【流行前沿】QSFL: A Two-Level Uplink Communication Optimization Framework for Federated Learning
今天分享一篇研究模型细粒度传输的联邦学习文章,作者Liping Yi来自于南开大学,发表在ICML 2022。
Intro
故事的起源还是来自于深度网络越来越大,导致上行链路达到了TB级别,这对于低带宽的无线上行链路来说太难传输了,因此要对通信过程进行优化。作者总结了现有的communication-effective schemes,也就是delaying communication, sampling clients, encoding models, sparsification, quantization,然后说这些都不行。这里就有点牵强,明明有部分效果还不错而且也有理论分析的。那这篇文章呢,就提出了更进一步的传输方式,主要是两个level:
-
首先是用户的层级。只选取“高质量”的用户上传,其他的不传,开销就小了。这个“高质量”定义,会是文章的看点。
-
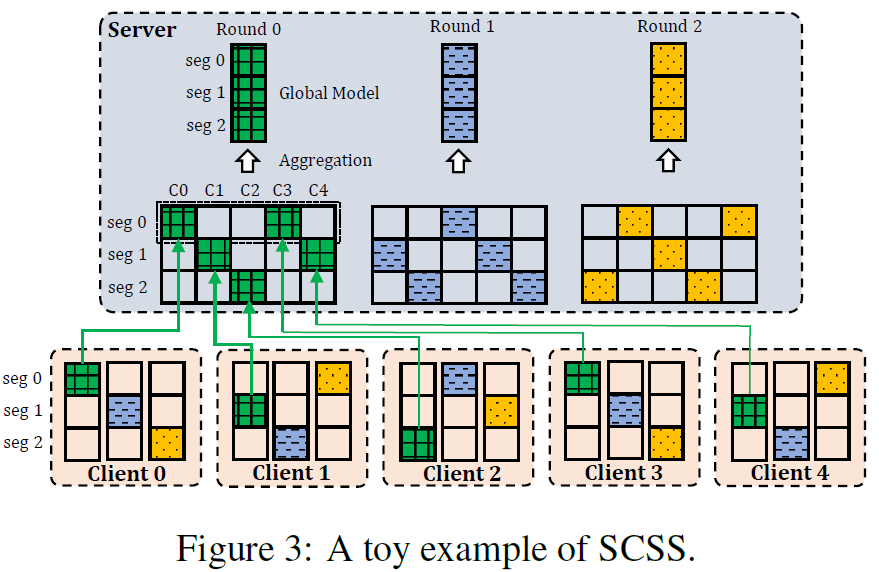
其次是模型的层级。之前一次都传一整个模型,先把一个大模型切分成若干帧,一次传一帧,不同用户拼接起来,这模型就能用了。这里的关注点就在于,如何切分,上传谁的,如何保证收敛性,效果如何,是后文看点。
接下来根据这两个部分分别讨论。
用户选择
用户质量的刻画使用了贡献度和相关性的加权平均,具体表达式为

在贡献度方面,文章是选取loss大的用户而不是loss小的用户。按理说loss越小模型越好,但是文章的解释是loss越大,梯度下降越大,收敛速率越快。此时舍弃一些已经训练到小loss的用户,对整体的loss下降没什么影响。其实也有道理,因为大loss表示这个用户急待更新,将其作为上传的组成是合理的。
在相关性方面,文章比较了用户梯度与上一轮全局梯度在方向上的差异。文章的解释是梯度符号的一致性能够保证一致的梯度方向,因此收敛速率会加快。这个选择确实能很快收敛到至少一个方向上的最优点,对于iid的时候应该是很有效的。
总之,这两个方法都是为了比较快的让所有用户都达到收敛条件。
模型的帧传输
模型先被切分为若干帧,然后每个用户传一帧。需要确保上传的帧数不小于上传用户的帧数,这样模型才能完整传输。还有一个trick是,上传帧的时候,其ID的计算是\((client id + round)\%NS\),因此每个用户相邻两次上传都是一个模型的相邻两个部分,具有很强的相关性。估计这样的原因是为了让整体模型没有比较大的抖动,在训练上保持了一致性。
收敛性证明
首先文章只证明了帧传输技术是收敛的,对于用户选取没有证明(毕竟这个太麻烦了)。文章的证明思路来源于“randomly discarding a fraction of the gradients/parameters”。猜测这个证明思路应该是先分析模型传输部分时带来的向量,然后结合到收敛框架中作为一个项。其实这也打开了一种思路,不管是什么天花乱坠的操作方法,只要以距离为起点,应该就能推出来收敛界。
另外在优化超参的时候,文章直接用了GA,这方面没什么好说的。
仿真
文章开源了官方代码,让人非常感动,就冲这份勇气也要好好扒一下这个代码!
扒了一下午,失败了。今晚看懂Flask,下次开一篇重新讲,
文章用了bash文件来进行批处理,看来这个是常规操作,也需要学。
另外仿真结果还是有一点值得说一下。仿真的用户数量上,文章选取了\(C ∈ {10, 20, 30, 40, 50}\)。注意单独的帧传输几乎是不受用户数量影响的,但是在用户选取的时候,只有在用户数量超过40的时候才没有震荡。也就是说,更新步子不能太大,否则会扯着蛋;另外就是iid的冗余度太高了,确实不太需要传输这么多类似的模型参数。
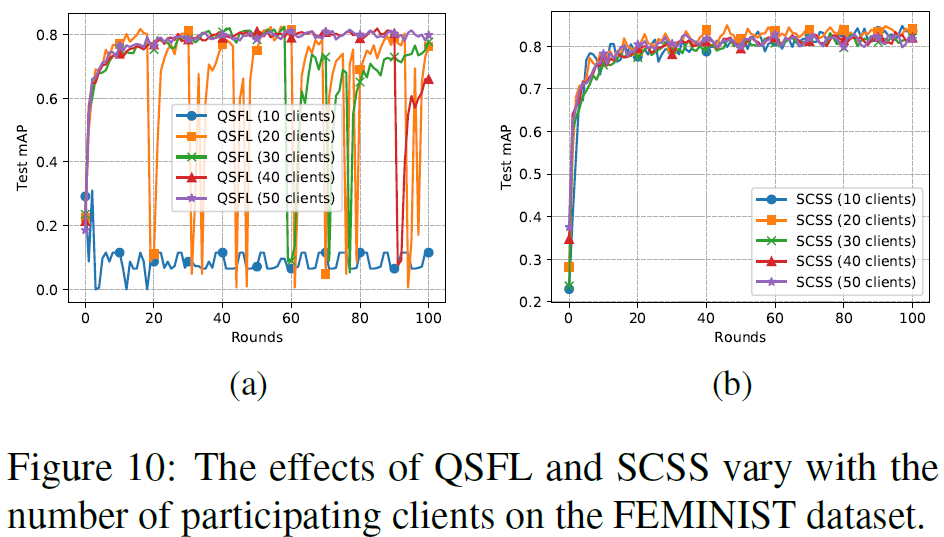
另外这个收敛速率肯定是会慢一点的,作者也承认了不过就没做实验,具体有多慢就不知道了。
总结
这篇文章展示的一个趋势是多种communication-efficient技术的交叉使用。在这篇文章里,就综合应用了client sampling, uploading delaying, sparsification三种方式。目前来看自己在代码上面还差得比较多,就快速理解复现上面还做得不太行。还得多看多想才行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号