软件测试常用的sql语句
一.数据库基础(mysql)
1.windows命令行连接服务器
- mysql -h&ip -p&port -u&用户名 -p
- -h (host) 连接的ip localhost
- -p (port) 端口号 3306
- -u (username) 用户名 root
- -p (password) 密码 123456
- 如果在本地登录,直接写mysql -uroot -p
2.数据库的执行原理
- 数据服务器提供服务,客户端连接到数据库服务器。向服务器发送sql语句,服务器执行SQL,返回结果。
3.字段类型
- 整型
-
整型
占用字节
范围
范围
tinyint
1
-27~27-1
-128~127
smallint
2
-215~215-1
-32768~32767
mediumint
3
-223~223-1
-8388608~8388607
int
4
-231~231-1
-2147483648~2147483647
bigint
8
-263~263-1
-
-
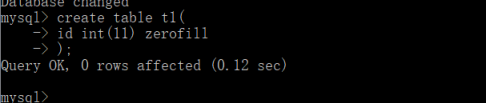
显示宽度:最小的显示位数,比如int(11),最少用11位数字显示值。
![]()
-
显示的时候不够11位以0填充
-
显示宽度必须结合zerofill才起作用
-
- 无符号数(unsigned)
-
无符号数就是没有负数,无符号数的正数的范围是有符号数正数范围的2倍
-
create table t4(
id tinyint(255)unsigned
);
-
-
unsigned的在sql中的使用方法:
-
tinyint unsigned
mediumint unsigned
int unsigned;
- 浮点数
|
浮点数 |
占用字节 |
范围 |
|
float(单精度) |
4 |
-3.4E+38~3.4E+38 |
|
double(双精度) |
8 |
-1.8E+308~1.8E+308 |
-
- 浮点数的声明:float(M,D),double(M,D)
M:总位数 D:小数位数 M-D:整数位数
例如:float(9,3) 一共9位数,小数3位,整数6位.
double(9,3) 一共9位数,小数3位,整数6位.
-
- 精度问题:float 只有 6~7位可信数
double 有 14~15位可信数据
- 定点型-保存小数
- 主要用于存储金额
-
decimal(M,D) 存D位小数,M-D位整数,总共M位
-
M的最大值是65,D的最大值是30,默认是(10,0)
4.字符型
- 字符集:字符到二进制的编码的集合,叫字符集
-
latin1 使用1个字节表示字符,gbk使用2个字节表示字符,utf8使用3个字节表示字符,如果有6个字节,在gbk中可以存3个汉字,utf8可以存两个汉字
- mysql支持 40种字符集,查询语法:show charset;
- 客户端设置字符集是为了告诉服务器,我要用哪个字符集来跟服务器沟通,设置字符集:set names utf8;
-
- 定长和变长字符串
- 定长char(L):有多少空间就占用少空间,不会回收剩余的空间。L的最大长度是255字符,utf8中一个字符相当于3个字节,gbk中一个字符相当于2个字节
- 变长varchar(L):如果空间没用完,剩余的空间,mysql会回收。L:最多字符数,理论最大长度是65535字节,但事实上达不到
-
一般我们不能确定插入的值的长度,要用varchar
- text型-保存长文本
|
数据类型 |
描述 |
|
char(L) |
定长字符 |
|
varchar(L) |
可变长度字符 |
|
tinytext |
大段文本(大块数据) 28-1=255个字符 |
|
text |
大段文本(大块数据) 216-1=65535个字符 |
|
mediumtext |
224-1 |
|
longtext |
232-1 |
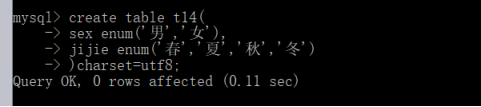
- 枚举enum-相当于单选
- 语法:enum(选项)
-
- 意义:只能选择指定的值的一个
- 优点可以控制插入的数据;节省保存数据的空间;可以提高查询的速度。
- 集合set-相当于多选
- 语法:set('值1','值2',,,)
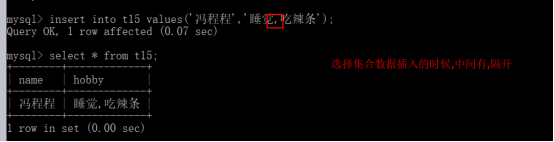
- 创建表

-
- 插入数据
- 日期时间
|
数据类型 |
描述 |
|
datetime |
日期时间 占8个字节 0001-01-01 00:00:01 ~ 9999-12-31 23:59:59 |
|
date |
日期 |
|
time |
时间 |
|
year |
年份,占用1个字节 |
|
timestamp |
时间戳,占用4个字节 最大值1970-01-01 00:00:01 ~ 2038-01-19 11:14:07 |
5.列属性
6.运算符
- 运算符
- 算数运算符:+ - * / % 取余/取模
- 关系运算符:> ≥ < ≤ !=
- 逻辑运算符
-
&& 与 and 两个条件都满足
-
|| 或 or 两个条件满足一个
-
! 非 not 取反
-
- 小括号()
小括号内优先级最高
- 别名as
可以对表名,字段名使用as来取别名,可以解决重名问题。取别名as可省略
7.索引
二.基础语句(sql)
1.语法
select 选项 from 表名 [where 条件] [group by 字段名] [having 条件] [order by 字段] [limit 参数];
2.字段列表
from子句;distinct;聚合函数-做一些统计
|
聚合函数 |
描述 |
|
sum() |
求和 |
|
avg() |
求平均值 |
|
max() |
最大值 |
|
min() |
最小值 |
|
count() |
记录数 |
3.where条件
- 关系和逻辑运算:对值进行过滤,符合条件的就查询出来。所有的关系运算,都可以使用到where条件里面。
- 空和非空:is null和is not null
- 在和不在:in和not in
- in 在......范围内:where 字段 in('值1','值2')
- not in 不在......范围内:where 字段 not in('值1','值2')
- between和not between
- 在什么范围 -- 数值型,日期时间
- 语法: ....where 字段 between 值1 and 值2. 在什么范围之内
-
语法: ....where 字段 not between 值1 and 值2. 不在什么范围之内
- 通配符
- 下划线(_):匹配一个字符
- 百分号(%):匹配多个字符(包括没有字符)
- 模糊查询(like)
- ......where 字段 like '值'; 值一般使用通配符
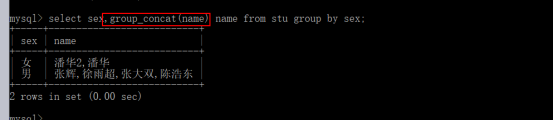
- group by 分组: ......[where 条件] group by 字段
- select sex,group_concat(name) name from stu group by sex;通过分组显示男的所有成员的姓名和女的所有成员的姓名,使用group_concat()函数将同一组的值连接起来
![]()
- having条件:对查询结果进行筛选
- where:查找的范围是当前表中的字段
- having:查找的范围是select后面的选项(即查询结果)作为条件查找
- asc:升序,默认,从小到大,可省略不写
- desc:降序,从大到小
- limit限制:...... limit 起始位置,个数; 如果开始位置为0,可以省略
- select * from stu order by age desc limit 3;首先降序
- limit m,n:从m开始向后取n条数据
- 从表中查询的结果都是从0开始排序
4.数据库操作
- 创建数据库:creat database [if not exists] '数据库名' charset=字符编码;
- 数据库名是关键字或特殊符号需要,一般不需要反引号
- if not exists,创建了一个已经存在的数据库,此命令不报错且不覆盖
- 查看数据库:show database;
- 数据的本质是文件夹
- 查看创建数据库的sql语句:show creat database 数据库名;
- 数据库修改-修改字符集:alter database 数据库名 charset-字符集;
- 删除数据库:drop database [if exists] '数据库名';
- if exists删除之前判断一下,存在就删除
5.表的操作
- 数据库的选择:use '数据库名';
