如何实现一个简易版的 Spring - 如何实现 @Component 注解
前言
前面两篇文章(如何实现一个简易版的 Spring - 如何实现 Setter 注入、如何实现一个简易版的 Spring - 如何实现 Constructor 注入)介绍的都是基于 XML 配置文件方式的实现,从 JDK 5 版本开始 Java 引入了注解支持,带来了极大的便利,Sprinng 也从 2.5 版本开始支持注解方式,使用注解方式我们只需加上相应的注解即可,不再需要去编写繁琐的 XML 配置文件,深受广大 Java 编程人员的喜爱。接下来一起看看如何实现 Spring 框架中最常用的两个注解(@Component、@Autowired),由于涉及到的内容比较多,会分为两篇文章进行介绍,本文先来介绍上半部分 — 如何实现 @Component 注解。
实现步骤拆分
本文实现的注解虽然说不用再配置 XML 文件,但是有点需要明确的是指定扫描 Bean 的包还使用 XML 文件的方式配置的,只是指定 Bean 不再使用配置文件的方式。有前面两篇文章的基础后实现 @Component 注解主要分成以下几个步骤:
- 读取 XML 配置文件,解析出需要扫描的包路径
- 对解析后的包路径进行扫描然后读取标有 @Component 注解的类,创建出对应的 BeanDefinition
- 根据创建出来的 BeanDefinition 创建对应的 Bean 实例
下面我们一步步来实现这几个步骤,最后去实现 @Component 注解:
读取 XML 配置文件,解析出需要扫描的包路径
假设有如下的 XML 配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.e3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/beans/spring-context.xsd">
<context:scann-package base-package="cn.mghio.service.version4,cn.mghio.dao.version4" />
</beans>
我们期望的结果是解析出来的扫描包路径为: cn.mghio.service.version4、cn.mghio.dao.version4 。如果有仔细有了前面的文章后,这个其实就比较简单了,只需要修改读取 XML 配置文件的类 XmlBeanDefinitionReader 中的 loadBeanDefinition(Resource resource) 方法,判断当前的 namespace 是否为 context 即可,修改该方法如下:
public void loadBeanDefinition(Resource resource) {
try (InputStream is = resource.getInputStream()) {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(is);
Element root = document.getRootElement(); // <beans>
Iterator<Element> iterator = root.elementIterator();
while (iterator.hasNext()) {
Element element = iterator.next();
String namespaceUri = element.getNamespaceURI();
if (this.isDefaultNamespace(namespaceUri)) { // beans
parseDefaultElement(element);
} else if (this.isContextNamespace(namespaceUri)) { // context
parseComponentElement(element);
}
}
} catch (DocumentException | IOException e) {
throw new BeanDefinitionException("IOException parsing XML document:" + resource, e);
}
}
private void parseComponentElement(Element element) {
// 1. 从 XML 配置文件中获取需要的扫描的包路径
String basePackages = element.attributeValue(BASE_PACKAGE_ATTRIBUTE);
// TODO 2. 对包路径进行扫描然后读取标有 @Component 注解的类,创建出对应的 BeanDefinition
...
}
private boolean isContextNamespace(String namespaceUri) {
// CONTEXT_NAMESPACE_URI = http://www.springframework.org/schema/context
return (StringUtils.hasLength(namespaceUri) && CONTEXT_NAMESPACE_URI.equals(namespaceUri));
}
private boolean isDefaultNamespace(String namespaceUri) {
// BEAN_NAMESPACE_URI = http://www.springframework.org/schema/beans
return (StringUtils.hasLength(namespaceUri) && BEAN_NAMESPACE_URI.equals(namespaceUri));
}
第一个步骤就已经完成了,其实相对来说还是比较简单的,接下来看看第二步要如何实现。
对解析后的包路径进行扫描然后读取标有 @Component 注解的类,创建出对应的 BeanDefinition
第二步是整个实现步骤中最为复杂和比较麻烦的一步,当面对一个任务比较复杂而且比较大时,可以对其进行适当的拆分为几个小步骤分别去实现,这里可以其再次拆分为如下几个小步骤:
- 扫描包路径下的字节码(.class )文件并转换为一个个 Resource 对象(其对于 Spring 框架来说是一种资源,在 Spring 中资源统一抽象为 Resource ,这里的字节码文件具体为 FileSystemResource)
- 读取转换好的 Resource 中的 @Component 注解
- 根据读取到的 @Component 注解信息创建出对应的 BeanDefintion
① 扫描包路径下的字节码(.class )文件并转换为一个个 Resource 对象(其对于 Spring 框架来说是一种资源,在 Spring 中资源统一抽象为 Resource ,这里的字节码文件具体为 FileSystemResource)
第一小步主要是实现从一个指定的包路径下获取该包路径下对应的字节码文件并将其转化为 Resource 对象,将该类命名为 PackageResourceLoader,其提供一个主要方法是 Resource[] getResources(String basePackage) 用来将一个给定的包路径下的字节码文件转换为 Resource 数组,实现如下:
public class PackageResourceLoader {
...
