLUSHDB adminFLUSHDB
# rename-command KEYS adminKEYS
rename-command SCAN adminSCAN
rename-command CONFIG ""
maxclients 100000
timeout 60
maxmemory 6000M
maxmemory-policy volatile-lru
save ""
appendonly yes
masterauth 0NZcyqRqLUteci7D
requirepass 0NZcyqRqLUteci7D
appendfilename "appendonly-8379.aof"
appendfsync always
cluster-enabled yes
cluster-config-file /usr/local/redis/conf/nodes-8379.conf
cluster-node-timeout 15000
cluster-require-full-coverage no
no-appendfsync-on-rewrite yes
protected-mode no
---------------------------------------------------------
vim /usr/local/redis/conf/redis-8380.conf
bind 0.0.0.0
port 8380
daemonize yes
pidfile /var/run/redis_8380.pid
logfile "/usr/local/redis/logs/redis.log"
dir /usr/local/redis/data
rename-command FLUSHALL adminFLUSHALL
rename-command FLUSHDB adminFLUSHDB
# rename-command KEYS adminKEYS
rename-command SCAN adminSCAN
rename-command CONFIG ""
maxclients 100000
timeout 60
maxmemory 6000M
maxmemory-policy volatile-lru
save ""
appendonly yes
masterauth 0NZcyqRqLUteci7D
requirepass 0NZcyqRqLUteci7D
appendfilename "appendonly-8380.aof"
appendfsync always
cluster-enabled yes
cluster-config-file /usr/local/redis/conf/nodes-8380.conf
cluster-node-timeout 15000
cluster-require-full-coverage no
no-appendfsync-on-rewrite yes
protected-mode no
=========================================================
依次启动6个 Redis 实例:
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis-8379.conf
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis-8380.conf
启动完毕之后,使用 Redis 源码包中附带的 Ruby 工具创建集群。
4 Redis-4.0 Cluster创建
4.1 ruby工具准备
因为要使用 Ruby 工具,所以要先保证有 Ruby 环境,并且安装 Redis 插件。
cd /opt
gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB

curl -L get.rvm.io | bash -s stable

source /usr/local/rvm/scripts/rvm
# 查看rvm库中已知的ruby版本
rvm list known
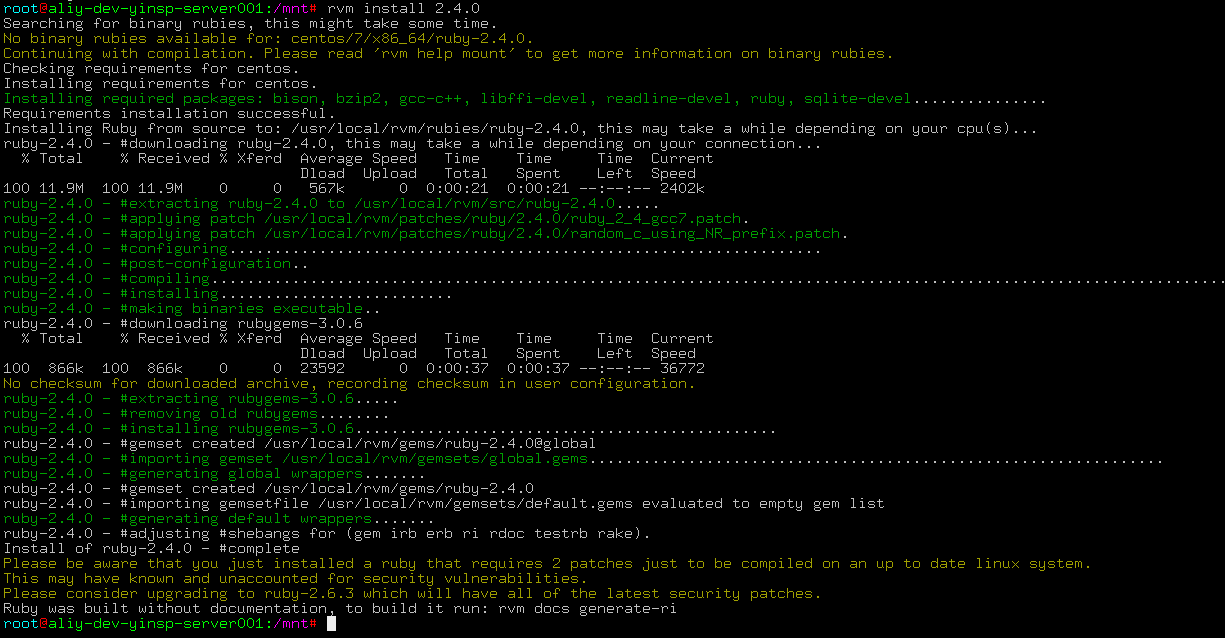
# 安装一个ruby版本
rvm install 2.4.0
# 使用一个ruby版本
rvm use 2.4.0

# 卸载一个已知版本
rvm remove 2.0.0
# 查看版本
ruby --version
# 再安装redis就可以了
gem install redis
