
JavaWeb
JavaWeb
开发遵循《阿里巴巴Java开发手册1.4.0》
框架就像一个傀儡师,我们写的程序是傀儡,顶多就是给傀儡化化妆、打扮打扮,实际的运作全是傀儡师搞的。
1.基础
1.1.Java
1.1.1.类加载机制
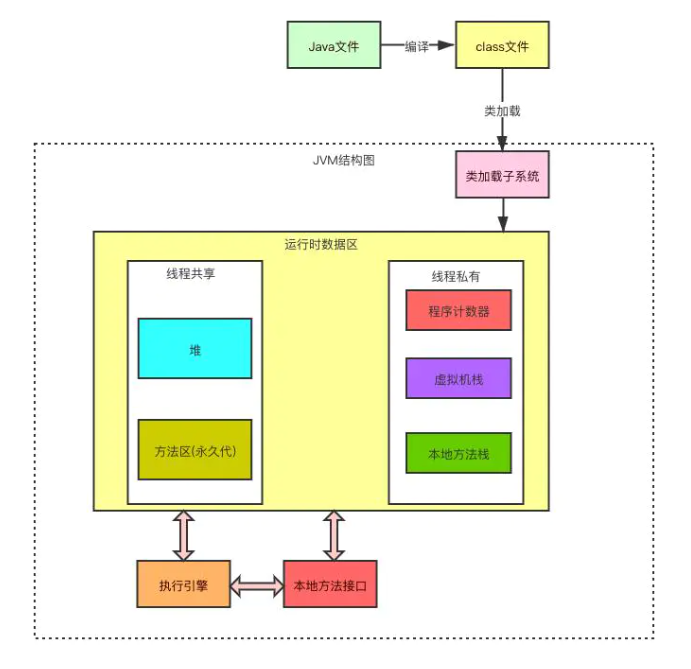
Java文件保存业务逻辑代码,Java编译器将其编译为class文件,保存着JVM将要执行的指令。当JVM需要某个类时,会加载对应的class文件生成Class对象。将class文件加载到虚拟机的内存,这个过程被称为类的加载。类加载的最终产品是位于堆区中的Class对象。
Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。类加载器并不需要等到某个类被“首次主动使用”时再加载它,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它。如果在预先加载的过程中遇到了class文件缺失或存在错误,类加载器必须在程序首次主动使用该类时才报告错误(LinkageError错误),如果这个类一直没有被程序主动使用,那么类加载器就不会报告错误。
Java类生命周期
类加载的过程包括了加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)五个阶段,验证、准备、解析这三个阶段也被统称为连接(Linking)阶段。最后是使用(Using)与卸载(Uploading)。
在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也成为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
加载(Loading)
加载阶段主要查找并加载类的二进制数据,类加载器通过一个类的完全限定名查找此类字节码文件,并利用字节码文件创建一个class对象。在加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取其定义的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
相对于类加载的其他阶段而言,加载阶段是可控性最强的阶段,因为开发人员既可以使用系统提供的类加载器来完成加载,也可以使用自己定义的类加载器来完成加载。
- JVM类加载器
类的加载由类加载器完成,类加载器通常由JVM提供。JVM提供的这些类加载器通常被称为系统类加载器,除此之外,开发者可以通过继承ClassLoader基类来创建自己的类加载器。JVM预定义有三种类加载器:
-
启动类加载器(Bootstrap ClassLoader)
用来加载 Java 的核心类,是用原生代码来实现的,并不继承自java.lang.ClassLoader(负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类)。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。
-
扩展类加载器(Extension ClassLoader)
它负责加载JRE的扩展目录,lib/ext或者由java.ext.dirs系统属性指定的目录中的JAR包的类,由Java语言实现,父类加载器为null。
-
应用程序类加载器(Application ClassLoader)
被称为系统(也称为应用)类加载器,它负责在JVM启动时加载来自Java命令的-classpath选项、java.class.path系统属性或者CLASSPATH换将变量所指定的JAR包和类路径。程序可以通过ClassLoader的静态方法getSystemClassLoader()来获取系统类加载器。如果没有特别指定,则用户自定义的类加载器都以此类加载器作为父加载器。由Java语言实现,父类加载器为ExtClassLoader。
JVM的类加载机制有以下三个特点:
-
全盘负责
所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
-
缓存机制
缓存机制将会保证所有加载过的Class都会被缓存。当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
-
双亲委派
双亲委派就是如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,,若成功则直接返回,,否则继续向上,直到到达最顶层的类加载器。因此。所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器无法完成该加载请求时,子加载器才会尝试自己去加载该类。
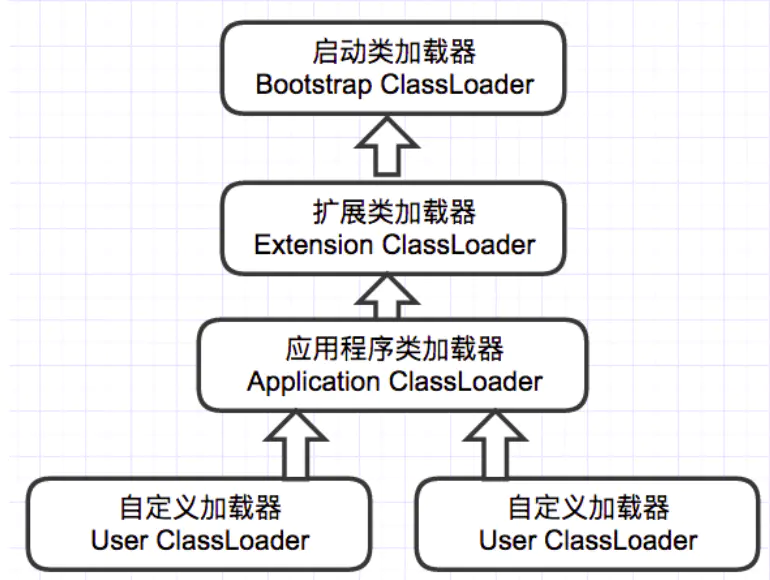
JVM 通过双亲委派模型进行类的加载,当然我们也可以通过继承java.lang.ClassLoader实现自定义的类加载器。采用双亲委派的一个好处是比如加载位于rt.jar包中的java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。从而系统内防止内存中出现多份同样的字节码,保证Java程序安全稳定运行。
JVM有3种类加载方式:
-
命令行启动应用时候由JVM初始化加载。
-
通过ClassLoader.loadClass()方法动态加载。将class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。Classloader.loaderClass得到的class是还没有连接(验证、准备、解析)的。
-
通过Class.forName()方法动态加载。将类的class文件加载到jvm中,还会对类进行解释,执行类中的static块。Class.forName()得到的class是已经初始化完成的,但可以修改initialize参数不进行初始化,也可指定加载器。
验证(Verification)
验证阶段是为了确保Class文件的字节流中包含的信息是符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。大致会完成4个检验动作:
-
文件格式验证
验证字节流是否符合Class文件格式的规范。例如:是否以0xCAFEBABE开头,主次版本号是否在当前虚拟机的处理范围之内,常量池中的常量是否有不被支持的类型。
-
元数据验证
对字节码描述的信息进行语义分析(注意:对比javac编译阶段的语义分析),以保证其描述的信息符合Java语言规范的要求。
-
字节码验证
通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
-
符号引用验证
确保解析动作能正确执行。
验证阶段是非常重要的,但不是必须的,它对程序运行期没有影响。如果所引用的类经过反复验证,那么可以考虑采用-Xverifynone参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
准备(Preparation)
准备阶段是为static修饰的类变量分配内存,并设置类变量初始值的阶段。这些内存都将在方法区中分配。不包含final修饰的静态变量,因为final变量在编译时分配。
注意:
-
此时进行内存分配的仅包括类变量(static),而不包括实例变量。实例变量会在对象实例化时随着对象一块分配在Java堆中。
-
这里所设置的初始值通常情况下是数据类型默认的零值(如0、0L、null、false等)而不是被在Java代码中被显式地赋予的值。
举个例子:类中定义了变量
public static int a = 100;,实际上变量 a 在准备阶段过后的初始值为0而不是100(对这句话有疑惑的可以去补充下JAVA数据类型初始值的知识),将a赋值为100的put static指令是程序被编译后, 存放于类构造器<clinit>()方法之中的。不过注意,如果声明为public static final int a = 100;,在编译阶段会为a生成ConstantValue属性,在准备阶段虚拟机会根据ConstantValue属性将a赋值为100。
解析(Resolution)
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程,主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。符号引用就是一组符号来描述目标,可以是任何字面量。
PS:
-
符号引用(Symbolic References)
符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。在编译时,java类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。各种虚拟机实现的内存布局可能有所不同,但是它们能接受的符号引用都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
-
直接引用
直接引用可以是
- 直接指向目标的指针(比如,指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的指针)
- 相对偏移量(比如,指向实例变量、实例方法的直接引用都是偏移量)
- 一个能间接定位到目标的句柄
直接引用是和虚拟机的布局相关的,同一个符号引用在不同的虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经被加载入内存中了。
初始化(Initialization)
这里是类加载的最后阶段,如果该类具有父类就进行对父类进行初始化。执行其静态初始化器(静态代码块)和静态初始化成员变量。(前面已经对static初始化了默认值,这里我们对它进行赋值,成员变量也将被初始化。)
JVM负责对类进行初始化,主要对类变量进行初始化。
Java对类变量进行初始值设定的两种方式:
- 声明类变量是指定初始值
- 使用静态代码块为类变量指定初始值
JVM初始化步骤:
- 假如这个类还没有被加载和连接,则程序先加载并连接该类。
- 假如该类的直接父类还没有被初始化,则先初始化其直接父类。
- 假如类中有初始化语句,则系统依次执行这些初始化语句。
只有当对类的主动使用的时候才会导致类的初始化,类的主动使用包括以下六种:
- 创建类的实例,也就是new的方式。
- 访问某个类或接口的静态变量,或者对该静态变量赋值。
- 调用类的静态方法。
- 反射(如Class.forName())
- 初始化某个类的子类,则其父类也会被初始化。
- Java虚拟机启动时被标明为启动类的类(Java Test),直接使用java.exe命令来运行某个主类。
注意以下几种情况不会执行类初始化:
- 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
- 通过类名获取Class对象,不会触发类的初始化。
- 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。
- 通过ClassLoader默认的loadClass方法,也不会触发初始化动作。
示例如下:
class Teacher { public static void main(String[] args) { staticFunction(); } static Teacher teacher = new Teacher(); static { System.out.println("teacher static code block"); } { System.out.println("teacher normal code block"); } Teacher() { System.out.println("teacher construction method"); System.out.println("age = " + age + ", name = " + name); } public static void staticFunction() { System.out.println("teacher static method"); } int age = 24; static String name = "Tony"; }
main作为程序入口,首先初始化Teacher。对 Teacher 类进行初始化首先是执行类构造器(按顺序收集类中所有静态代码块和类变量赋值语句就组成了类构造器),后执行对象的构造器(先收集成员变量赋值,后收集普通代码块,最后收集对象构造器,最终组成对象构造器)。
类构造器顺序:
static Teacher teacher = new Teacher(); static { System.out.println("teacher 静态代码块"); } static String name = "Tony";
其中new Teacher()时,name还是准备阶段赋予的null。new Teacher()导致执行对象的构造器提前:
int age = 24; { System.out.println("teacher普通代码块"); } Teacher() { System.out.println("teacher 构造方法"); System.out.println("age= " + age + ",name= " + name); }
其中打印出的name为null。构造完成后,继续执行未完成的执行类构造器。
最终执行结果为:
teacher normal code block teacher construction method age = 24, name = null teacher static code block teacher static method
1.1.2.反射机制
动态语言,即程序运行时,允许改变程序结构或变量类型的语言。Java并非动态语言,它却有着一个非常突出的动态相关机制:Reflection。
基本原理
class字节码文件载入内存时,JVM产生一个java.lang.Class对象代表该class字节码文件,从该Class对象中可以获得类的许多基本信息,这就是反射机制。一个类只会被载入JVM一次,包名+类名即为唯一标识。Class类的构造方法为private,其对象是JVM在加载类时通过调用类加载器中的defineClass()方法创建的,因此不能显式地创建一个Class对象。
Class对象获取
Java程序中获取Class对象有以下3种方式:
- Class.forName(String className):多用于配置文件。
- className为类全名,如java.lang.String。
- 该方法会抛出ClassNotFoundException异常,需要处理。
- 类名.class:多用于参数的传递。
- 通过.class获得Class对象更安全,推荐使用。
- 对象.getClass():多用于对象获取字节码的方式。
- getClass()为Object对象的方法。
PS:获取基本数据类型的Class对象,可以使用对应的打包类加上.TYPE,例如,Integer.TYPE可获得int的Class对象。
Class常用方法
这里准备一个Entity便于下面Demo示例进行理解。
public class Person { private String name; private Integer age; // 此处省略构造方法、gettter/setter、toString public void eat(){ System.out.println("eat..."); } public void eat(String food){ System.out.println("eat..."+food); } }
- 构造相关
- public Constructor getConstructor(Class<?>... parameterTypes):获得参数类型与parameterTypes对应的构造方法。
public class Demo { public static void main(String[] args) throws Exception { Class<Person> personClass = Person.class; Constructor<Person> constructor1 = personClass.getConstructor(); Person nobody = constructor1.newInstance(); Constructor<Person> constructor2 = personClass.getConstructor(String.class, Integer.class); Person jack = constructor2.newInstance("Jack", 4); } }
- 属性相关
-
public Field getField(String name):获取名为name的public成员属性。
-
public Field[] getFields():获取所有public成员属性(包括父类)。
-
public Field getDeclaredField(String name):获取名为name的成员属性。
-
public Field[] getDeclaredFields():获取所有成员属性(不包括父类)。
上述方法获得Field对象后,可通过相应的方法对对应的类进行操作(注意:操作私有成员属性,需要先调用对应Field的setAccessible(true)方法)。示例如下:
public class Demo { public static void main(String[] args) throws Exception { Person person = new Person("Tom", 3); Class<Person> personClass = Person.class; Field name = personClass.getDeclaredField("name"); name.setAccessible(true); Object o = name.get(person); System.out.println(o); name.set(person, 20); System.out.println(person); } }
运行结果为:
3 Person{name='Tom', age=20}
- 方法相关
- public Method getMethod(String name, Class<?>... parameterTypes):获得方法名为name,参数类型与parameterTypes对应的方法。
- public Method[] getMethods():获得所有公共方法,包括由类或接口声明的以及从超类和超接口继承的方法。
public class Demo { public static void main(String[] args) throws Exception { Person person = new Person("Tom", 3); Class<Person> personClass = Person.class; Method eat = personClass.getMethod("eat"); eat.invoke(person); Method eatWithFood = personClass.getMethod("eat", String.class); eatWithFood.invoke(person, "apple"); } }
运行结果为:
eat... eat...apple
注意:getMethods()方法获得的方法顺序与原类的方法顺序并不相同,取决于方法名对应的Symbol对象的地址的先后顺序,Symbol对象在方法名第一次使用时创建。JVM这样排序是考虑到对象的地址使用二分排序的算法可快速定位。
1.1.3.注解
又称Java标注,是Java语言5.0版本开始支持加入源代码的特殊语法元注解。
元注解
元注解是负责对其它注解进行说明的注解,在 java.lang.annotation 包中。
- @Documented
描述注解是否被抽取到API文档中。@Documented修饰的Annotation去注解其它类时,javadoc生成该类文档会包含对应注解。该注解为标记注解,无成员变量。
- @Target
描述注解能够作用的位置。含有一个成员变量ElementType[] value(),用于设置使用目标,可取值及含义如下:
public enum ElementType { TYPE, // 用于类、接口(包括注解类型)或enum声明 FIELD, // 用于成员变量(包括枚举常量) METHOD, // 用于方法 PARAMETER, // 用于类型参数(JDK1.8新增) CONSTRUCTOR, // 用于构造方法 LOCAL_VARIABLE, // 用于局部变量 ANNOTATION_TYPE, PACKAGE, // 用于包 TYPE_PARAMETER, TYPE_USE, MODULE, RECORD_COMPONENT; }
- @Retention
描述注解被保留的阶段。含有一个成员变量RetentionPolicy value(),用来设置保留策略,可取值及含义如下:
public enum RetentionPolicy { SOURCE, // 在源文件中有效(即源文件保留) CLASS, // 在 class 文件中有效(即 class 保留) RUNTIME // 在运行时有效(即运行时保留) }
生命周期大小排序为 SOURCE < CLASS < RUNTIME,前者能使用的地方后者一定也能使用。
- @Inherited
描述注解是否被子类继承。@Inherited修饰的Annotation去注解其它类时,其子类自动继承该Annotation。该注解为标记注解,无成员变量。
PS:还有两个元注解@Repeatable、@Native自行查看。
注解应用
利用了Java反射机制,我们可以获得注解标注内容,从而实现一些功能。以下是列出的两个例子:
- 通过注解与Java反射机制实现方法调用
准备我们将要调用的类及其方法:
package com.demo.anno; public class Demo { public void show() { System.out.println("show"); } }
准备注解,用于我们将要调用的类及其方法:
@Target(value = {ElementType.TYPE}) @Retention(value = RetentionPolicy.RUNTIME) public @interface Conf { String className(); String methodName(); }
实现代码:
@Conf(className = "com.demo.anno.Demo", methodName = "show") public class Test { public static void main(String[] args) throws Exception { // 1.获得注解 Class<Test> testClass = Test.class; Conf annotation = testClass.getAnnotation(Conf.class); // 2.获得方法 String className = annotation.className(); String methodName = annotation.methodName(); // 3.执行方法 Class<?> demoClass = Class.forName(className); Constructor<?> constructor = demoClass.getConstructor(); Object demo = constructor.newInstance(); Method method = demoClass.getMethod(methodName); method.invoke(demo); } }
className填入类唯一标识,methodName填入方法。通过反射机制来获得注解,再获得注解中配置的值,再通过反射机制拿到方法、生成实例后执行。执行结果如下:
show
- 对含注解的方法进行Exception检查(Junit原理)
准备标记注解,用于注解方法,被注解的方法进行Exception检查:
@Target(value = {ElementType.METHOD}) @Retention(value = RetentionPolicy.RUNTIME) public @interface Check { }
准备需要的方法:
public class Demo { @Check public void add(){ System.out.println("1+0="+(1+0)); } @Check public void sub(){ System.out.println("1-0="+(1-0)); } @Check public void mul(){ System.out.println("1*0="+(1*0)); } @Check public void div(){ System.out.println("1/0="+(1/0)); } }
检验的实现:
public class Test { public static void main(String[] args) { // 1.获取所有方法 Demo demo = new Demo(); Class<? extends Demo> demoClass = demo.getClass(); Method[] methods = demoClass.getMethods(); // 2.执行 for (Method method : methods) { if (method.isAnnotationPresent(Check.class)) { try { method.invoke(demo); } catch (IllegalAccessException | InvocationTargetException | ArithmeticException e) { System.out.println("Error"); } } } } }
通过反射机制获得Demo的所有方法,如果含有Check注解,执行该方法,以检验方法是否存在异常。运行结果如下:
1+0=1 1-0=1 Error 1*0=0
PS:
- 如果注解本本身只有一个注解类型元素,而且命名为value,那么在使用注解的时候可以直接使用。
1.1.4.序列化机制
Java序列化和反序列就是把Java对象转换为有序字节流和反转回来的过程。通过序列化与反序列可实现对象的持久化(对象存储在JVM的堆区,JVM停止运行,对象也不存在,可将对象序列换写进硬盘来实现持久化。)和对象网络传输(数据只能以二进制形式在网络中传输,对象序列化为字节流即可进行网络数据传输。)等功能。
Java序列化是“深复制”,即序列化不仅保留对象的数据,而且递归保留对象引用的每个对象的数据。
序列化是保存对象的状态,和类状态无关,所以它不会读取静态数据。
版本号
版本号serialVersionUID用来标示Java类的版本,默认是数据域类型和方法签名信息通过SHA算法取到的指纹,采用了SHA码的前8个字节,主要用在反序列化过程中的类的校验。用来保证在反序列时,发送方发送的和接受方接收的是可兼容的对象。如果接收方接收的类的serialVersionUID与发送方发送的serialVersionUID不一致,进行反序列时会抛出 InvalidClassException。序列化的类可显式声明 serialVersionUID 的值,如下:
private static final long serialVersionUID = -4392658638228508589L;
注意:建议显式指定 serialVersionUID 的值,因为
-
不同的 jdk 编译可能生成不同的serialVersionUID 默认值,可能导致生成方发送的序列化字节流无法反序列化。
-
Java根据类细节默认生成serialVersionUID值,类源码修改重新编译后,默认生成serialVersionUID值也可能会变化,原本序列化的字节流无法反序列化。
那对类的哪些修改可能会导致反序列化失败呢?分几种情况讨论。
- 如果修改类时仅仅修改了方法、静态变量或瞬态实例变量(瞬态变量就是被 transient 修饰的变量),反序列化不受影响。
- 如果修改类时修改了非瞬态的实例变量,则可能导致序列化版本不兼容,这时应该更新 serialVersionUID 类变量的值。
- 如果只是新增或者删除类中的实例变量,序列化版本可以兼容,这时可以不更新serialVersionUID 类变量的值,但是反序列化得到的新增的实例变量值都是null或0。
序列号
序列号是关联到对象的,是内部流处理的机制,外部是不可见的。
对于每个对象,都有一个序列号。序列化对象时,程序将先检查该对象是否已经被序列化过,未序列化会将其数据存储到输出流中,否则只会输出一个序列化编号。反序列化时,首次遇到的序列号,会根据流中的信息构建一个Java对象,否则引用之前构建的对象而不是反序列化。
注意:由于上述序列化特性,可变对象序列化后,修改变量再次序列化,其序列化的依然是之前的内容,但两次序列化之间进行过反序列化,第二次反序列化的内容为修改后的内容。
实现
对于需要实现序列化的类,需要实现Serializable接口或者Externalizable接口。而JDK提供的ObjectOutputStream和ObjectInputStream用来实现序列化和反序列化。
- Serializable
Serializable是一个标记接口。对于不想序列化的属性添加transient关键字即可。
假设提供序列化对象Person实现Serializable:
public class Person implements Serializable { private static final long serialVersionUID = -8228632858950394658L; private String name; private transient Integer age; // 此处省略构造方法、gettter/setter、toString }
进行序列化与反序列化示例:
public class Demo { public static void main(String[] args) { // 序列化对象 Person person = new Person("Tom", 3); // 序列化 ObjectOutputStream objectOutputStream; try { objectOutputStream = new ObjectOutputStream(new FileOutputStream("D:\\test.txt")); objectOutputStream.writeObject(person); } catch (IOException e) { throw new RuntimeException(e); } // 反序列化 ObjectInputStream objectInputStream; Person readPerson; try { objectInputStream = new ObjectInputStream(new FileInputStream("D:\\test.txt")); readPerson = (Person) objectInputStream.readObject(); } catch (IOException | ClassNotFoundException e) { throw new RuntimeException(e); } System.out.println(readPerson); } }
运行结果:
Person{name='Tom', age=null}
- Externalizable