public Resource[] getResources(String basePackage) {
Assert.notNull(basePackage, "basePackage must not be null");
String location = ClassUtils.convertClassNameToResourcePath(basePackage);
ClassLoader classLoader = getClassLoader();
URL url = classLoader.getResource(location);
Assert.notNull(url, "URL must not be null");
File rootDir = new File(url.getFile());
Set<File> matchingFile = retrieveMatchingFiles(rootDir);
Resource[] result = new Resource[matchingFile.size()];
int i = 0;
for (File file : matchingFile) {
result[i++] = new FileSystemResource(file);
}
return result;
}
private Set<File> retrieveMatchingFiles(File rootDir) {
if (!rootDir.exists() || !rootDir.isDirectory() || !rootDir.canRead()) {
return Collections.emptySet();
}
Set<File> result = new LinkedHashSet<>(8);
doRetrieveMatchingFiles(rootDir, result);
return result;
}
private void doRetrieveMatchingFiles(File dir, Set<File> result) {
File[] dirContents = dir.listFiles();
if (dirContents == null) {
return;
}
for (File content : dirContents) {
if (!content.isDirectory()) {
result.add(content);
continue;
}
if (content.canRead()) {
doRetrieveMatchingFiles(content, result);
}
}
}
...
}
上面的第一小步至此已经完成了,下面继续看第二小步。
② 读取转换好的 Resource 中的 @Component 注解
要实现第二小步(读取转换好的 Resource 中的 @Component 注解),首先面临的第一个问题是:如何读取字节码?,熟悉字节结构的朋友可以字节解析读取,但是难度相对比较大,而且也比较容易出错,这里读取字节码的操作我们使用著名的字节码操作框架 ASM 来完成底层的操作,官网对其的描述入下:
ASM is an all purpose Java bytecode manipulation and analysis framework.
其描述就是:ASM 是一个通用的 Java 字节码操作和分析框架。其实不管是在工作或者日常学习中,我们对于一些比较基础的库和框架,如果有成熟的开源框架使用其实没有从零开发(当然,本身就是想要研究其源码的除外),这样可以减少不必要的开发成本和精力。ASM 基于 Visitor 模式可以方便的读取和修改字节码,目前我们只需要使用其读取字节码的功能。
ASM 框架中分别提供了 ClassVisitor 和 AnnotationVisitor 两个抽象类来访问类和注解的字节码,我们可以使用这两个类来获取类和注解的相关信息。很明显我们需要继承这两个类然后覆盖其中的方法增加自己的逻辑去完成信息的获取,要如何去描述一个类呢?其实比较简单无非就是 类名、是否是接口、是否是抽象类、父类的类名、实现的接口列表 等这几项。
但是一个注解要如何去描述它呢?注解其实我们主要关注注解的类型和其所包含的属性,类型就是一个 包名 + 注解名 的字符串表达式,而属性本质上是一种 K-V 的映射,值类型可能为 数字、布尔、字符串 以及 数组 等,为了方便使用可以继承自 LinkedHashMap<String, Object> 封装一些方便的获取属性值的方法,读取注解部分的相关类图设计如下:
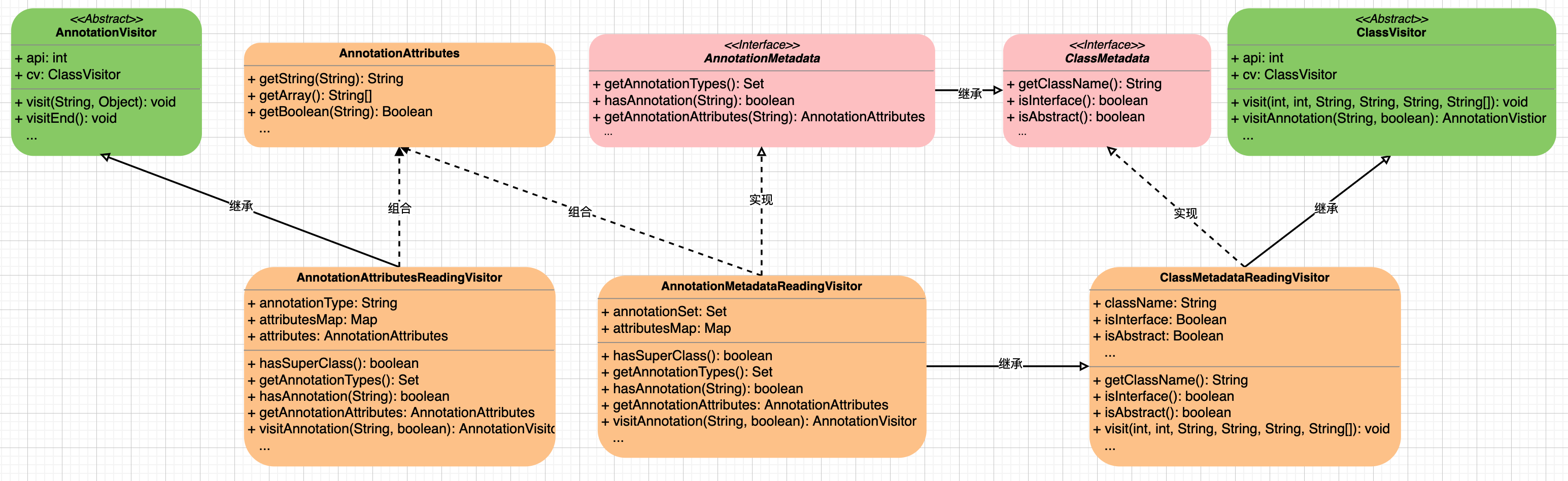
其中绿色背景的 ClassVisitor 和 AnnotationVisitor 是 ASM 框架提供的类,ClassMetadata 是类相关的元数据接口,AnnotationMetadata 是注解相关的元数据接口继承自 ClassMetadata,AnnotationAttributes 是对注解属性的描述,继承自 LinkedHashMap 主要是封装了获取指定类型 value 的方法,还有三个自定义的 Visitor 类是本次实现的关键,第一个类 ClassMetadataReadingVisitor 实现了 ClassVisitor 抽象类,用来获取字节码文件中类相关属性的提取,其代码实现如下所示:
/**
* @author mghio
* @since 2021-02-14
*/
public class ClassMetadataReadingVisitor extends ClassVisitor implements ClassMetadata {
private String className;
private Boolean isInterface;
private Boolean isAbstract;
...
public ClassMetadataReadingVisitor() {
super(Opcodes.ASM7);
