MongoDB知识点总结
一:MongoDB 概述
一、NoSQL 简介
1. 概念:NoSQL(Not Only SQL的缩写),指的是非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。用于超大规模数据的存储,数据存储不需要固定的模式,无需多余操作就可以横向扩展。
2. 特点
1. 优点:具有高可扩展性、分布式计算、低成本、架构灵活且是半结构化数据,没有复杂的关系等。
2. 缺点:没有标准化、有限的查询功能、最终一致是不直观的程序等。
3. 分类


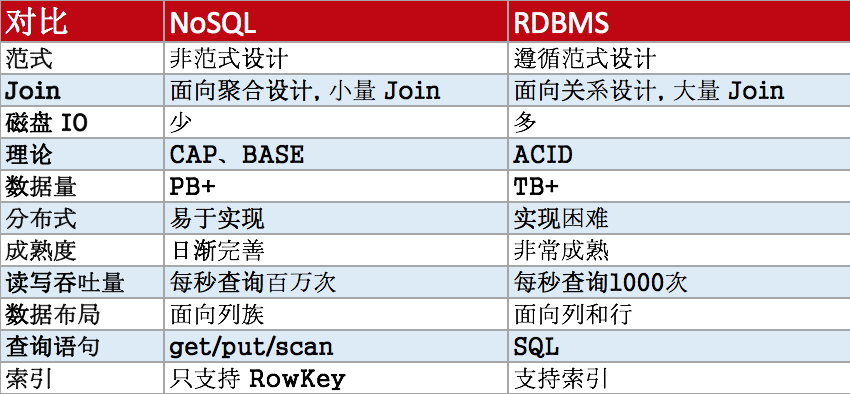
4. NoSQL 和 RDBMS 的对比
二、MongoDB 简介
1. 概念:MongoDB 是由C++语言编写的一个基于分布式文件存储的开源文档型数据库系统。
2. 功能:JSON 文档模型、动态的数据模式、二级索引强大、查询功能、自动分片、水平扩展、自动复制、高可用、文本搜索、企业级安全、聚合框架MapReduce、大文件存储GridFS。
1. 面向集合文档的存储:适合存储Bson(json的扩展)形式的数据;
2. 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
3. 强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
4. 完整的索引支持,支持查询计划;
5. 使用分片集群提升系统扩展性;
3. 适用场景
1. 网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2. 缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源 过载。
3. 在高伸缩性的场景,用于对象及JSON数据的存储。

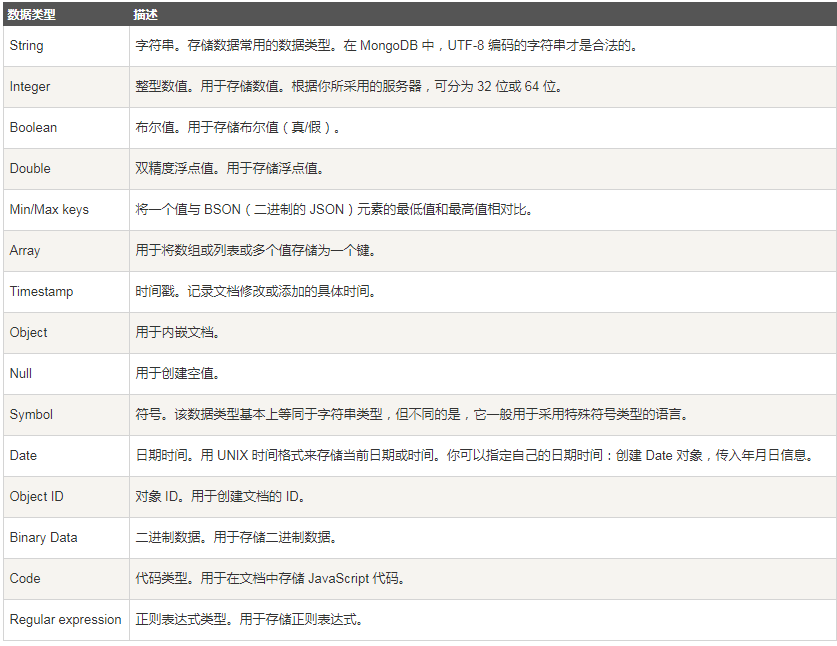
4. 数据类型
三、概念详解
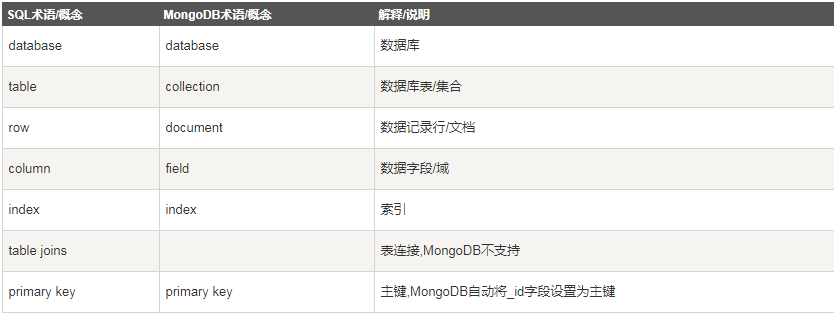
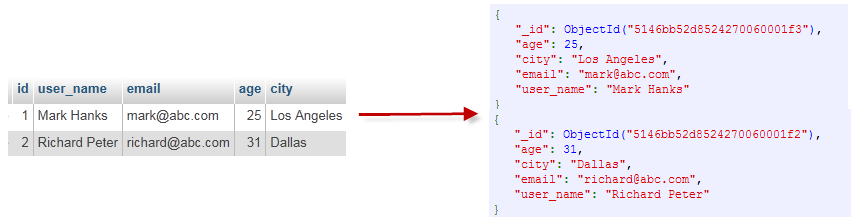
1. 数据库:MongoDB 默认的数据库为"db",该数据库存储在data目录中。单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
2. 集合:集合就是 MongoDB 文档组,类似于 RDBMS 的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
3. 文档:一个键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
四、安装配置
1. Windows
1. 下载(4.2.7版本以上)并直接安装
2. 配置环境变量