Externalizable本身继承Serializable,需要实现void writeExternal(ObjectOutput out)方法与void readExternal(ObjectInput in)方法,指定哪些成员序列化与反序列化。
序列化对象Person实现Externalizable的举例如下:
public class Person implements Externalizable { private static final long serialVersionUID = -3822864358992658508L; private String name; private Integer age; // 此处省略构造方法、gettter/setter、toString @Override public void writeExternal(ObjectOutput out) throws IOException { out.writeObject(name); out.writeObject(age); } @Override public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { this.name = (String) in.readObject(); this.age = (Integer) in.readObject(); } }
注意:
- 需要进行序列化的对象本身及其成员变量均需要能进行序列化。
- 序列化对象需要提供无参构造以反序列化。
- Externalizable接口实现中,write与read数量和顺序保持一致,write数量小于read数量反序列化时会报OptionalDataException,read顺序与write顺序一致。
1.1.5.Maven
Maven 是 Apache 下的一个纯 Java 开发的开源项目,它是一个基于项目对象模型(POM)的项目管理和理解工具。Maven 是使用 Java 语言编写的,因此它具有跨平台性,主要服务于基于 Java 平台的项目构建、依赖管理和项目信息管理。当然,Maven 也可被用于构建和管理其他的项目,例如 C#,Ruby,Scala 和其他语言编写的项目。
生命周期
Maven 拥有三套标准的生命周期,并相互独立。每套生命周期包含一系列的构建阶段(phase),阶段具有顺序,执行生命周期某个phase时会按照顺序从该生命周期首个phase执行到指定的某个phase。
-
Clean Lifecycle:在构建之前进行一些清理工作。
构建阶段:pre-clean(清理前)、clean(清理)、post-clean(清理后)
-
Default Lifecycle:构建的核心部分,编译,测试,打包,部署等等。
构建阶段:
名称 作用 validate 验证项目是否正确以及所有必要信息是否可用。 initialize 初始化构建状态。 generate-sources 生成编译阶段需要的所有源码文件。 process-sources 处理源码文件,例如过滤某些值。 generate-resources 生成项目打包阶段需要的资源文件。 process-resources 处理资源文件,并复制到输出目录,为打包阶段做准备。 compile 编译源代码,并移动到输出目录。 process-classes 处理编译生成的字节码文件 generate-test-sources 生成编译阶段需要的测试源代码。 process-test-sources 处理测试资源,并复制到测试输出目录。 test-compile 编译测试源代码并移动到测试输出目录中。 test 使用适当的单元测试框架(例如 JUnit)运行测试。 prepare-package 在真正打包之前,执行一些必要的操作。 package 获取编译后的代码,并按照可发布的格式进行打包,例如 JAR、WAR 或者 EAR 文件。 pre-integration-test 在集成测试执行之前,执行所需的操作,例如设置环境变量。 integration-test 处理和部署所需的包到集成测试能够运行的环境中。 post-integration-test 在集成测试被执行后执行必要的操作,例如清理环境。 verify 对集成测试的结果进行检查,以保证质量达标。 install 安装打包的项目到本地仓库,以供其他项目使用。 deploy 拷贝最终的包文件到远程仓库中,以共享给其他开发人员和项目。 -
Site Lifecycle:生成项目报告,站点,发布站点。
构建阶段:pre-site、site、post-site、site-deploy
Maven 生命周期是抽象的,其本身不能做任何实际工作,这些实际工作(如源代码编译)都通过调用 Maven 插件中的插件目标(plugin goal)完成的。(Maven 的所有功能都是通过插件实现的)
项目构建
Archetype 是 Maven 项目的模板工具包,它定义了 Maven 项目的基本架构。Archetype 为开发人员提供了数千种创建 Maven 项目的模板,Maven 通过这些模板可以帮助用户快速的生成项目的目录结构以及 POM 文件。Maven Archetype 由下面 5 个模块组成:
- maven-archetype-plugin:Archetype 插件。
- archetype-packaging:用于描述 Archetype 的生命周期与构建项目软件包。
- archetype-models:用于描述类与引用。
- archetype-common:核心类。
- archetype-testing:用于测试 Maven Archetype 的内部组件。
调用mvn archetype:generate -DgroupId=net.biancheng.www -DartifactId=helloMaven -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false可创建一个maven-archetype-quickstart架构的Maven项目。(-DgroupId: 项目组 ID,通常为组织名或公司网址的反写;-DartifactId: 项目名;-DarchetypeArtifactId: 指定 ArchetypeId,maven-archetype-quickstart 用于快速创建一个简单的 Maven 项目;-DinteractiveMode: 是否使用交互模式。)
POM
POM(Project Object Model,项目对象模型)是 Maven 的基本组件,它是以 xml 文件的形式存放在项目的根目录下,名称为 pom.xml。POM 中定义了项目的基本信息,用于描述项目如何构建、声明项目依赖等等。
POM示例:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <!-- 配置POM继承,可选 --> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.2</version> <relativePath/> </parent> <!-- 配置项目坐标 --> <groupId>cn.meyok.mavenlearn</groupId> <artifactId>pomlearn</artifactId> <version>0.0.1-SNAPSHOT</version> <!-- 项目产生的构件类型,例如jar、war、ear、pom。插件可以创建他们自己的构件类型,所以前面列的不是全部构件类型 --> <packaging>jar</packaging> <!-- 配置相关信息,产生文档使用,可选 --> <name>mavenlearn</name> <url>http://mavenlearn.meyok.cn</url> <description>mavenlearn</description> <!-- 配置本地仓库路径,可选 --> <localRepository>D:/myRepository/repository</localRepository> <!-- 配置远程仓库,可选 --> <repositories> <repository> <id>meyok.lib</id> <url>http://download.meyok.org/maven/lib</url> </repository> ... </repositories> <!-- 配置POM聚合,可选 --> <modules> <module>user</module> ... </modules> <!-- 配置Profile,可选 --> <profiles> <profile> <id>test</id> <activation> <property> <name>env</name> <value>test</value> </property> </activation> .... </profile> <profile> <id>normal</id> .... </profile> <profile> <id>prod</id> .... </profile> </profiles> <!-- 配置属性,可选 --> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <junit.version>4.9</junit.version> ... </properties> <!-- 配置依赖 --> <!-- 依赖管理 --> <dependencyManagement> <dependencies> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <scope>test</scope> </dependency> ... </dependencies> </dependencyManagement> <!-- 依赖导入 --> <dependencies> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-core</artifactId> <version>1.7.1</version> <scope>compile</scope> <optional>false</optional> <!-- 排除传递的依赖 --> <exclusions> <exclusion> <groupId>org.apache.shiro</groupId> <artifactId>shiro-cache</artifactId> </exclusion> ... </exclusions> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> </dependency> ... </dependencies> <!-- 配置构建配置 --> <build> <finalName>pomlearn</finalName> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.xml</include> </includes> <excludes> <exclude>**/*.txt</exclude> <exclude>**/*.doc</exclude> </excludes> </resource> </resources> <!-- 插件管理配置 --> <pluginManagement> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-antrun-plugin</artifactId> <version>1.8</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> <warName>WebMavenLearn</warName> ... </configuration> <executions> <execution> <id>mavenlearn.meyok.cn</id> <phase>pre-clean</phase> <goals> <goal>run</goal> ... </goals> <configuration> <tasks> <echo>预清理阶段</echo> </tasks> </configuration> </execution> </executions> </plugin> ... </plugins> </pluginManagement> <!-- 插件配置 --> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId> </plugin> ... </plugins> </build> </project>
无论 POM 文件中是否显示的声明,所有的 POM 均继承自一个父 POM,这个父 POM 被称为 Super POM,它包含了一些可以被继承的默认设置。
有关POM的主要组成如下:
- 依赖
Maven依赖会从仓库里取。
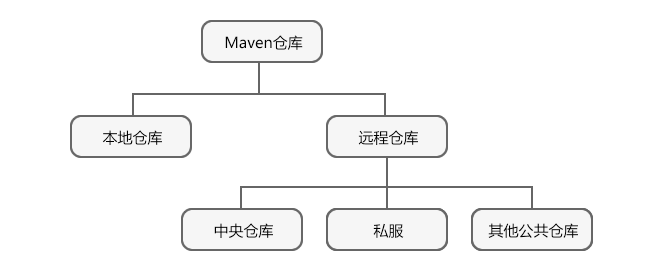
对于远程仓库:
- 中央仓库是由 Maven 社区提供的一种特殊的远程仓库,它包含了绝大多数流行的开源构件。在默认情况下,当本地仓库没有 Maven 所需的构件时,会首先尝试从中央仓库下载。
- 私服是一种特殊的远程仓库,它通常设立在局域网内,用来代理所有外部的远程仓库。它的好处是可以节省带宽,比外部的远程仓库更加稳定。
- 除了中央仓库和私服外,还有很多其他公共仓库,例如 JBoss Maven 库,Java.net Maven 库等等。
当 Maven 根据坐标寻找构件时,它会首先查看本地仓库,若本地仓库存在此构件,则直接使用;若本地仓库不存在此构件,Maven 就会去远程仓库查找(先是中央仓库,后是上述配置的远程仓库),若发现所需的构件后,则下载到本地仓库使用。如果本地仓库和远程仓库都没有所需的构件,则 Maven 就会报错。(如果在找寻的过程中,如果发现该仓库有镜像设置,则用镜像的地址代替。 如果仓库的id设置成“central”,则该配置会覆盖maven默认的中央仓库配置)
关于设置:
-
scope:用于设置依赖的范围,有以下值可取:
-
compile(默认值): 适用于所有阶段(开发、测试、部署、运行)。
-
provided:只在开发、测试阶段使用,目的是不让Servlet容器和你本地仓库的jar包冲突 。如servlet.jar。
-
runtime: 只在运行时使用,如JDBC驱动,适用运行和测试阶段。
-
test:只在测试时使用,用于编译和运行测试代码。不会随项目发布。
-
system: 类似provided,需要显式提供包含依赖的jar,Maven不会在Repository中查找它。
-
import:只能在 dependencyManagement 元素中使用,其功能是将目标 POM中 dependencyManagement 的配置导入当前POM。
注意:
-
非compile范围的依赖是不能传递的。
-
依赖版本按照路径最短者优先原则、路径相同先声明优先原则。
-
使用system还需要设置systemPath:
<systemPath>jar包地址</systemPath>
-
-
optional:表示该依赖是否传递给引用该项目坐标的项目,默认false表示传递。
- 构建
Maven有默认的插件目标与生命周期的阶段绑定,但可通过plugin配置进行修改。相关配置作用如下:
- id:自定义阶段id,任务的唯一标识。
- phase:插件目标需要绑定的生命周期阶段。
- goals:用于指定一组插件目标,其子元素 goal 用于指定一个插件目标。
- configuration:该任务的配置,其子元素 tasks 用于指定该插件目标执行的任务。
- Profile
Profile是为了在不同的环境定制不同的构建过程,防止开发环境,测试环境、生产环境等转变过程中不同的配置转变的复杂性。Profile 可以通过以下 6 种方式激活:
-
命令行激活
通过-P加id的方式命令行激活,多个id之间用逗号隔开,如
mvn clean install -Ptest。 -
settings.xml 文件显示激活
在本地仓库的settings.xml 添加如下代码进行激活:
<activeProfiles> <activeProfile>test</activeProfile> </activeProfiles> -
系统属性激活
如上述示例POM的test添加了如下配置,表示系统属性env存在,且值等 test 时,自动激活该 Profile。可使用
-Denv=test添加系统属性env为test。<activation> <property> <name>env</name> <value>test</value> </property> </activation> -
操作系统环境激活
如下所示,表示本地计算机操作系统环境信息如下所示激活:
<activation> <os> <name>Windows 10</name> <family>Windows</family> <arch>amd64</arch> <version>10.0</version> </os> </activation> -
文件存在与否激活
如下所示,表示对应文件存在、不存在时激活:
<activation> <file> <exists>./src/main/resources/env.prod.properties</exists> <missing>./src/main/resources/env.test.properties</missing> </file> </activation> -
默认激活
对应的Profile添加如下配置:
<activation> <activeByDefault>true</activeByDefault> </activation>
PS:
-
项目version后带“-SNAPSHOT”表示该项目为快照版本(开发版本,相比于发行版本),其它项目依赖该项目时,先从远程仓库查找是否存在版本是否更新(前部分version还是相等,对比的是Maven设置的更新时间戳),对比本地仓库进行相关操作后导入。
-
Maven继承的目的是为了消除 POM 中的重复配置,聚合的目的是为了方便快速的构建项目。两者打包类型(packaging)必须是 pom。
- 对于继承:父POM相对位置(relativePath)默认为 ../pom.xml,如果找不到,再从仓库中查找。子模块的 POM 中,当前模块的 groupId 和 version 元素可以省略,隐式的从父模块中继承这两个元素。
-
finalName指明了构建后的打包名,默认为
-
Maven常用构建环节命令(在pom.xml同级目录下执行
mvn ...):-
clean(清理):将以前编译得到的旧文件class字节码文件删除。
-
compile(编译):将java源程序编译成class字节码文件。
-
test(测试):自动测试,自动调用junit程序。
-
report(报告):测试程序执行的结果。
-
package(打包):动态Web工程打War包,java工程打jar包。
-
install(安装):将打包得到的文件复制到“仓库”中的指定位置。
-
deploy(部署):将动态Web工程生成的war包复制到Servlet容器下,使其可以运行。
-
-
Maven基本目录结构如下:
内容 路径 Java源代码 src/main/java 资源文件 src/main/resources 测试源代码 src/test/java 测试资源文件 src/test/resources 打包输出文件 target 编译输出文件 target/classes Maven 项目核心配置文件 pom.xml
1.1.6.代理模式
代理(Proxy)模式是一种结构型设计模式,提供了对目标对象另外的访问方式,即通过代理对象访问目标对象。这样做的好处是可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。
代理模式有三种类型,静态代理,动态代理(JDK代理,接口代理)、Cglib代理(在内存中动态的创建目标对象的子类)。
静态代理
静态代理要求目标对象继承某个目标接口,代理对象实现目标接口的所有方法。代理对象内含目标对象实例,实现方法时可调用目标对象的方法并在自己实现方法的过程中添加相应的操作,以达到增强目标对象的方法的目的。
静态代理虽然实现了对目标对象的功能扩展,但由于它要实现目标对象的所有方法,一旦目标接口增加方法,代理对象和目标对象都要进行相应的修改,增加维护成本。
动态代理
动态代理利用了Java的反射机制,在内存中动态创建代理对象中,加入自己的方法与反射获取到目标对象的方法。通过Proxy类的静态方法Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h);来获得代理对象,其中:
- loader:目标类的类加载器。
- interfaces:目标对象实现的接口。
- h:事件处理,执行目标对象的方法时,会触发事件处理器的方法,会把当前执行目标对象的方法作为参数传入。
示例:
Target类实现了ITarget接口,包含一个方法echo,实现为System.out.println("Target save method");。Advice类包含要增强的方法。代理类实现如下:
public class ProxyTest { public static void main(String[] args) { // 目标对象 final Target target = new Target(); // 通知 final Advice advice = new Advice(); Class<? extends Target> targetClass = target.getClass(); ITarget proxy = (ITarget) Proxy.newProxyInstance(targetClass.getClassLoader(), targetClass.getInterfaces(), new InvocationHandler() { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 前置增强 advice.before(); Object invoke = method.invoke(target, args); // 后置增强 advice.after(); return invoke; } }); proxy.echo(); } }
执行结果为:
advice before method Target echo method advice after method
JDK 动态代理有一个最致命的问题是它只能代理实现了某个接口的实现类,并且代理类也只能代理接口中实现的方法,要是实现类中有自己私有的方法,而接口中没有的话,该方法不能进行代理调用。
Cglib代理
Cglib代理是通过在内存中创建一个子类对象实现对目标对象功能的扩展。(需要cglib依赖)
示例:
Target类包含一个方法echo,为System.out.println("Target save method");。Advice类包含要增强的方法。代理类实现如下:
public class ProxyTest { public static void main(String[] args) { // 目标对象 final Target target = new Target(); // 通知 final Advice advice = new Advice(); //返回值 就是动态生成的代理对象 基于cglib //1.创建增强器 Enhancer enhancer = new Enhancer(); //2.设置父类(目标) enhancer.setSuperclass(Target.class); //3.设置回调 enhancer.setCallback((MethodInterceptor) (proxy, method, args1, methodProxy) -> { //执行前置 advice.before(); //执行目标 Object invoke = method.invoke(target, args1); //执行后置 advice.after(); return invoke; }); //4.创建代理对象 Target proxy = (Target) enhancer.create(); proxy.echo(); } }
// TODO 解决代码执行报错问题
1.1.7.JDBC
Java数据库连接 (JDBC) 是标准应用程序编程接口 (API) 的 JavaSoft 规范,它允许 Java 程序访问数据库管理系统。 JDBC API 由一组用 Java 编程语言编写的接口和类组成。使用这些标准接口和类,程序员可以编写连接到数据库的应用程序,发送以结构化查询语言 (SQL) 编写的查询,并处理结果。由于 JDBC 是一种标准规范,一个使用 JDBC API 的 Java 程序可以连接到任何数据库管理系统 (DBMS),只要该特定 DBMS 的驱动程序存在。
JDBC基本组成如下:
- JDBC驱动管理器(DriverManager):负责注册特定的JDBC驱动器。
- JDBC驱动器API:由Sun公司负责制定,搭个桥,其中最主要的接口是java.sql.Driver接口。
- JDBC驱动器(Driver):数据库驱动,由数据库厂商创建。实现JDBC驱动器API,负责与特定的数据库连接,以及处理通信细节。
实现
- 相关对象
-
DriverManager:驱动管理对象
1.注册驱动:告诉程序该使用
static void registerDriver(Driver driver):注册与给定的驱动程序 DriverManager
写代码使用:Class.forName("com.mysql.cj.jdbc.Driver");
通过查看源码发现:在com.mysql.jdbc.Driver类中存在静态代码块
java.sql.DriverManager.registerDriver(new Driver());
注意:mysql5之后的驱动jar包可以省略注册驱动的步骤。
2.获取数据库连接:
方法:static Connection getConnection(String url, String user, String passward)
参数:
url:指定连接的路径
语法(mysql):jdbc:mysql://ip地址(域名):端口号/数据库名称
细节:如果连接的时本机mysql服务器,并且mysql服务器默认端口是3306,则url可以简写为:jdbc:mysql:///db3
user:用户名
passward:密码 -
Connection:数据库连接对象
1.功能
1.获取执行sql的对象
Statement createStatement()
PreparedStatement prepareStatement(String sql)
2.管理事务
开启事务:void setAutoCommit(boolean autoCommit) :调用该方法设置参数为false,即开启事务
提交事务:void commit()
回滚事务:void rollback() -
Statement:执行sql对象
1.执行sql
1.boolean execute(String sql) :可以执行任意的sql,了解
2.int executeUpdate(String sql) :执行DML、DDL语句
返回值: DML:影响的行数,可以通过影响的行数判断DML语句是否执行成功
3.ResultSet executeQuery(String sql):执行DQL语句 -
ResultSet:结果集对象,封装查询结果
boolean next():游标向下移一行,返回值为是否为最后一行,是返回false
Xxx getXxx(parameter):获取数据
Xxx:表示数据类型
parameter:
int:代表列的编号,从1开始。
String:代表列的名称。 -
PreparedStatement:执行sql对象。
- 示例代码
首先需要我们导入MySQL连接依赖,名为mysql-connector-java。
以下执行查询年龄为10的javaweb_user_info表,User表含三个字段id(bigint unsigned)、gmt_create(datetime)、gmt_modified(datetime)、username(varchar(20))、age(tinyint unsigned)。
public class Test { public static void main(String[] args) { // 0.准备变量 Connection connection = null; Statement statement = null; ResultSet resultSet = null; List<UserDO> users = null; Integer age = 10; try { // 1.注册驱动 Class.forName("com.mysql.cj.jdbc.Driver"); // 2.获取数据库连接对象 connection = DriverManager.getConnection("jdbc:mysql:///demo", "******", "******"); // 3.定义sql语句 String sql = "SELECT * FROM javaweb_user_info WHERE age = "; // 4.获取执行sql的对象 Statement statement = connection.createStatement(); // 5.执行sql resultSet = statement.executeQuery(sql+age); // 6.处理结果 UserDO user = null; users = new ArrayList<UserDO>(); while(resultSet.next()){ Integer id = resultSet.getInt("id"); Date gmtCreate = resultSet.getTimestamp("gmt_create"); Date gmtModified = resultSet.getTimestamp("gmt_modified"); String username = resultSet.getString("username"); Integer age = resultSet.getInt("age"); user = new User(id, gmtCreate, gmtModified, username, age); users.add(user); } } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException throwables) { throwables.printStackTrace(); } finally { // 7.释放资源 if(resultSet != null){ try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } if(statement != null){ try { statement.close(); } catch (SQLException e) { e.printStackTrace(); } } if(connection != null){ try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } } System.out.println(users); } }
为了防止SQL注入,以下将会使用PreparedStatement而不是Statement重新编写步骤3-5:
PreparedStatement statement = null; // 3.定义sql语句 String sql = "SELECT * FROM javaweb_user_info WHERE age = ?"; // 4.获取执行sql的对象 prepareStatement statement = connection.prepareStatement(sql); statement.setInt(1, age); // 5.执行sql resultSet = statement.executeQuery(sql+age);
数据库连接池
实现数据连接的重用,减少连接时间。以下介绍C3P0连接池和Druid连接池。
- C3P0
需要导入c3p0相关依赖c3p0、machange-commons-java(c3p0依赖的包)。
- 配置
使用xml文件进行配置,举例如下(命名为c3p0-config.xml):
<?xml version="1.0" encoding="utf-8"?> <c3p0-config> <default-config> <property name="driverClass">com.mysql.cj.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/demo</property> <property name="user">******</property> <property name="password">******</property> <property name="initialPoolSize">5</property> <property name="maxPoolSize">10</property> <property name="checkoutTimeout">3000</property> </default-config> <named-config name="otherc3p0"> <property name="driverClass">com.mysql.cj.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/demo</property> <property name="user">******</property> <property name="password">******</property> <property name="initialPoolSize">5</property> <property name="maxPoolSize">8</property> <property name="checkoutTimeout">3000</property> </named-config> </c3p0-config>
- 调用
// 1.获得DataSource // 使用默认配置 DataSource ds = new ComboPooledDataSource(); // 使用指定名称配置 DataSource ds = new ComboPooledDataSource("otherc3p0"); // 2.获得Connection Connection connection = ds.getConnection(); // TODO 具体业务 connection.close();
- Druid
需要导入druid相关依赖druid。
- 配置
使用properties文件,举例如下(命名为druid.properties):
driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql://127.0.0.1:3306/demo username=****** password=****** initialSize=5 maxActive=10 maxWait=3000 maxIdle=8 minIdle=3
- 调用
// 1.获得DataSource // 配置 Properties pro = new Properties(); InputStream resourceAsStream = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"); pro.load(resourceAsStream); // 获取DataSource private static DataSource ds = DruidDataSourceFactory.createDataSource(pro); // 2.获得Connection Connection connection = ds.getConnection(); // TODO 具体业务 connection.close();
JDBCTemplate
JDBCTemplate封装了jdbc,再一次简化了java的数据库的使用。
需要导入JDBCTemplate相关依赖spring-jdbc、spring-tx(与事务相关)(待解决:commons-logging在这里的作用)。
使用方法,通过new JdbcTemplate(DataSource)得到JdbcTemplate对象即可调用相关方法,这里的DataSource参数可通过上述连接池获取。此后,只需编写好sql语句,然后调用JdbcTemplate对象的方法即可,示例如下:
public class Test { /** * update:DML * queryForMap:列名为key,值为value * queryForList:每行为一个map,再将map封装为list * query: * queryForObject: */ private JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource()); @Test public void demo1() { String sql = "UPDATE account SET balance = 5000 WHERE id = ?"; int count = template.update(sql, 1); System.out.println(count); } @Test public void demo2() { String sql = "SELECT * FROM account WHERE id = ? OR id = ?"; List<Map<String, Object>> maps = template.queryForList(sql, 1, 2); for(Map m : maps){ System.out.println(m); } } @Test public void demo3_1() { String sql = "SELECT * FROM account"; List<Account> query = template.query(sql, new RowMapper<Account>() { @Override public Account mapRow(ResultSet resultSet, int i) throws SQLException { Account account = new Account(); int id = resultSet.getInt("id"); String name = resultSet.getString("name"); double balance = resultSet.getDouble("balance"); account.setId(id); account.setName(name); account.setBalance(balance); return account; } }); for(Account q : query){ System.out.println(q); } } @Test public void demo3_2() { String sql = "SELECT * FROM account"; List<Account> query = template.query(sql, new BeanPropertyRowMapper<Account>(Account.class)); for (Account acc : query){ System.out.println(acc); } } @Test public void demo4() { String sql = "SELECT COUNT(?) FROM account"; Long count = template.queryForObject(sql, Long.class, "id"); System.out.println(count); } }
1.1.8.Jedis
Jedis是Redis官方推荐的Java连接开发工具。
PS:需要导入的包Jedis(Redis操作基本包)、common-pool2(连接池包)
基本使用
Jedis的基本使用非常简单,只需要创建Jedis对象的时候指定host,port, password即可。当然,Jedis对象又很多构造方法,都大同小异,只是对应和Redis连接的socket的参数不一样而已。
// 指定Redis服务Host和port Jedis jedis = new Jedis("localhost", 6379); // 如果Redis服务连接需要密码,制定密码 jedis.auth("******"); // TODO 操作jedis对象访问Redis服务 // 使用完关闭连接 jedis.close();
连接池
Jedis连接池是基于apache-commons pool2实现的。在构建连接池对象的时候,需要提供池对象的配置对象,及JedisPoolConfig(继承自GenericObjectPoolConfig)。我们可以通过这个配置对象对连接池进行相关参数的配置(如最大连接数,最大空数等)。
JedisPoolConfig config = new JedisPoolConfig(); config.setMaxIdle(8); config.setMaxTotal(18); JedisPool pool = new JedisPool(config, "127.0.0.1", 6379, 2000, "password"); Jedis jedis = pool.getResource(); // TODO 操作jedis对象访问Redis服务 jedis.close(); pool.close();
1.2.Front-End
1.2.1.浏览器架构
基本组件
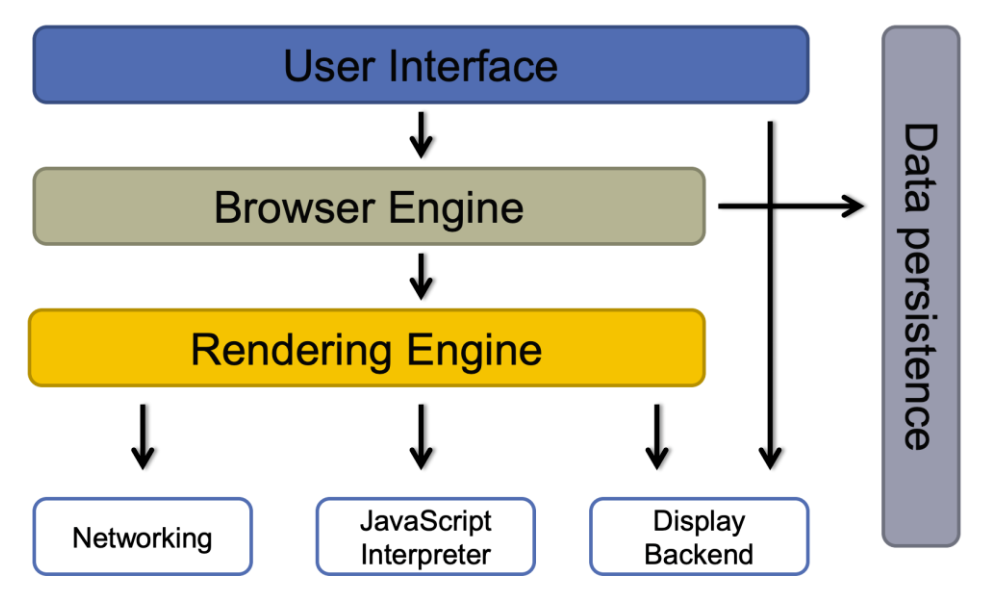
现代浏览器基本组件大致可以归纳成四部分:
- User Interface:提供用户与Browser Engine交互的方法,其中包括地址栏(address bar)、向前/退后按钮、书签菜单等等(除了 page 本身的内容,我们可以粗略地理解为打开一个空页面的时候呈现的界面就是浏览器的用户界面)。
- Browser Engine:协调(主控)UI和Rendering Engine,在他们之间传输指令。 提供对Rendering Engine的高级接口,一方面它提供初始化加载URL和其他高级的浏览器动作(如刷新、向前、退后等)方法,另一方面Browser Engine也为User Interface提供各种与错误、加载进度相关的消息。
- Rendering Engine:为给定的URL提供可视化的展示。它解析HTML、CSS、JavaScript,包含了一个compositor(合成器)和Javascript Engine(JS解释引擎),分别是负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上和用于解析和执行 JavaScript 代码。 值得注意的是,不同的浏览器使用不同的Rendering Engine,例如IE使用Trident、Firefox使用Gecko、Safai使用Webkit、Chrome和Opera使用Webkit(以前是Blink)。
- 后端服务:网络、数据存储如Cookie、Storage等。
- Networking:基于互联网HTTP和FTP协议,处理网络请求。网络模块负责Internet communication and security,character set translations and MIME type resolution。另外网络模块还提供获得到文档的缓存,以减少网络传输。为所有平台提供底层网络实现,其提供的接口与平台无关。
- JavaScript Interpreter:解释和运行网站上的js代码,得到的结果传输到Rendering Engine来展示。
- UI Backend:用于绘制基本的窗口小部件,比如组合框和窗口。而在底层使用操作系统的用户界面方法,并公开与平台无关的接口。
渲染引擎工作流程
渲染引擎的主要工作都是以HTML/JavaScript/CSS等文件作为输入,以可视化内容作为输出。不同的渲染引擎,主要在一些css的支持性上和渲染表现上不同。
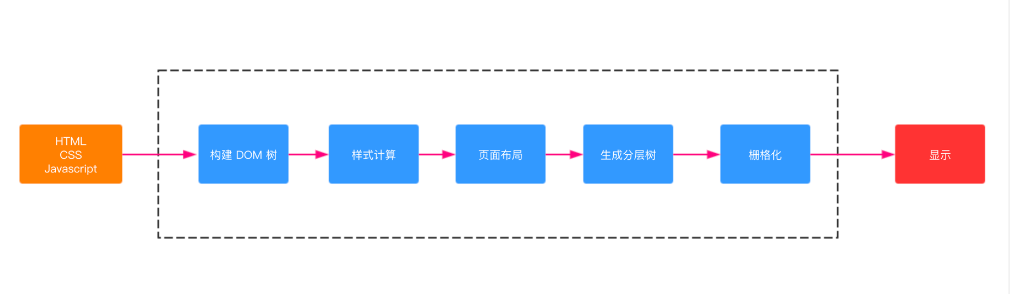
- 渲染进程将 HTML 内容转换为能够读懂DOM树结构。
- 渲染引擎将CSS样式表转化为浏览器可以理解的styleSheets,计算出 DOM 节点的样式。
- 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
浏览器的多进程架构
不同的浏览器使用不同的架构,可以是一个单进程多线程的应用程序,也可以是一个使用IPC通信的多进程应用程序。这里以Chrome为例,介绍浏览器的多进程架构。
在Chrome中,主要的进程有4个:
- Browser Process(浏览器进程):负责浏览器的TAB的前进、后退、地址栏、书签栏的工作和处理浏览器的一些不可见的底层操作,比如网络请求和文件访问。
- Renderer Process(渲染进程 ):负责一个Tab内的显示相关的工作,也称渲染引擎。
- Plugin Process(插件进程):负责控制网页使用到的插件
- GPU Process(GPU进程 ):负责处理整个应用程序的GPU任务
这4个进程之间的关系是什么呢?首先,当我们是要浏览一个网页,我们会在浏览器的地址栏里输入URL,这个时候Browser Process会向这个URL发送请求,获取这个URL的HTML内容,然后将HTML交给Renderer Process,Renderer Process解析HTML内容,解析遇到需要请求网络的资源又返回来交给Browser Process进行加载,同时通知Browser Process,需要Plugin Process加载插件资源,执行插件代码。解析完成后,Renderer Process计算得到图像帧,并将这些图像帧交给GPU Process,GPU Process将其转化为图像显示屏幕。
多进程架构的优点:
- 更高的容错性:当今WEB应用中,HTML,JavaScript和CSS日益复杂,这些跑在渲染引擎的代码,频繁的出现BUG,而有些BUG会直接导致渲染引擎崩溃,多进程架构使得每一个渲染引擎运行在各自的进程中,相互之间不受影响,也就是说,当其中一个页面崩溃挂掉之后,其他页面还可以正常的运行不收影响。
- 更高的安全性和沙盒性(sanboxing):渲染引擎会经常性的在网络上遇到不可信、甚至是恶意的代码,它们会利用这些漏洞在你的电脑上安装恶意的软件,针对这一问题,浏览器对不同进程限制了不同的权限,并为其提供沙盒运行环境,使其更安全更可靠
- 更高的响应速度:在单进程的架构中,各个任务相互竞争抢夺CPU资源,使得浏览器响应速度变慢,而多进程架构正好规避了这一缺点。
1.2.2.HTML
HTML(HyperText Markup Language)是用于构建网页及其内容的代码。一种定义内容结构的标记语言。 HTML 由一系列元素组成,您可以使用这些元素来封装或包装内容的不同部分,以使其以某种方式出现或以某种方式发挥作用。 封闭标签可以使单词或图像超链接到其他地方,可以使单词斜体,可以使字体更大或更小,等等。
基本结构
<!DOCTYPE html> <html lang="ch"> <head> <meta charset="UTF-8"> <title>title</title> </head> <body> ... </body> </html>
body标签
-
文本标签
-
注释 :
<!-- 注释内容 --> -
换行:
<br/> -
标题:
<h1>标题内容</h1>(可选h1-h6) -
段落:
<p>段落内容</p> -
水平线:
<hr color="red" width="200" size="10" align="left"/> -
加粗字体:
<b>内容</b> -
倾斜字体:
<i>内容</i> -
字体标签:
<font color="red" size="5" face="楷体"><center>内容 ©®</center></font>
-
-
图片标签
<img src="../image/feiwu.jpeg" align="right" alt="image1" width="500" height="300"/>
-
列表标签
- 有序列表:ol
<ol type="A" start="2"> <li>睁眼</li> <li>看手机</li> <li>穿衣服</li> <li>洗漱</li> </ol> - 无序列表:ul
<ul type="square"> <li>睁眼</li> <li>看手机</li> <li>穿衣服</li> <li>洗漱</li> </ul> -
链接标签
<a href="https://www.baidu.com/" target="_blank">链接</a>
-
块标签
-
div:每个div占满一整行
<div>div块</div> -
span:文本信息在一行显示
<span>span块</span>
-
-
语义化标签
-
页头:
<header>内容</header> -
页尾:
<footer>内容</footer>
-
-
表格标签
<table border="1" width="50%" cellpadding="0" cellspacing="0" bgcolor="#AA7755" align="center"> <thead> <caption>学生信息表</caption> <tr> <th>编号</th> <th>姓名</th> <th>成绩</th> </tr> </thead> <tbody> <tr bgcolor="#223344" align="center"> <td>1</td> <td>小龙女</td> <td colspan="3">100</td> </tr> <tr> <td>2</td> <td>杨过</td> </tr> </tbody> <tfoot> <tr> <td>3</td> <td>尹志平</td> </tr> </tfoot> </table>
- 表单标签
<form action="#" method="post"> 用户名:<input name="username"><br> 密码:<input name="password"><br> <input type="submit" value="登录"> </form>
form用于定义表单。可以定义一个范围,范围代表采集用户数据的范围。其属性action用于指定提交数据的URL,method指定提交方式。表单项中的数据要想被提交,必须指定name属性。
method提交方式共7种,常用2种:
- get
- 请求参数会在地址栏中显示,封装在请求行中。
- 请求参数大小有限制
- 不太安全
- post
- 请求参数不会在地址栏中显示,封装在请求体中
- 请求参数大小无限制
- 较为安全
对于表单中的表单项列举如下:
<form action="#" method="post"> <label for="username"> 用户名:</label><input type="text" name="username" value="root" id="username"><br> 密码:<input type="password" name="password" placeholder="请输入密码"><br> 性别:<input type="radio" name="gender" value="male" checked="checked"> 男 <input type="radio" name="gender" value="female"> 女 <br> 爱好:<input type="checkbox" name="hobby" value="Java" checked="checked"> Java <input type="checkbox" name="hobby" value="Python"> Python <input type="checkbox" name="hobby" value="C"> C <br> 图片:<input type="file" name="file"><br> 隐藏域:<input type="hidden" name="id" value="aa"><br> 取色器:<input type="color" name="color"><br> 生日:<input type="date" name="birthday"><br> 生日:<input type="datetime-local" name="birthday"><br> 邮箱:<input type="email" name="email"><br> 年龄:<input type="number" name="age"><br> 省份:<select name="province"> <option value="" selected>--请选择--</option> <option value="1">北京</option> <option value="2">上海</option> </select><br> 自我描述:<textarea cols="20" rows="5"></textarea><br> <input type="submit" value="登录"><br> <input type="button" value="一个按钮"><br> <input type="image" src="../image/demo.jpg"><br> </form>
1.2.3.CSS
CSS(Cascading Style Sheets)是我们用来设置 HTML 文档样式的语言。
CSS与HTML结合
结合方式可分为以下三种:
- 内联样式:在标签内使用style属性指定css代码。
<div style="color:red;"> hello css </div>
- 内部样式:在head标签内定义style标签,style标签的标签体内容即是css代码。
<style> div{ color:blue; } </style>
-
外部样式:定义css资源文件后,在head标签内,定义link标签,引入外部的资源,或者使用import导入。
准备css资源文件demo.css:
div{ color:pink; } p{ color:red; font-size:30px; } html文件引入:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>CSS与HTML结合</title> <link rel="stylesheet" href="../css/demo.css"> <!--<style> @import "../css/demo.css"; </style>--> </head> <body> <div> hello css </div> <p> hello css </p> </body> </html>
选择器
- 基础选择器
-
id选择器(#id属性值):选择器具体的id属性值的元素
-
元素选择器(标签名)
-
类选择器(.+类名)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>基础选择器</title> <style> #id_name { color:red; } div { color:green; } .cls_college { color:blue; } </style> </head> <body> <div id="id_name">meyok</div> <div>UESTC</div> <p class="cls_college">SE</p> </body> </html>
PS:覆盖规则id>类>元素。
- 拓展选择器
-
选择所有元素(*{})
-
并集选择器(选择器1,选择器2{})
-
子选择器(选择器1 选择器2{}):筛选选择器1元素下的选择器2元素
-
父选择器(选择器1>选择器2{}):筛选选择器2的父选择器1
-
属性选择器(元素名称[属性名="属性值"]{}):选择元素名称,属性名=属性值的元素
-
伪类选择器(状态{})
如
<a>标签有4种状态:link(初始化的状态)、visited(被访问过的状态)、active(正在访问的状态)、hover(鼠标悬浮状态)。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>扩展选择器</title> <style> div p{ color:red; } div>p{ border:1px solid; } input[type="text"]{ border:5px solid; } a:link{ color:pink; } </style> </head> <body> <div> <p>meyok</p> </div> <p>UESTC</p> <div>SE</div> <input type="text"> <input type="password"> <br> <a href="#">link</a> </body> </html>
属性
-
字体
color:#FF0000; font-size:30px; text-align:center; line-height:40px; -
边框
border:1px solid red; -
尺寸
height:200px; width:200px; -
背景
background:url("../image/demo.jpeg") no-repeat center;
1.2.4.ECMAScript(JavaScript)
ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会)在标准ECMA-262中定义的脚本语言规范。这种语言在万维网上应用广泛,它往往被称为JavaScript或JScript,但实际上后两者是ECMA-262标准的实现和扩展。
JS与HTML结合
- 内部JS:在head的script标签中添加内容即可。
- 外部JS:在head的script标签添加src属性即可。
// demo.js alert("我是外部的js文件");
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <script> alert("Hello World"); </script> <script src="../js/demo.js"></script> </head> <body> </body> </html>
对象
- Function
// 1.Function创建,参数为参数、方法体 var fun1 = new Function("a", "b", "alert(a+b);"); fun1(1, 2); alert(fun1.length); // 2.直接创建 function fun2(a, b){ alert(a+b); } fun2(3, 4); // 3.返回值创建 var fun3 = function(a, b){ alert(a+b); } fun3(5, 6); // 4.自己创建(不指定参数) function fun4(){ var sum = 0; for (var i = 0; i < arguments.length; ++i){ sum += arguments[i]; } return sum; } alert(fun4(7, 8, 9));
- Array
var arr1 = new Array(1, 2, 3); var arr2 = [1, 2, 3, 4]; document.write(arr1+"<br>"); document.write(arr2+"<br>"); var arr = new Array(1, "abc", true); document.write(arr+"<br>"); document.write(arr[0]+"<br>"); document.write(arr[3]+"<br>"); document.write(arr.join()+"<br>"); document.write(arr.join("--")+"<br>"); arr.push(11); document.write(arr+"<br>");
- Date
var date = new Date(); document.write(date+"<br>"); document.write(date.toLocaleString()+"<br>"); document.write(date.getTime()+"<br>");
- Math
document.write(Math.PI+"<br>"); document.write(Math.random()+"<br>"); document.write(Math.round(3.14)+"<br>"); //四舍五入 document.write(Math.ceil(3.14)+"<br>"); //向上取整 document.write(Math.floor(3.14)+"<br>"); //向下取整
- RegExp
var reg1 = new RegExp("^\\w{6,12}$"); var reg2 = /^\w{6,12}$/; var username = "zhangsan"; document.write(reg1.test(username));
- Global
// encodeURIComponent和decodeURIComponent编码的字符更多 var str = "船只"; var encode = encodeURI(str); document.write(encode+"<br>"); var s = decodeURI(encode); document.write(s+"<br>"); var str1 = "123"; document.write(parseInt(str1)+"<br>"); var str2 = "123abc"; document.write(parseInt(str2)+"<br>"); var str3 = "abc123"; document.write(parseInt(str3)+"<br>"); var num = NaN; document.write((num == NaN)+"<br>"); document.write(isNaN(num)+"<br>"); var jscode = "alert(123)"; eval(jscode);
Document Object Model
<!-- 1.获得HTML元素 --> var x = document.getElementById("intro"); var y = document.getElementsByTagName("p"); var x = document.getElementsByClassName("intro"); <!-- 2.改变HTML内容 --> document.write(new Date()) document.getElementById(id).innerHTML = 新的HTML内容 document.getElementById(id).attribute = 新属性值 // attribute为属性名称 ...