}
@Override
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
this.className = ClassUtils.convertResourcePathToClassName(name);
this.isInterface = ((access & Opcodes.ACC_INTERFACE) != 0);
this.isAbstract = ((access & Opcodes.ACC_ABSTRACT) != 0);
...
}
@Override
public String getClassName() {
return this.className;
}
@Override
public boolean isInterface() {
return this.isInterface;
}
@Override
public boolean isAbstract() {
return this.isAbstract;
}
...
}
第二个类 AnnotationMetadataReadingVisitor 用来获取注解的类型,然后通过构造方法传给 AnnotataionAttributesVisitor,为获取注解属性做准备,代码实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class AnnotationMetadataReadingVisitor extends ClassMetadataReadingVisitor implements AnnotationMetadata {
private final Set<String> annotationSet = new LinkedHashSet<>(8);
private final Map<String, AnnotationAttributes> attributesMap = new LinkedHashMap<>(8);
@Override
public AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
String className = Type.getType(descriptor).getClassName();
this.annotationSet.add(className);
return new AnnotationAttributesReadingVisitor(className, this.attributesMap);
}
@Override
public boolean hasSuperClass() {
return StringUtils.hasText(getSuperClassName());
}
@Override
public Set<String> getAnnotationTypes() {
return this.annotationSet;
}
@Override
public boolean hasAnnotation(String annotationType) {
return this.annotationSet.contains(annotationType);
}
@Override
public AnnotationAttributes getAnnotationAttributes(String annotationType) {
return this.attributesMap.get(annotationType);
}
}
第三个类 AnnotationAttributesReadingVisitor 根据类 AnnotationMetadataReadingVisitor 传入的注解类型和属性集合,获取并填充注解对应的属性,代码实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class AnnotationAttributesReadingVisitor extends AnnotationVisitor {
private final String annotationType;
private final Map<String, AnnotationAttributes> attributesMap;
private AnnotationAttributes attributes = new AnnotationAttributes();
public AnnotationAttributesReadingVisitor(String annotationType,
Map<String, AnnotationAttributes> attributesMap) {
super(Opcodes.ASM7);
this.annotationType = annotationType;
this.attributesMap = attributesMap;
}
@Override
public void visit(String attributeName, Object attributeValue) {
this.attributes.put(attributeName, attributeValue);
}
@Override
public void visitEnd() {
this.attributesMap.put(this.annotationType, this.attributes);
}
}
该类做的使用比较简单,就是当每访问当前注解的一个属性时,将其保存下来,最后当访问完成时以 K-V (key 为注解类型全名称,value 为注解对应的属性集合)的形式存入到 Map 中,比如,当我访问如下的类时:
/**
* @author mghio
* @since 2021-02-14
*/
@Component(value = "orderService")
public class OrderService {
...