cp /opt/redis-4.0.14/src/redis-trib.rb /usr/local/redis/bin/
4.2 创建集群注意事项
注意:创建集群之前,如果配置文件中配置了密码的,执行集群创建命令会报类似如下错误:
[root@aliy-prod-redis-server001 bin]# ./redis-trib.rb create --replicas 1 10.86.78.152:8379 10.86.78.152:8380 10.86.78.153:8379 10.86.78.153:8380 10.86.78.154:8379 10.86.78.154:8380
>>> Creating cluster
[ERR] Sorry, can't connect to node 10.86.78.152:8379
【解决方法】
vim /usr/local/rvm/gems/ruby-2.4.0/gems/redis-4.1.2/lib/redis/client.rb
class Client
DEFAULTS = {
:url => lambda { ENV["REDIS_URL"] },
:scheme => "redis",
:host => "127.0.0.1",
:port => 6379,
:path => nil,
:timeout => 5.0,
:password => "passwd123", # "0NZcyqRqLUteci7D"
:db => 0,
:driver => nil,
:id => nil,
:tcp_keepalive => 0,
:reconnect_attempts => 1,
:inherit_socket => false
}
注意:client.rb路径可以通过find命令查找:find / -name 'client.rb'
4.3 创建redis集群
cd /usr/local/redis/bin/
./redis-trib.rb create --replicas 1 10.86.78.152:8379 10.86.78.152:8380 10.86.78.153:8379 10.86.78.153:8380 10.86.78.154:8379 10.86.78.154:8380
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
10.86.78.143:8379
10.86.78.144:8379
10.86.78.145:8379
Adding replica 10.86.78.144:8380 to 10.86.78.143:8379
Adding replica 10.86.78.145:8380 to 10.86.78.144:8379
Adding replica 10.86.78.143:8380 to 10.86.78.145:8379
M: 8bea76614c3793b90885820e4666461fe6a2d531 10.86.78.143:8379
slots:0-5460 (5461 slots) master
S: 2055b2f822afe3e71fbad7cf2817c87a7e089c2f 10.86.78.143:8380
replicates 3e2aa851ed39ad73bbbabf0a4e5deae2d8eafcf7
M: 1ea11299f4af26b1ff1306b8f2c2255e6dfdfda4 10.86.78.144:8379
slots:5461-10922 (5462 slots) master
S: d9f577ad6dd5589bf96f9f0589c7fd9717d4c94e 10.86.78.144:8380
replicates 8bea76614c3793b90885820e4666461fe6a2d531
M: 3e2aa851ed39ad73bbbabf0a4e5deae2d8eafcf7 10.86.78.145:8379
slots:10923-16383 (5461 slots) master
S: 4a4a38f6035003ec66764104661fac6094ff058f 10.86.78.145:8380
replicates 1ea11299f4af26b1ff1306b8f2c2255e6dfdfda4
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join..
