k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
来源:https://blog.csdn.net/sinat_26917383/article/details/70240628
之前一直用R,现在开始学python之后就来尝试用Python来实现Kmeans。
之前用R来实现kmeans的博客:笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧)
聚类分析在客户细分中极为重要。有三类比较常见的聚类模型,K-mean聚类、层次(系统)聚类、最大期望EM算法。在聚类模型建立过程中,一个比较关键的问题是如何评价聚类结果如何,会用一些指标来评价。
.一、scikit-learn中的Kmeans介绍
scikit-learn 是一个基于Python的Machine Learning模块,里面给出了很多Machine
Learning相关的算法实现,其中就包括K-Means算法。官网scikit-learn案例地址:http://scikit-learn.org/stable/modules/clustering.html#k-means
部分来自:scikit-learn 源码解读之Kmeans——简单算法复杂的说各个聚类的性能对比:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1、相关理论
- (1)中心点的选择
k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法:k-means中心点
选择彼此距离尽可能远的那些点作为中心点;
先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
多次随机选择中心点训练k-means,选择效果最好的聚类结果
- (2)k值的选取
k-means的误差函数有一个很大缺陷,就是随着簇的个数增加,误差函数趋近于0,最极端的情况是每个记录各为一个单独的簇,此时数据记录的误差为0,但是这样聚类结果并不是我们想要的,可以引入结构风险对模型的复杂度进行惩罚:
λλ是平衡训练误差与簇的个数的参数,但是现在的问题又变成了如何选取λλ了,有研究[参考文献1]指出,在数据集满足高斯分布时,λ=2mλ=2m,其中m是向量的维度。
另一种方法是按递增的顺序尝试不同的k值,同时画出其对应的误差值,通过寻求拐点来找到一个较好的k值,详情见下面的文本聚类的例子。
2、主函数KMeans
参考博客:python之sklearn学习笔记
来看看主函数KMeans:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
参数的意义:
- n_clusters:簇的个数,即你想聚成几类
- init: 初始簇中心的获取方法
- n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。
- max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
- tol: 容忍度,即kmeans运行准则收敛的条件
- precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的
- verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
- random_state: 随机生成簇中心的状态条件。
- copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
- n_jobs: 并行设置
- algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
3、简单案例一
参考博客:python之sklearn学习笔记
本案例说明了,KMeans分析的一些类如何调取与什么意义。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
estimator初始化Kmeans聚类;estimator.fit聚类内容拟合;
estimator.label_聚类标签,这是一种方式,还有一种是predict;estimator.cluster_centers_聚类中心均值向量矩阵
estimator.inertia_代表聚类中心均值向量的总和4、案例二
案例来源于:使用scikit-learn进行KMeans文本聚类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
km_cluster是KMeans初始化,其中用init的初始值选择算法用’k-means++’;
km_cluster.fit_predict相当于两个动作的合并:km_cluster.fit(data)+km_cluster.predict(data),可以一次性得到聚类预测之后的标签,免去了中间过程。
- n_clusters: 指定K的值
- max_iter: 对于单次初始值计算的最大迭代次数
- n_init: 重新选择初始值的次数
- init: 制定初始值选择的算法
- n_jobs: 进程个数,为-1的时候是指默认跑满CPU
- 注意,这个对于单个初始值的计算始终只会使用单进程计算,
- 并行计算只是针对与不同初始值的计算。比如n_init=10,n_jobs=40,
- 服务器上面有20个CPU可以开40个进程,最终只会开10个进程
其中:
- 1
- 2
这是两种聚类结果标签输出的方式,结果貌似都一样。都需要先km_cluster.fit(data),然后再调用。
5、案例四——Kmeans的后续分析
Kmeans算法之后的一些分析,参考来源:用Python实现文档聚类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分为五类,同时用%time来测定运行时间,把分类标签labels格式变为list。
- (1)模型保存与载入
- 1
- 2
- 3
- 4
- 5
- 6
- (2)聚类类别统计
- 1
- 2
- (3)质心均值向量计算组内平方和
选择更靠近质心的点,其中 km.cluster_centers_代表着一个 (聚类个数*维度数),也就是不同聚类、不同维度的均值。
该指标可以知道:
一个类别之中的,那些点更靠近质心;
整个类别组内平方和。类别内的组内平方和要参考以下公式:
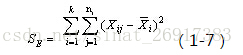
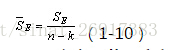
通过公式可以看出:
质心均值向量每一行数值-每一行均值(相当于均值的均值)
注意是平方。其中,n代表样本量,k是聚类数量(譬如聚类5)
其中,整篇的组内平方和可以通过来获得总量:
- 1
.
公众号“素质云笔记”定期更新博客内容: 二、大数据量下的Mini-Batch-KMeans算法
部分内容参考来源:scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
当数据量很大的时候,Kmeans 显然还是很弱的,会比较耗费内存速度也会收到很大影响。scikit-learn 提供了MiniBatchKMeans算法,大致思想就是对数据进行抽样,每次不使用所有的数据来计算,这就会导致准确率的损失。MiniBatchKmeans 继承自Kmeans 因为MiniBathcKmeans 本质上还利用了Kmeans 的思想.从构造方法和文档大致能看到这些参数的含义,了解了这些参数会对使用的时候有很大的帮助。batch_size 是每次选取的用于计算的数据的样本量,默认为100.
Mini Batch K-Means算法是K-Means算法的变种,采用小批量的数据子集减小计算时间,同时仍试图优化目标函数,这里所谓的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,与其他算法相比,减少了k-均值的收敛时间,小批量k-均值产生的结果,一般只略差于标准算法。
该算法的迭代步骤有两步:
1:从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
2:更新质心
与K均值算法相比,数据的更新是在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算
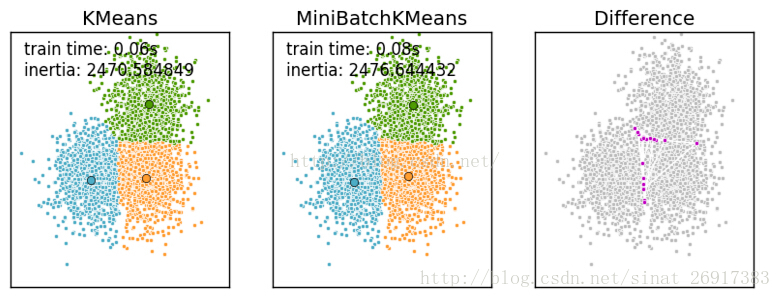
Mini Batch K-Means比K-Means有更快的 收敛速度,但同时也降低了聚类的效果,但是在实际项目中却表现得不明显
一张k-means和mini batch k-means的实际效果对比图来看一下 MiniBatchKMeans的python实现:
官网链接、案例一则链接主函数 :
- 1
- 2
相关参数解释(来自博客:用scikit-learn学习K-Means聚类):
- random_state: 随机生成簇中心的状态条件,譬如设置random_state = 9
- tol: 容忍度,即kmeans运行准则收敛的条件
max_no_improvement:即连续多少个Mini Batch没有改善聚类效果的话,就停止算法,
和reassignment_ratio, max_iter一样是为了控制算法运行时间的。默认是10.一般用默认值就足够了。batch_size:即用来跑Mini Batch
KMeans算法的采样集的大小,默认是100.如果发现数据集的类别较多或者噪音点较多,需要增加这个值以达到较好的聚类效果。- reassignment_ratio:
某个类别质心被重新赋值的最大次数比例,这个和max_iter一样是为了控制算法运行时间的。这个比例是占样本总数的比例,
乘以样本总数就得到了每个类别质心可以重新赋值的次数。如果取值较高的话算法收敛时间可能会增加,尤其是那些暂时拥有样本数较少的质心。
默认是0.01。如果数据量不是超大的话,比如1w以下,建议使用默认值。 如果数据量超过1w,类别又比较多,可能需要适当减少这个比例值。
具体要根据训练集来决定。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
内容跟kmeans很像,只是一般多加一个参数,batch_size。
.
三、sklearn中的cluster进行kmeans聚类
参考博客:python之sklearn学习笔记
- 1
- 2
- 3
- 4
- 5
公众号“素质云笔记”定期更新博客内容: .
延伸一:数据如何做标准化
- 1
.
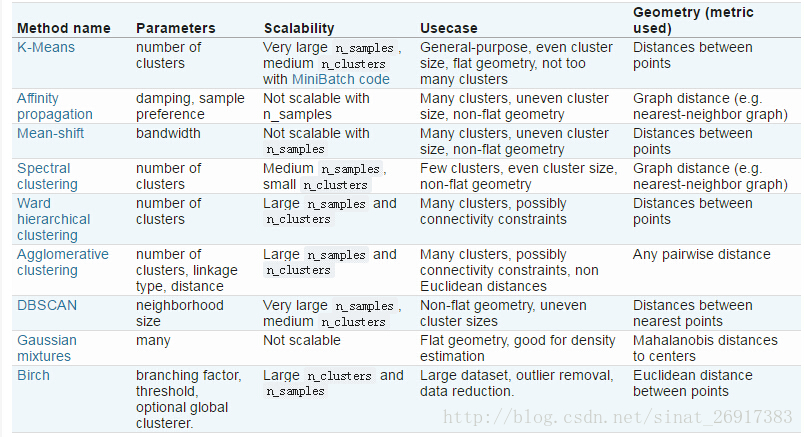
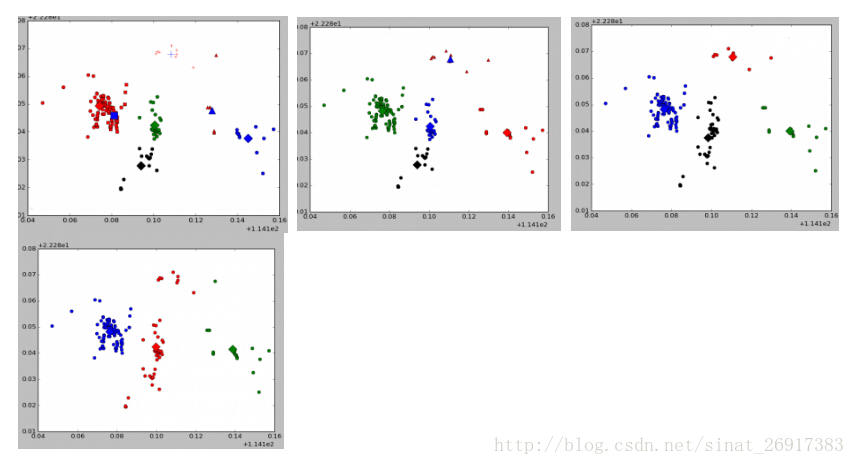
延伸二:Kmeans可视化案例
来源于博客:使用python-sklearn-机器学习框架针对140W个点进行kmeans基于密度聚类划分
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
延伸三:模型保存
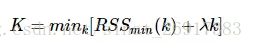


 浙公网安备 33010602011771号
浙公网安备 33010602011771号