}
此时 AnnotationAttributesReadingVisitor 类的 visit(String, Object) 方法的参数即为当前注解的属性和属性的取值如下:
至此我们已经完成了第二步中的前半部分的扫描指定包路径下的类并读取注解,虽然功能已经实现了,但是对应使用者来说还是不够友好,还需要关心一大堆相关的 Visitor 类,这里能不能再做一些封装呢?此时相信爱思考的你脑海里应该已经浮现了一句计算机科学界的名言:
计算机科学的任何一个问题,都可以通过增加一个中间层来解决。
仔细观察可以发现,以上读取类和注解相关信息的本质是元数据的读取,上文提到的 Resource 其实也是一中元数据,提供信息读取来源,将该接口命名为 MetadataReader,如下所示:
/**
* @author mghio
* @since 2021-02-14
*/
public interface MetadataReader {
Resource getResource();
ClassMetadata getClassMetadata();
AnnotationMetadata getAnnotationMetadata();
}
还需要提供该接口的实现,我们期望的最终结果是只要面向 MetadataReader 接口编程即可,只要传入 Resource 就可以获取 ClassMetadata 和 AnnotationMetadata 等信息,无需关心那些 visitor,将该实现类命名为 SimpleMetadataReader,其代码实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class SimpleMetadataReader implements MetadataReader {
private final Resource resource;
private final ClassMetadata classMetadata;
private final AnnotationMetadata annotationMetadata;
public SimpleMetadataReader(Resource resource) throws IOException {
ClassReader classReader;
try (InputStream is = new BufferedInputStream(resource.getInputStream())) {
classReader = new ClassReader(is);
}
AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor();
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
this.resource = resource;
this.classMetadata = visitor;
this.annotationMetadata = visitor;
}
@Override
public Resource getResource() {
return this.resource;
}
@Override
public ClassMetadata getClassMetadata() {
return this.classMetadata;
}
@Override
public AnnotationMetadata getAnnotationMetadata() {
return this.annotationMetadata;
}
}
在使用时只需要在构造 SimpleMetadataReader 传入对应的 Resource 即可,如下所示:
到这里第二小步从字节码中读取注解的步骤已经完成了。
③ 根据读取到的 @Component 注解信息创建出对应的 BeanDefintion
为了使之前定义好的 BeanDefinition 结构保持纯粹不被破坏,这里我们再增加一个针对注解的 AnnotatedBeanDefinition 接口继承自 BeanDefinition 接口,接口比较简单只有一个获取注解元数据的方法,定义如下所示:
/**
* @author mghio
* @since 2021-02-14
*/
public interface AnnotatedBeanDefinition extends BeanDefinition {
AnnotationMetadata getMetadata();
}
同时增加一个该接口的实现类,表示从扫描注解生成的 BeanDefinition,将其命名为 ScannedGenericBeanDefinition,代码实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class ScannedGenericBeanDefinition extends GenericBeanDefinition implements AnnotatedBeanDefinition {
private AnnotationMetadata metadata;
public ScannedGenericBeanDefinition(AnnotationMetadata metadata) {
super();
this.metadata = metadata;
setBeanClassName(this.metadata.getClassName());
}
@Override
public AnnotationMetadata getMetadata() {
return this.metadata;
}
}
还有一个问题就是使用注解的方式时该如何生成 Bean 的名字,这里我们采用和 Spring 一样的策略,当在注解指定 Bean 的名字时使用指定的值为 Bean 的名字,否则使用类名的首字母小写为生成 Bean 的名字, 很明显这只是其中的一种默认实现策略,因此需要提供一个生成 Baen 名称的接口供后续灵活替换生成策略,接口命名为 BeanNameGenerator ,接口只有一个生成 Bean 名称的方法,其定义如下:
/**
* @author mghio
* @since 2021-02-14
*/
public interface BeanNameGenerator {
String generateBeanName(BeanDefinition bd, BeanDefinitionRegistry registry);
}
其默认的生成策略实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class AnnotationBeanNameGenerator implements BeanNameGenerator {
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
return beanName;
}
}
return buildDefaultBeanName(definition);
}
private String buildDefaultBeanName(BeanDefinition definition) {
String shortClassName = ClassUtils.getShortName(definition.getBeanClassName());
return Introspector.decapitalize(shortClassName);
}
private String determineBeanNameFromAnnotation(AnnotatedBeanDefinition definition) {
AnnotationMetadata metadata = definition.getMetadata();