>>> Performing Cluster Check (using node 10.86.78.143:8379)
M: 8bea76614c3793b90885820e4666461fe6a2d531 10.86.78.143:8379
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 4a4a38f6035003ec66764104661fac6094ff058f 10.86.78.145:8380
slots: (0 slots) slave
replicates 1ea11299f4af26b1ff1306b8f2c2255e6dfdfda4
M: 3e2aa851ed39ad73bbbabf0a4e5deae2d8eafcf7 10.86.78.145:8379
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 2055b2f822afe3e71fbad7cf2817c87a7e089c2f 10.86.78.143:8380
slots: (0 slots) slave
replicates 3e2aa851ed39ad73bbbabf0a4e5deae2d8eafcf7
M: 1ea11299f4af26b1ff1306b8f2c2255e6dfdfda4 10.86.78.144:8379
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: d9f577ad6dd5589bf96f9f0589c7fd9717d4c94e 10.86.78.144:8380
slots: (0 slots) slave
replicates 8bea76614c3793b90885820e4666461fe6a2d531
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
看到如 [OK] All 16384 slots covered. 的提示说明集群创建成功。
仔细查看上面的日志信息,M:主节点。S:从节点。可以看到,自动把6个 Redis 分成了 3 个主节点和 3 个从节点,并且 3 个主节点所在服务器是不同的,而从节点的分布也是在三台服务器上各有一个,并且还不和其自己的主节点在同一个服务器,这样做的好处是保证了集群的高可用性。
4.4 redis 集群状态查看
随便连接一个 Redis 进行查看集群操作,连接 Redis 记得使用 -c 参数,表示启用集群模式,可以使用重定向等功能。
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Server
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Stats
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Clients
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Memory
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Persistence
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info Replication
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D info CPU
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D CLUSTER NODES
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D cluster nodes |grep master
/usr/local/redis/bin/redis-cli -c -p 8379 -a 0NZcyqRqLUteci7D cluster nodes |grep slave
上方信息展示说明如下:
- 节点ID
- IP:端口
- 标志:master,slave,myself,,fail,…
- 如果是个从节点,,这里是它的主节点的 NODE ID
- 集群最近一次向节点发送 PING 命令之后, 过去了多长时间还没接到回复。.
- 节点最近一次返回 PONG 回复的时间。
- 节点的配置纪元(configuration epoch):详细信息请参考 Redis 集群规范 。
- 本节点的网络连接情况:例如:connected 。
- 节点目前包含的槽:例如 192.168.117.135:6379 目前包含号码为 0 至 5460 的哈希槽。
4.5 Redis Cluster 常用命令
格式 说明
CLUSTER NODES 查看集群节点信息
CLUSTER REPLICATE <master-id> 进入一个从节点 Redis,切换其主节点
CLUSTER MEET <ip:port> 发现一个新节点,新增主节点
CLUSTER FORGET <id> 忽略一个节点,前提是他不能是有 Solts 的主节点
CLUSTER FAILOVER 手动故障转移
CLUSTER FAILOVER 命令说明:
有时在主节点正常的情况下强制手动故障转移也是必要的,如: 升级主节点的 Redis 进程,可以通过故障转移将其转为 Slave 再进行升级操作来避免对集群的可用性造成影响。
Redis 集群使用 CLUSTER FAILOVER 命令来进行故障转移,不过要在被转移的主节点的从节点上执行该命令;
手动故障转移比主节点失败自动故障转移更加安全,因为手动故障转移时客户端的切换是在确保新的主节点完全复制了失败的旧的主节点数据的前提下下发生的,所以避免了数据的丢失。
其基本过程如下:客户端不再链接我们淘汰的主节点,
同时主节点向从节点发送复制偏移量,
从节点得到复制偏移量后故障转移开始,
接着通知主节点进行配置切换,当客户端在旧的 Master 上解锁后重新连接到新的主节点上。
4.6 redis安全配置
# 访问密码:
如果集群已经创建好,也可以动态设置密码
在集群的所有实例(包含主节点和从节点)中执行
设置集群密码:
# 使用redis-cli连接redis集群
/usr/local/redis/bin/redis-cli -c -p 8379
/usr/local/redis/bin/redis-cli -c -p 8380
config set masterauth 0NZcyqRqLUteci7D
config set requirepass 0NZcyqRqLUteci7D
# 上面的配置 一定要每一个节点都配置执行一遍(包括主节点和从节点)
配置好上面的命令后,需要执行如下命令,将配置写入配置文件,否则下次重启密码就失效了!!!!!
config rewrite
如果刚开始创建集群,可以在redis的配置文件中写入下面两行配置:
1.在集群创建时,配置文件中添加如下两行
masterauth 0NZcyqRqLUteci7D
requirepass 0NZcyqRqLUteci7D
# 禁用危险命令
危险命令包括: keys * scan * config flushall flushdb
# 禁用命令
rename-command KEYS ""
rename-command SCAN ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
# 重命名命令
rename-command KEYS "adminKEYS"
rename-command SCAN "adminSCAN"
rename-command FLUSHALL "adminFLUSHALL"
rename-command FLUSHDB "adminFLUSHDB"
rename-command CONFIG "adminCONFIG"
5 redis-trib.rb 常用命令
redis-trib.rb add-node
添加主节点:
redis-trib.rb add-node <new_ip:new_port> <exist_ip:exist_port>
使用 add-node 命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口,这样,新节点就会添加到集群中。
如:
redis-trib.rb add-node 10.86.87.111:6378 10.86.87.111:6379
注释:
10.86.87.111:6378是新增的节点
10.86.87.111:6379集群任一个旧节点
添加从节点:
redis-trib.rb add-node –slave <new_ip:new_port> <exist_ip:exist_port>
此处的命令和添加一个主节点命令类似,此处并没有指定添加的这个从节点的主节点,这种情况下系统会在其他的集群中的主节点中随机选取一个作为这个从节点的主节点。
如:
redis-trib.rb add-node --slave --master-id 03ccad2ba5dd1e062464bc7590400441fafb63f2 192.168.10.220:6385 192.168.10.219:6379
注释:
--slave 表示添加的是从节点
--master-id 03ccad2ba5dd1e062464bc7590400441fafb63f2,主节点的node id,在这里是前面新添加的6378的node id
192.168.10.220:6385,新节点
192.168.10.219:6379 集群任一个旧节点
添加指定主节点 id 的从节点:redis-trib.rb add-node –slave –master-id <主节点id> <new_ip:new_port> <exist_ip:exist_port>
也可以使用 CLUSTER REPLICATE 命令,这个命令也可以改变一个从节点的主节点,要在从节点中使用哦。
删除节点
redis-trib del-node
删除节点:redis-trib del-node <exist_ip:exist_port> <node-id>
第一个参数是任意一个节点的地址(确定集群所在),第二个节点是你想要移除的节点地址。
使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的(无 Solts)。如果不是空的,需要将这个节点的数据重新分片到其他主节点上。
替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据。
重新分配slot
redis-trib.rb reshard
从新分片:redis-trib.rb reshard <exist_ip:exist_port>
你只需要指定集群中其中一个节点的地址,redis-trib 就会自动找到集群中的其他节点。
目前 redis-trib 只能在管理员的协助下完成重新分片的工作,要让 redis-trib 自动将哈希槽从一个节点移动到另一个节点,目前来说还做不到。
redis-trib.rb reshard 192.168.10.219:6378 //下面是主要过程
How many slots do you want to move (from 1 to 16384)? 1000 //设置slot数1000
What is the receiving node ID? 03ccad2ba5dd1e062464bc7590400441fafb63f2 //新节点node id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all //表示全部节点重新洗牌
Do you want to proceed with the proposed reshard plan (yes/no)? yes //确认重新分
新增加的主节点,是没有slots的,
M: 03ccad2ba5dd1e062464bc7590400441fafb63f2 192.168.10.219:6378
slots:0-332,5461-5794,10923-11255 (0 slots) master
主节点如果没有slots的话,存取数据就都不会被选中。
可以把分配的过程理解成打扑克牌,all表示大家重新洗牌;输入某个主节点的node id,然后在输入done的话,就好比从某个节点,抽牌。
查看集群节点情况:
redis-trib.rb check 192.168.10.219:6379
