第一周-哈希表
散列方法——杂凑法
选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放;
查找时,由同一个函数对给定值k计算地址,将k与地址单元中元素关键码进行比,确定查找是否成功。
- 冲突:两个关键字的值不同,但求得存储地址是一样的。(不同的关键码映射到同义散列地址)
- 同义词:具有相同函数值的多个关键字。
构造方法:1. 直接定址法 2. 数字分析法 3. 平方取中法 4. 折叠法 5. 除留余数法 6. 随机数法
- 直接定址法:
优点:以关键码key的某个线性函数值为散列地址,不会产生冲突。
缺点:要占用连续地址空间,空间效率低。 - 数字分析法:
选取适当的位数作为哈希值的长度,位数尽量小,减少冲突的可能。根据输入数字的位模式,选择选择要使用的数字位,将其组合成一个哈希值(将选定位数字位通过串联转化成一个整数,较大数字组合用取模运算控制范围)。
例:有一组数字 {123, 456, 789, 111, 222}。我们选择使用最低位和次低位作为参考位。
*选择哈希值的长度为 4 位。
*对于数字 123,选择的参考位是 3 和 2。将选择的参考位串联在一起得到 32,将其转换为一个整数得到哈希值 32。
*对于其他数字,以相同的方式计算哈希值。
*最后,可以通过取模运算将哈希值限制在 4 位范围内,例如,如果哈希值大于 9999,则可以使用取模 10000 的方式限制到 4 位。 - 平方取中法:
取关键字平方后的中间几位为哈希地址。 - 折叠法:
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586-4,则算法实现为:
点击查看代码
#include<iostream>
#include<cmath>
#include<vector>
#include<algorithm>
#include<string>
using namespace std;
int fold(const string& isbn)
{
int value=0;
int count=0;
for(long long unsigned int i=0;i<isbn.length();i++)
{
char ch=isbn[i];
if(isdigit(ch))
{//isdigit(ch) 是一个C++标准库中的函数,
//其作用是判断一个字符是否是数字字符。
//它接受一个字符作为参数,并返回一个表示判断结果的布尔值。
value+=(ch-'0');
count++;
if(count==4)
{//如果哈希值已经是四位数,则直接返回。
return value;
}
}
}
// 处理不足四位的情况,将哈希值循环左移
value=(value%10000)*10+(value/10000);
return value;
}
int main()
{
string isbn="0-442-20586-4";
int value=fold(isbn);
cout<<"isbn:"<<isbn<<"的哈希值是:"<<value<<endl;
return 0;
}
处理冲突的方法:1,开放定址法(开地址法)2,链地址法(拉链法)3,再散列法(双散列函数法)4,建立一个公共溢出区
-
开放地址法:有冲突时就去寻找下一个空的散列地址。(只要足够大就能找到)
除留余数法:Hi=(hash(key)+di)mod m di为增量,m为不大于散列表长度的质数。
确定di方法:线性探测法(di为1,2……m-1线性序列,一个数要查找di+1次),二次探测法(di为12,-12……q^2二次序列),伪随机探测法(di为伪随机数)。 -
链地址法:相同散列地址的记录链成一单链表m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构。
*step1:取数据元素的关键字key,计算器散列函数值(地址)。若该的值对应的链表为空,则将该元素插入此链表;否则执行step2解决冲突。
*step2:根据选择的冲突处理方法,计算关键字key的下一个存储地址,若该地址对应的链表不为空,则利用链表的前插法或后插法将该元素插入此链表。
优点:
- 非同义词不会冲突,(开放地址法会由于调整非同义词也会冲突)。
- 链表上节点空间动态申请,更适合于表长不确定的情况。
散列表的查找
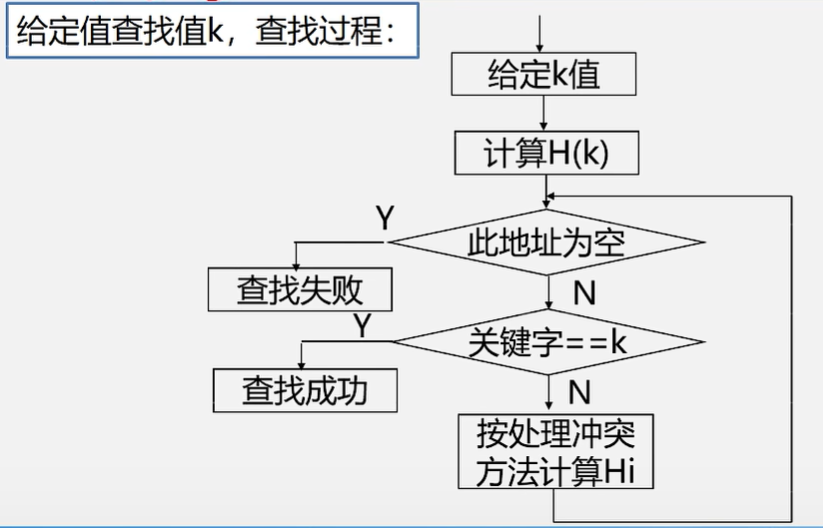
无序查找平均查找长度为(n+1)/2,(最差查找n次,最好查找1次,平均)。
有序表折半查找平均查找长度为lg2(n+1)-1。
平均长度取决于散列函数,处理冲突的方法,散列表的装填因子α
(α=表中填入的记录数/哈希表的长度(α越大,越有可能发生冲突))。
点击查看代码
#include<iostream>
#include<cmath>
#include<list>
#include<vector>
#include<unordered_map>//无序映射
using namespace std;
int main(){
unordered_map<string,float> fruits={
//创造无序映射,用于储存水果的名称和价格
{"apple",0.99},
{"banana",0.25},
{"orange",0.50},
{"grape",0.75}
};
string fruit_name;
cin>>fruit_name;
//判断fruit_name是否存在于fruits中。
if(fruits.count(fruit_name)>0)
{
float price=fruits[fruit_name];
cout<<price<<endl;
}else
{
cout<<"error"<<endl;
}
return 0;
}
洛谷p4305不重复数字
解1:
点击查看代码
#include<iostream>
#include<cmath>
#include<list>
#include<vector>
#include<unordered_map>//无序映射
using namespace std;
unordered_map<int,bool> m;
int main(){
ios::sync_with_stdio(false);/*这行代码关闭了 C++ 的输入输出流与 C 的输入输出流的同步,可以提高输入输出的速度。*/
cin.tie(0), cout.tie(0);/*这两行代码将 cin 和 cout 与其他输出关联起来,以提高输入输出的速度。*/
int t;
cin>>t;
for(int i=0;i<t;i++)
{
int n;
cin>>n;
int a;
m.clear();// 清空无序映射 mp,以便处理下一个测试用例
for(int j=0;j<n;j++)
{
cin>>a;
if(m[a]==0)
{
/*m[a]==0 是一个条件判断语句,用于判断无序映射 m 中是否存在键为 a 的元素,
并且该元素的值是否为 0。*/
cout<<a<<" ";
m[a]=1;
}
}
cout<<endl;
}
/*m[a]==0 是一个条件判断语句,用于判断无序映射 m 中是否存在键为 a 的元素,并且该元素的值是否为 0。
m[a] 表示从无序映射 m 中获取键为 a 的元素。如果该键存在,返回对应的值;如果该键不存在,则默认返回值为 0。
在这段代码中,当 m[a] 为 0 时,表示无序映射 m 中不存在键为 a 的元素,
或者存在键为 a 的元素,但其值为 0。在这种情况下,会输出元素 a 并将 m[a] 的值更新为 1。*/
return 0;
}
洛谷p1102A-B数对
点击查看代码
#include<bits/stdc++.h>
using namespace std;
int main()
{
long long n,c;
cin>>n>>c;
long long a[200005];
unordered_map<int,int> m;
m.clear();
for(long long i=0;i<n;i++)
{
cin>>a[i];
m[a[i]]++;
}
sort(a,a+n);
long long s=0;
for(long long i=0;i<n;i++)
{
long long k=a[i]-c;
if(m[k]!=0)
{
s+=m[k];
}
}
cout<<s<<endl;
return 0;
}
力扣第一题:两数之和。
https://leetcode.cn/problems/two-sum/
点击查看代码
#include <iostream>
#include <vector>
#include <unordered_map>
#include <array>
#include<cmath>
#include<algorithm>
using namespace std;
int main() {
unordered_map<int,int> umap;
int n;
cin>>n;
vector<int> a(n);
for(int i=0;i<n;i++)
{
cin>>a[i];
}
int result[2];
for(int i=0;i<n;i++)
{
if(umap.find(20-a[i])==umap.end())
{
umap[a[i]]=i;
}
if(umap.find(20-a[i])!=umap.end())
{
result[0]=umap[20-a[i]];
result[1]=i;
break;
}
}
cout<<result[0]<<' '<<result[1]<<endl;
return 0;
}
找到消失的数字
点击查看代码
#include <iostream>
#include <vector>
#include <unordered_map>
#include <array>
#include<cmath>
#include<algorithm>
using namespace std;
int main() {
unordered_map <int,int>umap;
int a[100];
int n;
cin>>n;
for(int i=0;i<n;i++)
{
cin>>a[i];
if(umap.find(a[i])==umap.end())
umap[a[i]]++;
}
for(int i=1;i<=n;i++)
{
if(umap.find(i)==umap.end())
{
cout<<i<<" ";
}
}
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下