3. 测试
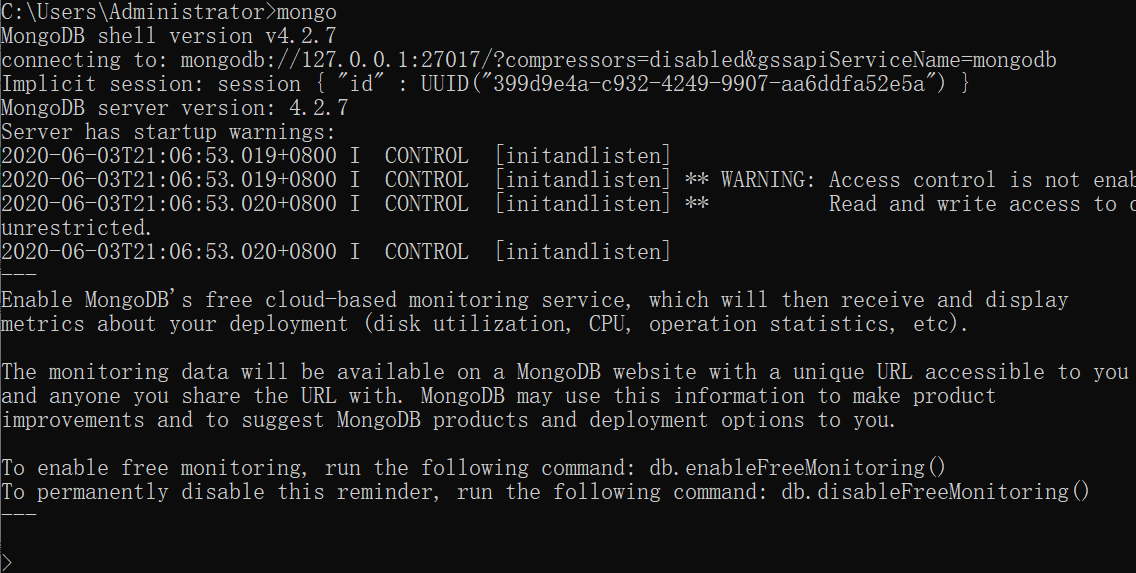
=
2. Linux

二:MongoDB CLI
一、增删改

二、操作符

三、查询
1. 基本操作

2. 聚合查询

3. 管道操作:MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理

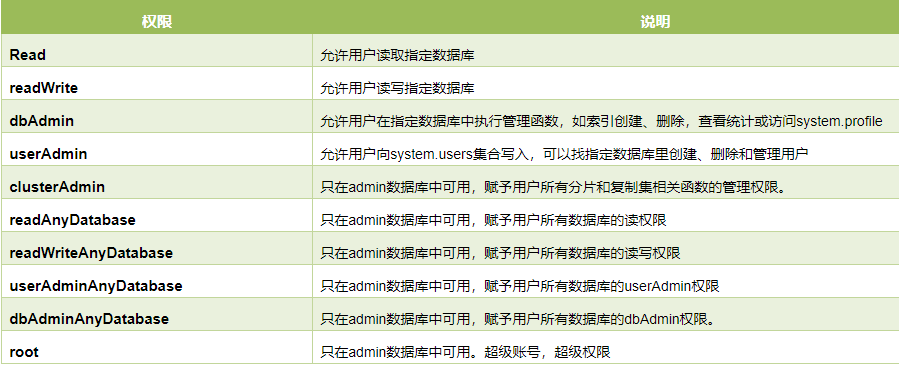
五、管理

六、索引和高可用
1. 索引
2. 高可用
三:MongoDB API
一、客户端连接
二、增删改
三、查询
__EOF__

本文链接:https://www.cnblogs.com/mh20131118/p/12116138.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix