
【机器学习PAI实践二】人口普查统计
产品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2
一、背景
感谢大家关注玩转数据系列文章,我们希望通过在阿里云机器学习平台上提供demo数据并搭建相关的实验流程的方式来帮助大家学习怎样通过算法来挖掘数据中的价值。本系列文章包括具体的实验流程以及相关的文档教程,欢迎大家进入阿里云数加机器学习平台体验。实验案例请在新建实验页签查看,例如以下图。
本章作为玩转数据系列的开篇,先提供一个简单的案例给大家热身。通过截取一份人口普查的数据,对学历和收入进行统计和分析。主要目的是帮助大家学习阿里云机器学习实验的搭建流程和组件的使用方式。不论什么关于阿里云机器学习方面的交流欢迎訪问我们的云栖社区公众号。
二、数据集介绍
数据源: UCI开源数据集Adult
针对美国某区域的一次人口普查结果,共32561条数据。
具体字段例如以下表:
| 字段名 | 含义 | 类型 |
|---|---|---|
| age | 年龄 | double |
| workclass | 工作类型 | string |
| fnlwgt | 序号 | string |
| education | 教育程度 | string |
| education_num | 受教育时间 | double |
| maritial_status | 婚姻状况 | string |
| occupation | 职业 | string |
| relationship | 关系 | string |
| race | 种族 | string |
| sex | 性别 | string |
| capital_gain | 资本收益 | string |
| capital_loss | 资本损失 | string |
| hours_per_week | 每周工作小时数 | double |
| native_country | 原籍 | string |
| income | 收入 | string |
三、数据探索流程
选中人口统计demo。从模型生成实验。例如以下图:
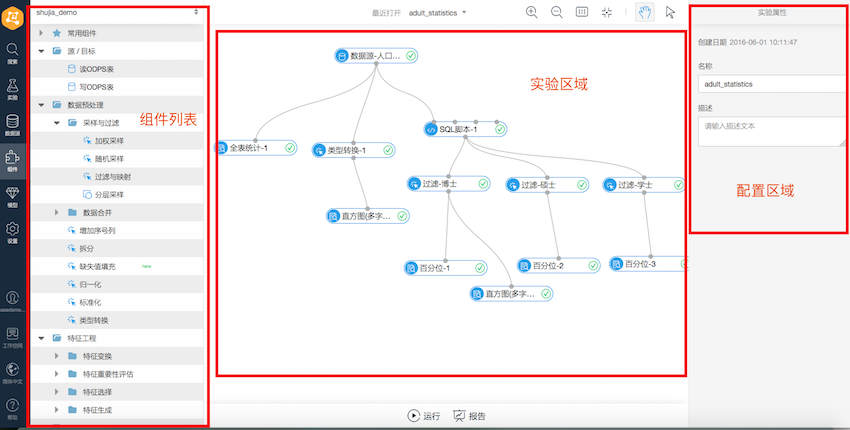
使用方式:
-用户通过从左边列表拖拽组件到试验区域搭建实验流程
-在配置区域对每一个组件的參数进行设置
1.数据导入
机器学习平台的底层计算式阿里云分布式计算系统MaxCompute(原名ODPS),所以实验数据须要先导入到ODPS表里,用户能够通过读ODPS表(图中的数据源-人口统计)组件导入数据。上传成功后。右键组件能够查看数据。例如以下图:
2.理解数据
数据导入后就能够对数据进行分析了。整个实现从纵向看分为三个部分。
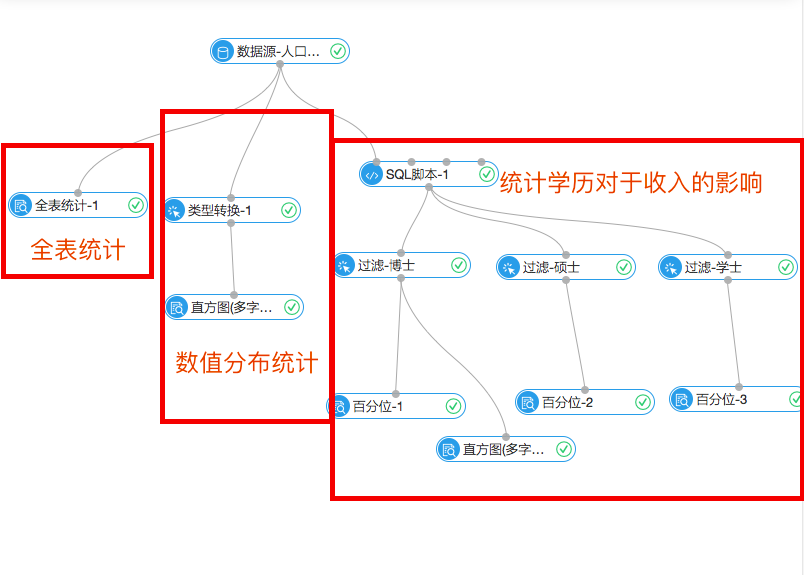
当中全表统计和数值分布统计是帮助用户更好的理解一份数据,理解一份数据是符合泊松分布或是高斯分布,连续或是离散的对之后的算法的选择会有一定帮助(具体的对比关系在之后的文章会具体介绍)。
阿里云机器学习的每一个套件都提供了可视化显示结果的功能。下图是数值统计的直方图组件结果。能够清楚地看到每一个输入数值的分布情况。
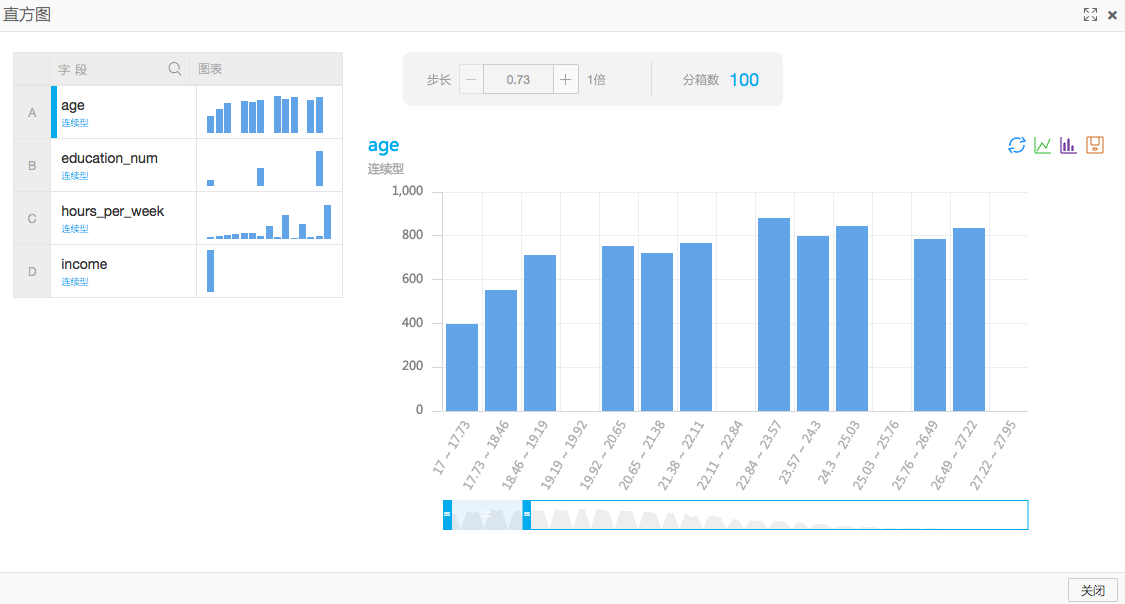
3.统计不同学历的人员的收入情况
每一个人都想添加收入。都想知道哪些因素对收入的影响最大。这些问题都能够通过提取特征,利用机器学习算法训练来得到。本文主要目的是简介一下机器学习平台的用法,这里简单的针对不同学历的人员的收入做一下统计。
(1)数据的预处理
我们看到在收入统计的这条线上。数据流入的第一个组件是SQL脚本(例如以下图),机器学习平台提供SQL脚本对于数据进行处理。这里是将string型的income字段转换成二值型的0和1的形式。0表示年收入在50K下面。1表示年收入在50K以上。这样的将文本数据数值化是机器学习特征处理的经常使用方式,以后会经经常使用到这样的方式。
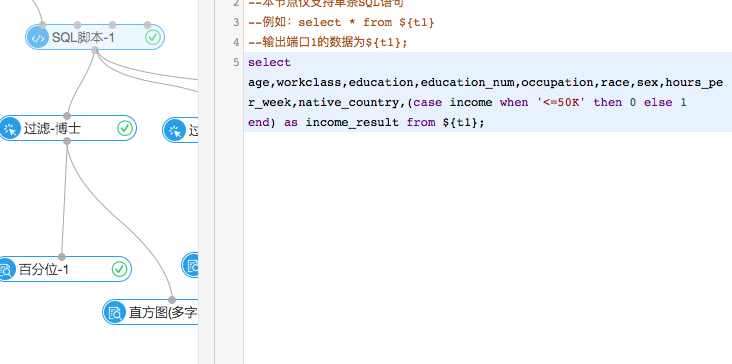
(2)过滤与映射
这一步主要是通过过滤与映射组件将数据依照学历分为三部分,各自是博士、硕士和学士。过滤与映射底层是SQL语法,支持where过滤条件,用户通过在右边的配置栏填写过滤条件就可以。
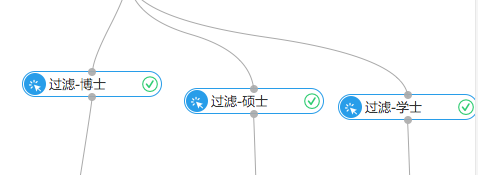
(3)统计结果
通过每一个百分位组件就能够方便的得到每一个分类下的收入比例。下图是调成折线图的展示效果,结果中为0的点也就是年收入在50K下面的人群占比例百分之25左右。
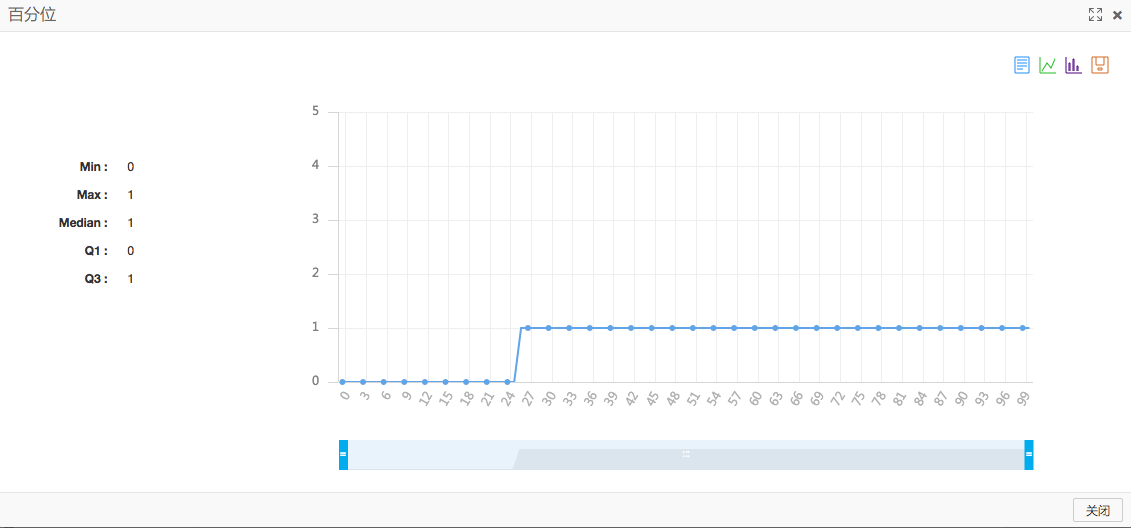
结合三个百分位组件就能够得到例如以下图结果。
| 学历 | 年收入>50K比例 |
|---|---|
| 博士 | 75% |
| 硕士 | 57% |
| 学士 | 42% |
四、其他
參与讨论:云栖社区公众号
免费体验:阿里云数加机器学习平台
