Prometheus-Alertmanager告警对接到企业微信
之前写过将Prometheus的监控告警信息通过Alertmanager推送到钉钉群。
最近转移了阵地,需要将Prometheus监控告警信息推送到企业微信群,经过两天的摸索,以及查了网上的一些资料,总结了此文,避免后面的同学走弯路。
Alertmanager将告警信息推送到微信群,主要涉及到如下几方面的配置:
- 企业微信后台的配置,包括新建告警部门和应用;
- Alertmanager的主配置文件配置和告警模板配置;
- Prometheus主配置文件的配置以及告警规则的配置;
下面就这三点分别进行介绍
1、企业微信后台配置
这里就不得不啰嗦几句,[互联]网大了,什么鸟都有,天下文章一大抄,管它对于不对,先转到自己博客再说。真正能够自己验证,能够理解其告警策略和原理的能有几人?
1.1 企业ID获取
首先访问企业微信官网:https://work.weixin.qq.com/
注册一个企业,当前是谁都可以注册,没有任何限制,也不需要企业认证,注册即可。
注册完成之后,登录后台管理,在【我的企业】这里,先拿到后面用到的第一个配置:企业ID

1.2 部门ID获取
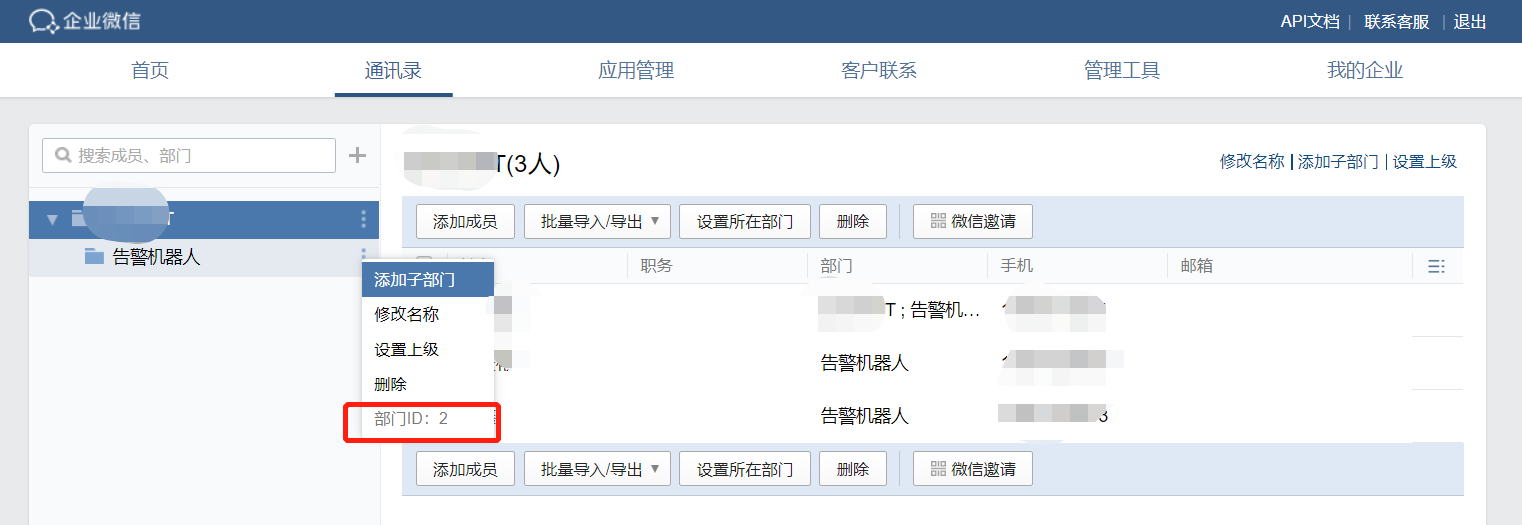
然后在通讯录中,添加一个子部门,用于接收告警信息,后面把人加到该部门,这个人就能接收到告警信息了。

获得我们配置告警的第二个参数:部门ID 2
1.3 告警AgentId和Secret获取
告警AgentId和Secret获取是需要在企业微信后台,【应用管理】中,自建应用才能够获得的。这里网上介绍的非常多,都只是说了这一步骤,而忽略了其他几个重要的步骤。


最后点击创建应用,可以看到我们刚才创建好的应用Prometheus。
点击这个应用,可以看到我们想要的AgentId和Secret
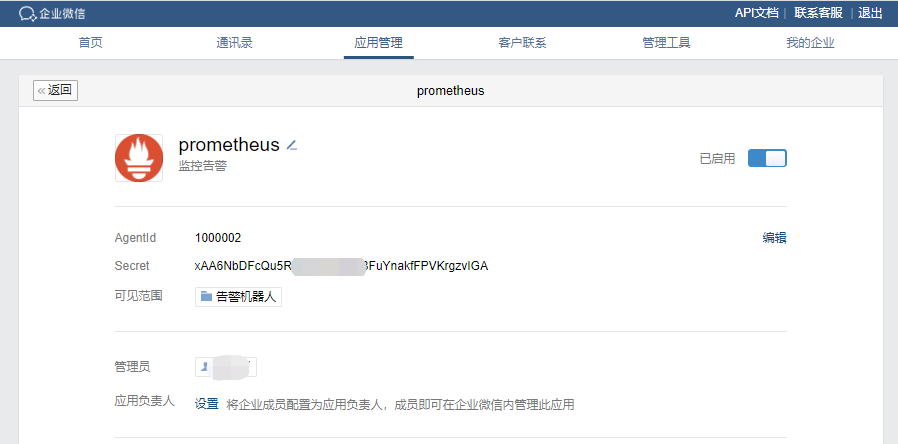
以上步骤完成后,我们就得到了配置Alertmanager的所有信息,包括:企业ID,AgentId,Secret和接收告警的部门id
下面我们来配置Alertmanager服务
2、Alertmanager服务配置
2.1 主配置文件
# 主配置文件信息如下:
cat /opt/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m # 每1分钟检测一次是否恢复
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_corp_id: 'bbbbbbbbbbbbbbbb' # 企业微信中企业ID
wechat_api_secret: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 企业微信中,应用的Secret
templates:
- '/opt/alertmanager/template/*.tmpl'
route:
receiver: 'wechat'
group_by: ['env','instance','type','group','job','alertname']
group_wait: 10s # 初次发送告警延时
group_interval: 10s # 距离第一次发送告警,等待多久再次发送告警
repeat_interval: 5m # 告警重发时间
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '2' # 企业微信中创建的接收告警的部门【告警机器人】的部门ID
agent_id: '1000002' # 企业微信中创建的应用的ID
api_secret: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 企业微信中,应用的Secret
2.2 告警模板
# cat /opt/alertmanager/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
2.3 Prometheus集成
下面配置prometheus告警规则
主配置文件:prometheus.yml中加入:
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/node_status.yml"
然后配置告警规则文件:node_status.yml
# cat rules/node_status.yml
[root@cn-prom prometheus-server]# cat rules/node_status.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up{job="prometheus"} == 0 or up{job="Linux-host"} == 0
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "Instance {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
value: "{{ $value }}"
- name: 内存告警规则
rules:
- alert: "内存使用率告警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 75
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} 内存报警"
description: "{{ $labels.alertname }} 内存资源利用率大于75%!(当前值: {{ $value }}%)"
value: "{{ $value }}"
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 70
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} CPU报警"
description: "服务器: CPU使用超过70%!(当前值: {{ $value }}%)"
value: "{{ $value }}"
- name: 磁盘报警规则
rules:
- alert: 磁盘使用率告警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} 磁盘报警"
description: "服务器:{{$labels.alertname}},磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
value: "{{ $value }}"
至此,企业Prometheus对接企业微信告警完毕,出现故障你就能看到如下告警信息和恢复信息了
========= 监控报警 =========
告警状态:firing
告警级别:Disaster
告警类型:实例存活告警
故障主机: 10.137.10.211:9100
告警主题: Instance 10.137.10.211:9100 is down
告警详情: Instance 10.137.10.211:9100 of job Linux-host has been down for more than 1 minutes.;
触发阀值:0
故障时间: 2020-09-21 10:21:08
========= = end = =========
========= 异常恢复 =========
告警类型:实例存活告警
告警状态:resolved
告警主题: Instance 10.137.10.211:9100 is down
告警详情: Instance 10.137.10.211:9100 of job Linux-host has been down for more than 1 minutes.;
故障时间: 2020-09-21 10:21:08
恢复时间: 2020-09-21 10:26:23
实例信息: 10.137.10.211:9100
========= = end = =========
以上,请测试验证,如有描述不清楚的地方,欢迎留言交流。
人们永远没有足够的时间把它做好,但永远有足够的时间重新来过。 可是,因为并不是总有机会重做一遍,你必须做得更好,换句话说, 人们永远没有足够的时间去考虑到底是不是想要它,但永远有足够的时间去为之后悔。 ★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ 浅掘千口井,不如深挖一口井!当知识支撑不了野心时,那就静下心来学习吧!运维技术交流QQ群:618354452
个人微信公众号,定期发布技术文章和运维感悟。欢迎大家关注交流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号