手动改变slave从节点所属的master主节点(一个slave只能属于一个master,而一个master可以有多个slave)
//查看一下6378的从节点
# redis-cli -p 6378 cluster nodes | grep slave | grep 03ccad2ba5dd1e062464bc7590400441fafb63f2
//将6385加入到新的master
# redis-cli -c -p 6385 -h 192.168.10.220
192.168.10.220:6385> cluster replicate 5d8ef5a7fbd72ac586bef04fa6de8a88c0671052 //新master的node id
OK
192.168.10.220:6385> quit
//查看新master的slave
# redis-cli -p 6379 cluster nodes | grep slave | grep 5d8ef5a7fbd72ac586bef04fa6de8a88c0671052
删除节点
1)删除从节点
# redis-trib.rb del-node 192.168.10.220:6385 '9c240333476469e8e2c8e80b089c48f389827265'
2)删除主节点
如果主节点有从节点,将从节点转移到其他主节点
如果主节点有slot,去掉分配的slot,然后在删除主节点
# redis-trib.rb reshard 192.168.10.219:6378 //取消分配的slot,下面是主要过程
How many slots do you want to move (from 1 to 16384)? 1000 //被删除master的所有slot数量
What is the receiving node ID? 5d8ef5a7fbd72ac586bef04fa6de8a88c0671052 //接收6378节点slot的master
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:03ccad2ba5dd1e062464bc7590400441fafb63f2 //被删除master的node-id
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes //取消slot后,reshard
新增master节点后,也进行了这一步操作,当时是分配,现在去掉。反着的。
# redis-trib.rb del-node 192.168.10.219:6378 '03ccad2ba5dd1e062464bc7590400441fafb63f2'
新的master节点被删除了,这样就回到了,就是这篇文章开头,还没有添加节点的状态
复制迁移
在redis集群中通过"cluster replicate <master_node_id> "命令可以将一个slave节点重新配置为另外一个master的slave。
注意:这个只是针对slave节点,即登录到slave节点的reids中,执行这个命令。
比如172.16.60.204:7003是172.16.60.202:7000主节点的slave节点,也可以把他设置成172.16.60.205:7004主节点的slave节点。
172.16.60.205:7004主节点的ID是48cbab906141dd26241ccdbc38bee406586a8d03
则操作为
[root@redis-new01 ~]# /data/redis-4.0.6/src/redis-cli -h 172.16.60.204 -c -p 7003
172.16.60.204:7003> cluster replicate 48cbab906141dd26241ccdbc38bee406586a8d03
OK
172.16.60.204:7003>
这样172.16.60.204:7003节点就变成了172.16.60.205:7004主节点的slave节点,而不再是172.16.60.202:7000主节点的slave节点!
这样可以自动的将一个复制节点从一个master下移动到另外一个master下。 这种情况下的复制节点的自动重配置被称为复制迁移。
复制迁移可以提升系统的可靠性和抗灾性。
在某种情况下,你想让集群的复制节点从一个master迁移到另一个master的原因可能是:
集群的抗崩溃能力总是跟集群中master 拥有的平均slave数量成正比。
比如,如果一个集群中每个master只有一个slave,当master和slave都挂掉的时候这个集群就崩溃了。因为此时有一些哈希槽无法找到了。
虽然网络分裂会把一堆节点从集群中孤立出来(这样你一下就会知道集群出问题了),但是其他的更常见的硬件或者软件的问题并不会在多台机器上同时发生,
所以很 可能在你的这个集群(平均每个master只有一个slave)有一个slave在早上4点挂掉,然后他的master在随后的早上6点挂掉。这样依然会 导致集群崩溃。
可以通过给每个master都再多加一个slave节点来改进系统的可靠性,但是这样很昂贵。复制迁移允许只给某些master增加slave。比方说你的集群有20个节点,
10个master,每个master都有1个slave。然后你增加3个 slave到集群中并把他们分配给某几个master节点,这样某些master就会拥有多于1个slave。
当某个 master失去了slave的时候,复制迁移可以将slave节点从拥有富余slave的master旗下迁移给没有slave的master。所以当 你的slave在早上4点挂掉的时候,
另一个slave会被迁移过来取代它的位置,这样当master节点在早上5点挂掉的时候,依然有一个slave可 以被选举为master,集群依然可以正常运行。