Browser Object Model
HTML DOM 的 document 也是 window 对象的属性之一。
<!-- 获取窗口宽度与高度 --> var w = window.innerWidth; var h = window.innerHeight; window.open() // 打开新窗口 window.close() // 关闭当前窗口 window.moveTo() // 移动当前窗口 window.resizeTo() // 调整当前窗口的尺寸 location.hostname // 返回web主机的域名 location.pathname // 返回当前页面的路径和文件名 location.port // 返回web主机的端口(80或443) location.protocol // 返回所使用的web协议(http:或https:) location.href // 属性返回当前页面的URL location.assign() // 方法加载新的文档 location.reload() history.back() // 方法加载历史列表中的前一个 URL history.forward() // 方法加载历史列表中的下一个 URL window.alert("警告框"); window.confirm("确认框"); window.prompt("提示框"); setInterval() // 间隔指定的毫秒数不停地执行指定的代码 setTimeout() // 在指定的毫秒数后执行指定代码 clearInterval() // 方法用于停止setInterval()方法执行的函数代码 clearTimeout() // 方法用于停止执行setTimeout()方法的函数代码 document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT; path=/";
1.2.5.jQuery
jQuery是一个快速、简洁的JavaScript框架。
自定义JS框架
在demo.js中,我们自定义了一个通过id获取组件的函数:
function $(id){ let obj = document.getElementById(id); return obj; }
那么在导入该js后,就可以调用我们的方法:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>自定义js框架</title> <script src="js/demo.js"></script> </head> <body> <div id="div">div1...</div> <script> let div = $("div") alert(div.innerHTML); </script> </body> </html>
jQuery语法
导入jQuery的js文件,就可调用jQuery框架。
-
选择器
-
基本选择器
jQuery可通过id、tag、class来获取元素,方法分别为
$("#id")、$("tag")、$(".class")。(混合使用中间加逗号)jQuery对象在操作时,比JS方法更加方便。jQuery对象和JS对象方法不通用,两者相互转化方法如下:
- jq --> js : jq对象[索引] 或者 jq对象.get(索引)
- js --> jq : &(js对象)
-
属性选择器
$("div[title]"):含有属性title的div元素。$("div[title='test']"):属性title值等于test的div元素。$("div[title!='test']"):属性title值不等于test的div元素(没有属性title的也将被选中)。$("div[title^='te']"):属性title值以te开始的div元素。$("div[title$='est']"):属性title值以est结束的div元素。$("div[title*='test']"):属性title值含有es的div元素。$("div[id][title*='es']"):选取有属性id的div元素,然后在结果中选取属性title值含有“es”的div元素。
-
层级选择器
$("body div"):选取<body>内所有<div>。$("body > div"):选取<body>内子<div>。
-
过滤选择器
$("div:first"):选取第一个div元素。$("div:last"):选取最后一个div元素。$("div:not(.one)"):选取class不为one的所有div元素。$("div:even"):选取索引值为偶数的div元素。$("div:odd"):选取索引值为奇数的div元素。$("div:gt(3)"):选取索引值为大于3的div元素。$("div:eq(3)"):选取索引值为等于3的div元素。$("div:lt(3)"):选取索引值为小于3的div元素。$(":header"):选取所有的标题元素。
-
表单过滤选择器
$("input[type='text']:enabled"):选取可用 <input type='text'> 元素。$("input[type='text']:disabled"):选取不可用 <input type='text'> 元素。$("input[type='checkbox']:checked"):选取已选 <input type='checkbox'> 元素。(可利用length获取复选框选中的个数)$("#job > option:selected"):选取下拉框已选中元素。(可利用length获取下拉框选中的个数)
-
-
jQuery入口函数
DOM文档加载完成之后执行该函数中的代码,格式为:
$(function (){ // 函数内容 }); 注意:window.onload只能定义一次,如果定义多次,后边的会将前边的覆盖掉。$(function)可以定义多次。
-
DOM操作
- 获取/修改元素属性value值:
$("...").val(["值"]) - 获取/修改标签体内容:
$("...").html(["值"]) - 获取/修改文本内容:
$("...").text(["值"]) - 获取/修改/新增元素属性:
$("...").attr("属性名"[, "值"]) - 删除/检验是否存在元素属性:
$("...").remove("属性名") - 获得选中状态:
$("...").prop("checked"),prop是用来操作固有属性的,自定义属性使用attr。 - 添加/删除/开启class:
$("...").addClass("类名")、$("...").removeClass("类名")、$("...").toggleClass("类名")。 - 获取/修改CSS样式:
$("...").css("css键名"[, "值"])。 - 对象添加操作
- 对象1.append(对象2)/对象1.prepend(对象2):对象2添加到对象1内部末尾/开头
- 对象1.appendTo(对象2)/对象1.prependTo(对象2):对象1添加到对象2内部末尾/开头
- 对象1.after(对象2)/对象1.before(对象2):对象2添加到对象1后边/前边
- 对象1.insertAfter(对象2)/对象1.insertBefore(对象2):对象1添加到对象2后边/前边
- 对象.remove():移除元素
- 对象.empty():清空元素的所有后代元素,但是保留当前对象以及其属性节点
- 删除节点:
$("...").remove()。
- 获取/修改元素属性value值:
-
jQuery高级
-
jQuery动画
- speed:动画速度,可以是“slow”、“normal”、“fast”或毫秒数。
- easing:指定切换效果,默认“swing”(动画执行时先慢后快再慢),可用参数“linear”(匀速)。
- fn:在动画完成时执行的函数,每个元素执行一次。
列举如下:
<script> function showFn() { $("#showDiv").show("slow", "swing", function() { alert("显示了……") }); $("#showDiv").show(5000, "swing"); $("#showDiv").slideDown("slow"); $("#showDiv").fadeIn("slow"); } function hideFn() { $("#showDiv").hide("slow", "linear"); $("#showDiv").slideUp("slow"); $("#showDiv").fadeOut("slow"); } function toggleFn() { $("#showDiv").toggle("slow"); $("#showDiv").slideToggle("slow"); $("#showDiv").fadeToggle("slow"); } </script> -
jQuery遍历
- js方式:for(初始化值;循环结束条件;步长)。
- jq方式:
- jq对象.each(callback)
- $.each(object, [callback])
- for..of : jq3.0后提供的方式
列举如下:
<script type="text/javascript"> $(function() { let citys = $("#city li"); for (let i = 0; i < citys.length; i++) { if("上海" == citys[i].innerHTML) { break; } alert(i+":"+citys[i].innerHTML); } citys.each(function() { alert(this.innerHTML); }); citys.each(function(index, element) { if("上海" == $(element).html()) { return true; //return false;退出循环。return true;继续循环的下一次 } // alert(index+":"+element.innerHTML); alert(index+":"+$(element).html()); }); $.each(citys, function() { alert($(this).html()); }); for(li of citys) { alert($(li).html()); } }); </script> -
jQuery事件绑定与解绑
- jq标准的绑定方式:jq对象.事件方法(回调函数);
- on绑定事件/off解除事绑定:jq对象.on("事件名称", 回调函数);jq对象.off("事件名称");
- 事件切换:jq对象.toggle(fn1, fn2...);
列举如下:
<script type="text/javascript"> $(function() { $("#name").click(function() { alert("我被点击了。。。"); }); $("#name").mouseover(function() { alert("鼠标来了。。。"); }); $("#name").mouseout(function() { alert("鼠标走了。。。"); }); $("#name").mouseover(function() { alert("鼠标来了。。。"); }).mouseout(function() { alert("鼠标走了。。。"); }); alert("我要获得焦点了"); $("#name").focus(); }); $(function() { $("#btn").on("click", function() { alert("我被点击了。。。") }); $("#btn2").click(function() { $("#btn").off("click"); // $("#btn").off(); //解除所有 }); }); // jq1.9版本后删除了toggle,可使用Migrate插件恢复此功能。 // <script src="../js/jquery-migrate-1.0.0.js" type="text/javascript" charset="utf-8"></script> $(function() { $("#btn").toggle(function( ){ $("#myDiv").css("backgroundColor", "pink"); }, function() { $("#myDiv").css("backgroundColor", "blue"); }); }); </script> -
jQuery的插件
插件增强jQuery的功能,实现方式如下:
$.fn.extend(object):增强通过jQuery获取的对象的功能 $("#id")$.extend(object):增强jQuery对象自身的功能 $/jQuery
列举如下:
<script type="text/javascript"> //使用jQuery插件,给jq对象添加2个方法,check()选中所有复选框,uncheck()取消选中所有复选框 // 1.定义jquery的对象插件 $.fn.extend({ //定义了一个check()方法。所有的jq对象都可以调用该方法 check:function (){ //让复选框选择 //this:调用该方法的jq对象 this.prop("checked", true); }, uncheck:function (){ //让复选框不选中 this.prop("checked", false); } }); $(function (){ $("#btn-check").click(function (){ $("input[type='checkbox']").check(); }); $("#btn-uncheck").click(function (){ $("input[type='checkbox']").uncheck(); }); }); </script> <script type="text/javascript"> //对全局方法扩展2个方法,扩展min方法:求2个值的最小值;扩展max方法:求2个值最大值 $.extend({ max:function (a, b){ return a>=b ? a : b; }, min:function (a, b){ return a<=b ? a : b; } }); let max = $.max(3, 5); alert(max); let min = $.min(4, 7); alert(min); </script>
-
AJAX
AJAX是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
-
原生js实现AJAX
示例如下:
<script> // 定义方法 function fun(){ // 发送异步请求 // 1.创建核心对象 var xhttp; if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else { // code for IE6, IE5 xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } // 2.建立连接 /* 参数: 1.请求方式:GET,POST get方式:请求参数在URL后拼接,send方法空参 post方式:请求参数在send方法中定义 2.请求的URL 3.同步或异步请求,true异步,false同步 */ xhttp.open("GET", "ajaxServlet?username=Tom", true); // 3.发送请求 xhttp.send(); // xhttp.send("username=Tom"); // 4.接受并处理来自服务器的响应结果 // 获取方式:xhttp.responseText // 当服务器响应成功后再获取 // 当xhttp对象的就绪状态改变时,触发事件onreadystatechange。 xhttp.onreadystatechange = function() { // 判断readyState就绪状态是否为4,判断status响应状态码是否为200 if (this.readyState == 4 && this.status == 200) { // 获取服务器的响应结果 let responseText = xhttp.responseText; alert(responseText); } }; } </script> -
jQuery实现AJAX方式
<script> // 定义方法 function fun() { // 使用$.ajax()发送异步请求 $.ajax({ // 请求路径 url:"ajaxServlet", // 请求方式,默认GET type:"POST", // 请求参数,一般用Json // data:"username=Jack&age=23" data:{"username": "jack", "age": 23}, // 响应成功后的回调函数 success:function(data) { alert(data); }, // 响应出错会执行的函数 error:function() { alert("出错了。。。") }, // 设置接受到的响应数据格式 dataType:"text" }); } </script> <script> //定义方法 function fun() { $.get("ajaxServlet", {username: "root"}, function(data) { alert(data); }, "text"); } </script> <script> //定义方法 function fun() { $.post("ajaxServlet", {username: "root"}, function(data) { alert(data); }, "text"); } </script>
1.4.文件
1.4.1.XML
XML (Extensible Markup Language)指可扩展标记语言,用于信息的记录和传递,因此XML经常被用于充当配置文件。XML 的优势之一,就是可以在不中断应用程序的情况下进行扩展。
基本组成
- XML声明:定义XML版本和编码信息。
- 注释:
<!-- 注释内容 -->。 - 元素:由开始标签、元素内容、结束标签组成。(根元素有且仅有一个根元素。)
- 属性:处于开始标签内,提供关于元素的额外(附加)信息。
示例:
<?xml version="1.0" encoding="utf-8" ?> <users> <user id="1"> <name>Tom</name> <age>23</age> <gender>male</gender> </user> <user id="2"> <name>Mary</name> <age>24</age> <gender>female</gender> </user> </users>
语法规则
-
XML 声明文件的可选部分,如果存在需要放在文档的第一行,如下所示:
-
XML 标签对大小写敏感。
-
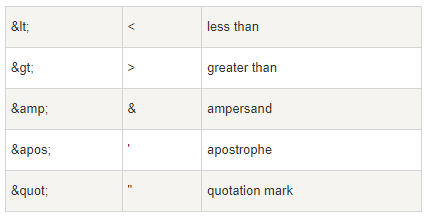
XML 中预定义的实体引用:
-
XML 属性值必须加引号。
-
在 XML 中,空格会被保留,多个连续的空格字符裁减(合并)为一个。
-
XML 以 LF 存储换行。
XML解析
XML解析方式分为两种:DOM(Document Object Model)和SAX(Simple API for XML)。这两种方式不是针对Java语言来解析XML的技术,而是跨语言的解析方式。例如DOM还在JavaScript中存在。
-
DOM
使用DOM要求解析器把整个XML文档装载到一个Document对象中。Document对象包含文档元素,即根元素,根元素包含N个子元素。一个XML文档解析后对应一个Document对象,这说明使用DOM解析XML文档方便使用,因为元素与元素之间还保存着结构关系。
-
SAX
DOM会一行一行的读取XML文档,最终会把XML文档所有数据存放到Document对象中。SAX也是一行一行的读取XML文档,但是当XML文档读取结束后,SAX不会保存任何数据,同时整个解析XML文档的工作也就结束了。
但是,SAX在读取一行XML文档数据后,就会给感兴趣的用户一个通知。例如当SAX读取到一个元素的开始时,会通知用户当前解析到一个元素的开始标签。而用户可以在整个解析的过程中完成自己的业务逻辑,当SAX解析结束,不会保存任何XML文档的数据。
大多数浏览器都内建了供读取和操作 XML 的 XML 解析器,解析器把 XML 转换为 JavaScript 可存取的对象(XML DOM)。下面的 JavaScript 片段加载一个 XML 文档("books.xml")获得对应的XML DOM:
if (window.XMLHttpRequest) { // IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码 xhttp = new XMLHttpRequest(); } else { // IE6, IE5 浏览器执行代码 xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET","books.xml",false); xhttp.send(); xmlDoc = xhttp.responseXML;
命名空间
命名空间是一套XML元素和它们的构成属性。命名空间通过将元素和属性放入逻辑区域并分别提供区分元素和属性得的方式,将元素组织在一起。命名空间还用来引用特定的DTD或者XML Schema。
声明一个命名空间需要三个部分:
-
xmlns:指定值作为XML的命名空间,他是声明空间必须的,而且可以附加在任何XML元素上。
-
prefix:指定一个命名空间前缀。它(包括冒号)只用于声明一个命名空间前缀。如果使用了这个前缀,那么在文档中使用该前缀(prefix:element)的任何元素都被认为是位于声明命名空间范围内。
-
NamespaceURI :这是唯一的标识符,必需且必须定义在单个引号或者双引号之内。该值不必指向一个Web资源,它只有一个具有符号意义的标识符。
命名空间名称是并不需要指向任何事物的 URL,它并不等同于Web地址,比如如果您访问XSLT命名空间(http://www.w3c.org/1999/XSL/Transform),你将发现只有一句话:“这是一个由XSL 转换(XSLT)1.0 规范定义的XML命名空间”。唯一的标识符只是一个符号,因此对文档来说就不需要定义了。URL 是为了命名空间名称而选择的,因为它们包含了可以在全球 Internet上使用的域名并且是唯一的。
可以使用两 种不同的方式定义一个命名空间:
- 默认命名空间:使用不带前缀的 xmlns 属性来定义命名空间,并且所有子元素都被认为是属于已定义的命名空间。默认命名空间就是一个让XML文档更具可读性且更易于写入的工具。如果您打算在文档系统中统一使用一个命名空间,那么利用这个命名空间的前缀就能很容易地消除每个元素的前缀。放在名称空间http://www.test.com/ns/ns_test里。
- 带有前缀的命名空间:使用带有前缀的 xmlns 属性来定义命名空间。当前缀附加在一个元素之前时,认为它属于那个命名空间。
XML验证
DTD或者XML Schema可以定义XML文件标签规范从而实现XML验证。
- DTD(Document Type Definition)
DTD是一套为了进行程序间的数据交换而建立的关于标记符的语法规则,根据使用方式DTD可以分为内部DTD和外部DTD:
-
内部dtd:将约束规则定义在xml文档中。此时,XML声明中的standalone属性必须设置为yes,它表示声明的工作独立于外部源。
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE 根标签名 [ declaration1 declaration2 ... ]> ... -
外部dtd:将约束规则定义在外部的dtd文档中。此时,必须将XML声明中的standalone属性设置为no,它表示声明包括来自外部源的信息。
-
本地:
<!DOCTYPE 根标签名 SYSTEM "dtd文件位置"><?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <!DOCTYPE students SYSTEM "student.dtd"> SYSTEM 关键字表示文档使用的是私有的DTD 文件,dtd文件位置可以是相对URI或者绝对 URI。
-
网络:
<!DOCTYPE 根标签名 PUBLIC "DTD的名称" "外部DTD文件的URI"><!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd"> PUBLIC 关键字用于声明公共的 DTD,并且这个 DTD 还有一个名称,"DTD 的名称"也称为公共标识符(public identifier)。这个DTD 可以存放在某个公共的地方,XML处理程序会根据名称按照某种方式去检索 DTD,如果XML处理器不能根据名称检索到DTD,就会使用"外部DTD文件的URI"来查找该DTD。
PS:公共DTD名称要遵守一些约定。如果一项DTD是ISO标准,它的名称要以字符串"ISO"开始。如果是一个非ISO的标准组织批准的DTD,它的名字以加号(+)开始。如果不是标准组织批准的DTD,它的名称以连字符(-)开始。这些开始字符或字符串后接双斜杠(//)和DTD所有者的名字(比如上面例子的 Sun Microsystems,Inc.),之后是另一个双斜杠和DTD 描述的文档类型,接着又是一个双斜杠后接ISO639语言标识符,如EN表示英语,ZH表示中文。
-
declaration语法如下:
-
元素
元素是XML文档的基本组成部分,在DTD定义中,每一条<!ELEMENT…>语句用于定义一个元素,其基本的语法格式如下所示:
<!ELEMENT 元素名称 元素内容> 其中,“元素名称”是自定义的名称,它用于定义被约束XML文档中的元素。“元素内容”是对元素包含内容的声明,包括数据类型和符号二部分,它共有五种内容形式。
数据类型规则具体如下:
-
PCDATA(Parsed Character Data):表示元素中嵌套的内容是普通文本字符串。如
<!ELEMENT name (#PCDATA)>。 -
子元素:说明元素必须包含的元素。如
<!ELEMENT student (name)>。上述两种用括号包围,表示一个组合,纯子元素可用逗号隔开(限制了顺序),#PCDATA与子元素、子元素与子元素之间可用竖线隔开,表示或。如```
<!ELEMENT note (to,from,header,(message|body))>、<!ELEMENT note (#PCDATA|to|from|header|message)>。 -
EMPTY:表示该元素既不包含字符数据,也不包含子元素,是一个空元素。
-
ANY:表示该元素可以包含任何的字符数据和子元素。
可以在上述单个规则或组合规则后加符号,符号规则具体如下:
- 问号(?):表示该对象可以出现0次或1次。
- 星号(*):表示该对象可以出现0次或多次。
- 加号(+):表示该对象可以出现1次或多次。
-
-
属性
在DTD文档中,定义元素的同时,还可以为元素定义属性。DTD属性定义的基本语法格式如下所示:
<!ATTLIST 元素名称 属性名1 属性类型 设置说明 属性名2 属性类型 设置说明 ...... > 其中,“元素名”是属性所属元素的名字,“属性名”是属性的名称,“属性类型”则是用来指定该属性是属于哪种类型,“设置说明”用来说明该属性是否必须出现。
设置说明规则具体如下:
- REQUIRED:属性必需。
- IMPLIED:属性非必需。
- FIXED value:属性值为固定value。
- value:属性默认值value,其后XML文件可修改。
属性类型规则具体如下:
-
CDATA:表明属性类型是字符数据。
-
(en1|en2|...):属性为枚举类型,从en1、en2、...中取值。如下所示。
<!ATTLIST sport value (basketball|football|ping-pong) "basketball" > -
ID:表明值为唯一的 id,其属性值必须遵守XML名称定义的规则。说明规则只能设置为#IMPLIED或#REQUIRED。
-
IDREF和IDREFS
限制值为已设为ID的值,IDREF为一对一,IDREFS为一对多,多个id之间使用空格隔开。如下所示
<!ATTLIST class id ID #REQUIRED > <!ATTLIST teacher id ID #REQUIRED > <!ATTLIST student id ID #REQUIRED class_id IDREF #REQUIRED teachers_id IDREFS #REQUIRED > <class id="0909"/> <teacher id="20201455"/> <teacher id="20201456"/> <student id="2020090909027" class_id="0909" teachers_id="20201455 20201456"/> -
NMTOKEN和NMTOKENS
NMTOKEN表明值为合法的XML名称(由一个或者多个字母、数字、句点(.)、连字号(-)或下划线(_)所组成的一个名称),NMTOKENS表明值为合法的 XML 名称的列表,中间用空格隔开。如下所示:
<!ATTLIST student name NMTOKEN #REQUIRED course NMTOKENS #REQUIRED > <student name="meyok" course="HTML CSS JavaScript"/> -
ENTITY和ENTITYS
ENTITY表明值是一个实体(需要提前使用
<!ENTITY …>语句定义的一个引用实体,参见后续实体),ENTITYS表明值是一个实体列表,中间使用空格隔开。示例如下:<!ENTITY UESTC_library_url "https://www.lib.uestc.edu.cn/"> <!ENTITY UESTC_swan_img "https://www.lib.uestc.edu.cn/******/swan.jpg"> <!ENTITY UESTC_ginkgo_img "https://www.lib.uestc.edu.cn/******/ginkgo.jpg"> <!ATTLIST UESTC library ENTITY #REQUIRED img ENTITYS #IMPLIED > <UESTC library="&UESTC_library_url;" img="&UESTC_swan_img; &UESTC_ginkgo_img;"/> 注意:只有引用实体才可以作为ENTITY类型属性的设置值,参数实体不能用作ENTITY类型的属性的设置值。
-
NOTATION
NOTATION表明此值是符号的名称(需要提前使用
<!NOTATION …>语句定义的notation,NOTATION定义语句为<!NOTATION 符号名 SYSTEM "MIME类型或URL路径名">),示例如下:<!NOTATION mp SYSTEM "movPlayer.exe"> <!NOTATION gif SYSTEM "Image/gif"> <!ATTLIST movie device NOTATION (mp|gif) #REQUIRED > <movie device="mp"/>
-
实体
有时候需要在多个文档中调用同样的内容,比如公司名称,版权声明等,为了避免重复输入这些内容,可以通过<!ENTITY…>语句定义一个表示这些内容的实体,然后在各个文档中引用实体名替代它所表示的内容。实体可分为两种类型,分别是引用实体和参数实体,接下来,针对这两种实体类型进行详细地讲解。
-
引用实体
引用实体的语法定义格式有两种:
<!ENTITY 实体名称 "实体内容"> <!ENTITY 实体名称 SYSTEM "外部XML文档的URL"> 引用实体用于解决XML文档中内容重复的问题,其引用方式方法为
&实体名称;。如下所示:<!ENTITY UESTC_library_url "https://www.lib.uestc.edu.cn/"> <url>&UESTC_library_url;</url> -
参数实体
参数实体只能被DTD文件自身使用,它的语法格式为:
<!ENTITY % 实体名称 "实体内容"> 引用参数实体的方式是
%实体名称;,示例如下:<!ENTITY % TAG_NAME "name|email|address"> <!ELEMENT person_info (%TAG_NAME;|birthday)> <!ELEMENT customer_info (%TAG_NAME;|company)> 参数实体不仅可以简化元素中定义的相同内容,还可以简化属性的定义,示例如下:
<!ENTITY % common.attributes 'id ID #IMPLIED account CDATA #REQUIRED' > <!ATTLIST purchaseOrder %common.attributes;>
-
- XML Schema
一个基本的示例(文件名为note.xsd):
<?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.runoob.com" xmlns="http://www.runoob.com" elementFormDefault="qualified"> <xs:element name="note"> <xs:complexType> <xs:sequence> <xs:element name="to" type="xs:string"/> <xs:element name="from" type="xs:string"/> <xs:element name="heading" type="xs:string"/> <xs:element name="body" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
- xmlns:xs="http://www.w3.org/2001/XMLSchema":显示 schema 中用到的元素和数据类型来自命名空间 "http://www.w3.org/2001/XMLSchema"。同时它还规定了来自命名空间 "http://www.w3.org/2001/XMLSchema" 的元素和数据类型应该使用前缀 xs:
- targetNamespace="http://www.runoob.com":显示被此 schema 定义的元素 (note, to, from, heading, body) 来自命名空间 "http://www.runoob.com"。
- xmlns="http://www.runoob.com":指出默认的命名空间是 "http://www.runoob.com"。
- elementFormDefault="qualified":指出任何 XML 实例文档所使用的且在此 schema 中声明过的元素必须被命名空间限定。
xml对其的引用(node.xml):
<?xml version="1.0"?> <note xmlns="http://www.runoob.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.runoob.com note.xsd">> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>
- xmlns="http://www.runoob.com":规定了默认命名空间的声明。此声明会告知 schema 验证器,在此 XML 文档中使用的所有元素都被声明于 "http://www.runoob.com" 这个命名空间。
- 一旦您拥有了可用的 XML Schema 实例命名空间:xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance",就可以使用 schemaLocation 属性了。此属性有两个值。第一个值是需要使用的命名空间。第二个值是供命名空间使用的 XML schema 的位置:xsi:schemaLocation="http://www.runoob.com note.xsd"
xsd中配置相关解释:
- 简易元素:
<xs:element name="******" type="******" default="******" fixed="******"/>
name指元素的名称,type指元素的数据类型,default默认值,fixed固定值。
常用类型:xs:string、xs:decimal、xs:integer、xs:boolean、xs:date、xs:time
- 属性
<xs:attribute name="******" type="******" default="******" fixed="******" use="required"/>
在默认的情况下,属性是可选的。如需规定属性为必选,请使用 "use" 属性。
内建属性:xs:string、xs:decimal、xs:integer、xs:boolean、xs:date、xs:time
-
限定 / Facets
<xs:element name="age"> <xs:simpleType> <xs:restriction base="xs:integer"> ... </xs:restriction> </xs:simpleType> </xs:element> -
范围限定
<xs:restriction base="xs:integer"> <xs:minInclusive value="0"/> <xs:maxInclusive value="120"/> </xs:restriction> -
枚举约束
<xs:restriction base="xs:string"> <xs:enumeration value="Audi"/> <xs:enumeration value="Golf"/> <xs:enumeration value="BMW"/> </xs:restriction> -
模式约束
<xs:restriction base="xs:string"> <xs:pattern value="[a-z]"/> </xs:restriction> <!--可接受的值是大写字母A-Z其中的三个:value="[A-Z][A-Z][A-Z]" 可接受的值是大写或小写字母a-z其中的三个:value="[a-zA-Z][a-zA-Z][a-zA-Z]" 可接受的值是字母x、y或z中的一个:value="[xyz]"--> <!--可接受的值是五个阿拉伯数字的一个序列,且每个数字的范围是 0-9:--> <xs:restriction base="xs:integer"> <xs:pattern value="[0-9][0-9][0-9][0-9][0-9]"/> </xs:restriction> <!--可接受的值是a-z中零个或多个字母:--> <xs:restriction base="xs:string"> <xs:pattern value="([a-z])*"/> </xs:restriction> -
空白字符限定
<!--"preserve",XML处理器不会移除任何空白字符:--> <!--"replace",XML处理器将移除所有空白字符(换行、回车、空格以及制表符)--> <!--"collapse",XML处理器将移除所有空白字符(换行、回车、空格以及制表符会被替换为空格,开头和结尾的空格会被移除,而多个连续的空格会被缩减为一个单一的空格)--> <xs:restriction base="xs:string"> <xs:whiteSpace value="preserve"/> </xs:restriction> -
长度限定
<!--精确到8个字符:--> <xs:restriction base="xs:string"> <xs:length value="8"/> </xs:restriction> <!--限定其值最小为5个字符,最大为8个字符:--> <xs:minLength value="5"/> <xs:maxLength value="8"/> -
数据类型限定
限定 描述 enumeration 定义可接受值的一个列表 fractionDigits 定义所允许的最大的小数位数。必须大于等于0。 length 定义所允许的字符或者列表项目的精确数目。必须大于或等于0。 maxExclusive 定义数值的上限。所允许的值必须小于此值。 maxInclusive 定义数值的上限。所允许的值必须小于或等于此值。 maxLength 定义所允许的字符或者列表项目的最大数目。必须大于或等于0。 minExclusive 定义数值的下限。所允许的值必需大于此值。 minInclusive 定义数值的下限。所允许的值必需大于或等于此值。 minLength 定义所允许的字符或者列表项目的最小数目。必须大于或等于0。 pattern 定义可接受的字符的精确序列。 totalDigits 定义所允许的阿拉伯数字的精确位数。必须大于0。 whiteSpace 定义空白字符(换行、回车、空格以及制表符)的处理方式。
-
-
复合元素
-
空元素
<xs:element name="product"> <xs:complexType> <xs:attribute name="prodid" type="xs:positiveInteger"/> </xs:complexType> </xs:element> -
仅包含元素
<xs:element name="employee"> <xs:complexType> <xs:sequence> <xs:element name="firstname" type="xs:string"/> <xs:element name="lastname" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> -
仅包含文本
<!--使用extension或restriction元素来扩展或限制元素的基本简易类型--> <xs:element name="somename"> <xs:complexType> <xs:simpleContent> <xs:extension base="basetype"> .... .... </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <!--或者:--> <xs:element name="somename"> <xs:complexType> <xs:simpleContent> <xs:restriction base="basetype"> .... .... </xs:restriction> </xs:simpleContent> </xs:complexType> </xs:element> -
带有混合内容
<xs:element name="letter"> <xs:complexType mixed="true"> <xs:sequence> <xs:element name="name" type="xs:string"/> <xs:element name="orderid" type="xs:positiveInteger"/> <xs:element name="shipdate" type="xs:date"/> </xs:sequence> </xs:complexType> </xs:element> <!--注意: 为了使字符数据可以出现在 "letter" 的子元素之间,mixed 属性必须被设置为 "true"。<xs:sequence> 标签 (name、orderid 以及 shipdate ) 意味着被定义的元素必须依次出现在 "letter" 元素内部。-->
-
-
指示器
-
Order 指示器:Order 指示器用于定义元素的顺序。
-
all:规定子元素可以按照任意顺序出现,且每个子元素必须只出现一次,当使用 <all> 指示器时,你可以把 <minOccurs> 设置为 0 或者 1,而只能把<maxOccurs> 指示器设置为 1。
-
Choice:规定可出现某个子元素或者可出现另外一个子元素(非此即彼)。
-
Sequence :规定子元素必须按照特定的顺序出现。
<xs:element name="person"> <xs:complexType> <xs:all> <xs:element name="firstname" type="xs:string"/> <xs:element name="lastname" type="xs:string"/> </xs:all> </xs:complexType> </xs:element> -
-
Occurrence指示器:用于定义某个元素出现的频率。对于所有的 "Order" 和 "Group" 指示器(any、all、choice、sequence、group name 以及 group reference),其中的 maxOccurs 以及 minOccurs 的默认值均为 1。
- maxOccurs:规定某个元素可出现的最大次数。
- minOccurs:规定某个元素可出现的最小次数。
<xs:element name="person"> <xs:complexType> <xs:sequence> <xs:element name="full_name" type="xs:string"/> <xs:element name="child_name" type="xs:string" maxOccurs="10" minOccurs="0"/> </xs:sequence> </xs:complexType> </xs:element> -
Group 指示器:用于定义相关的数批元素。
-
元素组:通过 group 声明进行定义。
<xs:group name="persongroup"> <xs:sequence> <xs:element name="firstname" type="xs:string"/> <xs:element name="lastname" type="xs:string"/> <xs:element name="birthday" type="xs:date"/> </xs:sequence> </xs:group> <xs:element name="person" type="personinfo"/> <xs:complexType name="personinfo"> <xs:sequence> <xs:group ref="persongroup"/> <xs:element name="country" type="xs:string"/> </xs:sequence> </xs:complexType> -
属性组:通过 attributeGroup 声明来进行定义。
<xs:attributeGroup name="personattrgroup"> <xs:attribute name="firstname" type="xs:string"/> <xs:attribute name="lastname" type="xs:string"/> <xs:attribute name="birthday" type="xs:date"/> </xs:attributeGroup> <xs:element name="person"> <xs:complexType> <xs:attributeGroup ref="personattrgroup"/> </xs:complexType> </xs:element>
-
-
PS:
-
DTD不支持名域(Namespace)机制。XML Schema利用名域将文档中特殊的节点与schema说明相联系,一个xml文件可以有多个对应的schema,而用 DTD 的一个xml文件中只能有一个相对应的DTD 。
-
XML解析器通常会解析XML文档中所有的文本。对于不想解析的部分,使用CDATA ,格式如下(由
<![CDATA[开始,由]]>结束):
<script><![CDATA[未被解析的内容]]></script>
1.5.Web Server
1.5.1.HTTP
HTTP 协议一般指 HTTP(超文本传输协议)。http:// 起始与默认使用端口 80,而 HTTPS 的 URL 则是由 https:// 起始与默认使用端口443。
HTTP消息结构
- 客户端请求
包括请求行(request line)、请求头部(header)、空行和请求数据,如下所示:
GET /hello.txt HTTP/1.1 User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3 Host: www.example.com Accept-Language: en, mi
请求方法有以下几种:
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
- 服务端响应
包括状态行、消息报头、空行和响应正文,如下所示:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Accept-Ranges: bytes Content-Length: 51 Vary: Accept-Encoding Content-Type: text/plain
响应头信息如下:
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。 注意Refresh的意义是"N秒之后刷新本页面或访问指定页面",而不是"每隔N秒刷新本页面或访问指定页面"。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV="Refresh" ...>。 注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。 |
| Server | 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie | 设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。 |
HTTP状态码
分类如下:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
状态码列表:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
HTTP content-type
Content-Type 标头告诉客户端实际返回的内容的内容类型。
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded :
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
1.5.2.Tomcat
Tomcat 服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选。
Web服务器
按功能分类,Web服务器可以分为HTTP Server和Application Server。
-
HTTP Server
HTTP Server是一种应用程序,主要用来做静态内容服务、代理服务器、负载均衡等。它绑定服务器的IP地址并监听某一个TCP端口来接收并处理HTTP请求,关心的是HTTP协议层面的传输和访问控制。通过HTTP Server,客户端可获取服务器上存储的网页(HTML格式)、文档(PDF格式)、音频(MP4格式)、视频(MOV格式)等等静态资源。常使用的HTTP Server是Apache、Nginx。
对于服务器上的动态资源,可以通过CGI/Servlet技术,将处理过的动态内容通过HTTP Server分发,但是一个HTTP Server始终只是把服务器上的文件如实的通过HTTP协议传输给客户端。
-
Application Server
与HTTP Server相比,Application Server能够动态的生成资源并返回到客户端。
支持Servlet的程序被称为服务器小程序容器(Servlet Container)/服务器小程序引擎(Servlet Engine),用于在发送的请求和响应之上提供网络服务,在Servlet的生命周期内包容和管理Servlet,是一个实时运行的外壳程序。运行时由Web服务器软件处理一般请求,并把Servlet调用传递给“容器”来处理。
Tomcat本属于是一个Application Server,更准确的来说,是一个Servlet/JSP应用的容器。但是为了方便,Tomcat集成HTTP Server的功能。
Tomcat架构
Tomcat架构如图:
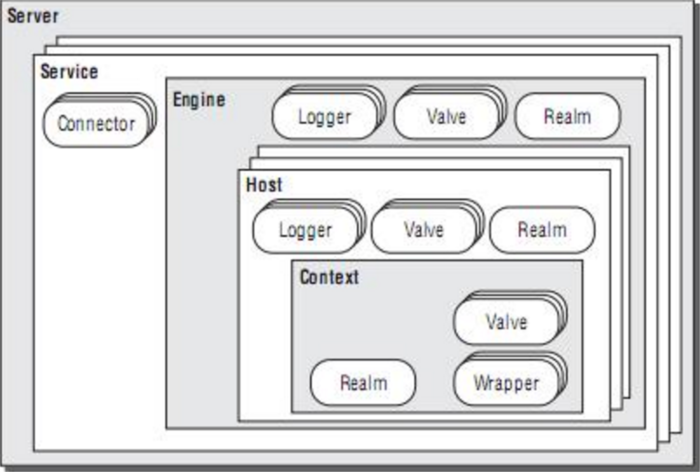
Tomcat两个核心组件是连接器(Connector)和容器(Container)。
-
Server
Tomcat构成的顶级构成元素,Server的实现类StandardServer可以包含一个到多个Service。
-
Service
Service的实现类StandardService调用了Container接口(其实是调用了Servlet Engine)。
-
Connector
Tomcat默认为是 Coyote,将Service和Container连接起来,Connector可以根据不同的设计和应用场景进行替换,一个Container可以选择对应多个Connector。多个Connector和一个Container就形成了一个Service,有了Service就可以对外提供服务了。
Connector根据收到的HTTP请求将 socket 连接封装成 request 、 response 对象传递给Container,最后根据Response中的内容生成相应的HTTP报文返回给客户端。
-
Container
服务器部署的项目是运行在Container中的,Container里面的项目获取到Connector传递过来对应的Request、Response对象进行相应的操作。
Engine、Host、Context、Wrapper均继承Container且前者包含后者。通常一个 Servlet class对应一个Wrapper。
Context 还可以定义在父容器Host中,Host不是必须的,但是要运行 war 程序,就必须要Host,因为war中必有 web.xml 文件,这个文件的解析就需要 Host 了,如果要有多个 Host 就要定义一个 top 容器 Engine 了。而 Engine 没有父容器了,一个 Engine 代表一个完整的 Servlet 引擎。
Tomcat运行内部流程
假设来自客户的请求为http://localhost:8080/test/index.jsp,Tomcat的运行流程如下:
- 请求被发送到本机端口8080,被在那里侦听的Coyote HTTP/1.1 Connector获得。
- Connector把该请求交给它所在的Service的Engine来处理,并等待Engine的回应。
- Engine获得请求localhost:8080/test/index.jsp,匹配它所有虚拟主机Host。
- Engine匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机)。
- localhost Host获得请求/test/index.jsp,匹配它所拥有的所有Context。
- Host匹配到路径为/test的Context(如果匹配不到就把该请求交给路径名为""的Context去处理)。
- path="/test"的Context获得请求/index.jsp,在它的mapping table中寻找对应的servlet。
- Context匹配到URL PATTERN为*.jsp的servlet,对应于JspServlet类。
- 构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet或doPost方法。
- Context把执行完了之后的HttpServletResponse对象返回给Host。
- Host把HttpServletResponse对象返回给Engine。
- Engine把HttpServletResponse对象返回给Connector。
- Connector把HttpServletResponse对象返回给客户端。
目录结构
-
bin:存放各个平台上启动和停止Tomcat服务器的脚本。
- catalina.sh:用于启动和关闭tomcat服务器。
- configtest.sh:用于检查配置文件。
- startup.sh:启动Tomcat脚本。
- shutdown.sh :关闭Tomcat脚本。
-
conf:存放各种Tomcat服务器的配置文件。
- server.xml:Tomcat 的全局配置文件。
- web.xml:为不同的Tomcat配置的web应用设置缺省值的文件。
- tomcat-users.xml:Tomcat用户认证的配置文件。
-
lib:存放Tomcat服务器所需要的jar。
-
logs:
- localhost_access_log.2013-09-18.txt:访问日志
- localhost.2013-09-18.log:错误和其它日志
- manager.2013-09-18.log:管理日志
- catalina.2013-09-18.log:Tomcat启动或关闭日志文件
-
temp:存放Tomcat运行的临时文件。
-
webapps:含Web应用的程序(JSP、Servlet和JavaBean等)。
-
work:由Tomcat自动生成,这是Tomcat放置它运行期间的中间(intermediate)文件(诸如编译的JSP文件)地方。如果当Tomcat运行时,你删除了这个目录那么将不能够执行包含JSP的页面。
PS:
-
Tomcat使用:将项目目录或者war(Tomcat会自动解压)放在webapps下即可。或者在conf/Catalina/localhost下新建XML文件,添加
<Context docBase="项目路径" reloadable="true"/>即可 (此时虚拟路径为XML文件名,docBase可使用相对于webapps的相对路径,推荐此方法)。 -
Application Server往往是运行在HTTP Server的背后,执行应用,将动态的内容转化为静态的内容之后,通过HTTP Server分发到客户端。Tomcat处理静态HTML的能力不如Apache服务器。当配置正确时,可以把Apache做为HTML页面服务,而Tomcat 实际上运行JSP页面和Servlet。
-
connect的监听端口可在/conf/server.xml中Connector标签的port属性修改。
-
http://ip地址:端口号默认访问的是Tomcat目录/webapps/ROOT目录。
-
Maven打包后生成的war包中,META-INF存储了项目的元信息,其中文件MANIFEST.MF仅此一份,描述了程序的基本信息、Main-Class的入口、jar依赖路径Class-Path。WEB-INF放置资源,其下web.xml为项目配置,lib放置项目依赖jar包,classes放置java字节码文件……。
1.5.3.Servlet
Servlet(Server Applet)是Java Servlet的简称,称为小服务程序或服务连接器,用Java编写的服务器端程序,具有独立于平台和协议的特性,主要功能在于交互式地浏览和生成数据,生成动态Web内容。
生命周期
在Server启动后,Server调用Servlet的init()方法创建Servlet(可设置Server启动时创建或第一次调用时创建),Server面对每次请求调用一次Servlet的service方法,当Server不再需要Servlet时(一般当Server关闭时),Server调用Servlet的destroy()方法销毁Servlet。
Servlet实现
- Servlet接口:需实现init()、getServletConfig()、service()、getServletInfo()、destroy()
- GenericServlet类:将Servlet接口中的其他方法做了默认空实现,只将service()方法作为抽象。
- HttpServlet类:实现doGet()、doPost()
url与servlet类映射
两种映射方式:
-
web.xml配置
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <!-- 配置Servlet --> <servlet> <servlet-name>demo1</servlet-name> <servlet-class>cn.meyok.weblearn.servlet.ServletDemo1</servlet-class> <load-on-startup>-1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>demo1</servlet-name> <url-pattern>/demo1</url-pattern> </servlet-mapping> </web-app> load-on-startup标签用于配置servlet创建时机,值为负数表示第一次访问时被创建,非负数表示在服务器启动时被创建。
-
WebServlet注解
在对应servlet实现类添加@WebServlet()注解。该注解有以下主要属性:
- String name:对应servlet-name,缺省值为包名+类名。
- String[ ] value/urlPatterns:对应url-pattern。
- int loadOnStartup:对应load-on-startup。
Request&Response
HttpServletRequest常用方法:
- String getMethod():获取请求方式。如GET。
- String getContextPath():获取虚拟目录。webapps的项目目录。
- String getServletPath():获取Servlet路径。servlet映射的路径。
- String getQueryString():获取get方式请求参数。“?”后面的内容,如name=meyok。
- String getRequestURI():获取URI。ContextPath+ServletPath,如/demo/test。
- StringBuffer getRequestURL():获取URL。如http://localhost:8080/demo/test。
- String getProtocol():获取协议及版本。如HTTP/1.1。
- String getRemoteAddr():获取客户机的IP地址。如0:0:0:0:0:0:0:1。
- Enumeration<String> getHeaderNames():获取所有请求头名。
- String getHeader(String var1):获取某个请求头值。
- BufferedReader getReader():
- ServletContext getServletContext():获取ServletContext。还可以通过this.getServletContext()获取。
- void setAttribute(String var1, Object var2):设置数据。转发后通过getAttribute获取。
- ……
HttpServletResponse常用方法:
- PrintWriter getWriter():获得PrintWriter,调用write方法或print()方法输出。
- ServletOutputStream getOutputStream():获得ServletOutputStream,调用write方法输出。
- ……
PS:
- ServletContext
在服务器启动时为每个web项目创建一个单独的ServletContext对象,一个web项目只有一个此对象,其实是对web.xml的封装。乱码问题
-
乱码问题
-
post方式产生中文乱码的原因:数据在请求体中,放入request的缓冲区中,缓冲区默认编码为ISO-8859-1(不支持中文)。将request的缓冲区编码修改即可。
req.setCharacterEncoding("UTF-8"); -
get方式产生中文乱码的原因:get方式提交的数据在请求行的url后面,在地址栏上就已经进行了一次url的编码了。解决办法:先将存入到request缓冲区中的内容以ISO-8859-1的格式提取,再以UTF-8的编码解码。
String name = req.getParameter("name"); String encode = URLEncoder.encode(name, "ISO_8859_1"); String decode = URLDecoder.decode(encode, "UTF-8"); // 简化写法 String name = new String(name.getBytes(StandardCharsets.ISO_8859_1), StandardCharsets.UTF_8); -
Response对象的中文响应乱码处理
// 使用字节流的方式输出中文 ServletOutputStream outputStream = resp.getOutputStream(); // 设置浏览器默认打开时候采用的字符集 resp.setHeader("Content-Type", "text/html;charset=UTF-8"); // 设置中文转成字节数组字符集编码 outputStream.write("中文".getBytes(StandardCharsets.UTF_8)); // 设置浏览器默认打开时候采用的字符集 resp.setHeader("Content-Type", "text/html;charset=UTF-8"); // 设置response获得字符流的缓冲区的编码 resp.setCharacterEncoding("UTF-8"); // 使用字符流输出中文 resp.getWriter().print("中文"); // 简化代码 resp.setContentType("text/html;charset=UTF-8");
-
-
转发与重定向
重定向使用Response的sendRedirect()即可,参数为URI。转发使用Request的getRequestDispatcher().forward(request, response)即可,参数为ServletPath。转发是一次请求,浏览器地址栏不发生变化,只能转发到当前服务器内部资源。
- Servlet作用域
servlet有三大作用域,Request、Session、Application。Session作用域对应一次会话,只要浏览器不关就是一个session。Application对应一个应用程序,在tomcat启动的时候被创建,tomcat关闭的时候被销毁。
Cookie&Session
- Cookie
Cookie是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。
Cookie示例:
@Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { Cookie[] cookies = request.getCookies(); //获取数据,遍历Cookies if (cookies != null) { for (Cookie cookie : cookies) { String name = cookie.getName(); String value = cookie.getValue(); System.out.println(name+" : "+ value); } } Cookie c = new Cookie("name", "setMaxAge"); // 设置Cookie的存活时间:正数,将cookie持久化到硬盘中,多少秒后自动删除cookie文件;负数,默认,关闭浏览器自动删除cookie;0,删除硬盘中持久化的cookie。 c.setMaxAge(30); response.addCookie(c1); }
对于Cookie的设置:
-
同一个tomcat部署,设置path,可以让路径下的其他项目访问到(默认虚拟目录):
c.setPath("/"); -
不同tomcat部署,如果设置一级域名相同,那么多个服务器之间的cookie就可以共享,如setDomain(".baidu.com"),那么tieba.baidu.com和news.baidu.com中的cookie就可以共享
- Session
Session代表着服务器和客户端一次会话的过程。Session对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的Web 页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当客户端关闭会话,或者 Session 超时失效时会话结束。
Session示例:
@Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { HttpSession session = request.getSession(); session.setAttribute("msg", "hello session"); Object msg = session.getAttribute("msg"); System.out.println(msg); //期望客户端关闭后,session也能相同 Cookie c = new Cookie("JSESSIONID", session.getId()); c.setMaxAge(60*60*24); response.addCookie(c); }
Filter&Listener
- Filter
它主要用于对用户请求进行预处理,也可以对HttpServletResponse进行后处理。使用Filter的完整流程:Filter对用户请求进行预处理,接着将请求交给Servlet进行处理并生成响应,最后Filter再对服务器响应进行后处理。
实现filter通过实现Filter类,包含三个方法,init方法、destory方法分别在Web服务器启动后、关闭前调用,doFilter方法为每次访问对应绑定的路径时调用。Web服务器会将所有的Filter串成chain,根据web.xml文件中的注册顺序,决定先调用哪个Filter。doFilter方法实现中,filterChain.doFilter方法调用前代码内容在调用servlet前执行,调用后代码内容在调用servlet后执行,且filterChain.doFilter方法调用前代码先执行的调用后代码后执行。
下面列举一个用于处理请求相应编码的Filter:
在web.xml添加如下配置:
<filter> <filter-name>filter</filter-name> <filter-class>cn.meyok.weblearn.filter.CharacterEncodingFilter</filter-class> </filter> <filter-mapping> <filter-name>filter</filter-name> <url-pattern>/*</url-pattern> <dispatcher>REQUEST</dispatcher> </filter-mapping>
CharacterEncodingFilter类实现:
public class CharacterEncodingFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { servletRequest.setCharacterEncoding("UTF-8"); filterChain.doFilter(servletRequest, servletResponse); servletResponse.setContentType("text/html;charset=UTF-8"); } @Override public void destroy() { } }
// TODO 该例子可能存在问题,需要验证。
PS:
- 除了web.xml配置filter映射,还可以在filter上添加@WebFilter()注释,filter-chain顺序是根据类名排序的。
- web.xml中dispatcher取值及含义:
- REQUEST:当用户直接访问页面时,Web容器将会调用过滤器。如果目标资源是通过RequestDispatcher的include()或forward()方法访问时,那么该过滤器就不会被调用。
- INCLUDE:如果目标资源是通过RequestDispatcher的include()方法访问时,那么该过滤器将被调用。除此之外,该过滤器不会被调用。
- FORWARD:如果目标资源是通过RequestDispatcher的forward()方法访问时,那么该过滤器将被调用,除此之外,该过滤器不会被调用。
- ERROR:如果目标资源是通过声明式异常处理机制调用时,那么该过滤器将被调用。除此之外,过滤器不会被调用。
- Listener
在Servlet规范中定义了多种类型的监听器,它们用于监听的事件源是三个域对象,分别为ServletContext、HttpSession、ServletRequest,Servlet规范针对这三个域对象上的操作,又把这多种类型的监听器划分为三种类型:监听三个域对象的创建和销毁的事件监听器、监听三个域对象的属性(Attribute)的增加和删除的事件监听器、监听绑定到 HttpSession 域中的某个对象的状态的事件监听器。
Servlet监听器的注册不是直接注册在事件源上,而是由WEB容器负责注册,开发人员只需在web.xml文件中使用<listener>标签配置好监听器,web容器就会自动把监听器注册到事件源中。
-
监听三个域对象创建和销毁的事件监听器
-
ServletContextListener
用于监听 ServletContext 对象的创建和销毁事件。当 ServletContext 对象被创建和被销毁时,接口中的方法void contextInitialized(ServletContextEvent sce)、contextDestroyed(ServletContextEvent sce)将会被分别调用。
主要用途:
-
保存全局应用数据对象
在服务器启动时,对一些对象进行初始化,并且将对象保存ServletContext数据范围内,实现全局数据。例如:创建数据库连接池。
-
加载框架配置文件
Spring框架(配置文件随服务器启动加载) org.springframework.web.context.ContextLoaderListener。
-
实现任务调度(定时器),启动定时程序。可使用java.util.Timer。
-
-
HttpSessionListener
用于监听HttpSession的创建和销毁。创建和销毁一个Session时,接口中的该方法sessionCreated(HttpSessionEvent) 、sessionDestroyed (HttpSessionEvent)将会被分别调用。
-
ServletRequestListener
用于监听ServletRequest对象的创建和销毁。ServletRequest对象被创建和被销毁时,监听器的requestInitialized方法、requestDestroyed方法将会被分别调用。
-
-
监听三个域对象的属性(Attribute)的变化的事件监听器
Servlet规范定义了监听 ServletContext、HttpSession、HttpServletRequest 这三个对象中的属性(Attribute)变更信息事件的监听器,分别为ServletContextAttributeListener、HttpSessionAttributeListener、ServletRequestAttributeListener。这三个接口中都定义了三个方法来处理被监听对象中的属性的增加,删除和替换的事件,同一个事件在这三个接口中对应的方法名称完全相同,只是接受的参数类型不同。
三个方法分别为attributeAdded(XXEvent)、attributeRemoved(XXEvent)、attributeReplaced(XXEvent),对应属性被添加、删除、代替时执行对应的Event,三个域的Event的完整类名分别为ServletContextAttributeEvent、HttpSessionBindingEvent、ServletRequestAttributeEvent。
-
监听绑定到HttpSession域中的某个对象的状态的事件监听器
保存在 Session 域中的对象可以有多种状态:绑定到 Session 中、从 Session 域中解除绑定、随 Session 对象持久化到一个存储设备中(钝化)、随 Session 对象从一个存储设备中恢复(活化)。
Servlet 规范中定义了两个特殊的监听器接口来帮助 JavaBean 对象了解自己在 Session 域中的这些状态:HttpSessionBindingListener接口和HttpSessionActivationListener接口,实现这两个接口的类不需要 web.xml 文件中注册,因为监听方法调用,都是由Session自主完成的
-
HttpSessionBindingListener
实现该接口的 Java 对象,可以感知自己被绑定到 Session 或者从 Session 中解除绑定。
绑定和解绑时web 服务器分别调用该JavaBean对象的void valueBound(HttpSessionBindingEvent)、void valueUnbound(HttpSessionBindingEvent )方法。
注意:当 Session 绑定的 JavaBean 对象替换时,会让新对象绑定,旧对象解绑。
-
HttpSessionActivationListener
实现该接口的 Java 对象,可以感知自己从内存被钝化硬盘上,或者从硬盘被活化到内存中。
当绑定到 HttpSession 对象中的 JavaBean 对象将要随 HttpSession 对象被钝化之前和被活化之后,web 服务器分别调用该 JavaBean 对象的 void sessionWillPassivate(HttpSessionBindingEvent) 、 void sessionDidActive(HttpSessionBindingEvent) 方法。
注意:钝化和活化应该由 Tomcat 服务器 自动进行,所以应该配置 Tomcat 如下。
<Context> <!-- 1分钟不用 进行钝化 表示1分钟 --> <Manager className="org.apache.catalina.session.PersistentManager" maxIdleSwap="1"> <!-- 钝化后文件存储位置 directory="it315" 存放到it315目录--> <Store className="org.apache.catalina.session.FileStore" directory="it315"/> </Manager> </Context>
-
生成图片校验码示例
@WebServlet("/checkCodeServlet") public class CheckCodeServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { this.doPost(request, response); } @Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //1.创建一对象,在内存中图片(验证码图片对象) int width = 100; int height = 50; BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB); //2.美化图片 //2.1 填充背景色 Graphics g = image.getGraphics(); //画笔对象 g.setColor(Color.pink); // 设置画笔颜色 g.fillRect(0, 0, width, height); //2.2画边框 g.setColor(Color.blue); g.drawRect(0, 0, width-1, height-1); //2.3写验证码 String str = "ABCDEFGHIJKLMNOPQRESTUVWXYZabcdefghijklmnopqresuvwxyz0123456789"; Random random = new Random(); for (int i = 1; i <= 4; i++) { int index = random.nextInt(str.length()); char c = str.charAt(index); g.drawString(c+"", width/5*i, height/2); } //2.4画干扰线 g.setColor(Color.green); for (int i = 0; i < 10; ++i) { int x1 = random.nextInt(width); int y1 = random.nextInt(height); int x2 = random.nextInt(width); int y2 = random.nextInt(height); g.drawLine(x1, y1, x2, y2); } //3.将图片输出到页面展示 ImageIO.write(image, "jpg", response.getOutputStream()); } }
PS:
-
servlet的依赖为javax.servlet-api,其scope为provided,不会打包到.war文件中,因为运行期Web服务器本身已经提供了Servlet API相关的jar包。
-
Servlet是单例,Servlet类中的变量,谁都可以访问修改,有线程安全问题。若实现的是Servlet接口,尽量将变量放在方法里。
-
web.xml配置initParameter:
<!-- 指定初始化参数--> <context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/classes/applicationContext.xml</param-value> </context-param> servletContext.getInitParameter("contextConfigLocation")获取配置的String。
1.5.4.JSP
JSP(全称Java Server Pages)是由Sun Microsystems公司倡导和许多公司参与共同创建的一种使软件开发者可以响应客户端请求,而动态生成HTML、XML或其他格式文档的Web网页的技术标准。
JSP处理过程
- 就像其他普通的网页一样,您的浏览器发送一个 HTTP 请求给服务器。
- Web 服务器识别出这是一个对 JSP 网页的请求,并且将该请求传递给 JSP 引擎。通过使用 URL或者 .jsp 文件来完成。
- JSP 引擎从磁盘中载入 JSP 文件,然后将它们转化为 Servlet。这种转化只是简单地将所有模板文本改用 println() 语句,并且将所有的 JSP 元素转化成 Java 代码。
- JSP 引擎将 Servlet 编译成可执行类,并且将原始请求传递给 Servlet 引擎。
- Web 服务器的某组件将会调用 Servlet 引擎,然后载入并执行 Servlet 类。在执行过程中,Servlet 产生 HTML 格式的输出并将其内嵌于 HTTP response 中上交给 Web 服务器。
- Web 服务器以静态 HTML 网页的形式将 HTTP response 返回到您的浏览器中。
- 最终,Web 浏览器处理 HTTP response 中动态产生的HTML网页,就好像在处理静态网页一样。
总的来说,JSP网页就是用另一种方式来编写Servlet而不用成为Java编程高手。除了解释阶段外,JSP网页几乎可以被当成一个普通的Servlet来对待。
JSP语法
- 头部标签
-
page:配置JSP页面
-
contentType
等同于response.setContentType(),设置响应体的mime类型以及字符集,设置当前JSP编码(只能是高级的IDE才能生效,如果使用低级工具,则需要设置pageEncoding属性设置当前页面的字符集)
-
import:导包
-
errorPage:当前页面发生异常后,会自动跳转到指定的错误页面。
-
isErrorPage:标识当前页面是否是错误页面。
- true:是,可以使用内置对象exception
- false:否,默认值
-
-
include:页面包含的。导入页面的资源文件
<%@ include file="top.jsp"%> -
taglib:导入资源,prefix前缀自定义。
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
-
内置对象
变量名 真实类型 作用 pageContext PageContext 当前页面共享数据,还可以获取其他八个内置对象 request HttpServletRequest 一次请求访问的多个资源(转发) session HttpSession 一次会话的多个请求间 application ServletContext 所有用户键共享数据 response HttpServletResponse 响应对象 page Object 当前页面(Servlet)的对象 this out JspWriter 输出对象,数据输出到页面上 config ServletConfig Servlet的配置对象 exception Throwable 异常对象 -
脚本程序
脚本程序可以包含任意量的Java语句、变量、方法或表达式,只要它们在脚本语言中是有效的。
<% 代码片段 %> -
JSP声明
一个声明语句可以声明一个或多个变量、方法,供后面的Java代码使用。在JSP文件中,您必须先声明这些变量和方法然后才能使用它们。
<%! declaration; [ declaration; ]+ ... %> -
JSP表达式
一个JSP表达式中包含的脚本语言表达式,先被转化成String,然后插入到表达式出现的地方。
<%= 表达式 %> -
JSP注释
<%-- 注释 --%>
示例:
<%@ page contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %> <!DOCTYPE html> <html> <head> <title>JSP - Hello World</title> </head> <body> <% System.out.println("hello jsp"); int i = 5; out.print("out"); %> <%! int i = 3; %> <%= i %> <h1>hi~ jsp</h1> <% response.getWriter().write("response"); %> </body> </html>
el表达式
jsp默认会解析el表达式,如果想忽略,则在page中添加属性isELIgnored="true",或者在el表达式前加\,忽略单个el表达式。
el表达式使用:
-
运算
-
算数运算符: + - * /(div) %(mod)
-
比较运算符: > < >= <= == !=
-
逻辑运算符: &&(and) ||(or) !(not)
-
空运算符: empty
用于判断字符串,集合,数组对象是否为null并且长度是否为0
${empty list}
-
-
获取值
el表达式只能从域对象中获取值
语法:
-
${域名称.键名}:从指定域中获取指定键的值
域名称:
pageScope --> pageContext
requestScope --> request
sessionScope --> session
applicationScope --> application(ServletContext)
-
${键名}:表示依次从最小的域中查找是否有该键对应的值,直到找到为止。
-
示例:
<%@ page import="cn.meyok.weblearn.entity.UserDO" %> <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>el表达式示例</title> </head> <body> <% UserDO user = new UserDO("meyok", 22); request.setAttribute("user", user); %> ${requestScope.user.name}<br> ${pageContext.request.contextPath}<br> </body> </html>
jstl
需要导入taglib:
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
-
if:test必须属性,接受boolean表达式,决定是否显示标签体内容,一般会结合el表达式一起使用。
<c:if test="${number mod 2 == 0}">${number}为偶数</c:if><br> -
choose:选择。
<c:choose> <c:when test="${number == 1}">Monday</c:when> <c:when test="${number == 2}">Tuesday</c:when> <c:when test="${number == 3}">Wednesday</c:when> <c:when test="${number == 4}">Thursday</c:when> <c:when test="${number == 5}">Friday</c:when> <c:when test="${number == 6}">Saturday</c:when> <c:when test="${number == 7}">Sunday</c:when> <c:otherwise>数字输入有误</c:otherwise> </c:choose> -
forEach:varStatus,循环状态对象;index,容器中元素的索引,从0开始;count,循环次数,从1开始。
<%@ page import="java.util.List" %> <%@ page import="java.util.ArrayList" %> <%@ page contentType="text/html;charset=UTF-8" language="java" %> <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> <html> <head> <title>foreach标签</title> </head> <body> <c:forEach begin="1" end="10" var="i" step="2" varStatus="s"> ${i} ${s.index} ${s.count}<br> </c:forEach><br> <% List list = new ArrayList(); list.add("aaa"); list.add("bbb"); list.add("ccc"); request.setAttribute("list", list); %> <c:forEach items="${list}" var="str" varStatus="s"> ${s.index} ${s.count} ${str}<br> </c:forEach> </body> </html>
1.6.其它
1.6.1.NGINX
NGINX是异步框架的网页服务器,也可以用作反向代理、负载平衡器和 HTTP 缓存。
NGINX配置文件结构
NGINX配置文件由以下结构构成:
-
全局块:配置nginx全局指令。
- user:设置nginx服务的系统使用用户 (一般情况下是处于注释状态)
- worker_processes:允许生成的进程数,默认为1。
- pid:指定nginx进程运行文件存放地址。
- include:指定包含其它扩展配置文件,如
/etc/nginx/modules-enabled/*.conf;。 - error_log:nginx的错误日志。
-
events块:配置影响nginx服务器或与用户的网络连接。
- worker_connections:每个进程允许最大的连接数
-
http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。
-
upstream块:负载均衡设置。
-
server块:配置虚拟主机的相关参数,一个http中可以有多个server。
-
listen:端口。
-
server_name:域名地址。
-
root:项目访问路劲。
-
index:
-
location块:配置请求的路由,以及各种页面的处理情况。
location匹配URL语法如下:
- =:用于不含正则表达式的 uri 前,要求请求字符串与 uri 严格匹配,如果匹配 成功,就停止继续向下搜索并立即处理该请求。
- ~:用于表示 uri 包含正则表达式,并且区分大小写。
- ~*:用于表示 uri 包含正则表达式,并且不区分大小写。
- ^~:用于不含正则表达式的 uri 前,要求 Nginx 服务器找到标识 uri 和请求字 符串匹配度最高的 location 后,立即使用此 location 处理请求,而不再使用 location 块中的正则 uri 和请求字符串做匹配。
-
-
负载均衡
NGINX有三种负载均衡模式:
-
轮询(默认):每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
-
权重:weight 代表权重,默认为 1,权重越高被分配的客户端越多,权重越大,能力越大,责任越大,处理的请求就越多。
upstream myserver{ server 127.0.0.1:8080 weight = 1; server 127.0.0.1:8090 weight = 2; } -
ip_hash:每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 session 的问题。可与weight配合使用。
upstream myserver{ ip_hash; server 127.0.0.1:8080 weight = 1; server 127.0.0.1:8090 weight = 2; }
常用指令
要启动 nginx,请运行可执行文件。nginx一旦启动,就可以通过-s参数调用可执行文件来控制它。使用以下语法:
nginx -s 信号
其中信号可能是以下之一:
stop— 快速关机quit— 优雅关机reload— 重新加载配置文件reopen— 重新打开日志文件
默认nginx.conf配置:
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; # server { # listen 80; # server_name localhost; # #charset koi8-r; # #access_log logs/host.access.log main; # location / { # root html; # index index.html index.htm; # } # #error_page 404 /404.html; # # redirect server error pages to the static page /50x.html # # # error_page 500 502 503 504 /50x.html; # location = /50x.html { # root html; # } # # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # # # #location ~ \.php$ { # # proxy_pass http://127.0.0.1; # #} # # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # # # #location ~ \.php$ { # # root html; # # fastcgi_pass 127.0.0.1:9000; # # fastcgi_index index.php; # # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # # include fastcgi_params; # #} # # deny access to .htaccess files, if Apache's document root # # concurs with nginx's one # # # #location ~ /\.ht { # # deny all; # #} # } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} # upstream nginx_demo { # server 127.0.0.1:8080; # } server { listen 8081; server_name 127.0.0.1; location / { root html; proxy_pass http://127.0.0.1:8080; index index.html index.htm; } # root C:\Tomcat\apache-tomcat-9.0.65\webapps; } }
1.6.2.日志管理
Log4j
依赖:
<dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> </dependency>
Log4j是一个用Java编写的可靠,快速和灵活的日志框架(API),它是在Apache软件许可下发布的。 log4j是一个用Java编写的流行的日志包。
Log4j框架结构如下:
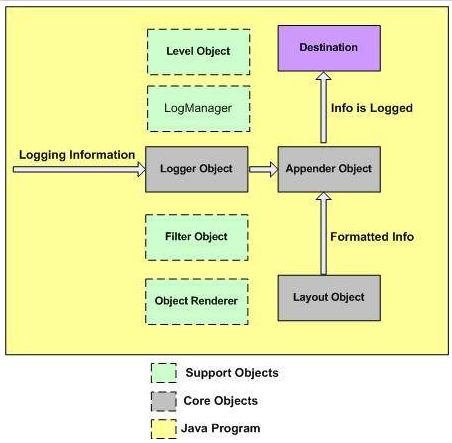
Log4j有三个主要组件:
- logger:负责捕获日志记录信息。
- appender:负责将日志信息发布到各个首选目的地。
- layout:负责格式化不同样式的日志信息。
Log4j的主持组件:
- level:定义任何日志记录信息的粒度和优先级。 API中定义了七个级别的日志记录:OFF,DEBUG,INFO,ERROR,WARN,FATAL和ALL。
- filter:用于分析日志记录信息,并进一步决定是否应记录该信息。Appender对象可以有多个与之关联的Filter对象。 如果将日志记录信息传递给特定的Appender对象,则与该Appender关联的所有Filter对象都需要批准日志记录信息,然后才能将其发布到附加目标。
- ObjectRenderer:专门提供传递给日志记录框架的不同对象的String表示。 Layout对象使用此对象来准备最终的日志记录信息。
- LogManager:管理日志记录框架。 它负责从系统范围的配置文件或配置类中读取初始配置参数。
Log4j配置涉及分配Level,定义Appender以及在配置文件中指定Layout对象,以下设置将根记录器的级别定义为DEBUG,将名为X的appender附加到它上面并设置将X的appender设置为有效的appender,以及appender X的布局:
# Define the root logger with appender file log=/usr/home/log4j log4j.rootLogger=DEBUG, X # Define the file appender log4j.appender.X=org.apache.log4j.FileAppender log4j.appender.X.File=${log}/log.out # Define the layout for file appender log4j.appender.X.layout=org.apache.log4j.PatternLayout log4j.appender.X.layout.conversionPattern=%m%n
Log4j日志级别总共有TRACE < DEBUG < INFO < WARN < ERROR < FATAL ,且级别是逐渐提供,如果日志级别设置为INFO,则意味TRACE和DEBUG级别的日志都看不到。除了根记录器,也可使用以下格式
log4j.logger.[logger-name]=level, appender1,appender..n
在我们的Java中,可使用LogManager来获取Logger并添加日志:// TODO 解决代码问题
public class App { public static void main( String[] args ) { Logger log = LogManager.getLogger(App.class); log.info("Hello this is an info message"); } }
Log4j可自定义日志格式,如下:
-
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
-
%r 输出自应用启动到输出该log信息耗费的毫秒数
-
%c 输出所属的类目,通常就是所在类的全名
-
%t 输出产生该日志事件的线程名
-
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
-
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
-
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main(TestLog4.java:10)
-
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
-
%%: 输出一个”%”字符
-
%F: 输出日志消息产生时所在的文件名称
-
%L: 输出代码中的行号
-
%m: 输出代码中指定的消息,产生的日志具体信息
-
%n: 输出一个回车换行符,Windows平台为”\r\n”,Unix平台为”\n”输出日志信息换行
可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。
示例如下:
Commons Logging
依赖:
<dependency> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> </dependency>
Commons Logging是一个第三方日志库,它是由Apache创建的日志模块。Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。默认情况下,Commons Loggin自动搜索并使用Log4j,如果没有找到Log4j,再使用JDK Logging。
进行好Log4j的配置后,通过LogFactory来获得log,示例代码如下:
public class App { public static void main( String[] args ) { Log log = LogFactory.getLog(App.class); try { int i = 1/0; } catch (Exception e) { log.error("error", e); } } }
SLF4J与Logback
SLF4J类似于Commons Logging,也是一个日志接口,而Logback类似于Log4j,是一个日志的实现。
依赖:
<!-- SLF4J --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> </dependency> <!-- Logback依赖 --> <!-- 其它两个模块的基础模块 --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> </dependency> <!-- log4j的一个改良版本,此外完整实现SLF4J API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-access</artifactId> </dependency> <!-- 访问模块与Servlet容器集成提供通过Http来访问日志的功能 --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> </dependency>
<!-- 如果采用SLF4J+LOG4J还需添加以下依赖 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency>
2.Back-End
2.1.Spring
2.1.1.基础
Spring是一个开源框架,Spring是一个轻量级的Java 开发框架。它是为了解决企业应用开发的复杂性而创建的。框架的主要优势之一就是其分层架构,分层架构允许使用者选择使用哪一个组件,同时为 J2EE 应用程序开发提供集成的框架。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅限于服务器端的开发。从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。Spring的核心是控制反转(IoC)和面向切面(AOP)。简单来说,Spring是一个分层的full-stack(一站式) 轻量级开源框架。
PS:Spring基础相关依赖
<!-- 基本依赖,包含core(依赖的jcl为日志相关)、bean、context、expression(SpEL表达式)--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> </dependency> <!-- 测试相关依赖 --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> </dependency>
Spring架构核心
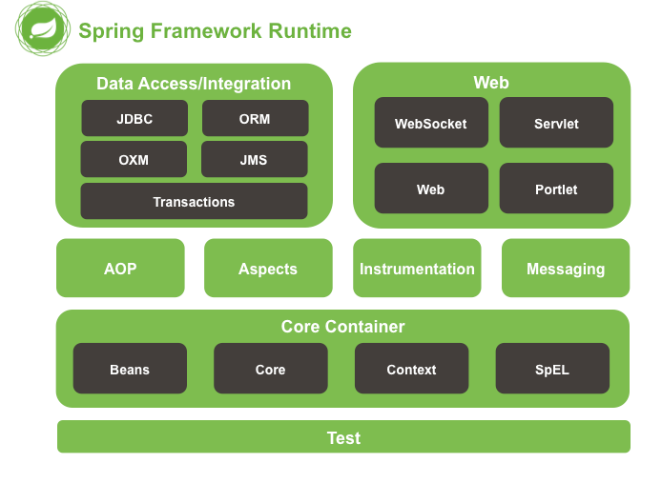
Spring中关键元素为Beans、Core和Context。如果把Beans比作演员,Context相当于舞台,Core相当于道具。Bean包装了Object,而Context维护了Beans之间的关系,所以Context就是一个Bean关系的集合,这个关系集合又叫IoC容器。Core就是发现、建立和维护每个Bean之间的关系所需要的一些列的工具。
IoC
了解IoC前首先了解两个概念。
-
IoC(Inversion of Control),即“控制反转”。传统Java SE程序设计,是直接在对象中new进行对象创建,程序主动。而IoC具有专门的容器控制依赖对象的创建,程序中需要的对象从IoC容器中取得,依赖对象的获取被反转。
-
DI(Dependency Injection),即“依赖注入”。IoC容器动态将程序依赖对象注入到组件中。
Spring的IoC容器初始化过程如下:
- Resource资源定位:Resouce指的是BeanDefinition的资源定位。
- BeanDefinition的载入:把用户定义好的Bean表示成IoC容器内部的数据结构,而这个容器内部的数据结构就是BeanDefition。
- BeanDefinition的注册:将IoC容器的BeanDefition保存到HashMap中。
IoC容器为BeanFactory,一般使用其子类ApplicationContext。Spring的ApplicationContext可通过对应context配置文件获取:
// 1.XML获得 ApplicationContext app = new ClassPathXmlApplicationContext("applicationContext.xml"); // 2.File获得 ApplicationContext app = new FileSystemXmlApplicationContext("C:\\SpringLearn\\src\\main\\resources\\applicationContext.xml"); // 3.class获得(此方法要求对应的class为configuration,可在类上添加@Configuration标志该类是Spring的核心配置类) ApplicationContext app = new AnnotationConfigApplicationContext(SpringConfiguration.class); // 4.HttpServletRequest获得 ServletContext servletContext = req.getServletContext(); ApplicationContext app = WebApplicationContextUtils.getWebApplicationContext(servletContext);
ApplicationContext获取后即可调用getBean方法获得Bean:
// 1.以id获取 User user = (User) app.getBean("user"); // 2.以class获取 User user = app.getBean(User.class);
applicationContext.xml作为我们配置文件,基本格式如下:(xsi:schemaLocation中顺序分别为bean相关、context相关。)
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation= "http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!-- TODO 配置 --> </beans>
相关配置编写方法如下:
-
Bean
Bean的创建有三种方式:
-
构造方法创建:id指明bean的id,class指明bean的类型,constructor-arg标签用于指定对应的构造方法参数。(除value直接指定基本数据类型的值外,对于其它bean可通过赋予ref值为其它bean的id来赋予。)
<bean id="user" class="org.meyok.springlearn.entity.User"> <constructor-arg name="id" value="1"/> <constructor-arg name="username" value="MeYok"/> </bean> -
静态工厂创建:class我们设置的静态工厂类,factory-method指定静态工厂类的方法,该方法为static,返回值为生成的bean。方法需要参数,使用constructor-arg标签传入。
<bean id="user" class="org.meyok.springlearn.factory.StaticFactory" factory-method="getUser"> <constructor-arg name="username" value="MeYok"/> </bean> -
实例工厂创建:实例工厂需要先创建工厂的bean,再创建对应的bean。
<bean id="factory" class="org.meyok.springlearn.factory.DynamicFactory"/> <bean id="user" factory-bean="factory" factory-method="getUser"> <constructor-arg name="username" value="MeYok"/> </bean>
Bean创建时可通过property标签指定属性的值。比如这里有一个Test类,Bean中指定其属性值的方法如下:
public class Test { private List<String> strList; private Map<String, User> userMap; private Properties properties; // 省去构造方法及getter、setter } <bean id="test" class="org.meyok.springlearn.entity.Test"> <property name="strList"> <list> <value>ChengDu</value> <value>UESTC</value> <value>SE</value> </list> </property> <property name="userMap"> <map> <!-- value-ref的值为其它bean的id --> <entry key="u1" value-ref="user"/> <entry key="u2" value-ref="user"/> </map> </property> <property name="properties"> <props> <prop key="username">MeYok</prop> <prop key="gender">male</prop> </props> </property> </bean> Bean创建时可通过init-method、destroy-method属性指定Bean在创建及销毁时执行的方法。
public class User { // 省去属性、构造方法及getter、setter public void init() { System.out.println("init..."); } public void destroy() { System.out.println("destroy..."); } } <bean id="user" class="org.meyok.springlearn.entity.User" init-method="init" destroy-method="destroy"/> import标签可导入其它applicationContext.xml:
<import resource="applicationContext-user.xml"/> Bean的scope有五种类型:
- Singleton(默认):表示Spring容器只创建一个bean的实例,Spring在创建第一次后会缓存起来,之后不再创建,就是设计模式中的单例模式。
- Prototype:代表线程每次调用这个bean都新创建一个实例。
- Request:表示每个request作用域内的请求只创建一个实例。
- Session:表示每个session作用域内的请求只创建一个实例。
- GlobalSession:这个只在porlet的web应用程序中才有意义,它映射到porlet的global范围的session,如果普通的web应用使用了这个scope,容器会把它作为普通的session作用域的scope创建。
可通过scope属性在创建bean的时候修改:
<bean id="user" class="org.meyok.springlearn.entity.User" scope="prototype"/> -
-
context
在context导入配置文件需要context:property-placeholder标签,location指定配置文件,如配置c3p0连接池:
<context:property-placeholder location="classpath:jdbc.properties"/> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="driverClass" value="${jdbc.driver}"/> <property name="jdbcUrl" value="${jdbc.url}"/> <property name="user" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </bean> Bean支持注解方式配置,此时需要context:component-scan标签配置组件扫描,如:
<context:component-scan base-package="org.meyok.springlearn"/>
除了XML文件进行配置,也可通过注解方法进行配置。
首先需要一个核心配置类:
@Configuration @ComponentScan("org.meyok.springlearn") @Import(DataSourceConfiguration.class) public class SpringConfiguration { }
Configuration注解标志该类是Spring的核心配置类。ComponentScan注解作用同于context:component-scan标签,指定组件扫描。Import同于import标签,指定配置文件,只是这里的配置文件不是properties而是Java类,对应的Java类如下所示:
@PropertySource("classpath:jdbc.properties") public class DataSourceConfiguration { @Value("${jdbc.driver}") private String driver; @Value("${jdbc.url}") private String url; @Value("${jdbc.username}") private String username; @Value("${jdbc.password}") private String password; @Bean("dataSource") //Spring会将当前方法的返回值以指定名称存储到Spring容器中 public DataSource getDataSource() throws PropertyVetoException { ComboPooledDataSource dataSource = new ComboPooledDataSource(); dataSource.setDriverClass(driver); dataSource.setJdbcUrl(url); dataSource.setUser(username); dataSource.setPassword(password); return dataSource; } }
PropertySource注解指定配置文件,相当于context:property-placeholder标签。Value注解指定值,相当于value属性。Bean注解将方法的返回值指定为对应的bean,相当于bean标签。
除了Bean注解,Component注解(Repository、Service、Controller)也可以注入Bean,只是它是注解在类上的。可通过Scope注解修改Bean的scope。比如以下service:
@Service("userService") @Scope("singleton") public class UserServiceImpl implements UserService { @Value("${jdbc.driver}") private String driver; @Resource(name = "userDao") private UserDao userDao; @PostConstruct public void init() { System.out.println("init..."); } @PreDestroy public void destroy() { System.out.println("destroy..."); } }
其中,可通过Autowired注解或者Resource注解来注入属性,相当于带ref属性的property标签。Autowired是按照数据类型从Spring容器中进行匹配的,可添加Qualifier注解指定id,而Resource注解相当于Autowired注解+Qualifier注解。PostConstruct注解相当于init-method属性,PreDestroy相当于destroy-method属性。Autowired注解可用于构造函数、成员变量、Setter方法,默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false),而Resource注解默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
PS:
-
context:annotation-config标签只会激活Autowired注解和Resource注解,而context:component-scan标签不仅具有context:annotation-config标签的功能,还会激活Component注解。
-
Spring测试类修改RunWith,添加ContextConfiguration注解
@RunWith(SpringJUnit4ClassRunner.class) //@ContextConfiguration("classpath:applicationContext.xml") @ContextConfiguration(classes = {SpringConfiguration.class}) public class SpringJunitTest { @Autowired private UserService userService; @Autowired private DataSource dataSource; @Test public void test() { // TODO test } }
AOP
<!--Spring本身有aop实现,但aspectj更好,spring融入并推荐了--> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> </dependency>
AOP(Aspect-Oriented Programming),即面向切面编程,它与 OOP( Object-Oriented Programming,面向对象编程) 相辅相成,提供了与 OOP 不同的抽象软件结构的视角。在 OOP 中,我们以类(class)作为我们的基本单元,而 AOP 中的基本单元是 Aspect(切面)。
