【流行前沿】联邦学习 Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits
Sunwoo Lee, , Anit Kumar Sahu, Chaoyang He, and Salman Avestimehr. "Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits." (2022).
简介
传统FedAvg算法下,SGD的多轮本地训练会导致模型差异增大,从而使全局loss收敛缓慢。本文作者提出每次本地用户更新后,仅对部分网络参数进行聚合,从而降低模型间参数差异。在128个用户时,验证准确率比FedAvg提高了2.2%,loss的下降速度也更快。但是该算法并没有减少传输的参数量,甚至会增加传输的次数,从而可能会提高总的延迟。
核心算法

每次更新所有用户网络的同一个部分,在周期\(\tau\)内完成网络所有参数的更新。和FedAvg相比,同样是交换了所有参数,只是改成了高频分部更新,所以差异会小一些。
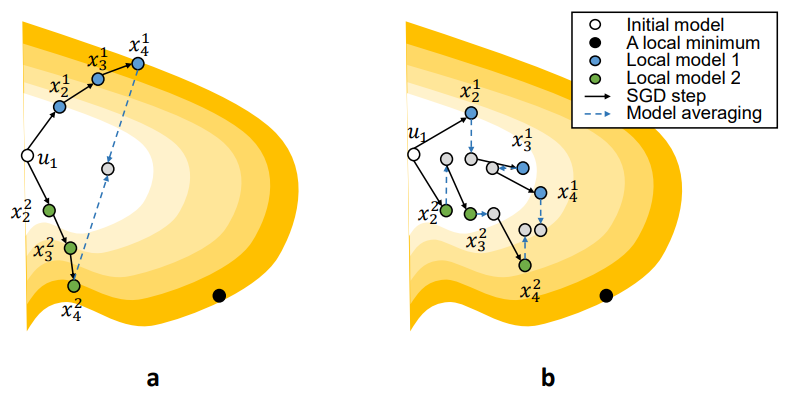
理论推导
非常高深的理论推导,如何对部分网络进行操作值得学习【挖坑】
目前来看,根据数据进行优化,和贝叶斯学习,似乎是两种不同的理论分析思路。
仿真效果
- 用Dirichlet's distribution来生成异构数据分布
- cross-silo和cross-device的区别:cross-device表示每个时间节点只有部分客户端在线,cross-silo表示所有用户一直在线。
- variance reduction的技术会损害泛化性能
- 附录中的仿真设置非常详细,可以参考
评价
价值 = 新意100×有效性1×问题大小10
- 新意主要来源于理论推导部分,很硬核
- 网络更新的划分与数据分布并没有建立联系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号