【论文考古】量化SGD Federated Learning with Quantization Constraints
简介
这篇文章是通信领域对FL进行量化的代表作,其中挂名的IEEE Fellow都是通信领域的大佬。与机器学习领域的研究思路不同,这篇文章没有强调神经网络的训练或者SGD的收敛性分析,而是站在通信的角度,研究如何针对FL的特性来设计量化算法,从而使得传输错误尽量小。最终本文选择的FL特性是FedAvg时多用户平均对量化带来的增益,并主要运用了1996年左右的格编码相关理论。文章首先给出了用户数量越多,量化误差越小的理论分析,并进行了实验验证。同时实验验证了较小量化误差带来的FL性能增益。
理论
-
subtractive dithered lattice quantization的步骤
![image-20220310113530071]()
-
quantization:选最靠近的格的对应的整数组合
![image-20220310114337086]()
-
partitioning是将矩阵分成向量来量化;dithering其实还是满足了量化后向量的均值不变;entropy coding只是为了进一步降低rate,并不是核心的东西
-
-
在FedAvg聚合时,量化误差会随着用户数量的增加指数级消失
![image-20220310114550004]()


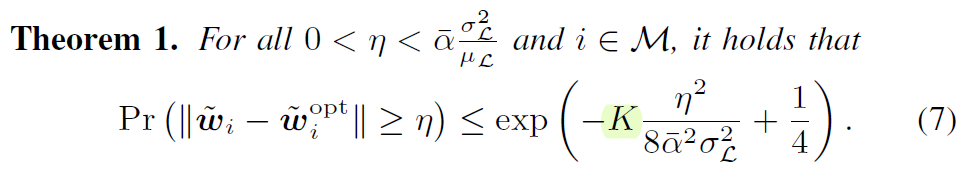
实验
- 先做了量化误差的比较,然后做了FL性能的比较
- FL部分非常拉跨,学习的是一个映射\(f(\alpha)=\sin 6\pi \alpha\),同时神经网络是个两层的sigmoid激活函数,完全不能体现出深度神经网络的特性,错误概率甚至超过\(0.1\)
观点
- 没有使用分布式有损信源编码的原因
- 计算上复杂
- 要求编译码器知道所有用户更新参数的联合分布,这是不现实的
评价
- 在通信的角度,研究的还是如何衡量传输中速率与误差的关系。从这个地方进行切入,能蹭到许多热点,而且凭借solid information theoretic arguments蹭得理直气壮。主要的工作就在于根据新场景的特性、信息论中的条件,选择合适的技术。
- 文章并没有根据信道条件来改变传输条件,而是由信道条件计算出可以无损传输的比特数量,用来进行量化。
- 为了水字数,可以放一些无效的想法(比如分布式信源编码、联合entropy code),告诉大家这样做我已经想过啦,行不通
- Question old school assumptions:为什么每个用户的编码器要一样?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号