Hadoop知识点总结
一:大数据概述
一、大数据简介
1. 概念:指无法在一定时间范围内使用常规软件工具进项捕捉、管理和处理数据集合,需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。
2. 作用:解决海量数据的存储和海量数据的分析计算问题。
3. 大数据与云计算的关系:大数据必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术,有效地处理大量的容忍经过时间内的数据。
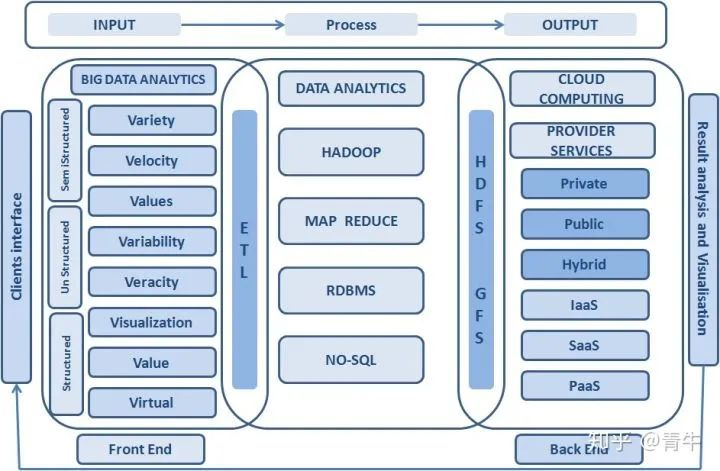
二、大数据特征
1. Volume(容量大):数据的大小决定所考虑的数据的价值和潜在的信息。
2. Velocity(速度快):获得并处理数据的效率。是区分传统数据挖掘最显著特征。
3. Variety(多样性):数据类型的多样性。以数据库/文本的结构化数据和以网络日志,图片,音频、视频等为主的非结构化数据。
4. Value(价值):合理运用大数据,以低成本创造高价值。
5. Variability(可变性):妨碍了处理和有效地管理数据的过程。
6. Veracity(真实性):数据的质量。
7. Complexity(复杂性):数据量巨大,来源多渠道。
三、大数据应用场景
1. 物流仓储:大数据分析系统助力商家精细化运营,提升销量,节约成本。
2. 零售及商品推荐:分析用户消费习惯,给用户推荐可能喜欢的商品,为用户购买商品提供方便。
3. 旅游:深度结合大数据能力和旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。
4. 保险:海量数据挖掘及风险预测,助力保险行业精准直销,提升精细化定价能力。
5. 金融:多维度体现用户特征,助力金融机构推荐优质用户,防范欺诈风险。
6. 房地产:大数据全面助力房地产行业,打造精准投资与营销,选出更合适的地,建更合适的楼,卖更合适的用户。
7. 人工智能:深度结合大数据能力及人工智能,提供数据资源。
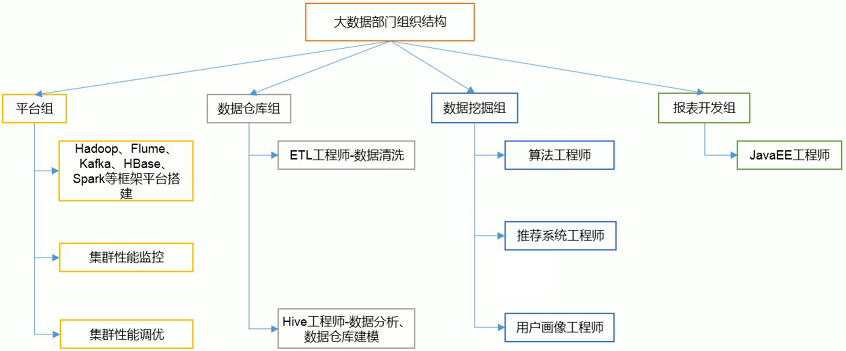
四、大数据部门组织结构
二:Hadoop 概述
一、Hadoop 简介
1. 概念:Hadoop 是由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
2. 作用:解决海量数据的存储和海量数据的分析计算问题。
3. 优点
1. 高可靠性:Hadoop 能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2. 高扩展性:Hadoop 在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点中。
3. 高效性:Hadoop 可以在节点之间动态并行的移动数据,使得速度非常快。
4. 成本低:Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
3. 发展历程
1. Hadoop 起源于 Apache Nutch 项目,始于2002年,是 Apache Lucene的子项目之一。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年、2004年,Google 发表的"分布式文件系统(GFS):可用于处理海量网页的存储 " 和 “分布式计算框架(MapReduce):可用于处理海量网页的索引计算问题” 两篇论文为该问题提供了可行的解决方案。
3. 由于 NDFS 和 MapReduce 在 Nutch 引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop(大数据生态圈,包含很多软件)。
4. 到了2008年年初,Hadoop 已成为 Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。
4. 三大发行版本
1. Apache Hadoop:免费开源,拥有全世界的开源贡献者,代码更新迭代版本比较快,但难以维护,适合学习使用。
1. 官网地址:http://hadoop.apache.org/releases.html
2. 下载地址:https://archive.apache.org/dist/hadoop/common/
2. Cloudera Hadoop:版本兼容性更好,适用于互联网企业。
1. 官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
2. 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
3. Hortonworks Hadoop:核心免费开源产品软件HDP(ambari),提供一整套的web管理界面来管理集群。
1. 官网地址:https://hortonworks.com/products/data-center/hdp/