所以简而言之,关于复制迁移应该注意下面几个方面:
- 集群在迁移的时候会尝试去迁移拥有最多slave数量的master旗下的slave。
- 想利用复制迁移特性来增加系统的可用性,你只需要增加一些slave节点给单个master(哪个master节点并不重要)。
- 复制迁移是由配置项cluster-migration-barrier控制的
升级节点
升级从服务器节点很简单,因为你只需要停止节点然后用已更新的Redis版本重启。如果有客户端使用从服务器节点分离读请求,它们应该能够在某个节点
不可用时重新连接另一个从服务器。
升级主服务器要稍微复杂一些,建议的步骤是:
1)使用cluster failover来触发一次手工故障转移主服务器(请看本文档的手工故障转移小节)。
2)等待主服务器变为从服务器。
3)像升级从服务器那样升级这个节点。
4)如果你想让你刚刚升级的节点成为主服务器,触发一次新的手工故障转移,让升级的节点重新变回主服务器。
可以按照这些步骤来一个节点一个节点的升级,直到全部节点升级完毕。
6 遇到的问题以及解决方案
新增节点直接变成从节点
这个是因为要新增的那个 Redis 节点中有原来残留的数据信息,新增前请把 AOF 和 RDB 备份的文件都删除掉,并且进入准备新增的 Redis 中执行一下下面两条命令
127.0.0.1:6379> FLUSHALL
127.0.0.1:6379> CLUSTER RESET
虽然一主一从加哨兵可以解决普通场景下服务可用的问题,但是两个节点分别存储所有的缓存数据,这不仅导致容量受限,更是让我们受限于机器配置最差的那一台,这就是木桶效应。硬件垂直扩容并不能解决日益庞大的缓存数据量和提供能搞得可用性。
在古老的Redis版本中,水平扩容的能力来自于发送命令的客户端,由客户端路由不同的key给到不同的节点,下次读取的时候,也按照相同方式路由key到指定节点拿到数据。如果接下来还希望增加扩容节点的话,就要对历史缓存数据做迁移,迁移过程中为保证数据一致性也要付出一定代价。为了解决节点的不断扩容,设计初期可以预先设置很多节点,以备日后使用,所有设计的节点都参与到分片当中,鉴于初期数据较少,可单台服务器多个节点,在日后数据增多的情况下,只需要迁移节点到新的服务器。而不需要对数据进行重新分配等操作。但是这种做法依然让我们觉得难维护,难迁移,难应对故障,迁移过程中也很难保证数据一致性,比如50个节点,任意一个节点想要停止并迁移服务器,都会引发数据不一致或者出现故障,只能停止集群,等待迁移完成后,集群上线。
Redis3.0提供了Cluster集群。这个集群的概念和前面提到的集群有所不同。前面的集群仅代表,多个节点间没有相互的关系,只是根据客户端路由分配key到不同的节点,所有节点共同分配所有数据。3.0的Cluster功能,拥有和单机实例相同的性能,几乎支持所有命令,对于涉及多个键的命令,比如MGET,如果每一个键都在同一个节点则可以正常返回数据,否则提示错误。另外集群中限制了0号数据库,如果切换数据库则会提示错误。
哨兵和集群是两个独立的功能,但从特性来看哨兵可以视为集群的子集。当不需要数据分片或者已经利用客户端分片的场景下哨兵已经足够使用,如果需要水平扩容,Cluster是非常好的选择。
每个集群至少三台主节点。
7 redis-4.0版本新特性
Redis4.0中增加了 UNLINK 命令(替换del命令),这个命令在删除体积较大的键时,命令在后台线程里面执行,还有异步的 flushdb 和 flushall 命令分别是
flushdb async
flushall async
尽可能的避免了服务器阻塞。
增加了交换数据库命令,比如SWAPDB 0 1 ,交换0库和1库
增加了memory命令,可以视察内存使用情况,通过help命令可以看到
127.0.0.1:6379> memory help
1) "MEMORY DOCTOR - Outputs memory problems report"
2) "MEMORY USAGE <key> [SAMPLES <count>] - Estimate memory usage of key"
3) "MEMORY STATS - Show memory usage details"
4) "MEMORY PURGE - Ask the allocator to release memory"
5) "MEMORY MALLOC-STATS - Show allocator internal stats"
MEMORY USAGE <key> 预估指定key所需内存
MEMORY STATS 视察内存使用详情
MEMORY PURGE 向分配器索要释放更多内存
MEMORY MALLOC-STATS 视察分配器内部状态
另外还有一系列优化比如 LRU和PSYNC,还有模块系统。
8 节点启动/停止/重启脚本
vim /etc/init.d/redis-8379 vim /etc/init.d/redis-8380 #!/bin/sh # chkconfig: 35 80 90 # Simple Redis init.d script conceived to work on Linux systems # as it does use of the /proc filesystem. REDISPORT=8380 EXEC=/usr/local/redis/bin/redis-server CLIEXEC=/usr/local/redis/bin/redis-cli PIDFILE=/var/run/redis_${REDISPORT}.pid CONF="/usr/local/redis/conf/redis-${REDISPORT}.conf" case "$1" in start) if [ -f $PIDFILE ] then echo "$PIDFILE exists, process is already running or crashed" else echo "Starting Redis server..." $EXEC $CONF & fi if [ "$?" = "0" ] then echo "Redis is running..." fi ;; stop) if [ ! -f $PIDFILE ] then echo "$PIDFILE does not exist, process is not running" else PID=$(cat $PIDFILE) echo "Stopping ..." $CLIEXEC -p $REDISPORT -a "0NZcyqRqLUteci7D" shutdown while [ -x /proc/${PID} ] do echo "Waiting for Redis to shutdown ..." sleep 1 done echo "Redis stopped" fi ;; restart|force-reload) ${0} stop ${0} start ;; *) echo "Usage: /etc/init.d/redis-${REDISPORT} {start|stop|restart|force-reload}" >&2 ;; esac chmod +x /etc/init.d/redis-* ll /etc/init.d/redis-* chkconfig --add redis-8379 chkconfig --add redis-8380 /etc/init.d/redis-8379 start /etc/init.d/redis-8380 start
9 redis集群密码设置
9.1、密码设置(推荐)
在配置redis个节点的时候,在所有Redis集群配置文件中的redis.conf文件加入:
masterauth passwd123
requirepass passwd123
说明:这种方式需要重新启动各节点
9. 2.如果集群已经创建好,也可以动态设置密码
在集群的所有实例(包含主节点和从节点)中执行
设置集群密码:
# 使用redis-cli连接redis集群
/usr/local/redis/bin/redis-cli -c -p 8379
/usr/local/redis/bin/redis-cli -c -p 8380
config set masterauth 0NZcyqRqLUteci7D
config set requirepass 0NZcyqRqLUteci7D
config rewrite # 这一步骤一定要执行,用于将密码配置写入配置文件的,如果不执行会导致下次重启redis时,密码失效!!!
# 上面的配置 一定要每一个节点都配置执行一遍(包括主节点和从节点)
注意:各个节点密码都必须一致,否则Redirected就会失败, 推荐这种方式,这种方式会把密码写入到redis.conf里面去,且不用重启。
9.3、设置密码之后如果需要使用redis-trib.rb的各种命令
如:./redis-trib.rb check 127.0.0.1:7000,则会报错ERR] Sorry, can’t connect to node 127.0.0.1:7000
解决办法:vim /usr/local/rvm/gems/ruby-2.4.0/gems/redis-4.1.2/lib/redis/client.rb,然后修改passord
vim /usr/local/rvm/gems/ruby-2.4.0/gems/redis-4.1.2/lib/redis/client.rb
class Client
DEFAULTS = {
:url => lambda { ENV["REDIS_URL"] },
:scheme => "redis",
:host => "127.0.0.1",
:port => 6379,
:path => nil,
:timeout => 5.0,
:password => "passwd123", # "0NZcyqRqLUteci7D"
:db => 0,
:driver => nil,
:id => nil,
:tcp_keepalive => 0,
:reconnect_attempts => 1,
:inherit_socket => false
}
注意:client.rb路径可以通过find命令查找:find / -name 'client.rb'
10 redis 监控工具安装
./redis-stat --verbose --server=9000 5 10.86.78.144:8379 -a 0NZcyqRqLUteci7D &
./redis-stat 10.86.78.144:8379 -a 0NZcyqRqLUteci7D 1 10 --verbose
11 参考文档
https://www.jianshu.com/p/1ff269e8869d
故障转移
https://www.cnblogs.com/kevingrace/p/7910692.html
人们永远没有足够的时间把它做好,但永远有足够的时间重新来过。 可是,因为并不是总有机会重做一遍,你必须做得更好,换句话说, 人们永远没有足够的时间去考虑到底是不是想要它,但永远有足够的时间去为之后悔。 ★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ 浅掘千口井,不如深挖一口井!当知识支撑不了野心时,那就静下心来学习吧!运维技术交流QQ群:618354452
个人微信公众号,定期发布技术文章和运维感悟。欢迎大家关注交流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号