AWK实现多文件读取和处理
当我们使用awk整合文件的时候,如果是两个文件,我们经常会用NR==FNR和NR!=FNR两个来指定读取第一个或者是第二个文件,但是如果涉及到三个及以上文件这种方式就不适用,除非我们使用前面两个文件的方式,生成第三者,在用第三者进行整合,也是可以实现,但是这样子多了个第三者,而且显得比较笨拙。我们可以使用如下三种通用方式来实现awk多文件的读取和处理:
第一种: awk 'ARGIND==1{...}ARGIND==2{...}ARGIND==3{...} ...' file1 file2 file3 ...
第二种:awk 'FILENAME==ARGV[1]{...}FILENAME==ARGV[2]{...}FILENAME==ARGV[3]{...}...' file1 file2 file3 ...
第三种:awk 'FILENAME=="file1"{...}FILENAME=="file2"{...}FILENAME=="file3"{...}...' file1 file2 file3 ...
以上方式可以用来处理两个及以上文件。如下是针对以上的一个示例:
本例共使用三个文件,分别是hh、zz、xx
hh文件内容:
1234 huang
456 zhi
789 xiong
zz文件内容:
13141234 zhang
1314456 dong
1314789 hua
xx文件内容:
1234 || 13141234
456 Love 1314456
789 || 1314789
例一:将xx文件当中的第一列和hh第一列一样的用hh的第二列替换
命令:awk 'NR==FNR{a[$1]=$2}NR!=FNR{print a[$1],$2,$3}' hh xx
执行结果如下
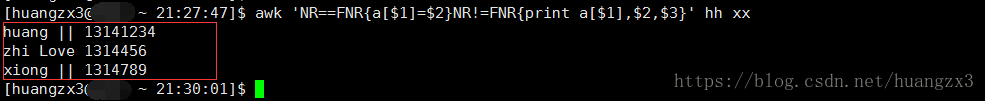
NR==FNR代表读第一个文件
a[$1]=$2代表将第一个文件即(hh)当中第一列作为a数组的键,$2作为a[$1]的值
NR!=FNR代表读第二个文件
print a[$1],$2,$3 代表将第二个文件(即xx)当中的第一个列作为a数组的键,即a[$1],此时得到的值就是在第一个文件给a[$1]赋予的值
例二:将xx文件当中的第一列以及第三列分别和hh以及zz第一列对应起来,分别取对应hh和zz第二列的值替换到xx文件当中
命令:awk 'ARGIND==1{a[$1]=$2}ARGIND==2{b[$1]=$2}ARGIND==3{print a[$1],$2,b[$3]}' hh zz xx 或者采用其他两种方式
执行结果如下:
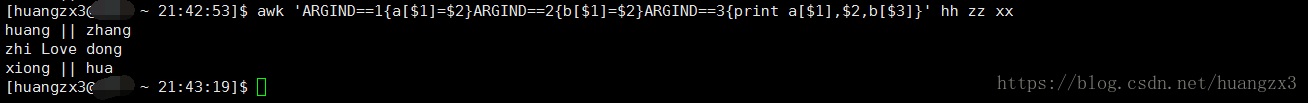
ARGIND==1代表处理第一个文件
ARGIND==2代表处理第二个文件
ARGIND==3代表处理第三个文件.........类似
数组键值对处理逻辑与例一当中一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号