
OpenResty 在马蜂窝广告监测中的应用
马蜂窝技术原创内容,更多干货请订阅公众号:mfwtech
广告是互联网变现的重要手段之一。
以马蜂窝旅游 App 为例,当用户打开我们的应用时,有可能会在首屏或是信息流、商品列表中看到推送的广告。如果刚好对广告内容感兴趣,用户就可能会点击广告了解更多信息,进而完成这条广告希望完成的后续操作,如下载广告推荐的 App 等。
广告监测平台的任务就是持续、准确地收集用户在浏览和点击广告这些事件中携带的信息,包括来源、时间、设备、位置信息等,并进行处理和分析,来为广告主提供付费结算以及评估广告投放效果的依据。
因此,一个可靠、准确的监测服务非常重要。为了更好地保障平台和广告主双方的权益,以及为提升马蜂窝旅游网的广告服务效果提供支撑,我们也在不断地探索适合的解决方案,加强广告监测服务的能力。
Part.1 初期形态
初期我们的广告监测并没有形成完整的服务对外开放,因此实现方式及提供的能力也比较简单,主要分为两部分:一是基于客户端打点,针对事件进行上报;另一部分是针对曝光、点击链接做转码存档,当请求到来后解析跳转。
但是很快,这种方式的弊端就暴露出来,主要体现在以下几个方面:
-
收数的准确性:数据转发需要访问中间件才能完成,增加了多段丢包的机率。在和第三方监测服务进行对比验证时,Gap 差异较大;
-
数据的处理能力:收集的数据来自于各个业务系统,缺乏统一的数据标准,数据的多种属性导致解析起来很复杂,增加了综合数据二次利用的难度;
-
突发流量:当流量瞬时升高,就会遇到 Redis 内存消耗高、服务掉线频繁的问题;
-
部署复杂:随着不同设备、不同广告位的变更,打点趋于复杂,甚至可能会覆盖不到;
-
开发效率:初期的广告监测功能单一,例如对实时性条件的计算查询等都需要额外开发,非常影响效率。
Part.2 基于 OpenResty 的架构实现
在这样的背景下,我们打造了马蜂窝广告数据监测平台 ADMonitor,希望逐步将其实现成一个稳定、可靠、高可用的广告监测服务。
2.1 设计思路
为了解决老系统中的各种问题,我们引入了新的监测流程。主体流程设计为:
-
在新的监测服务 (ADMonitor) 上生成关于每种广告独有的监测链接,同时附在原有的客户链接上;
-
所有从服务端下发的曝光链接和点击链接并行依赖 ADMonitor 提供的服务;
-
客户端针对曝光行为进行并行请求,点击行为会优先跳转到 ADMonitor,由 ADMonitor 来做二段跳转。
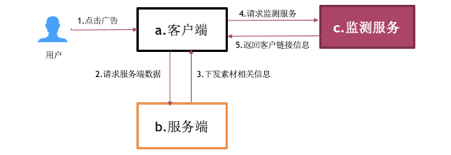
通过以上方式,使监测服务完全依赖 ADMonitor,极大地增加了监测部署的灵活性及整体服务的性能;同时为了进一步验证数据的准确性,我们保留了打点的方式进行对比。
2.2 技术选型
