字符串知识点总结
读字符串函数fgets
功能:从文件中读取字符串,每次只读取一行。
注意:
- fgets每次最多只能读取n-1个字2.符,第n个为NULL。
- 当遇到换行符或者EOF时,即使当前位置在n-1之前也读出结束。
- 若函数返回成功,则返回 字符串数组str的首地址。
例:小L很喜欢听私人笑声,可是有些歌曲他没有夹带私人笑声,小L就很生气,请你帮帮小L给歌曲带上私人笑声吧。
给你一段歌词,请你在所有’.'后面加上"xixixixi.",然后再输出全部歌词,例如给你一段歌词为:
“da ji da li,jin wan chi ji.xiong di jie mei,come on wo men yi qi.lao si ji,lao si ji ta zai zhe li.”
输出答案则是:
“da ji da li,jin wan chi ji.xixixixi.xiong di jie mei,come on wo men yi qi.xixixixi.lao si ji,lao si ji ta zai zhe li.xixixixi.”
输入描述
给你一行字符串,字符只由小写字母和",“和”."还有空格构成。(字符串长度<=1e6)
输出描述
输出题目要求字符串
用例输入 1
da ji da li,jin wan chi ji.xiong di jie mei,come on wo men yi qi.lao si ji,lao si ji ta zai zhe li.
用例输出 1
da ji da li,jin wan chi ji.xixixixi.xiong di jie mei,come on wo men yi qi.xixixixi.lao si ji,lao si ji ta zai zhe li.xixixixi.
#include<bits/stdc++.h>
using namespace std;
#define int long long
signed main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
char ss[100];
fgets(ss,100,stdin);
int n=strlen(ss);
for(int i=0;i<n;i++)
{
if(ss[i]=='.')
{
cout<<".xixixixi";
}else
{
cout<<ss[i];
}
}
return 0;
}
洛谷:P1957 口算练习题
to_string 可以将整形数据转化为字符串,stoi()函数可以将字符串转化为整形数据。
#include<bits/stdc++.h>
using namespace std;
#define int long long
signed main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int n;
cin>>n;
string s;
char c;
int d,e;
while(n--)
{
cin>>s;
if(s[0]=='a'||s[0]=='b'||s[0]=='c')
{
c=s[0];
cin>>d>>e;
}else
{
d=stoi(s);
cin>>e;
}
if(c=='a')
{
cout<<d<<"+"<<e<<"="<<d+e<<endl;
string ss="";
ss+=to_string(d)+'+'+to_string(e)+'='+to_string(d+e);
cout<<ss.size()<<endl;
}if(c=='b')
{
cout<<d<<"-"<<e<<"="<<d-e<<endl;
string ss="";
ss+=to_string(d)+'-'+to_string(e)+'='+to_string(d-e);
cout<<ss.size()<<endl;
}if(c=='c')
{
cout<<d<<"*"<<e<<"="<<d*e<<endl;
string ss="";
ss+=to_string(d)+'*'+to_string(e)+'='+to_string(d*e);
cout<<ss.size()<<endl;
}
}
return 0;
}
getline()用的比较多的用法
getline(cin,temp,delim);
· cin是标准输入流函数
· temp是用来存储字符的变量名
· delim是结束标志
——————————————————————————————————————————————
此函数可读取整行,包括前导和嵌入的空格,并将其存储在字符串对象中。遇到换行符或者EOF结束,不读取换行符。delim是自己设定的结束符。
在使用getline读入一整行时,如果前面使用getchar()、cin这类读入了一个字母,但是不会读入后续换行\n符号或者空格的输入时,再接getline()就容易出现问题。
这是因为输入数字之后,敲回车,产生的换行符仍然滞留在输入流,接着就被getline(cin,s)给读进去了,此时的s=“\n”,所以实际上s只是读入了一个换行符\n。
而若是前面使用getline(),再又用getline()进行读入,此时不会发生问题。getline()中读入结束的回车后,结束符不放入缓存区,会将读入的\n直接去除,下一个输入前,缓冲区为空,并不会因为回车留下\n。
如果前面用了cin、getchar(),可以在后面使用一个getchar()吃掉接下来的换行。
_______________________________________________________________________________________________________________
例:
#include<bits/stdc++.h>
using namespace std;
#define int long long
signed main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
string s;
cin>>s;
getchar();
string ss;
getline(cin,ss);
int k1=0,k2;
if(ss.find(s)!=string::npos)
{
k2=ss.find(s);
while(ss.size()>0)
{
k1++;
ss.erase(ss.find(s),s.size());
if(ss.find(s)==string::npos)
{
break;
}
}
cout<<k1<<" "<<k2<<endl;
}
else
{
cout<<"-1"<<endl;
}
return 0;
}
诸如上述代码,当使用getchar()进行换行符的读取时结果指挥输出-1,而cin.getline()结果却不一样。
当使用getline()函数时,如果前面出现了某些输入操作,可以在中间添加cin.ignore(),getline(),getchar()函数来消除换行符的影响。
当使用getchar()函数时,要将ios::。。。注释掉,因为ios::。。。是关闭流和同步,关闭之后,c和c++的读入不能同时用,getchar()是c的,getline()是c++的。
(1) istream& getline (istream& is, string& str, char delim);
(2) istream& getline (istream& is, string& str);
is是一个流,例如cin
str是一个string类型的引用,读入的字符串将直接保存在str里面
delim是结束标志,默认为换行符
getline()这个函数是可以读取空格,遇到换行符或者EOF结束,getline是读取换行符的,只是读取后丢弃了,所以缓冲区内就没有换行符了,这与fgets()存在着差异
getline()函数也可以指定一个可选的分隔符参数,用于指定读取行的结束标志,例如getline(cin, line, ',')表示遇到逗号','时停止读取。
在日常使用中我们经常需要将getline与while结合使用
例1:
string str;
while(getline(cin,str)){
。。。
}
那么在这个例子中是不是我们输入了一个回车就会跳出循环呢,答案是否定的,while只会检测cin的输入是否合法,那么什么时候会跳出循环呢,只有1.输入EOF,2.输入到了文件末尾
例2:
string str;
while(getline(cin,str),str != "#"){
。。。
}
在这个例子中,逗号运算符的作用就是将最后一个式子作为判定的条件,即while判断的是str != "#"这个条件,只有当输入到str的为#键时,循环才会结束
https://blog.csdn.net/m0_37616927/article/details/86749099
在原字符串中给查找指定字符串 .find()
to_string
集美大学“第十五届蓝桥杯大赛”
https://zhuanlan.zhihu.com/p/678902967
【3】20231122
求区间[2023,20231122]范围内的整数出现 1122 子串的整数数量。
点击查看代码
#include<bits/stdc++.h>
using namespace std;
int main()
{
int ans=0;
for(int i=2023;i<=20231122;i++)
{
ans+=to_string(i).find("1122")!=string::npos;
}
cout<<ans<<endl;
return 0;
}
to_string(i) 是一个 C++ 标准库函数,用于将整数转换为对应的字符串。接受一个整数作为参数,并返回一个表示该整数的字符串。
例如:如果你有一个整数变量 int num = 123,你可以使用 to_string(num) 来将它转换为字符串。函数将返回一个包含 "123" 的字符串。(✳只适用于整形数据)
当你想要在一个字符串中找到一个特定的子字符串时,可以使用 .find("1122") 函数。它接受一个字符串作为参数,并返回一个表示该子字符串在原始字符串中第一次出现的位置的整数值。(✳.find()函数只会返回第一次出现的位置(从0开始索引)。)
例如,如果你有一个字符串变量 string str = "112233445566";,你可以使用 str.find("1122") 来找到子字符串 "1122" 在原始字符串中的位置。如果 "1122" 存在于字符串中,函数将返回一个非负整数,表示子字符串的起始位置。如果子字符串不存在,函数将返回一个特殊的值 string::npos。
字符串如何删去制定范围内的字符
要删除字符串中指定范围内的字符,可以使用erase函数来实现。erase函数的第一个参数是要删除字符的起始位置,第二个参数是要删除字符的个数。
例如,如果要删除字符串中从索引位置2开始的3个字符,可以这样做:
#include <iostream>
#include <string>
int main() {
std::string str = "Hello, World!";
str.erase(2, 3);
std::cout << str << std::endl; // 输出: He, World!
