GBDT的基本原理
这里以二元分类为例子,给出最基本原理的解释
GBDT 是多棵树的输出预测值的累加
GBDT的树都是 回归树 而不是分类树
- 分类树

分裂的时候选取使得误差下降最多的分裂
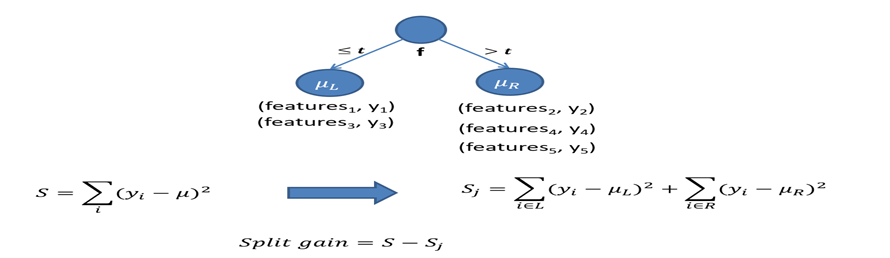
计算的技巧

最终分裂收益按照下面的方式计算,注意圆圈内的部分是固定值
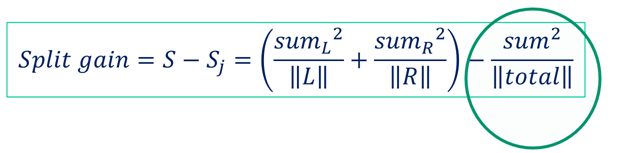
- GBDT 二分类
GBDT在实现中可以完全复用上面的计算方法框架,只是我们的优化的目标函数不同。
这里使用的是 指数误差函数,不管是预测正确还是错误 误差值都存在,但是正确的预测 会使得误差值小于错误的预测 参考
AdaBoost and the Super Bowl of Classifiers
A Tutorial Introduction to Adaptive Boosting

关于常用误差函数 参考 http://www.cnblogs.com/rocketfan/p/4083821.html
参考 Greedy Functon Approximation:A Gradient Boosting Machine
4.4节关于二分类情况误差函数的设计

这里其实和上面给出的一样,只是增加了 log(1 +, 另外多了一个2,2yF), 参考前面的LossFunction http://www.cnblogs.com/rocketfan/p/4083821.html
的推导,其实这个应该算作LogLoss或者说是logistic regression, cross entropy error,也就是从probablity出发的logloss推导到output F(x)的表示就是上面的
式子,而它看上去刚好就是一个指数误差函数。
严格意义上说是LogLoss不是指数误差 不过LogLoss和指数误差看上去比较相似。
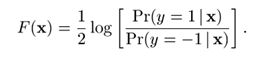
这个F值其实就是逻辑回归的思路,类似 语音语言处理一书27页解释,线性加权的值(output)用来预测 p(true)和p(false)的比例的log值(回归值是实数范围取值不适合预测0-1,做了一个转换),越是接近true,那么F(x)越接近+无穷(对应最大可能性判断true), p(false)越大 那么越接近-无穷(对应最大可能性判断false)
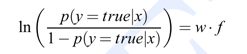
F(X) 对应 feature X 当前的回归预测值也就是多棵树经过决策到达叶子节点的输出值output(x)的累加值。N个样本则F(x)N个维度,当开始没有分裂的时候所有样本在一个节点则所有F(x)对应一个相同的值,分裂一次后两个叶子节点则F(X)对应可能到不同的叶子节点从而可能有两个不同的值。
对误差函数计算关于F的梯度,误差函数是

变量是F(x)
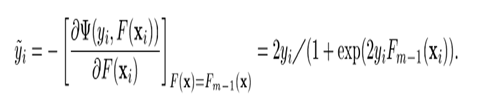
考虑learning_rate之后是 (@TODO)
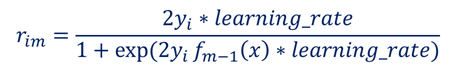
F(X) 对应 叶子节点中一个样本对应它的feature X 当前的预测值
参考 机器学习概率角度 一书的16章

我们的分裂目标从上面回归树基本算法中的希望逼近y 变成了 逼近梯度值 r_im,
也就是说当前树是预测负梯度值的。
F_m(x) = F_m-1(x) + learning_rate*(当前树的预测值(也就是预测负梯度..)) //@TODO check
再对比下ng课件最简单的梯度下降 针对regression的例子
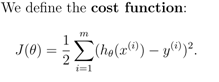
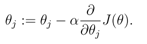

我们采用的每颗树更新策略是针对F(x)的,而F(x)沿着梯度的方向的累加,目标是使得我们的
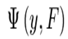
误差函数达到最小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号