为了使上述流程落地,广告监测的流量入口必须要具备高可用、高并发的能力,尽量减少非必要的网络请求。考虑到内部多个系统都需要流量,为了降低系统对接的人力成本,以及避免由于系统迭代对线上服务造成干扰,我们首先要做的就是把流量网关独立出来。
关于 C10K 编程相关的技术业内有很多解决方案,比如 OpenResty、JavaNetty、Golang、NodeJS 等。它们共同的特点是使用一个进程或线程可以同时处理多个请求,基于线程池、基于多协程、基于事件驱动+回调、实现 I/O 非阻塞。
我们最终选择基于 OpenResty 构建广告监测平台,主要是对以下方面的考虑:
第一,OpenResty 工作在网络的 7 层之上,依托于比 HAProxy 更为强大和灵活的正则规则,可以针对 HTTP 应用的域名、目录结构做一些分流、转发的策略,既能做负载又能做反向代理;
第二,OpenResty 具有 Lua协程+Nginx 事件驱动的「事件循环回调机制」,也就是 Openresty 的核心 Cosoket,对远程后端诸如 MySQL、Memcached、Redis 等都可以实现同步写代码的方式实现非阻塞 I/O;
第三,依托于 LuaJit,即时编译器会将频繁执行的代码编译成机器码缓存起来,当下次调用时将直接执行机器码,相比原生逐条执行虚拟机指令效率更高,而对于那些只执行一次的代码仍然可以逐条执行。
2.3 架构实现
整体方案依托于 OpenResty 的处理机制,在服务器内部进行定制开发,主要划分为数据收集、数据处理与数据归档三大部分,实现异步拆分请求与 I/O 通信。整体结构示意图如下:
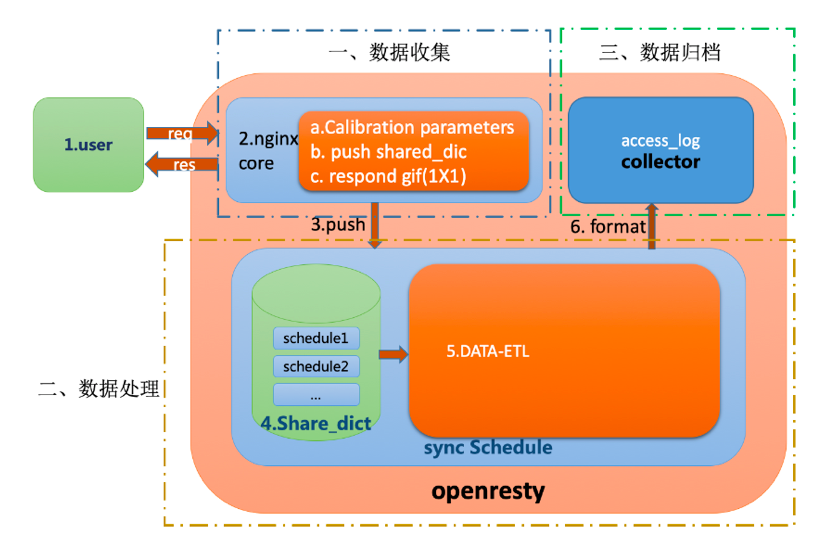
我们将多 Woker 日志信息以双端队列的方式存入 Master 共享内存,开启 Worker 的 Timer 毫秒级定时器,离线解析流量。
2.3.1 数据收集
收集部分也是主体承受流量压力最大的部分。我们使用 Lua 来做整体检参、过滤与推送。由于在我们的场景中,数据收集部分不需要考虑时序或对数据进行聚合处理,因此核心的推送介质选择 Lua 共享内存即可,以 I/O 请求来代替访问其他中间件所需要的网络服务,从而减少网络请求,满足即时性的要求,如下所示:
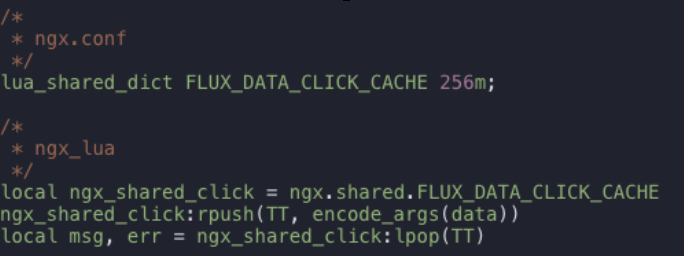
下面结合 OpenResty 配置,介绍一些我们对服务器节点进行的优化:
-
设置 lua 缓存-lua_code_cache:
(1)开启后会将 Lua 文件缓存到内存中,加速访问,但修改 Lua 代码需要 reload
(2)尽量避免全局变量的产生
(3)关闭后会依赖 Woker 进程中生成自己新的 LVM
-
设置 Resolver 对于网络请求、好的 DNS 节点或者自建的 DNS 节点在网络请求很高的情况下会很有帮助:
(1)增加公司的 DNS 服务节点与补偿的公网节点
