【流行前沿】Fundamentals of Task-Agnostic Data Valuation
今天分享一篇8月arxiv上发布的研究数据价值评估的文章,作者Amiri从Princeton又换到MIT的媒体实验室了。
故事的起源是作者想衡量数据的价值,但是又不想依赖于现有的两种流行方法:内部检验与外部竞争。
内部检验就是说,有一个确定的验证集或验证模型,用得到的指标来评判数据价值。这里的问题首先是验证本身就并不好实现,同时如果验证流程泄露,很容易被攻击。外部检验就是用博弈论的思想,根据竞争和需要来估计数据的价值。这是种“供需关系”的体现,并没有反应数据本身的价值。
那么作者想怎么搞呢?作者其实是站在用户的角度,对“供需关系”中的“需”做了进一步的解释。如何来看我需不需要这个数据呢:1)要看这个数据和我现有的数据有多大关系。如果我想做人脸识别,结果数据集只有猫狗,显然就没必要买了。2)要看这个数据集的丰富程度。如果数据集里面的东西我都有,那也没有必要花钱买这些。因此,作者就总结出了两个关键指标,分别是relevance和diversity。
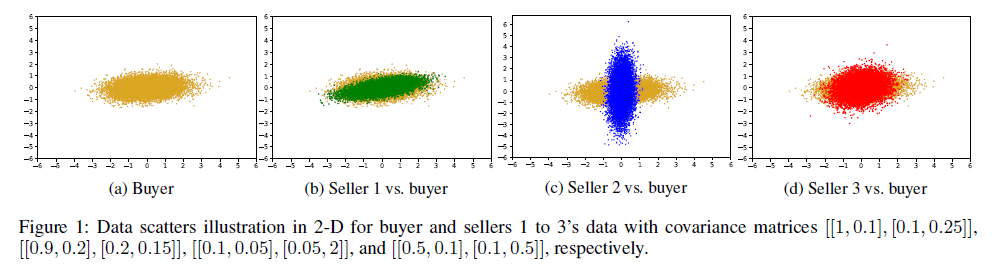
接下来应该如何定义这个指标呢?如果按照最小白的做法,那就是各找一个然后加起来。比如用余弦相似度来衡量relevance,用离散程度散度来衡量diversity。但是这样做有若干风险,首先是来源不同的指标往往数量级不同,可能造成小指标的淹没。另外relevance和diversity有折衷关系在里面,需要满足一个此消彼长的趋势,因此如果这两个指标来源于同一个计算量,那就比较合适了。
现在想一想,来源于同一个计算量?此消彼长?那不就是给定矩形面积然后调整长宽?因此作者找到PCA分析后的特征值来衡量数据集的分布,然后通过目标数据和现有数据的比较,分别计算相关的部分和差异的部分(也就是多样性)。
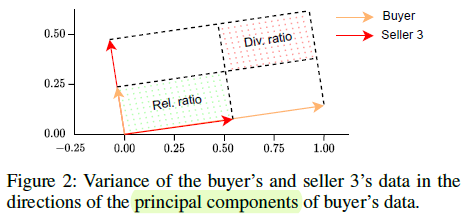
在找到这个指标后,接下来自然就是各种具体处理。包括数值的分布(归一化、分布在0.5附近)、在实际数据上面的验证。这部分自不必多说。
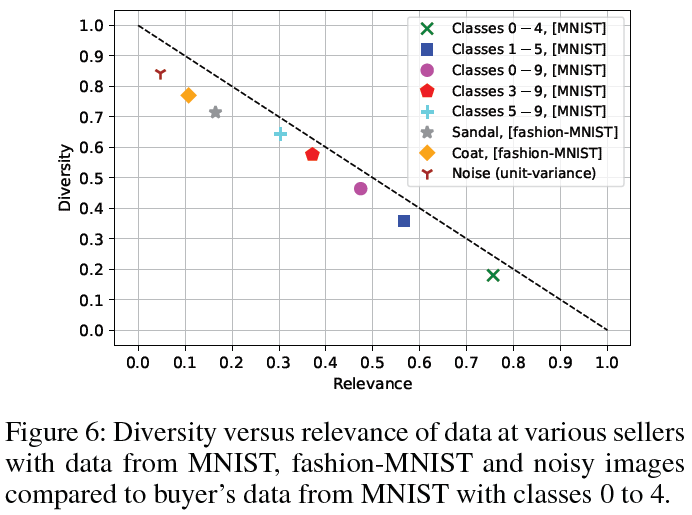
总结:这篇文章其实是满足”故事完整、逻辑严谨、有创新性“这个基本要求的。最大的价值在于在原有只看”diversity“的传统上,又新增了一个”relevance“的角度。这或许是说,其实我们评判一个数据,不一定只建立在某一个固定的维度上(如仅仅是分布距离),而是可以客观准确地分别建立各个重要维度的评判,让用户根据自己的需求来选择。此时关键的问题就在于如何设计相互兼容(数量级相近)、来源统一(不是简单加和)的评判指标。最好是同一个表达式的不同刻画维度,以此对应数据的不同方面的刻画。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号