- 创建表:creat table 表名(字段列表) [values('','',,,)]
- creat table ceshi(id int);
- 表也是以文件的形式保存的
- 查看所有表:show tables;
- 查看创建表的sql语句:show creat table 表名[\G];
- 加上\G则不需要分号
- 查看表结构:desc 表名;
- desc即describe
- 修改表名:alter table 原表名 rename to 新表名;
- 修改表的字符集:alter table 表名 charset=新字符集;
- 修改字段属性:alter table 表名 modify 字段名 新数据类型;
- 修改字段名称和属性:alter table 表名 change 原字段 新字段 新属性;
- 表引擎修改:alter table 表名 engine=新引擎;
- mysql引擎分为:MyISAM:查询的速度比较快; InnoDB:新的引擎,主要维护数据的安全。
- 删除表:drop table [if exists] 表名;
- 删除多个表:drop table 表1,表2,,,;
- 添加表字段:alter table 表名 add 字段名 数据类型;
- 删除字段:alter table 表名 drop 字段;
- 修改字段:alter table 表名 change 字段名 新字段名 新数据类型;
6.数据操作
- 创建一个表:
creat table ceshi(
id int,
name varchar(20),
hobby varchar(10),
addr char(10)
);
- 插入1-n条数据:
insert into 表名(字段列表) values(字段列表1),(字段列表2),,,
-
- 值和字段一定一样,他俩一致则再添加可以省略字段
- insert into ceshi(id,name,hobby,addr) values(1,'玉环','吃荔枝','唐朝');
- 查看表数据:select * from 表名 [where 条件];
- 汉字乱码要给显示框设置字符集:set names utf8;
- 更新数据:update 表名 set 字段1=值1,字段2=值2,,, where 条件;
- 删除数据:delete from 表名 where 条件;
- 注意添加where条件,没有条件则全表删除
- 给字段(或者表)起别名:select id as '新id',name as '新名字,hobby as '新爱好',addr as '新地址' from ceshi;
- 去除重复的数据:select distinct name,hobby from ceshi;
7.子查询
- 在一个select语句中,嵌入了另外一个select语句,那么被嵌入的select语句称之为子查询语句
- select * from stu where math>(select avg(math) from stu);
- ......where 字段=some || any || all(子查询);
- some:一些,any:任何,all:所有
- some和any等同于in,not in可以写成!=all
- ......where exists || not exists
- exists:存在,not exists:不存在
- ......where 字段=some || any || all(子查询);
8.连表查询
- 连接的作用:当查询结果的列表来源于多张表时,需要将多张表连接一个大的数据集,再选择合适的列返回
- 内连接查询:查询的结果为两个表重叠部分匹配到的数据
- 左连接查询:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null填充
- 右链接查询:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用null填充
- 内连接:select 选项 from 表1 inner join 表2 on 表1.相同字段=表2.相同字段;
- 左连接:select 选项 from 表1 left join 表2 on 表1.相同字段=表2.相同字段;
- 左表数据全部取出,右表只要符合条件的,没有的用null