return 0;
}
在上面的例子中,调用str.erase(2, 3)会删除字符串str中从索引位置2开始的3个字符,即"llo"这三个字符被删除了。
例:
[NOIP2011 普及组] 统计单词数
给定一个单词,请你输出它在给定的文章中出现的次数和第一次出现的位置。注意:匹配单词时,不区分大小写,但要求完全匹配,即给定单词必须与文章中的某一独立单词在不区分大小写的情况下完全相同(参见样例 1),如果给定单词仅是文章中某一单词的一部分则不算匹配(参见样例 2)。
输入格式
共 2 行。
第 1 行为一个字符串,其中只含字母,表示给定单词;
第 2 行为一个字符串,其中只可能包含字母和空格,表示给定的文章。
输出格式
一行,如果在文章中找到给定单词则输出两个整数,两个整数之间用一个空格隔开,分别是单词在文章中出现的次数和第一次出现的位置(即在文章中第一次出现时,单词首字母在文章中的位置,位置从 0 开始);如果单词在文章中没有出现,则直接输出一个整数 -1。
注意:空格占一个字母位
样例 1
样例输入1
To
to be or not to be is a question
样例输出1
2 0
样例2
样例输入2
to
Did the Ottoman Empire lose its power at that time
样例输出 2
-1
提示
数据范围
-
第一行单词长度 <10。
-
文章长度 <10^6。
#include<bits/stdc++.h>
using namespace std;
#define int long long
string ss[1000005]={""};
int a[1000005]={-1};
void convert(string &p)
{
int i = 0;
while(p[i] != '\0')
{
if(p[i] >= 'A' && p[i] <= 'Z' )
p[i] += 32;
i++;
}
}
signed main()
{
string s;
cin>>s;
cin.ignore();
string sss;
getline(cin,sss);
unordered_map<string,int>u;
convert(sss);
convert(s);
int k=0;
int z=-1;
for(int i=0;i<sss.size();i++)
{
if(sss[i]==' ')
{
u[ss[k]]++;
if(ss[k]==s)
{
++z;
a[z]=i-s.size();
}
k++;
continue;
}
ss[k]+=sss[i];
}
int sum=0;
if(z!=-1)
{
for(auto& c:u)
{
if(c.first==s)
{
sum+=c.second;
}
}
cout<<sum<<" "<<a[0]<<endl;
}else
{
cout<<"-1"<<endl;
}
}
设立了一个函数,将长字符文本和字符串全部转化为小写。
rfind()
- rfind(str)
rfind(str)是从字符串右侧开始匹配str,并返回在字符串中的位置(下标);
测试:
# include<string>
# include<iostream>
using namespace std;
int main()
{
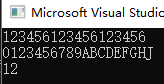
string str = "123456123456123456";
cout<<str<<endl<<"0123456789ABCDEFGHJ"<<endl;//方便查看上面字符串的下标
int pos = str.rfind("123");
cout<<pos<<endl;;
return 0;
}
- rfind(str,pos)
rfind(str,pos)是从pos开始,向前查找符合条件的字符串;
rfind(str,pos)实际的开始的位置是,pos+str.size(),即从该位置开始(不包括该位置字符)向前寻找匹配项,如果有则返回字符串位置,如果没有则返回string::npos。
# include<string>
# include<iostream>
using namespace std;
int main()
{
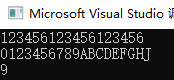
string str = "123456123456123456";
cout<<str<<endl<<"0123456789ABCDEFGHJ"<<endl;//方便查看上面字符串的下标
int pos = str.rfind("456",12);
cout<<pos<<endl;;
return 0;
}
如果没有的话返回string::npos
https://blog.csdn.net/qq_42446432/article/details/88086259
substr()
定义
substr()是C++语言函数,主要功能是复制子字符串,要求从指定位置开始,并具有指定的长度。如果没有指定长度_Count或_Count+_Off超出了源字符串的长度,则子字符串将延续到源字符串的结尾。
语法
substr(size_type _Off = 0,size_type _Count = npos)
一种构造string的方法
形式 : s.substr(pos, len)
返回值: string,包含s中从pos开始的len个字符的拷贝(pos的默认值是0,len的默认值是s.size() - pos,即不加参数会默认拷贝整个s)
异常 :若pos的值超过了string的大小,则substr函数会抛出一个out_of_range异常;若pos+n的值超过了string的大小,则substr会调整n的值,只拷贝到string的末尾
substr有2种常用用法:
假设:string s = “0123456789”;
string sub1 = s.substr(5); //只有一个数字5表示从下标为5开始一直到结尾:sub1 = “56789”
string sub2 = s.substr(5, 3); //从下标为5开始截取长度为3位:sub2 = “567”
实例
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s="sfsa";
string a=s.substr(0,3);
string b=s.substr();
string c=s.substr(2,3);
cout<<a<<endl;
cout<<b<<endl;
cout<<c<<endl;
return 0;
}
链接:https://www.nowcoder.com/questionTerminal/d9162298cb5a437aad722fccccaae8a7
来源:牛客网
描述
•连续输入字符串,请按长度为8拆分每个字符串后输出到新的字符串数组;
•长度不是8整数倍的字符串请在后面补数字0,空字符串不处理。
输入描述:
连续输入字符串(输入多次,每个字符串长度小于100)
输出描述:
输出到长度为8的新字符串数组
#include <iostream>
using namespace std;
int main(){
string str;
while(getline(cin,str)){
while(str.size()>8){
cout << str.substr(0,8) <<endl;
str=str.substr(8);
}
cout << str.append(8-str.size(),'0') << endl; //不够8位的补0
}
}

