【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容
G. Hinton, O. Vinyals, and J. Dean, “Distilling the Knowledge in a Neural Network.” 2015.
如何将一堆模型或一个超大模型的知识压缩到一个小模型中,从而更容易进行部署?
-
训练超大模型是因为它更容易提取出数据的结构信息(为什么?)
-
知识应该理解为从输入到输出的映射,而不是学习到的参数信息
-
模型的泛化性来源于错误答案的相对概率大小(一辆宝马被误判为卡车的概率大于被误判为萝卜的概率),而泛化性是学习的终极目标
-
基本构架:学习高温Softmax之后的值
![image]()
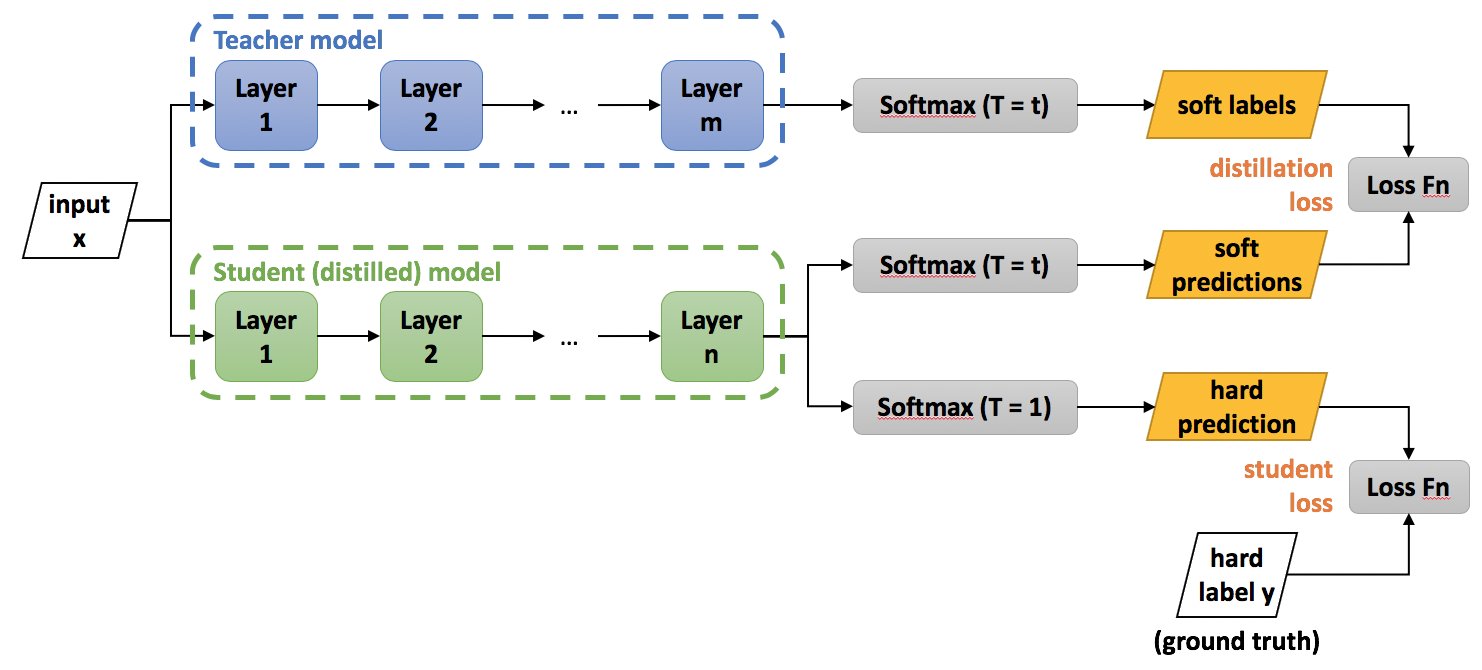
超大数据集下如何训练?
-
论文给出的方法:用专家模型独立训练容易混淆的数据,在准确率略微提高的基础上,将训练时间从许多周缩短为几天
-
模型集合是一个针对所有数据的generalist model和许多针对相近数据的专家模型。训练专家模型时,用generalist model的参数进行初始化(这样可以防止过拟合),训练数据一半是相近数据的集合,一半是随机选取的其他数据
(correct for the biased training set by incrementing the logit of the dustbin class by the log of the proportion by which the specialist class is oversampled 应该如何理解?)
-
分配不同种类到专家模型:将容易混淆的预测进行聚类,从而分配到专家模型
-
最后对包含专家模型的一组神经网络进行知识蒸馏,提炼成一个同样大小的单一神经网络,方便部署
实际效果
泛化性的检验:在MNIST数据集中,仅靠知识蒸馏,能识别出缺失的某张图片吗?
金句启发
-
把dropout和分布式学习相结合?
Dropout can be viewed as a way of training an exponentially large ensemble of models that share weights.
-
FL的特点在于数据不能共享,所以不能在服务器端做模型融合。能不能做一个分布式的知识蒸馏,用专家模型解决异构数据的难点?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号