- 右连接:select 选项 from 表1 right join 表2 on 表1.相同字段=表2.相同字段;
- 右表数据全部取出,左表只要符合条件的数据,没有的用null
- 两张表中的字段名是一样的可以简写成using形式
- select * from student right join scores using(studentno);
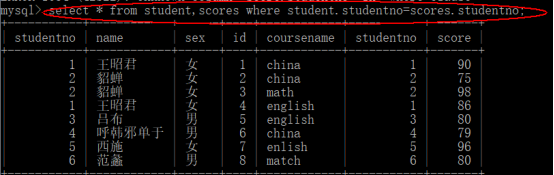
- 笛卡尔积:多表中数据排列组合,结果是字段连接,行数相乘,通过where条件,可以筛选出我们需要的数据
- select * from table1,table2 where 连接条件
![]()
9.事务
10.视图view
11.函数
- select 函数名() from ...;
- 聚合函数:
- sum(expr): 求和
-
- avg(expr): 求平均数
- max(expr) 求最大值
- min(expr) 获取最小
- 数值处理:rand()随机数
- 随机排序:select * from 表名 order by rand(); 随机数:select rand()...
- 四舍五入round():select round()
- 字符处理:
- 左边截取:left('字段',长度)
- 右边截取:right('字段',长度)
- 查看字节长度:select length('字段') '字节长度';
- 查看字符长度:select char_length('字段') '字符长度';
- 字段拼接:select group_concat(字段) from 表名;
- 加密函数
- select md5(密码);
- select password(密码);
12.外键
二.工作中遇到的较复杂语句(postgresql)
1.with
- sql语句
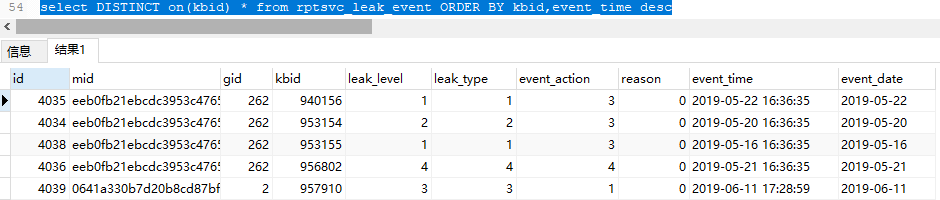
WITH type as (select DISTINCT on(kbid) * from rptsvc_leak_event ORDER BY kbid,event_time desc) SELECT leak_type,count(*) FROM type GROUP BY leak_type

- 解释
- 括号中的语句:select DISTINCT on(kbid) * from rptsvc_leak_event ORDER BY kbid,event_time desc,按照event_time降序、且对kbid去重后,返回所有内容。注意:order by之后一定要加kbid,不然报错。
-
- with后用as 将括号中的sql语句赋值给type,即type是一个新表。
- 这整个with语句可以替换成:
SELECT leak_type,count(*) FROM (select DISTINCT on(kbid) * from rptsvc_leak_event ORDER BY kbid,event_time desc) as type GROUP BY leak_type,
同样也要注意加as,不然语句不正确
2.row_number() over
- sql语句
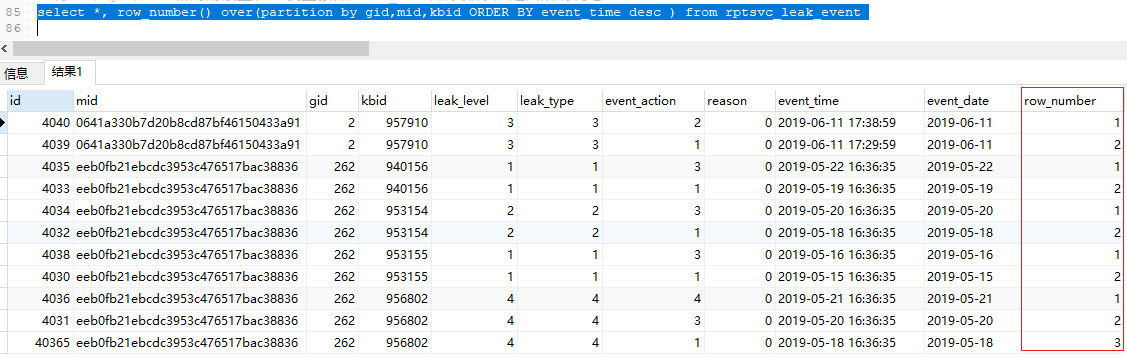
select *, row_number() over(partition by gid,mid,kbid ORDER BY event_time desc ) from rptsvc_leak_event
- 解释
- row_number() over(partition by gid,mid,kbid ORDER BY event_time desc ):先按照kib,gid,mid分组、且按照event_time降序排序,再为返回的内容每条给一个序号,每组的序号都是从1开始。
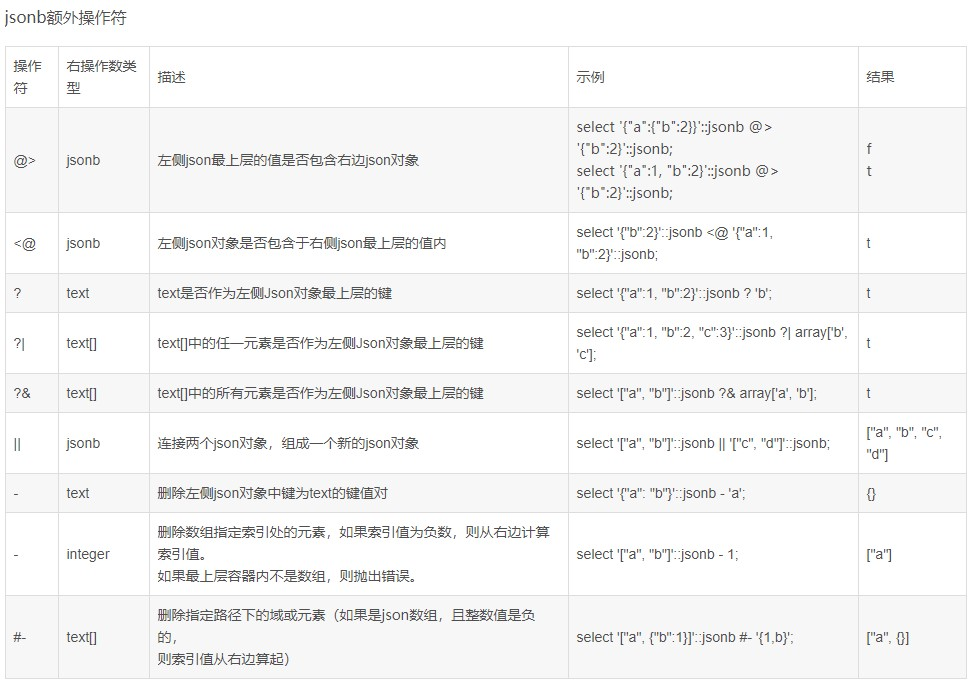
3.jsonb
- sql语句
select victim_ip from alarms where victim_ip @>'["203.208.41.46"]'::jsonb;
- 解释
- 当某个字段是jsonb类型时,要查询包含某内容的所有字段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号