2. 下载地址:https://hortonworks.com/downloads/#data-platform
二、Hadoop 核心架构
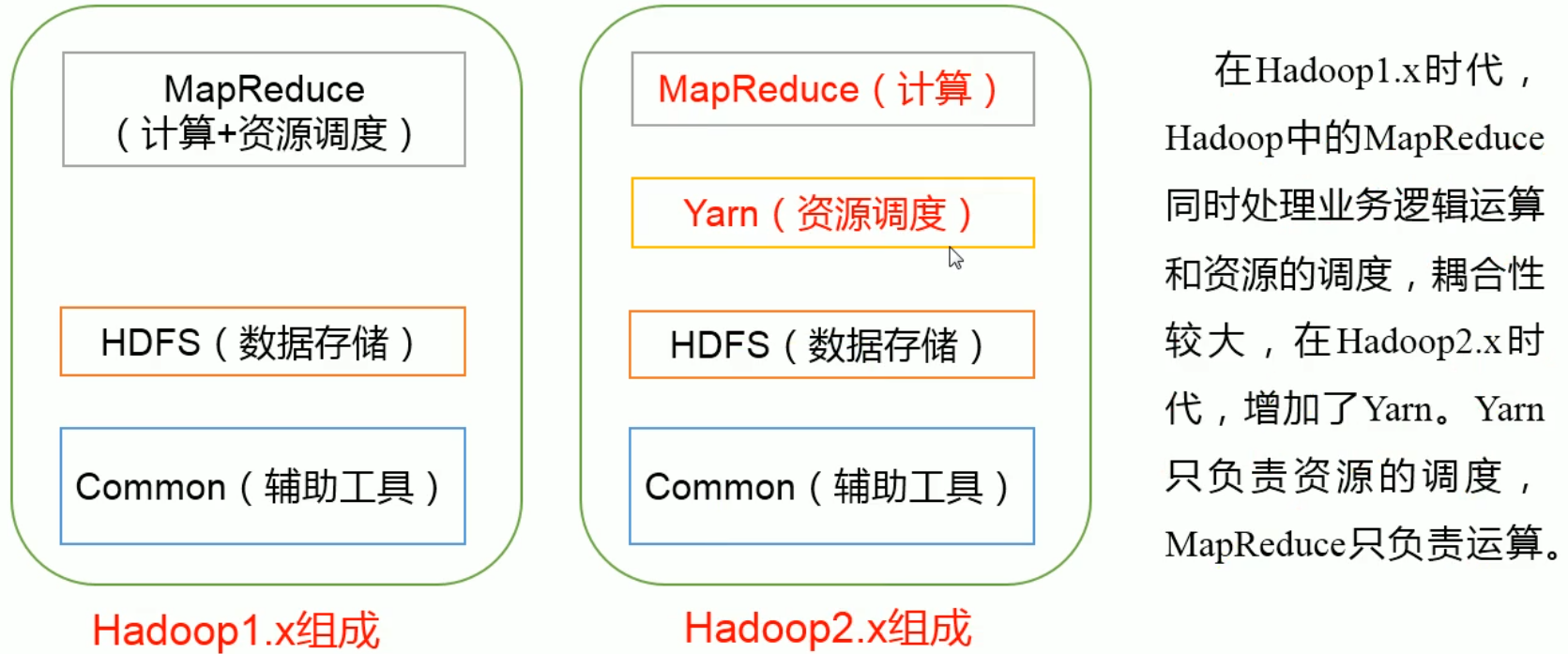
1. 历史版本及组成
2. HDFS(Hadoop Distributed File System 分布式文件系统) 架构概述
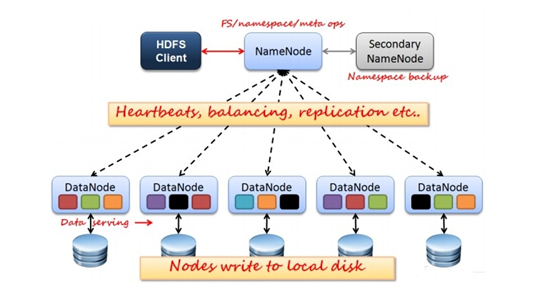
1. NameNode:管理集群当中的各种元数据,如文件名,文件属性(生成时间,副本数等)以及每个文件的块列表和块所在的DataNode等。
2. DataNode:存储集群中的各种块数据到本地文件系统并校验块数据。
3. Secondary NameNode:监控HDFS状态的辅助后台后台程序,每个一段时间获取HDFS元数据快照。
3. Yarn(Yet Another Resource Negotiator 资源管理调度系统) 架构概述

4. MapReduce(分布式运算框架) 架构概述
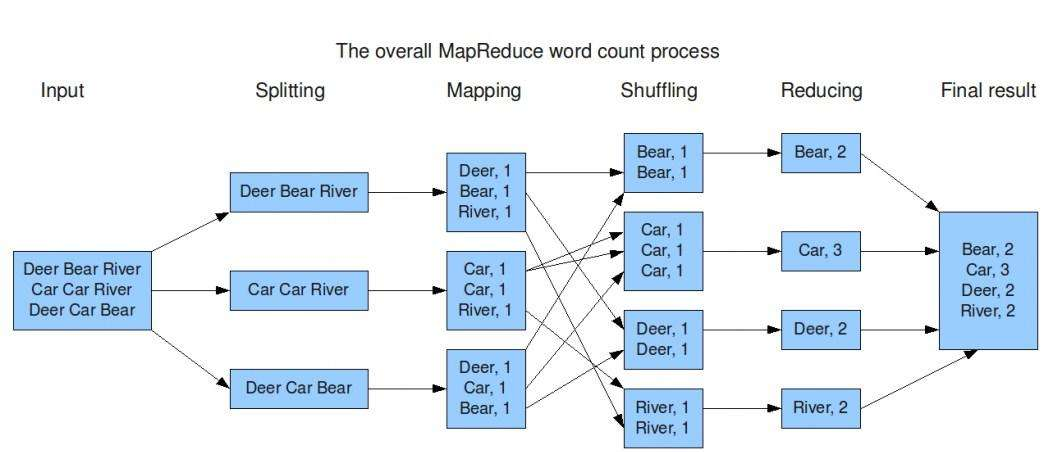
三、Hadoop 生态圈
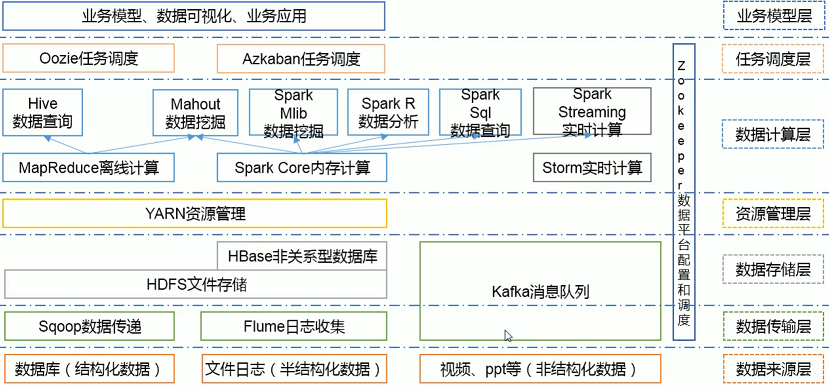
1. HDFS:Hadoop 分布式文件系统(Hadoop Distributed File System),建立在集群之上,适合PB级大量数据的存储,扩展性强,容错性高。
2. MapReduce:Hadoop 的计算框架,由 Map 和 Reduce 两部分组成,由Map生成计算的任务,分配到各个节点上,Reduce执行计算。
3. HBase:源自谷歌的 BigTable,是一个分布式的、面向列存储的开源数据库,性能高,可靠性高,扩展性强。
4. Hive:Hadoop 的数据仓库工具,将个结构化的数据文件映射为一张数据库表,通过类 SQL 语句快速实现简单的 MapReduce 统计,十分适合数据仓库统计。
5. Sqoop:Hadoop 的数据同步工具,将关系型数据库(MySQL、Oracle等)中的数据表和 HDFS 中的文件进性相互导入导出。
6. Flume:Hadoop 的日志收集工具,一个分布式、可靠的、高可用的海量日志聚合系统,用于日志数据收集、处理和传输。
7. Zookeeper:Hadoop 的分布式协作服务,主要作用于统一命名、状态同步、集群管理、配置同步,简化分布式应用协调及其管理难度,提供高性能的分布式服务。
