【Java入门提高篇】Day27 Java容器类详解(九)LinkedList详解
这次介绍一下List接口的另一个践行者——LinkedList,这是一位集诸多技能于一身的List接口践行者,可谓十八般武艺,样样精通,栈、队列、双端队列、链表、双向链表都可以用它来模拟,话不多说,赶紧一起来看看吧。
本篇将从以下几个方面对LinkedList进行解析:
1.LinkedList整体结构。
2.LinkedList基本操作使用栗子。
3.LinkedList与ArrayList的对比分析。
4.LinkedList整体源码分析。
LinkedList整体结构
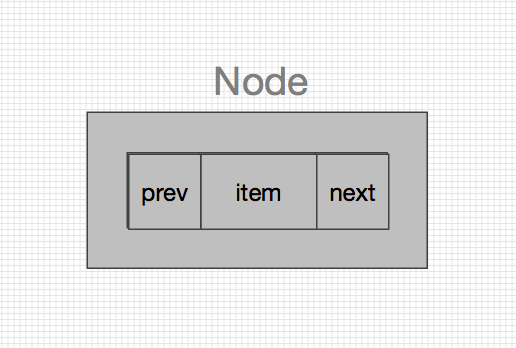
先来看看LinkedList中的结构,LinkedList跟ArrayList不一样,ArrayList中是动态维护了一个数组,所有的操作都是 在该数据上进行操作,而LinkedList中其实是一个个的Node节点,每个Node节点首尾相连。如果你还记得前几篇的内容的话,就应该会想起HashMap中其实也是有Node节点的,但两者还是有比较多不一样的地方,先来看看LinkedList中的Node吧。 
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
嗯,其实很简单,里面只有三个成员变量,item用来存储具体的元素信息,next指向下一个Node节点,prev指向上一个Node节点,node节点之间通过next和prev相连接,组成了一个双向链表的形式。
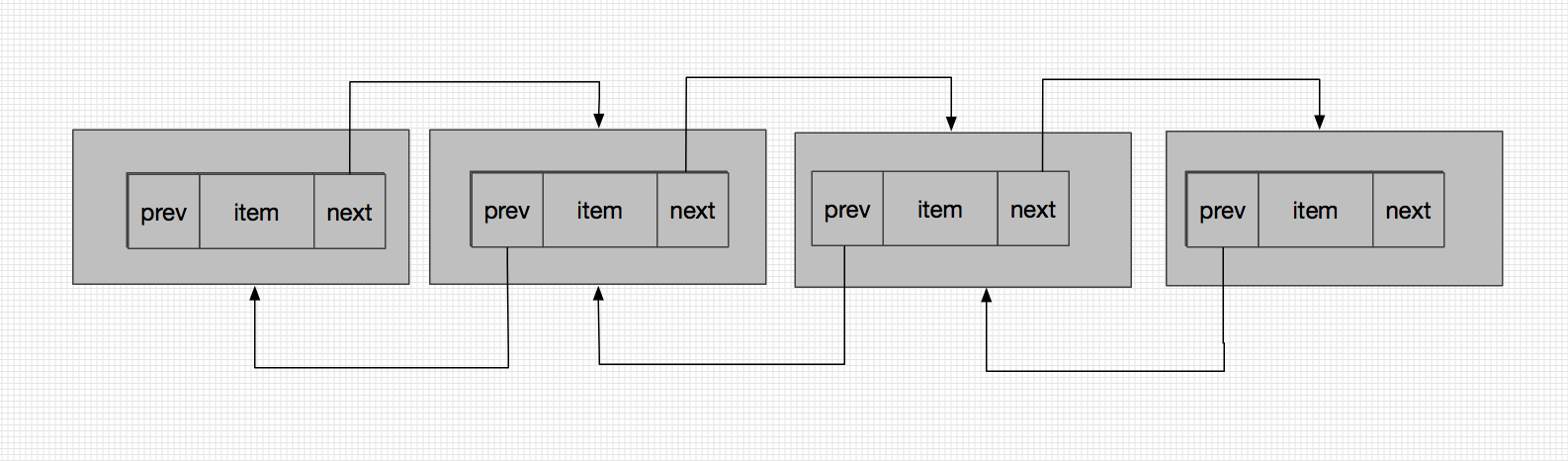
 嗯,看图说话应该就很好懂了,LinkedList正是由Node这样首尾相连组成了铁索连环的格局
嗯,看图说话应该就很好懂了,LinkedList正是由Node这样首尾相连组成了铁索连环的格局 。而HashMap中的Node节点其实是一个单链表的节点,只有指向后一个节点的引用(next),并没有指向前一个节点的引用,回顾一下HashMap的Node节点代码便能发现这一点。
。而HashMap中的Node节点其实是一个单链表的节点,只有指向后一个节点的引用(next),并没有指向前一个节点的引用,回顾一下HashMap的Node节点代码便能发现这一点。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } ......省略部分代码 }
LinkedList基本操作使用栗子
接下来看看LinkedList中的一些基础操作,以下是一个小栗子:
ublic class LinkedListTest { public static void main(String[] args){ // 定义要插入集合的字符串对象 String a = "A", b = "B", c = "C", d = "D", e = "E", f = "F", g = "G"; // 创建List集合 LinkedList<String> list = new LinkedList<>(); // add操作 添加元素 list.add(a); list.add(b); list.add(c); list.add(f); // 迭代器遍历 System.out.println("修改前:"); traverseListByIterator(list); // set操作 // 将索引位置为1的对象修改为对象g list.set(1, g); // 将索引位置为2的对象修改为对象d list.set(2, e); // 新建迭代器进行遍历(注意:迭代器是一次性使用的,遍历到列表尾部之后,无法重置,再次遍历时需要新建迭代器) System.out.println(); System.out.println("set修改后的集合中的元素是:"); traverseListByIterator(list); // 创建ArrayList List<String> strings = new ArrayList<>(); strings.add(d); strings.add(a); strings.add(f); // addAll添加所有元素 list.addAll(strings); //foreach方式遍历 System.out.println("addAll修改后的集合中的元素是:"); traverseListByForEach(list); // remove移除元素 String removeElement = list.remove(); System.out.println("移除的元素是:" + removeElement); System.out.println("remove修改后的集合中的元素是:"); traverseListByForEach(list); // add插入元素(在第四个位置插入元素"gg") list.add(3, "gg"); System.out.println("add插入元素后的集合中的元素是:"); traverseListByForEach(list); } /** * foreach方式遍历列表 * @param list 待遍历的列表 */ private static <T> void traverseListByForEach(List<T> list){ for (T t : list){ System.out.print(t + " "); } System.out.println(); } /** * 迭代器方式遍历列表 * @param list 待遍历的列表 */ private static <T> void traverseListByIterator(List<T> list){ Iterator<T> iterator = list.iterator(); // 循环获取列表中的元素 while (iterator.hasNext()) { System.out.print(iterator.next() + " "); } } }
这里仅仅演示了LinkedList的链表操作,主要有add、addAll、remove、set等,几乎每个常用方法都有重载方法,比如只有一个参数的add方法,会直接将该元素插入到列表的尾部,而有两个参数的add方法,会将元素插入指定位置。
LinkedList与ArrayList的对比分析
也许你会问,ArrayList不是也挺好用的吗,那些操作ArrayList也能做啊,为什么还要用LinkedList呢?
这是一个好问题,ArrayList的最大特点就是能随机访问,因为元素在物理上是连续存储的,所以访问的时候,可以通过简单的算法直接定位到指定位置,所以不管队列的元素数量有多少,总能在O(1)的时间里定位到指定位置,但是连续存储也是它的缺点,导致要在中间插入一个元素的时候,所有之后的元素都要往后挪动。而LinkedList的插入只需要调整前后元素的引用即可。

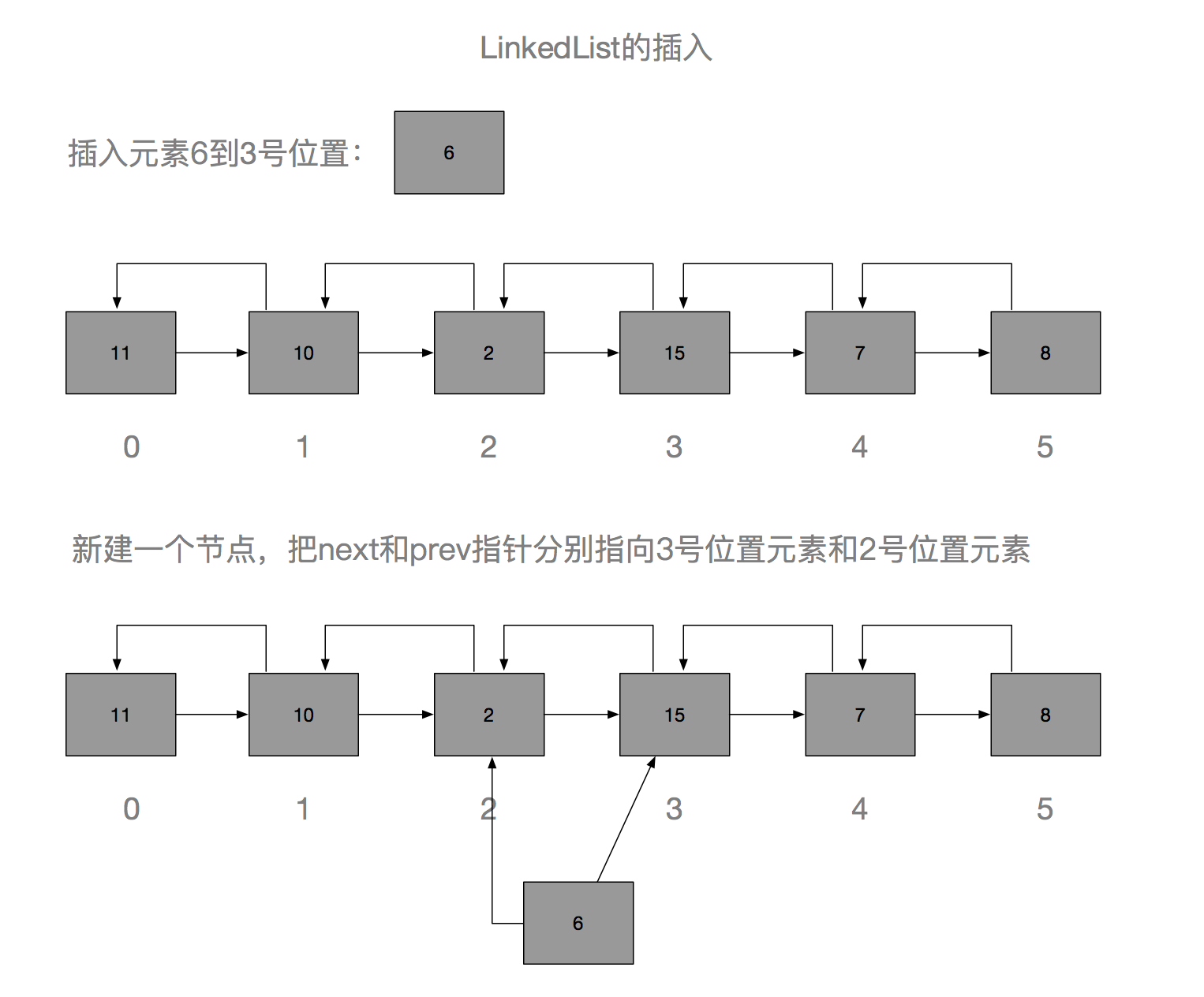
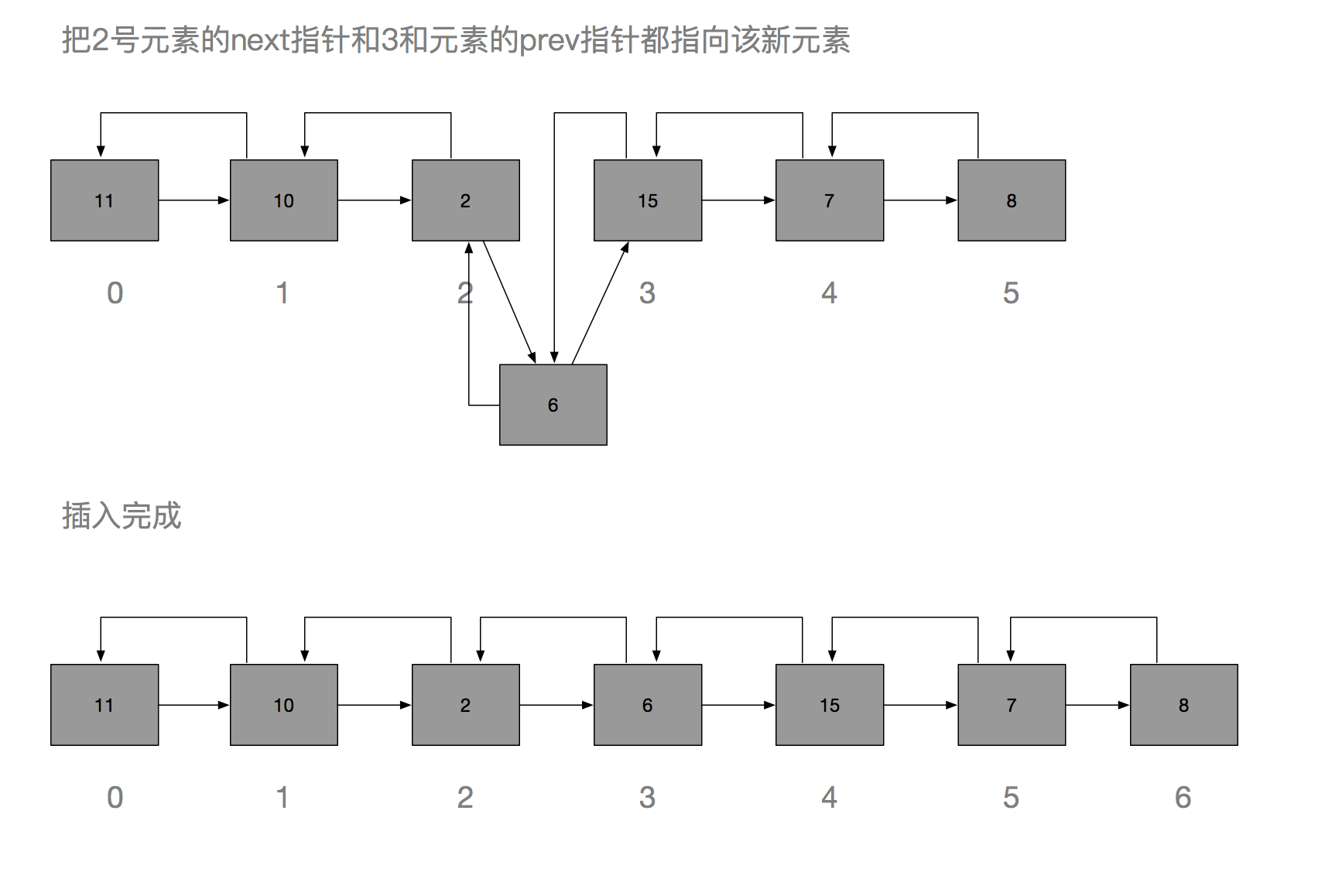
 看图说话,ArrayList插入显然需要进行更多的赋值操作,特别是数组元素个数比较多的时候,会更加明显,如果刚好需要扩容的话,那就会更慢了。而LinkedList只需要将插入位置的前后元素的next或prev引用进行调整即可,而且也没有扩容问题,因为它本身就没有容量的概念,理论上可以无限添加元素。
看图说话,ArrayList插入显然需要进行更多的赋值操作,特别是数组元素个数比较多的时候,会更加明显,如果刚好需要扩容的话,那就会更慢了。而LinkedList只需要将插入位置的前后元素的next或prev引用进行调整即可,而且也没有扩容问题,因为它本身就没有容量的概念,理论上可以无限添加元素。
然后来实际对比一下效率差距:
public abstract class TimeCounter { private String name; TimeCounter(String name){ this.name = name; } public void count(){long time = System.currentTimeMillis(); doSomething(); System.out.println(name + " 耗时:" + (System.currentTimeMillis() - time)); } protected abstract void doSomething(); }
先将这个计时抽象成一个模板,每个需要统计耗时的操作只需要继承该类,然后重写doSomeThing方法即可。
public class Test { public static void main(String[] args){ TimeCounter arrayListAddCounter = new TimeCounter("ArrayList add插入到末尾:") { private List<Integer> list = new ArrayList<>(); @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.add( i); } } }; TimeCounter linkedListAddCounter = new TimeCounter("LinkedList add插入到末尾:") { private List<Integer> list = new LinkedList<>(); @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.add( i); } } }; arrayListAddCounter.count(); linkedListAddCounter.count(); } }
ArrayList add插入到末尾: 耗时:11 LinkedList add插入到末尾: 耗时:9
 好像勉强符合预期,LinkedList比ArrayList略微快一点,其实如果在ArrayList容量足够的情况下,ArrayList的插入元素到末尾操作是要比LinkedList插入要快的,因为它只需要进行一次赋值即可,而LinkedList还需要先new一个新节点然后再接到链表的最后,这个new的过程看起来微不足道,但是一旦循环次数到达一定量级,开销是不可忽略的。例如把上面的循环次数从100000改成1000000,结果就会变成这样:
好像勉强符合预期,LinkedList比ArrayList略微快一点,其实如果在ArrayList容量足够的情况下,ArrayList的插入元素到末尾操作是要比LinkedList插入要快的,因为它只需要进行一次赋值即可,而LinkedList还需要先new一个新节点然后再接到链表的最后,这个new的过程看起来微不足道,但是一旦循环次数到达一定量级,开销是不可忽略的。例如把上面的循环次数从100000改成1000000,结果就会变成这样:
ArrayList add插入到末尾: 耗时:40
LinkedList add插入到末尾: 耗时:768
 这时候,创建节点的开销成了主要时间开销,效率甚至不如ArrayList。我们再换一个插入方式,上面是把元素插入到末尾,这次来把元素插入到首端看看:
这时候,创建节点的开销成了主要时间开销,效率甚至不如ArrayList。我们再换一个插入方式,上面是把元素插入到末尾,这次来把元素插入到首端看看:
public class Test { public static void main(String[] args){ TimeCounter arrayListAddCounter = new TimeCounter("ArrayList add插入到首端:") { private List<Integer> list = new ArrayList<>(); @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.add(0, i); } } }; TimeCounter linkedListAddCounter = new TimeCounter("LinkedList add插入到首端:") { private List<Integer> list = new LinkedList<>(); @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.add(0, i); } } }; arrayListAddCounter.count(); linkedListAddCounter.count(); } }
ArrayList add插入到首端: 耗时:607
LinkedList add插入到首端: 耗时:11
当每次都插入在首端时,ArrayList每次都需要进行元素移动,而且列表中元素越多,需要进行移动的次数也越多,在这种情况下,LinkedList是明显优于ArrayList的。
所以说,其实这两者是各有所长各有所短的,一般情况下,选ArrayList就好,除非是需要进行循环操作的次数到达了万的量级的时候,才需要对两者进行选择。也许你会说,既然一般情况下,两者的效率差别不大,那直接用ArrayList就好了,说这么多干嘛呢。哈哈,如果是这样想,那就大错特错了。首先我们不仅需要知其然,还需要知其所以然,如果仅仅知道LinkedList比ArrayList插入效率高,但是却不知道为什么高,高多少,是远远不够的。其次,我们不能仅仅考虑正常情况,对于极端情况也需要有预防措施,对极端情况的思考,正是高手与新手的最大区别。
下面再看看查找元素的比较:
public class Test { public static void main(String[] args){ TimeCounter arrayListAddCounter = new TimeCounter("ArrayList get遍历元素:") { private List<Integer> list = new ArrayList<>(); { for (int i = 0; i < 100000; i++) { list.add(i); } } @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.get(i); } } }; TimeCounter linkedListAddCounter = new TimeCounter("LinkedList get遍历元素:") { private List<Integer> list = new LinkedList<>(); { for (int i = 0; i < 100000; i++) { list.add(i); } } @Override protected void doSomething() { for (int i = 0; i < 100000; i++) { list.get(i); } } }; arrayListAddCounter.count(); linkedListAddCounter.count(); } }
ArrayList get遍历元素: 耗时:3
LinkedList get遍历元素: 耗时:4484
ArrayList完胜,可以看出LinkedList中查找元素是一个十分耗时的操作,甚至比插入元素耗时还要长,因为每次get的时候都是从链表两端进行逐个查找,直到找到指定的位置。想要知道具体细节的话,那就耐心的看看下面的源码解析吧。
LinkedList整体源码分析
先来看看LinkedList的整体结构:
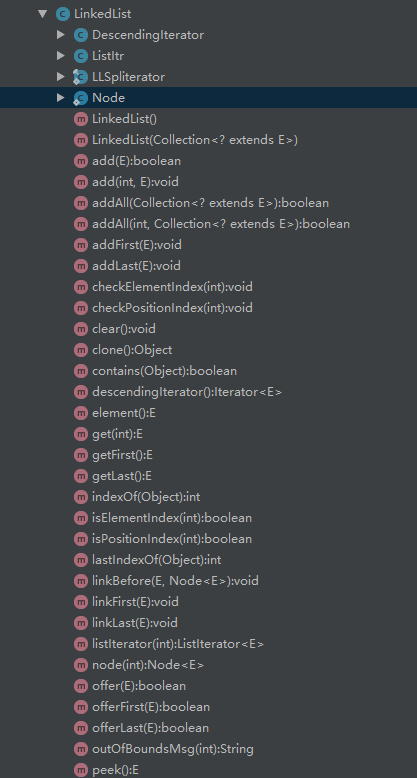
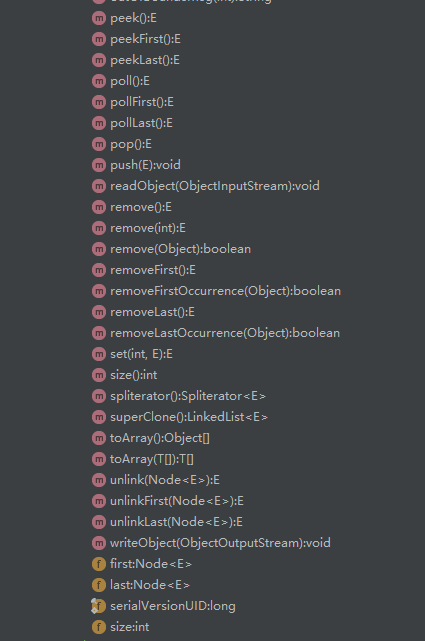
可以看到LinkedList有四个内部类,分别是Node、ListItr、DescendingIterator、LLSpliterator。Node类主要用于存放元素,先来看看Node:
private static class Node<E> { //存放元素 E item; //指向下一个Node节点 Node<E> next; //指向上一个Node节点 Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
这是可以说是最简单的类了,也构成了LinkedList的基础,LinkedList正是由一个个Node节点连接组成。再来看看ListItr类:
//列表迭代器类 private class ListItr implements ListIterator<E> { private Node<E> lastReturned; private Node<E> next; private int nextIndex; private int expectedModCount = modCount; ListItr(int index) { // assert isPositionIndex(index); next = (index == size) ? null : node(index); nextIndex = index; } public boolean hasNext() { return nextIndex < size; } public E next() { checkForComodification(); if (!hasNext()) throw new NoSuchElementException(); lastReturned = next; next = next.next; nextIndex++; return lastReturned.item; } public boolean hasPrevious() { return nextIndex > 0; } public E previous() { checkForComodification(); if (!hasPrevious()) throw new NoSuchElementException(); lastReturned = next = (next == null) ? last : next.prev; nextIndex--; return lastReturned.item; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex - 1; } public void remove() { checkForComodification(); if (lastReturned == null) throw new IllegalStateException(); Node<E> lastNext = lastReturned.next; unlink(lastReturned); if (next == lastReturned) next = lastNext; else nextIndex--; lastReturned = null; expectedModCount++; } public void set(E e) { if (lastReturned == null) throw new IllegalStateException(); checkForComodification(); lastReturned.item = e; } public void add(E e) { checkForComodification(); lastReturned = null; if (next == null) linkLast(e); else linkBefore(e, next); nextIndex++; expectedModCount++; } public void forEachRemaining(Consumer<? super E> action) { Objects.requireNonNull(action); while (modCount == expectedModCount && nextIndex < size) { action.accept(next.item); lastReturned = next; next = next.next; nextIndex++; } checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
这个类是LinkedList的迭代器类,主要用于顺序遍历LinkedList,在前面的栗子中有使用迭代器的hasNext方法和next方法,其实它们的实现都很简单,hasNext只是简单的比较下一个要访问的元素序号是否大于列表中的元素个数,next方法则是将next的引用赋值给lastReturned变量,然后将next指向其下一个节点并且将index加1。但跟普通迭代器不一样的地方在于这个迭代器不仅可以正序遍历,还可以使用previous方法进行倒序遍历,DescendingIterator便是使用了迭代器的previous方法进行便利的。
/** * 降序迭代器 */ private class DescendingIterator implements Iterator<E> { private final ListItr itr = new ListItr(size()); public boolean hasNext() { return itr.hasPrevious(); } public E next() { return itr.previous(); } public void remove() { itr.remove(); } }
这个迭代器就比较简单了,只是包裹了一个ListItr实例,然后重载了Iterator的几个方法。LLSpliterator是用于并行流的可分割式迭代器,这里就不做过多介绍了。
再来看看常用的几个方法的实现:
/** * 添加指定元素到列表尾部 */ public boolean add(E e) { linkLast(e); return true; } /** * 把元素e链接成尾节点 */ void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
当插入一个元素时,会new一个Node对象,并将该值放入Node节点中,然后挂到链表的尾部。
/** * 在列表指定位置插入指定元素 */ public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); } /** * 插入一个元素到指定非空节点之前 */ void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
add的重载版本,可以指定序号进行插入,将元素插入到链表中间,进行的操作过程可以联系前面的图进行理解。
/** * 返回指定位置的元素 */ public E get(int index) { checkElementIndex(index); return node(index).item; } /** * 返回指定元素序号的非空节点。 */ Node<E> node(int index) { // assert isElementIndex(index); //做了一个小优化,如果取的序号小于元素个数的一半,则从链表首端开始遍历,否则从链表尾部开始遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
可以看到get方法其实是从头部或者尾部进行遍历定位的,每次将x的引用向后/向前移动一位,当链表数据量比较大时,这个过程其实是很耗时间的,前面的对比中应该也能发现这一点。
/** * 取回并删除此列表的头部(第一个元素)。 */ public E remove() { return removeFirst(); } /** * 移除列表指定位置的元素,如果其后子序列存在,则将其元素左移,将它们的序号减一。 * 返回列表中移除的元素。 */ public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } /** * 移除并返回首节点 */ public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } /** * 移除首节点并返回该节点元素值 */ private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; } /** * 移除非空节点x */ E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
remove方法也有两个重载版本,不带参数的remove方法仅仅移除并返回最后一个节点,而指定序号参数的remove方法则会移除并返回链表中指定位置的节点。
此外链表还有可以用于队列的诸多方法:
- 在尾部添加元素:(add, offer),add()会在长度不够时抛出异常:IllegalStateException; offer()则不会,只返回false。
- 查看头部元素 (element, peek),返回头部元素,但不改变队列。element()会在没元素时抛出异常:NoSuchElementException; peek()返回null;
- 删除头部元素 (remove, poll),返回头部元素,并且从队列中删除,remove()会在没元素时抛出异常:NoSuchElementException; poll()返回null;
即可以通过以上方法来实现单向队列的操作,也可以使用addFirst,addLast,removeFirst,removeLast方法来实现双向队列的操作。以下是一个简单队列的实现:
public class MyQueue<T> { private LinkedList<T> list = new LinkedList<T>(); //清空队列 public void clear() { list.clear(); } //判断队列是否为空 public boolean isEmpty() { return list.isEmpty(); } //进队 public void enqueue(T o) { list.addLast(o); } //出队 public T dequeue(){ if(!list.isEmpty()) { return list.removeFirst(); } return null; } //获取队列长度 public int length() { return list.size(); } //查看队首元素 public T peek() { return list.getFirst(); } //测试队列 public static void main(String[] args) { MyQueue<String> queue = new MyQueue<String>(); System.out.println(queue.isEmpty()); queue.enqueue("a"); queue.enqueue("b"); queue.enqueue("c"); queue.enqueue("d"); queue.enqueue("e"); queue.enqueue("f"); System.out.println(queue.length()); System.out.println(queue.dequeue()); System.out.println(queue.dequeue()); System.out.println(queue.peek()); System.out.println(queue.dequeue()); queue.clear(); queue.enqueue("s"); queue.enqueue("t"); queue.enqueue("r"); System.out.println(queue.dequeue()); System.out.println(queue.length()); System.out.println(queue.peek()); System.out.println(queue.dequeue()); } }
嗯,其实就是借鸡生蛋的事情嘛,哈哈。
再来看看用LinkedList的简单栈实现:
public class MyStack<T> { private LinkedList<T> stack = new LinkedList<T>(); // 入栈 public void push(T v) { stack.addFirst(v); } // 出栈,但不删除 public T peek() { return stack.getFirst(); } // 出栈 public T pop() { return stack.removeFirst(); } // 栈是否为空 public boolean empty() { return stack.isEmpty(); } // 打印栈元素 public String toString() { return stack.toString(); } }
你看,其实很简单吧,LinkedList提供的大量的方法,可以很方便的进行链表、双向链表、队列、双端队列、栈等数据结构的实现,可以说非常好用了。
下面是LinkedList的全部源码,行有余力的话可以选择你想要了解的部分进行阅读,如果有不懂的地方可以在本文后面留言,当然,也可以直接跳过,以后想要深入了解的时候再进行阅读也不迟。
/** * 双向链表实现了List接口和Deque接口,实现了多有可选List操作,并且允许放入所有的元素,包括null。 * * 所有的操作都表现得像双向链表,索引到列表中的操作将从开头或者结尾遍历列表,以较接近指定索引为准。 * * 注意,这个实现类不是线程安全的,如果多个线程同时访问一个链表,并且至少一个线程修改了链表的结构, * 则必须在外部实现同步。结构性修改指的是那些增加删除一个或多个元素的操作,仅设置元素的值不是结构修改。 * 这通常通过在封装列表的某个对象上进行同步来实现。 * * 如果没有这样的对象存在,则列表应该使用Collections#synchronizedList方法包装,最好在创建列表的时候进行, * 以防止意外的非同步引用对列表进行了修改。 * List list = Collections.synchronizedList(new LinkedList(...)); * * 该类的iterator方法和listIterator方法返回的迭代器是“fail-fast”的,如果列表在迭代器创建之后的任何时刻被进行 * 结构性的修改了,则调用迭代器自身的remove或者add方法时将会抛出ConcurrentModificationException异常,因此 * 当遇到并发修改时,迭代器会快速的失败,而不是在未来某个不确定的时刻进行武断冒险或不确定性的行为 * * 注意,通常来说,不能保证迭代器的fail-fast机制,在遇到非同步的并发修改时,不可能做出任何严格的保证。 * fail-fast 迭代器只能尽最大努力抛出ConcurrentModificationException异常,因此,如果程序依赖这个异常来 * 进行正确性判断是错误的,fail-fast机制仅应该用于检测异常。 * */ public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable { transient int size = 0; /** * 指向第一个节点 * 恒等式: (first == null && last == null) || * (first.prev == null && first.item != null) */ transient Node<E> first; /** * 指向最后一个节点 * 恒等式: (first == null && last == null) || * (last.next == null && last.item != null) */ transient Node<E> last; /** * 构造一个空的列表 */ public LinkedList() { } /** * 构造一个包含指定集合内所有元素的列表,存储的顺序为集合的迭代器访问顺序。 * @throws NullPointerException 空指针异常 */ public LinkedList(Collection<? extends E> c) { this(); addAll(c); } /** * 把元素e链接成首节点 */ private void linkFirst(E e) { final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; } /** * 把元素e链接成尾节点 */ void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } /** * 插入一个元素到指定非空节点之前 */ void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; } /** * 移除首节点并返回该节点元素值 */ private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; } /** * 移除尾节点并返回该节点元素值 */ private E unlinkLast(Node<E> l) { // assert l == last && l != null; final E element = l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element; } /** * 移除非空节点x */ E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; } /** * 返回列表的首节点 */ public E getFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return f.item; } /** * 返回列表的最后一个节点 */ public E getLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return l.item; } /** * 移除并返回首节点 */ public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } /** * 移除并返回尾节点 */ public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l); } /** * 插入指定元素到列表首端 */ public void addFirst(E e) { linkFirst(e); } /** * 扩展指定元素到列表尾端 */ public void addLast(E e) { linkLast(e); } /** * 返回列表中是否包含指定元素 */ public boolean contains(Object o) { return indexOf(o) != -1; } /** * 返回列表中元素个数 */ public int size() { return size; } /** * 添加指定元素到列表尾部 */ public boolean add(E e) { linkLast(e); return true; } /** * 如果该元素存在,则移除列表中首次出现的该指定元素,如果不存在,则原链表不会改变。 * 如果该列表中包含该指定元素则返回true,否则返回false */ public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } /** * 添加指定集合中的所有元素到列表的尾部,顺序为指定集合的迭代器遍历顺序。如果该操作正在进行时,指定集合 * 被修改了,那么该操作的行为是不可预测的。 */ public boolean addAll(Collection<? extends E> c) { return addAll(size, c); } /** * 将指定集合中的所有元素插入到该列表的指定位置之后。将当前在该位置的元素及其之后的元素右移。新元素在列表 * 中的顺序为其原集合迭代器遍历顺序。 */ public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false; Node<E> pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; } for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true; } /** * 移除列表中所有元素 */ public void clear() { // 清除节点之间所有元素的链接不是必要的,但是: // - 如果被清除的节点处于不同代之间,可以帮助分代GC。 // - 一定要释放内存,即便有一个迭代器引用 for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; } // 位置访问操作 /** * 返回指定位置的元素 */ public E get(int index) { checkElementIndex(index); return node(index).item; } /** * 使用指定元素替换指定位置的元素 */ public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; } /** * 在列表指定位置插入指定元素,如果该位置有任何元素,则将其后的子序列元素都往右移(将它们的序号都增加1) */ public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); } /** * 移除列表指定位置的元素,如果其后子序列存在,则将其元素左移,将它们的序号减一。 * 返回列表中移除的元素。 */ public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } /** * 判断该序号是否在列表中对应位置存在元素 */ private boolean isElementIndex(int index) { return index >= 0 && index < size; } /** * 判断给参数是否是迭代器或者add操作的合法位置 */ private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } /** * 构造一个IndexOutOfBoundsException 异常的详情消息,在错误处理代码的许多可能的重构中, * 这个大纲在服务端和客户端虚拟机中都表现的最好。 */ private String outOfBoundsMsg(int index) { return "Index: "+index+", Size: "+size; } private void checkElementIndex(int index) { if (!isElementIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } /** * 返回指定元素序号的非空节点。 */ Node<E> node(int index) { // assert isElementIndex(index); //做了一个小优化,如果取的序号小于元素个数的一半,则从链表首端开始遍历,否则从链表尾部开始遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } // 搜索操作 /** * 返回指定元素在列表中第一次出现的位置,否则返回-1 */ public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; } /** * 返回指定元素在链表中最后一次出现的位置,如果链表中不包含该元素,则返回-1 */ public int lastIndexOf(Object o) { int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; } // 队列操作 /** * 取回但不删除此列表的头部(第一个元素)。 */ public E peek() { final Node<E> f = first; return (f == null) ? null : f.item; } /** * 取回但不删除此列表的头部(第一个元素)。 * 如果不存在,则会抛出NoSuchElementException异常 */ public E element() { return getFirst(); } /** * 取回并删除此列表的头部(第一个元素)。 * 如果该链表为空,则返回null */ public E poll() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); } /** * 取回并删除此列表的头部(第一个元素)。 */ public E remove() { return removeFirst(); } /** * 添加指定元素到链表尾部 */ public boolean offer(E e) { return add(e); } // 双向队列操作 /** * 插入指定元素到队列首部 */ public boolean offerFirst(E e) { addFirst(e); return true; } /** * 插入指定元素到队列尾部 */ public boolean offerLast(E e) { addLast(e); return true; } /** * * 取回但是不删除队列的首元素。如果队列为空则返回null。 */ public E peekFirst() { final Node<E> f = first; return (f == null) ? null : f.item; } /** * 取回但是不删除链表的最后一个元素,如果队列为空,则返回null */ public E peekLast() { final Node<E> l = last; return (l == null) ? null : l.item; } /** * 取回并删除队列的首元素,如果队列为空,则返回null */ public E pollFirst() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); } /** * 取回并删除队列的尾元素,如果队列为空,则返回null */ public E pollLast() { final Node<E> l = last; return (l == null) ? null : unlinkLast(l); } /** * 在队列前端插入元素 */ public void push(E e) { addFirst(e); } /** * 删除并返回队列的第一个元素,如果列表为空则抛出NoSuchElementException 异常 */ public E pop() { return removeFirst(); } /** * 删除此队列中第一个出现的指定元素(从头到尾的方式遍历时),如果队列中不包含该元素,则队列不会改变。 */ public boolean removeFirstOccurrence(Object o) { return remove(o); } /** * 删除此队列中最后一次出现的指定元素(从头到尾的方式遍历时),如果队列中不包含该元素,则队列不会改变。 */ public boolean removeLastOccurrence(Object o) { if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = last; x != null; x = x.prev) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } /** * 返回从指定位置开始,以正确的序列迭代该列表的迭代器. * 列表迭代器是“fail-fast”的,如果列表在迭代器创建之后的任何时刻被进行 * 结构性的修改了,则调用迭代器自身的remove或者add方法时将会抛出ConcurrentModificationException异常,因此 * 当遇到并发修改时,迭代器会快速的失败,而不是在未来某个不确定的时刻进行武断冒险或不确定性的行为 * * 注意,通常来说,不能保证迭代器的fail-fast机制,在遇到非同步的并发修改时,不可能做出任何严格的保证。 * fail-fast 迭代器只能尽最大努力抛出ConcurrentModificationException异常,因此,如果程序依赖这个异常来 * 进行正确性判断是错误的,fail-fast机制仅应该用于检测异常。 */ public ListIterator<E> listIterator(int index) { checkPositionIndex(index); return new ListItr(index); } //列表迭代器类 private class ListItr implements ListIterator<E> { //记录上一个返回的节点 private Node<E> lastReturned; //指向下一个节点 private Node<E> next; //下一个节点的序号 private int nextIndex; //用于检测遍历过程中List是否被修改 private int expectedModCount = modCount; ListItr(int index) { // assert isPositionIndex(index); next = (index == size) ? null : node(index); nextIndex = index; } public boolean hasNext() { return nextIndex < size; } public E next() { //检测是否修改 checkForComodification(); if (!hasNext()) throw new NoSuchElementException(); lastReturned = next; next = next.next; nextIndex++; return lastReturned.item; } public boolean hasPrevious() { return nextIndex > 0; } public E previous() { checkForComodification(); if (!hasPrevious()) throw new NoSuchElementException(); lastReturned = next = (next == null) ? last : next.prev; nextIndex--; return lastReturned.item; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex - 1; } public void remove() { checkForComodification(); if (lastReturned == null) throw new IllegalStateException(); Node<E> lastNext = lastReturned.next; unlink(lastReturned); if (next == lastReturned) next = lastNext; else nextIndex--; lastReturned = null; expectedModCount++; } public void set(E e) { if (lastReturned == null) throw new IllegalStateException(); checkForComodification(); lastReturned.item = e; } public void add(E e) { checkForComodification(); lastReturned = null; if (next == null) linkLast(e); else linkBefore(e, next); nextIndex++; expectedModCount++; } public void forEachRemaining(Consumer<? super E> action) { Objects.requireNonNull(action); while (modCount == expectedModCount && nextIndex < size) { action.accept(next.item); lastReturned = next; next = next.next; nextIndex++; } checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } } private static class Node<E> { //存放元素 E item; //指向下一个Node节点 Node<E> next; //指向上一个Node节点 Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } /** * 返回一个倒序遍历的迭代器 */ public Iterator<E> descendingIterator() { return new DescendingIterator(); } /** * 降序迭代器 */ private class DescendingIterator implements Iterator<E> { private final ListItr itr = new ListItr(size()); public boolean hasNext() { return itr.hasPrevious(); } public E next() { return itr.previous(); } public void remove() { itr.remove(); } } private LinkedList<E> superClone() { try { return (LinkedList<E>) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(e); } } /** * 浅克隆 */ public Object clone() { LinkedList<E> clone = superClone(); // Put clone into "virgin" state clone.first = clone.last = null; clone.size = 0; clone.modCount = 0; // Initialize clone with our elements for (Node<E> x = first; x != null; x = x.next) clone.add(x.item); return clone; } /** * 返回一个包含列表所有元素的数组,元素的顺序为从第一个到最后一个。 */ public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; return result; } /** * 返回一个包含列表所有元素的数组,元素的顺序为从第一个到最后一个。返回元素数组的类型 * 与指定数组的类型一致。如果列表大小适合指定的数组,则返回该数组。 否则,将为新数组分配指定 * 数组的运行时类型和此列表的大小。 * * 如果列表的空间适合指定的数组(数组比列表有更多的元素),紧跟在列表末尾之后的数组中的元素设置 * 为null(仅当调用者知道列表不包含任何null元素时,这在确定列表长度时很有用。) */ @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { if (a.length < size) a = (T[])java.lang.reflect.Array.newInstance( a.getClass().getComponentType(), size); int i = 0; Object[] result = a; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; if (a.length > size) a[size] = null; return a; } private static final long serialVersionUID = 876323262645176354L; /** * 序列化 */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // Write out size s.writeInt(size); // Write out all elements in the proper order. for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item); } /** * 反序列化 */ @SuppressWarnings("unchecked") private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject(); // Read in size int size = s.readInt(); // Read in all elements in the proper order. for (int i = 0; i < size; i++) linkLast((E)s.readObject()); } /** * 创建一个可分割的迭代器 */ @Override public Spliterator<E> spliterator() { return new LLSpliterator<E>(this, -1, 0); } /** Spliterators.IteratorSpliterator 的定制版本 */ static final class LLSpliterator<E> implements Spliterator<E> { static final int BATCH_UNIT = 1 << 10; // batch array size increment static final int MAX_BATCH = 1 << 25; // max batch array size; final LinkedList<E> list; // null OK unless traversed Node<E> current; // current node; null until initialized int est; // size estimate; -1 until first needed int expectedModCount; // initialized when est set int batch; // batch size for splits LLSpliterator(LinkedList<E> list, int est, int expectedModCount) { this.list = list; this.est = est; this.expectedModCount = expectedModCount; } final int getEst() { int s; // force initialization final LinkedList<E> lst; if ((s = est) < 0) { if ((lst = list) == null) s = est = 0; else { expectedModCount = lst.modCount; current = lst.first; s = est = lst.size; } } return s; } public long estimateSize() { return (long) getEst(); } public Spliterator<E> trySplit() { Node<E> p; int s = getEst(); if (s > 1 && (p = current) != null) { int n = batch + BATCH_UNIT; if (n > s) n = s; if (n > MAX_BATCH) n = MAX_BATCH; Object[] a = new Object[n]; int j = 0; do { a[j++] = p.item; } while ((p = p.next) != null && j < n); current = p; batch = j; est = s - j; return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED); } return null; } public void forEachRemaining(Consumer<? super E> action) { Node<E> p; int n; if (action == null) throw new NullPointerException(); if ((n = getEst()) > 0 && (p = current) != null) { current = null; est = 0; do { E e = p.item; p = p.next; action.accept(e); } while (p != null && --n > 0); } if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); } public boolean tryAdvance(Consumer<? super E> action) { Node<E> p; if (action == null) throw new NullPointerException(); if (getEst() > 0 && (p = current) != null) { --est; E e = p.item; current = p.next; action.accept(e); if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); return true; } return false; } public int characteristics() { return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED; } } }
最后,再对LinkedList做一个简单的小结:
LinkedList是由Node节点首尾相连而成的结构,相比ArrayList而言,在进行插入和删除时不需要进行大量的元素移动,省去了元素复制的开销,也不存在扩容开销,但是每次添加节点都需要创建一个新的Node对象,所以当节点数量很多时,这部分对象将占用很大开销,包括时间成本和空间成本,因此需要根据实际情况进行合理选择。LinkedList因为提供了大量方便的获取元素、插入元素和移除元素的方法,所以可以很方便的进行队列、栈等数据结构的实现。
 到此,LinkedList就算讲解完毕了,一不小心又写了这么长,罪过罪过。。。下次还是多分几篇写吧,这么长的文章,确实不便于阅读,面壁中。。。
到此,LinkedList就算讲解完毕了,一不小心又写了这么长,罪过罪过。。。下次还是多分几篇写吧,这么长的文章,确实不便于阅读,面壁中。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号