Set<String> types = metadata.getAnnotationTypes();
String beanName = null;
for (String type : types) {
AnnotationAttributes attributes = metadata.getAnnotationAttributes(type);
if (attributes.get("value") != null) {
Object value = attributes.get("value");
if (value instanceof String) {
String stringVal = (String) value;
if (StringUtils.hasLength(stringVal)) {
beanName = stringVal;
}
}
}
}
return beanName;
}
}
最后我们再定义一个扫描器类组合以上的功能提供一个将包路径下的类读取并转换为对应的 BeanDefinition 方法,将该类命名为 ClassPathBeanDefinitionScanner,其代码实现如下:
/**
* @author mghio
* @since 2021-02-14
*/
public class ClassPathBeanDefinitionScanner {
public static final String SEMICOLON_SEPARATOR = ",";
private final BeanDefinitionRegistry registry;
private final PackageResourceLoader resourceLoader = new PackageResourceLoader();
private final BeanNameGenerator beanNameGenerator = new AnnotationBeanNameGenerator();
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this.registry = registry;
}
public Set<BeanDefinition> doScanAndRegistry(String packageToScan) {
String[] basePackages = StringUtils.tokenizeToStringArray(packageToScan, SEMICOLON_SEPARATOR);
Set<BeanDefinition> beanDefinitions = new HashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
beanDefinitions.add(candidate);
registry.registerBeanDefinition(candidate.getId(), candidate);
}
}
return beanDefinitions;
}
private Set<BeanDefinition> findCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new HashSet<>();
try {
Resource[] resources = this.resourceLoader.getResources(basePackage);
for (Resource resource : resources) {
MetadataReader metadataReader = new SimpleMetadataReader(resource);
if (metadataReader.getAnnotationMetadata().hasAnnotation(Component.class.getName())) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader.getAnnotationMetadata());
String beanName = this.beanNameGenerator.generateBeanName(sbd, registry);
sbd.setId(beanName);
candidates.add(sbd);
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
}
到这里就已经把读取到的 @Component 注解信息转换为 BeanDefinition 了。
根据创建出来的 BeanDefinition 创建对应的 Bean 实例
这一步其实并不需要再修改创建 Bean 的代码了,创建的逻辑都是一样的,只需要将之前读取 XML 配置文件那里使用上文提到的扫描器 ClassPathBeanDefinitionScanner 扫描并注册到 BeanFactory 中即可,读取配置文件的 XmlBeanDefinitionReader 类的读取解析配置文件的方法修改如下:
public void loadBeanDefinition(Resource resource) {
try (InputStream is = resource.getInputStream()) {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(is);
Element root = document.getRootElement(); // <beans>
Iterator<Element> iterator = root.elementIterator();
while (iterator.hasNext()) {
Element element = iterator.next();
String namespaceUri = element.getNamespaceURI();
if (this.isDefaultNamespace(namespaceUri)) {
parseDefaultElement(element);
} else if (this.isContextNamespace(namespaceUri)) {
parseComponentElement(element);
}
}
} catch (DocumentException | IOException e) {
throw new BeanDefinitionException("IOException parsing XML document:" + resource, e);
}
}
private void parseComponentElement(Element element) {
String basePackages = element.attributeValue(BASE_PACKAGE_ATTRIBUTE);
// 读取指定包路径下的类转换为 BeanDefinition 并注册到 BeanFactory 中
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry);
scanner.doScanAndRegistry(basePackages);
}
到这里实现 @Component 注解的主要流程已经介绍完毕,完整代码已上传至仓库 GitHub 。
总结
本文主要介绍了实现 @Component 注解的主要流程,以上只是实现的最简单的功能,但是基本原理都是类似的,有问题欢迎留言讨论。下篇预告:如何实现 @Autowried 注解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号