8. Mahout:Hadoop 的机器学习和数据挖掘算法库,实现了大量数据挖掘算法,解决了并行挖掘的问题。
9. Spark:Hadoop 的内存计算框架,为大规模数据处理而设计的快速通用的计算引擎。
10. Pig:Hadoop的大规模数据分析工具,类似于Hive,它提供了 Plight 语言将类 SQL 的数据分析请求转化为一系列经过优化的 MapReduce 运算。
11. Ambari:一种基于Web的工具,支持Hadoop集群的供应、管理和监控等统一部署。
四、Hadoop 实际应用
1. Hadoop+HBase建立NoSQL分布式数据库应用
2. Flume+Hadoop+Hive建立离线日志分析系统
3. Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
4. 在线旅游、移动数据、电子商务、IT安全、医疗保健、图像处理等

三:Hadoop 安装部署(3.1.3版本)
一、伪分布式模式(单节点)
1. 安装并配置 JDK 及 Hadoop
2. 部署HDFS(端口:9870)

3. 部署YARN(端口:8088)
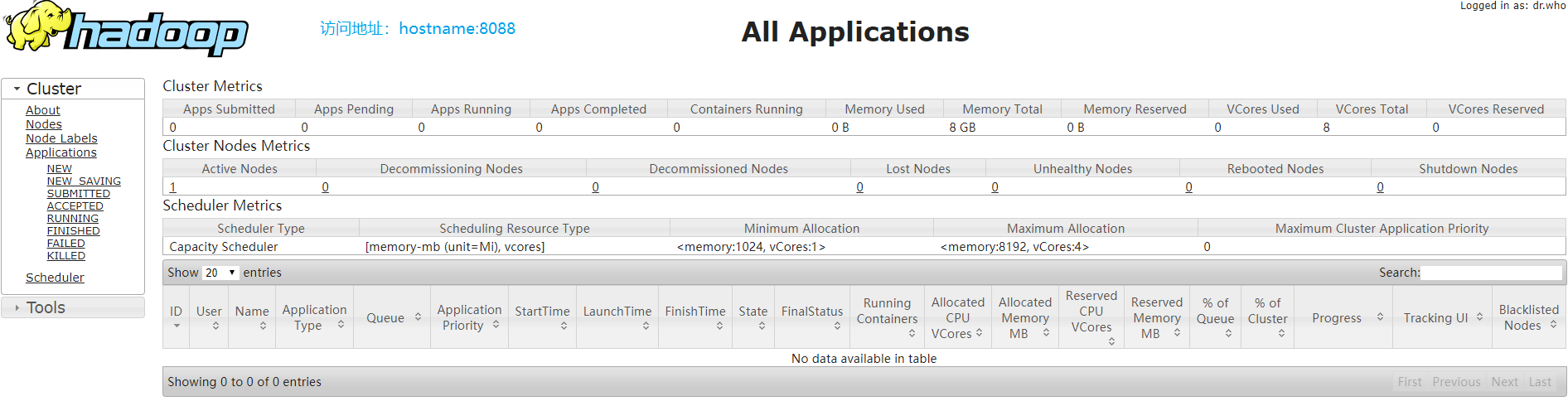
4. 配置历史服务器和日志聚集(端口:19888)
二、完全分布式模式(集群)
1. 配置 xsync 集群分发脚本(关闭防火墙)
2. 配置无密登录及时钟同步
3. 配置集群
4. 运行 wordcount 案例
四:Hadoop 源码编译
一、环境准备
1. Hadoop :hadoop-3.1.3-src.tar.gz
2. JDK:jdk-8u231-linux-x64.tar.gz (1.8及以上版本)
3. Maven:apache-maven-3.6.2-bin.tar.gz (3.5及以上版本)
4. Protobuf:protobuf-2.5.0.tar.gz (网页最下面,必须是2.5.0版本)
5. Cmake:cmake-3.13.5.tar.gz(3.13.0及以上版本)
6. Ant:apache-ant-1.10.7-bin.tar.gz(可不安装,版本1.10.8)
7. Findbugs:findbugs-3.0.1.tar.gz (可不安装,3.0.1版本)
二、安装
__EOF__

本文链接:https://www.cnblogs.com/mh20131118/p/12146993.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix