
Python爬取京东手机评论信息
代码如下:
1 # coding='utf-8' 2 import requests 3 import json 4 import time 5 import random 6 import xlwt 7 import xlutils.copy 8 import xlrd 9 10 11 def start(page): 12 # 获取URL 13 # score 评价等级 page=0 第一页 producitid 商品类别 14 # url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100014348492&score=0&sortType=5&page=&pageSize=10&isShadowSku=0&fold=1' 15 url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100014348492&score=0&sortType=5&page='+str(page)+'&pageSize=3100&isShadowSku=0&fold=1' 16 17 headers = { 18 "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36" 19 } 20 time.sleep(2) 21 test = requests.get(url=url, headers=headers) 22 t = test.text 23 data = json.loads(t.lstrip('fetchJSON_comment98vv12345(').rstrip(');')) 24 # data = json.loads(test) 25 return data 26 # 解析页面 27 28 29 def parse(data): 30 items = data['comments'] 31 for i in items: 32 yield ( 33 i['id'], # 用户id 34 i['guid'], 35 i['content'], # 内容 36 i['creationTime'], # 时间 37 i['isTop'], 38 i['referenceTime'], 39 i['firstCategory'], 40 i['secondCategory'], 41 i['thirdCategory'], 42 i['replyCount'], 43 i['score'], 44 i['nickname'], 45 i['userClient'], 46 i['productColor'], 47 i['productSize'], 48 i['plusAvailable'], 49 i['productSales'], 50 i['days'], 51 i['afterDays'] 52 ) 53 54 55 def excel(items): 56 # 第一次写入 57 newTable = "jingdong.csv" # 创建文件 58 wb = xlwt.Workbook("encoding='utf-8") 59 60 ws = wb.add_sheet('sheet1') # 创建表 61 headDate = ['id', 'guid', '内容', '时间', 'isTop', 'referenceTime', 'firstCategory', 'secondCategory', 'thirdCategory', 62 'replyCount', 'score', 'nickname', 'userClient', 'productColor', 'productSize', 63 'plusAvailable', 'productSales', 'days', 'afterDays'] # 定义标题 64 for i in range(0, 19): # for循环遍历写入 65 ws.write(0, i, headDate[i], xlwt.easyxf('font: bold on')) 66 67 index = 1 # 行数 68 69 for data in items: # items是十条数据 data是其中一条(一条下有三个内容) 70 for i in range(0, 19): # 列数 71 print(data[i]) 72 ws.write(index, i, data[i]) # 行 列 数据(一条一条自己写入) 73 print('______________________') 74 index += 1 # 等上一行写完了 在继续追加行数 75 wb.save(newTable) 76 77 78 def another(items, j): # 如果不是第一次写入 以后的就是追加数据了 需要另一个函数 79 80 index = (j - 1) * 10 + 1 # 这里是 每次写入都从11 21 31..等开始 所以我才传入数据 代表着从哪里开始写入 81 82 data = xlrd.open_workbook('jingdong.csv') 83 ws = xlutils.copy.copy(data) 84 # 进入表 85 table = ws.get_sheet(0) 86 87 for test in items: 88 89 for i in range(0, 19): # 跟excel同理 90 print(test[i]) 91 92 table.write(index, i, test[i]) # 只要分配好 自己塞入 93 print('_______________________') 94 95 index += 1 96 ws.save('jingdong.csv') 97 98 99 def main(): 100 j = 1 # 页面数 101 judge = True # 判断写入是否为第一次 102 103 for i in range(0, 300): 104 time.sleep(1.5) 105 # 记得time反爬 其实我在爬取的时候没有使用代理ip也没给我封 不过就当这是个习惯吧 106 first = start(j) 107 test = parse(first) 108 109 if judge: 110 excel(test) 111 judge = False 112 else: 113 another(test, j) 114 print('第' + str(j) + '页抓取完毕\n') 115 j = j + 1 116 117 118 if __name__ == '__main__': 119 main() 120 # 这个代码仅为全部数据下的评论而已 中差评等需要修改score!
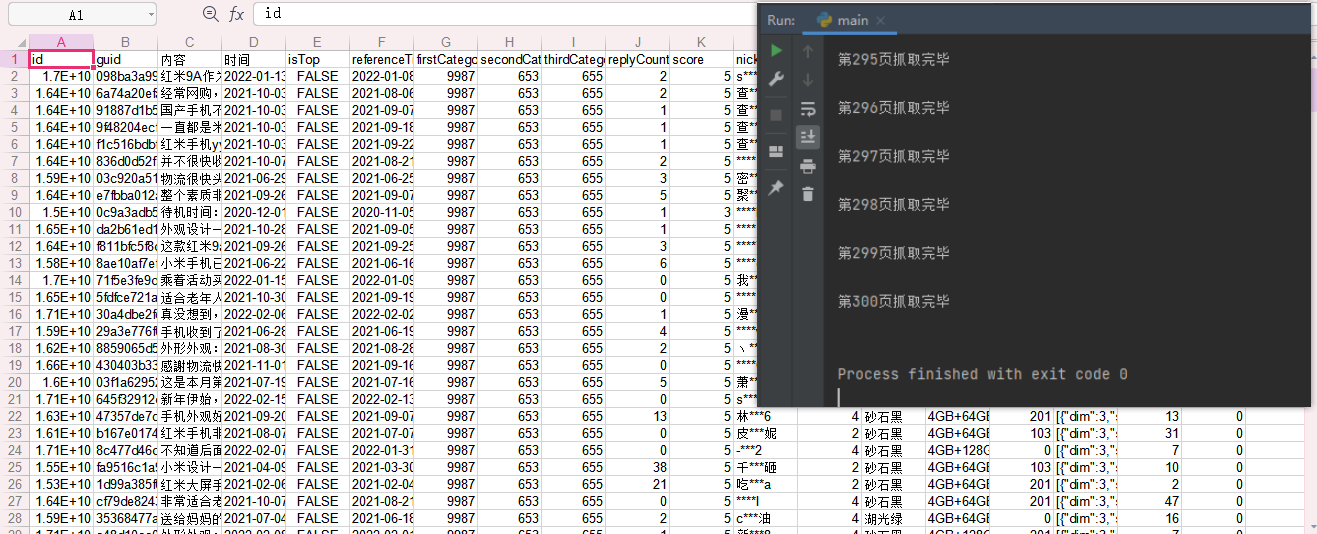
效果图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号