(2)使用 shared 来减少 Worker 查询次数
-
设置 epoll (multi_accept/accept_mutex/worker_connections):
(1)设置 I/O 模型、防止惊群
(2)避免服务节点浪费资源做无用处理而影响整体流转等
-
设置 keepalive:
(1)包含链接时长与请求上限等
配置优化一方面是要符合当前请求场景,另一方面要配合 Lua 发挥更好的性能。设置 Nginx 服务器参数基础是根据不同操作系统环境进行调优,比如 Linux 中一切皆文件、调整文件打开数、设置 TCP Buckets、设置 TIME_WAIT 等。
2.3.2 数据处理
这部分流程是将收集到的数据先通过 ETL,之后创建内部的日志 location,结合 Lua 自定义 log_format,利用 Nginx 子请求特性离线完成数据落盘,同时保证数据延迟时长在毫秒级。
对被解析的数据处理要进行两部分工作,一部分是 ETL,另一部分是 Count。
(1)ETL
![]()
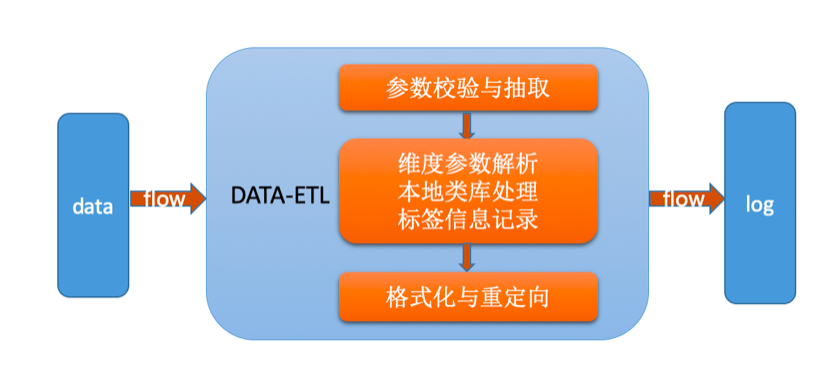
主要流程:
-
日志经过统一格式化之后,抽取包含实际意义参数部分进行数据解析
-
将抽取后的数据进行过滤,针对整体字符集、IP、设备、UA、相关标签信息等进行处理
-
将转化后的数据进行重加载与日志重定向
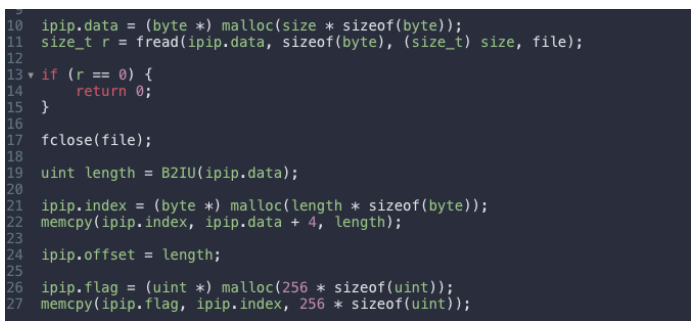
【例】Lua 利用 FFI 通过 IP 库解析 "ip!"用 C 把 IP 库拷贝到内存中,Lua 进行毫秒级查询:
(2)Count
对于广告数据来说,绝大部分业务需求都来自于数据统计,这里直接使用 Redis+FluxDB 存储数据,以有下几个关键的技术点:
-
RDS 结合 Lua 设置链接时间,配置链接池来增加链接复用
-
RDS 集群服务实现去中心化,分散节点压力,增加 AOF与延时入库保证可靠
-
FluxDB 保证数据日志时序性可查,聚合统计与实时报表表现较优
2.3.3 数据归档
数据归档需要对全量数据入表,这个过程中会涉及到对一些无效数据进行过滤处理。这里整体接入了公司的大数据体系,流程上分为在线处理和离线处理两部分,能够对数据回溯。使用的解决方案是在线 Flink、离线 Hive,其中需要关注:
-
ES 的索引与数据定期维护
-
Kafka 的消费情况
-
对于发生故障的机器使用自动脚本重启与报警等
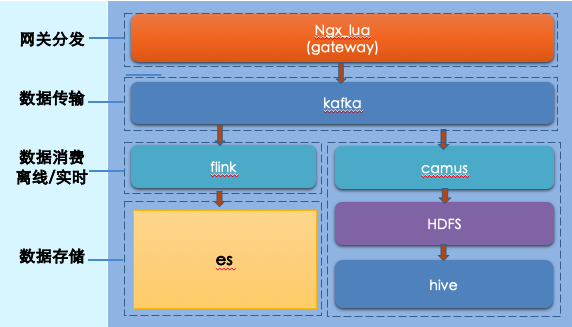
实时数据源:数据采集服务→ Filebeat → Kafka → Flink → ES
离线数据源:HDFS → Spark → Hive → ES
数据解析后的再利用:
解析后的数据已经拥有了重复利用的价值。我们的主要应用场景有两大块。
一是 OLAP,针对业务场景与数据表现分析访问广告的人群属性标签变化情况,包含地域,设备,人群分布占比与增长情况等;同时,针对未来人群库存占比进行预测,最后影响到实际投放上。
另一部分是在 OLTP,主要场景为:
-
判定用户是否属于广告受众区域
-
解析 UA 信息,获取终端信息,判断是否属于为低级爬虫流量
-
设备号打标,从 Redis 获取实时用户画像,进行实时标记等
2.4 OpenResty 其他应用场景
OpenResty 在我们的广告数据监测服务全流程中均发挥着重要作用:
-
init_worker_by_lua阶段:负责服务配置业务
-
access_by_lua阶段:负责CC防护、权限准入、流量时序监控等业务
-
content_by_lua阶段:负责实现限速器、分流器、WebAPI、流量采集等业务
-
log_by_lua阶段:负责日志落盘等业务
重点解读以下两个应用的实现方式。
2.4.1 分流器业务
NodeJS 服务向 OpenResty 网关上报当前服务器 CPU 和内存使用情况;Lua 脚本调用 RedisCluster 获取时间窗口内 NodeJS 集群使用情况后,计算出负载较高的 NodeJS 机器;OpenResty 对 NodeJS 集群流量进行熔断、降级、限流等逻辑处理;将监控数据同步 InfluxDB,进行时序监测。
2.4.2 小型 WEB 防火墙
使用第三方开源 lua_resty_waf 类库实现,支持 IP 白名单和黑名单、URL 白名单、UA 过滤、CC 攻击防护功能。我们在此基础上增加了 WAF 对 InfluxDB 的支持,进行时序监控和服务预警。
2.5 小结
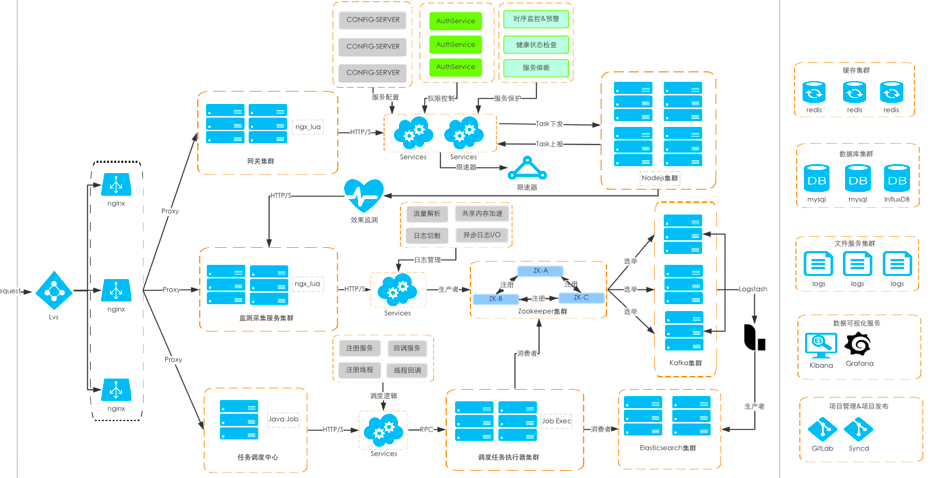
总结来看,基于 OpenResty 实现的广告监测服务 ADMonitor 具备以下特点:
-
高可用:依赖 OpenResty 做 Gateway, 多节点做 HA
-
立即返回:解析数据后利用 I/O 请求做数据异步处理,避免非必要的网络通信
-
解耦功能模块:对请求、数据处理和转发实现解耦,缩减单请求串行处理耗时
-
服务保障: 针对重要的数据结果利用第三方组件单独存储
完整的技术方案示意如下:
Part.3 总结
目前,ADMonitor 已经接入公司的广告服务体系,总体运行情况比较理想:
1. 性能效果
-
达到了高吞吐、低延迟的标准
-
转发成功率高,曝光计数成功率>99.9%,点击成功率>99.8%
2. 业务效果
-
与主流第三方监测机构进行数据对比:曝光数据 GAP < 1%,点击数据GAP < 3%
-
可提供实时检索与聚合服务
未来我们将结合业务发展和服务场景不断完善,期待和大家多多交流。
本文作者:江明辉,马蜂窝旅游网品牌广告数据服务端组研发工程师。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号