Spring AOP 默认使用标准的 JDK 动态代理(dynamic proxy)技术来实现 AOP 代理,通过它,我们可以为任意的接口实现代理。
applicationContext.xml基本格式如下:(xsi:schemaLocation中顺序分别为bean相关、aop相关。)
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation= "http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"> <!-- TODO 配置 --> </beans>
AOP织入需要准备ITarget接口,以及其实现类Target即加强对象,Advice增强方法。实例如下:
public interface ITarget { void save(); }
public class Target implements ITarget { @Override public void save() { System.out.println("save running..."); // int i = 1/0; } }
public class Advice { public void before(){ System.out.println("前置增强...."); } public void afterReturning(){ System.out.println("后置增强...."); } public Object around(ProceedingJoinPoint pjp) throws Throwable { System.out.println("环绕前增强...."); Object proceed = pjp.proceed(); System.out.println("环绕后增强...."); return proceed; } public void afterThrowing(){ System.out.println("异常抛出增强...."); } public void after(){ System.out.println("最终增强...."); } }
而applicationContext.xml文件中相应的配置如下:
<!-- 目标对象 --> <bean id="target" class="org.meyok.springlearn.aop.Target"></bean> <!-- 切面对象 --> <bean id="advice" class="org.meyok.springlearn.aop.Advice"></bean> <!-- 配置织入:告诉spring框架 哪些方法(切点)需要进行那些增强(前置,后置...) --> <aop:config> <!-- 声明切面 --> <aop:aspect ref="advice"> <!-- 切面:切点+通知 --> <aop:before method="before" pointcut="execution(public void org.meyok.springlearn.aop.Target.save())"/> <aop:before method="before" pointcut="execution(* org.meyok.springlearn.aop.*.*(..))"/> <aop:after-returning method="afterReturning" pointcut="execution(* org.meyok.springlearn.aop.*.*(..))"/> <aop:around method="around" pointcut="execution(* org.meyok.springlearn.aop.*.*(..))"/> <aop:after-throwing method="afterThrowing" pointcut="execution(* org.meyok.springlearn.aop.*.*(..))"/> <aop:after method="after" pointcut="execution(* org.meyok.springlearn..aop.*.*(..))"/> <!-- 当同一个切点有多个通知织入时,可将切点抽取为表达式 --> <aop:pointcut id="myPointcut" expression="execution(* org.meyok.springlearn.aop.*.*(..))"/> <aop:around method="around" pointcut-ref="myPointcut"/> <aop:after method="after" pointcut-ref="myPointcut"/> </aop:aspect> </aop:config>
当我们注入ITarget对象时,对象会被代理,调用的方法也会被增强。
通过注解的方法实现AOP时,可使用Aspect注解标注Advice表明其为切面,通过相应注解就可实现织入,示例如下:
@Component("Advice") @Aspect public class Advice { //定义切点表达式 @Pointcut("execution(* org.meyok.springlearn.aop.*.*(..))") public void pointcut(){} @Before(value = "pointcut()") public void before(){ System.out.println("前置增强...."); } public void afterReturning(){ System.out.println("后置增强...."); } @Around("execution(* org.meyok.springlearn.aop.*.*(..))") public Object around(ProceedingJoinPoint pjp) throws Throwable { System.out.println("环绕前增强...."); //切点方法 Object proceed = pjp.proceed(); System.out.println("环绕后增强...."); return proceed; } public void afterThrowing(){ System.out.println("异常抛出增强...."); } @After("Advice.pointcut()") public void after(){ System.out.println("最终增强...."); } }
applicationContext.xml文件中,可使用更高效的aspectj,添加相应的标签即可。
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation= "http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"> <context:component-scan base-package="org.meyok.springlearn"/> <!--aop自动代理--> <aop:aspectj-autoproxy/> </beans>
其它
-
事务管理
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-tx</artifactId> </dependency> Spring提供了相应的事务解决方案,在方法上添加Transactional注解。
关于事务的转播行为,可通过propagation参数进行设置,其值可取以下:
public enum Propagation { REQUIRED(0), SUPPORTS(1), MANDATORY(2), REQUIRES_NEW(3), // 开启新事务,A事务中套B事务,B事务不会使用A相同的事务 NOT_SUPPORTED(4), NEVER(5), NESTED(6); } Spring默认的回滚策略为抛出异常就回滚,但可设置noRollbackFor来排除特定异常回滚,如以下方法出现任何异常都不会回滚:
@Transactional(noRollbackFor = Exception.class) public void method() { } Spring默认的隔离级别是RR,可通过isolation来进行设置,其可取值如下:
public enum Isolation { DEFAULT(-1), READ_UNCOMMITTED(1), READ_COMMITTED(2), REPEATABLE_READ(4), SERIALIZABLE(8); } -
JDBCTemplate
Spring配置文件导入JDBCTemplate可通过如下所示:
<context:property-placeholder location="classpath:jdbc.properties"/> <!--数据源对象--> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="driverClass" value="${jdbc.driver}"/> <property name="jdbcUrl" value="${jdbc.url}"/> <property name="user" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </bean> <!--jdbc模板对象--> <bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"> <property name="dataSource" ref="dataSource"/> </bean> -
异常处理器
可使用Spring提供好的ExceptionResolver进行配置,value表示出错时转向视图,示例如下(这里我们自己设计了MyException):
<bean class="org.springframework.web.servlet.handler.SimpleMappingExceptionResolver"> <property name="defaultErrorView" value="error"/> <property name="exceptionMappings"> <map> <entry key="java.lang.ClassCastException" value="error1"/> <entry key="org.meyok.springlearn.exception.MyException" value="error2"/> </map> </property> </bean> 我们也可以自定义异常处理器:
<bean class="org.meyok.springlearn.resolver.MyExceptionResolver"/> public class MyExceptionResolver implements HandlerExceptionResolver { @Override public ModelAndView resolveException(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) { ModelAndView modelAndView = new ModelAndView(); if (ex instanceof MyException) { modelAndView.addObject("info", "自定义异常"); } else if (ex instanceof ClassCastException) { modelAndView.addObject("info", "类转换异常"); } modelAndView.setViewName("error"); return modelAndView; } } 注解方式:
@ControllerAdvice public class ProjectExceptionAdvice { @ExceptionHandler(Exception.class) public void doException(Exception e) { //记录日志 //通知运维 //通知开发 } }
PS:Spring为我们的项目提供了相应的在web.xml中配置常用实现类:
<!--Spring的监听器--> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <!--解决乱码的过滤器--> <filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> </filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
2.1.2.Spring MVC
Spring MVC是一个Java框架,用于构建Web应用程序。它遵循Model-View-Controller设计模式。它实现了核心Spring框架的所有基本功能,例如控制反转,依赖注入。
PS:Spring MVC相关依赖(包含Spring基础)
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> </dependency>
工作流程
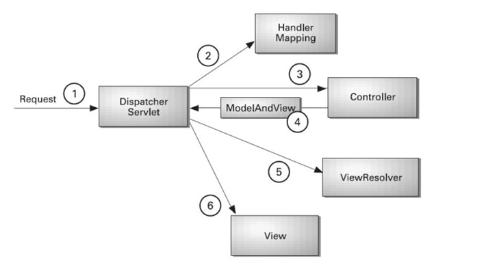
所有传入的请求都被充当前端控制器的DispatcherServlet拦截。DispatcherServlet从XML文件获取处理程序映射的条目,并将请求转发给控制器。控制器返回ModelAndView对象。DispatcherServlet检查XML文件中的视图解析器条目,并调用指定的视图组件。
配置文件
Spring MVC的配置文件一般和Spring的配置文件分开。在web.xml文件中,需要指明Spring与Spring MVC各自的配置文件,如下:
<!-- 全局初始化参数 --> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext.xml</param-value> </context-param> <!-- 配置SpringMVC的前端控制器 --> <servlet> <servlet-name>DispatcherServlet</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:spring-mvc.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>DispatcherServlet</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping>
上面部分指明Spring的配置文件,下面部分在DispatcherServlet这个servlet中指明Spring MVC的配置文件。
spring-mvc.xml的相关配置如下:
-
DispatcherServlet
在web.xml中我们配置DispatcherServlet会拦截所有的路径请求,而不会拦截 * .jsp,* .html,* .js。而对于mvc的静态资源,比如.css,也会被拦下,此时我们可以通过mvc:resources进行配置来防止资源无法访问(需要添加
<mvc:annotation-driven/>):<mvc:resources mapping="/js/**" location="/js/"/> <mvc:resources mapping="/img/**" location="/img/"/> ... 或者设置为交给Web应用服务器处理:
<mvc:default-servlet-handler/> -
Controller
<context:component-scan base-package="org.meyok.springlearn"> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"/> </context:component-scan> 配置Controller的注解扫描,一般要用include-filter将Controller类加入到白名单,而Spring配置中使用exclude-filter将Controller加入到黑名单。因为在spring容器初始化的时候,会先加载web.xml中context-param中的配置,之后再加载servlet中的init-param配置。加载springmvc的时候,如果扫描到service注解会重新加载这个service的bean(都是没有aop配置事务控制的),可能会覆盖之前的service,导致service的事务失效。
-
MappingHandler
<bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter"> <property name="messageConverters"> <list> <bean class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter"/> </list> </property> </bean> 配置MappingHandler的处理器映射器,Json与message的相互转换,如上所示。但也可以使用mvc的默认配置:
<mvc:annotation-driven/> 我们也可以利用该默认配置添加一些自定义的convert,如日期转换:
<mvc:annotation-driven conversion-service="dateConverter"/> <bean id="dateConverter" class="org.springframework.context.support.ConversionServiceFactoryBean"> <property name="converters"> <list> <bean class="org.meyok.springlearn.converter.DateConverter"></bean> </list> </property> </bean> 我们自定义的转化器如下:
public class DateConverter implements Converter<String, Date> { @Override public Date convert(String dateStr) { //将日期字符串转换成日期对象 返回 SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd"); Date date = null; try { date = format.parse(dateStr); } catch (ParseException e) { e.printStackTrace(); } return date; } } -
ViewResolver
<bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="prefix" value="/jsp/"></property> <property name="suffix" value=".jsp"></property> </bean> 配置prefix与suffix,在Controller中,return页面时可只写页面的部分名称,简化代码。
-
其它
<!--配置文件上传解析器--> <bean id="multipartResolver" class="org.springframework.web.multipart.commons.CommonsMultipartResolver"> <property name="defaultEncoding" value="UTF-8"/> <property name="maxUploadSize" value="50000000000"/> </bean>
Controller
通过RequestMapping注解来配置映射,标注在Controller类上或方法上。方法的返回类型为String,return直接返回页面,可添加ResponseBody来表明返回数据。也可返回ModelAndView(包括单个),Model封装数据,addObject方法添加键值对,View展示数据,setViewName方法设置要返回的视图名。
PS:mvc中可配置拦截器对资源请求进行拦截并做出相应操作:
<!--配置拦截器--> <mvc:interceptors> <mvc:interceptor> <!--代表对哪些资源执行拦截操作--> <mvc:mapping path="/**"/> <bean class="org.meyok.springlearn.interceptor.MyInterceptor"/> </mvc:interceptor> </mvc:interceptors>
public class MyInterceptor implements HandlerInterceptor { // 在目标方法执行之前执行 // 返回true代表放行 返回false代表不放行 @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { return true; } // 在目标方法执行之后视图返回之前执行 @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { } // 在整个流程都执行完毕后执行 @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { } }
PS:
- RequestMapping中produces属性可以设置返回数据的类型以及编码,可以是json或者xml。
2.1.3.Spring Boot
Spring Boot是一个构建在Spring框架顶部的项目。它提供了一种简便,快捷的方式来设置,配置和运行基于Web的简单应用程序。它是一个Spring模块,提供了RAD(快速应用程序开发)功能。它用于创建独立的基于Spring的应用程序,因为它需要最少的Spring配置,因此可以运行。
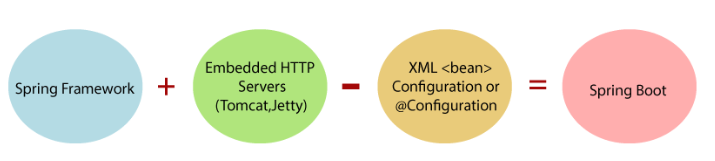
Spring Boot源代码模块
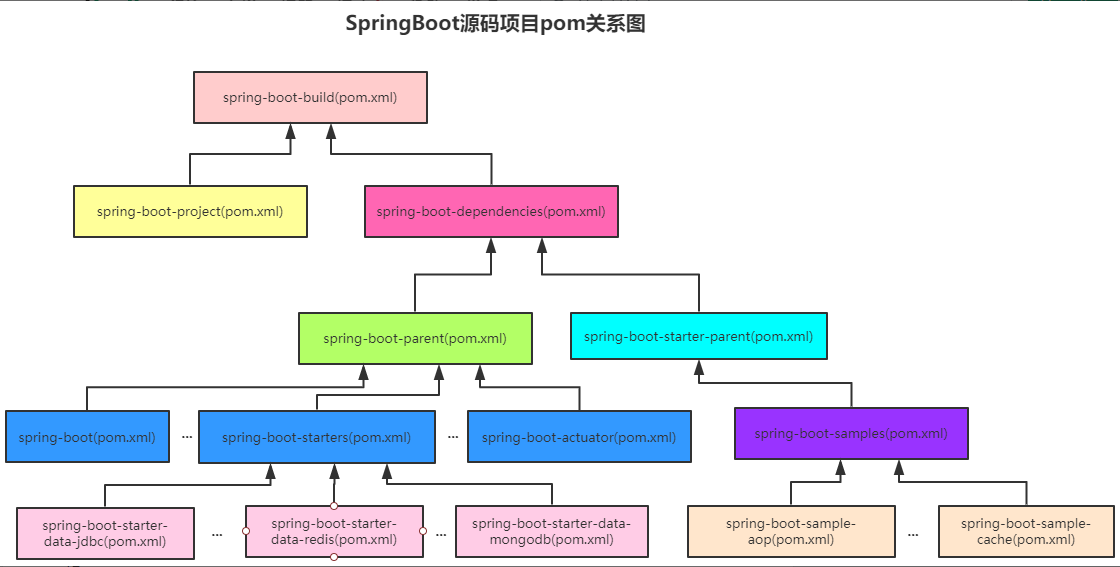
spring-boot-build是项目的根pom。子pom中spring-boot-project起到聚合module的作用,其子模块并不继承于它,而是继承于spring-boot-parent。spring-boot-dependencies主要定义了Spring Boot项目的各种依赖及其版本。spring-boot-starter是所有具体起步依赖的父pom,我们的所有具体SpringBoot项目是继承于它的,比如SpringBoot自带的样例的spring-boot-samples。
Spring Boot简化了我们Spring项目开发,包含默认的Web内嵌服务器,因而不用我们自己部署服务到Tomcat上。同时也不需要我们编写XML文件,它为我们进行默认配置,而修改/添加配置可通过编写application配置文件。
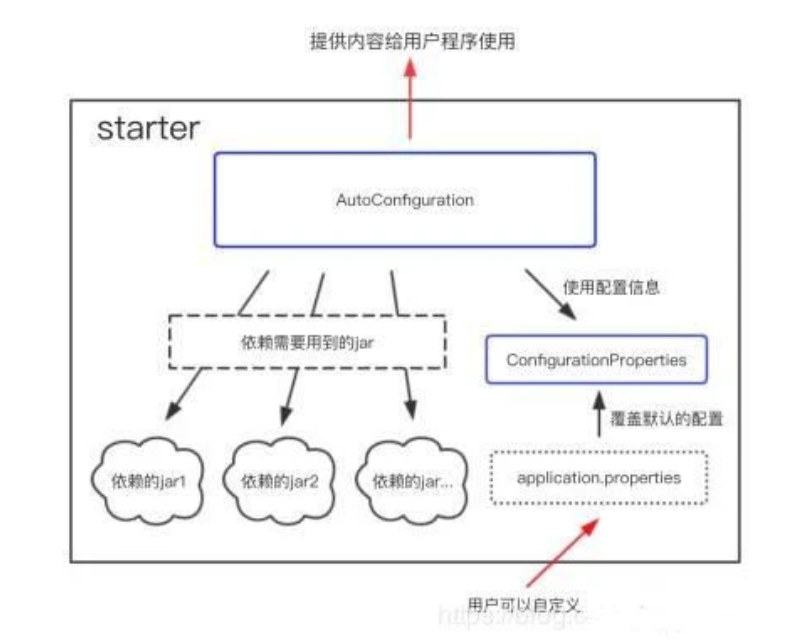
项目构成
Spring Boot项目首先需要一个启动类(假设这里是DemoApplication),添加SpringBootApplication注解表明这是个主配置类,Spring Boot项目启动后,会运行该类的main方法。SpringBootApplication被SpringBootConfiguration注解标注,而SpringBootConfiguration注解又被Configuration标注,表明这是个配置类;SpringBootApplication被EnableAutoConfiguration注解标注,表示启用自动配置;SpringBootApplication被ComponentScan注解标注,表明了需要扫描的Component。
启动类DemoApplication中执行SpringApplication.run(DemoApplication.class, args)方法来运行SpringBoot项目,args参数为我们运行main方法的临时配置,该方法的返回值为ConfigurableApplicationContext这个context。
相关配置
spring boot配置文件优先级从高到低(相同情况下最前者配置生效)为项目根目录中config目录下(运维组长)、项目根目录下(运维人员)、项目resources目录中config目录下(项目经理)、项目的resources目录下(程序员),且properties文件优先级高于yml。
如果配置文件名不为application.yml,为自定义名字,如ebank.yml。可添加参数--spring.config.name=ebank或-spring.config.location=classpath:/ebank.yml。
PS:
-
lombok中包含slf4j和log4j注解快速创建log。
-
logging.level配置日志级别,默认使用LogBack日志系统,默认的日志级别为INFO。level下,选择root、sql、web、包名可分别进行相应的日志级别配置。
-
logging.pattern配置日志样式,选择console、file等分别进行配置。
-
若将日志打印在文件中,使用logging.file.path进行配置.
-
ConfigurationProperties注解类上,通常要与Component注解或Configuration注解一起使用,可将prefix中指明的配置绑定到类的属性上,如:
datasource: driver: com.mysql.cj.jdbc.Driver url: jdbc:mysql:///springlearn?serverTimezone=UTC username: ****** password: ******
@Component @ConfigurationProperties(prefix = "datasource") public class MyDataSource { private String driver; private String url; private String username; private String password; // 省略构造方法、getter/setter、toString }
- spring boot测试,添加SpringBootTest注解,若测试类Application不在源引导类Application的包及其子包下,需要添加classes来指定源Application。如果不使用classes属性,也可以使用ContextConfiguration注解。
@SpringBootTest(classes = Springboot04JunitApplication.class) //@ContextConfiguration(classes = Springboot04JunitApplication.class) class Springboot04JunitApplicationTests { //1.注入要测试的对象 @Autowired private BookDao bookDao; @Test void contextLoads() { //2.执行要测试的对象相应的方法 bookDao.save(); } }
- Commons IO是针对开发IO流功能的工具类库。Common FileUpload依赖于Commons IO,处理文件上传依赖包。
- Jackson依赖:
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> </dependency>
2.1.4.Spring Cloud
Spring Cloud 是分布式微服务架构的一站式解决方案,它提供了一套简单易用的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务系统的构建。
Spring Cloud 本身并不是一个拿来即可用的框架,它是一套微服务规范,共有两代实现。
- Spring Cloud Netflix 是 Spring Cloud 的第一代实现,主要由 Eureka、Ribbon、Feign、Hystrix 等组件组成。
- Spring Cloud Alibaba 是 Spring Cloud 的第二代实现,主要由 Nacos、Sentinel、Seata 等组件组成。
Eureka
Nacos
Gateway
2.2.Business
2.2.1.MyBatis
依赖:
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> </dependency>
架构解析
Mybatis的架构可分为三层:
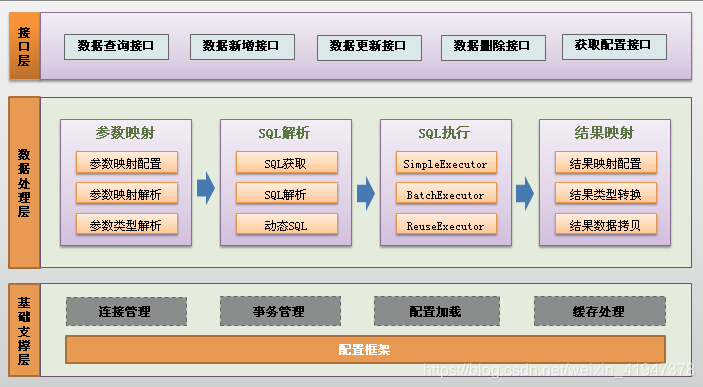
- 接口层:MyBatis提供给开发人员的一套API,主要表现在SqlSession接口,通过SqlSession接口开发人员就可以通知mybatis框架调用哪一条sql以及sql命令关联的参数,完成对数据库CRUD。这层主要考虑的就是使用人的需求,用起来怎么方便接口就怎么设计,属于对外的接口。
- 数据处理层:数据处理层就是具体解析和执行sql的地方,是MyBatis框架内部的核心,底层最终还是调用JDBC代码来执行的。这层就是通过对JDBC执行sql的步骤进行了拆解,划分了不同模块,同时抽象出了很多组件,每个组件各司其职,通过协作让整个sql执行更加灵活。
- 基础支撑层:支撑层用来完成MyBaits与数据库基本连接方式以及SQL命令与配置文件对应,主要负责MyBatis与数据库连接方式管理、MyBatis对事务管理方式、配置文件加载、MyBatis查询缓存管理。
四大组件:Exucutor、StatementHandler、ParameterHandler、ResultSetHandler,各司其职,让SQL执行流程更加灵活。
流程解析
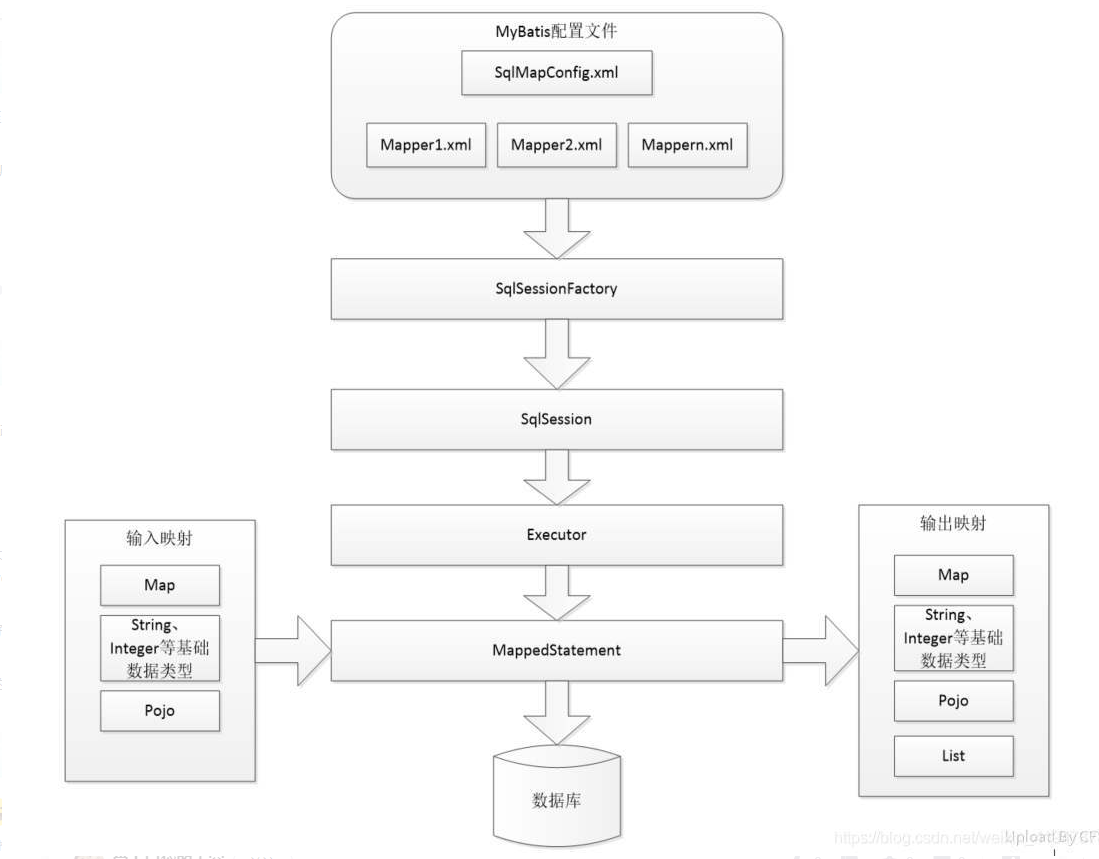
SqlMapConfig.xml作为mybatis的全局配置文件,配置了mybatis的运行环境等信息。Mapper.xml作为mybatis的sql映射文件,文件中配置了操作数据库的sql语句,此文件需要在SqlMapConfig.xml中加载。上面的两个配置文件在框架运行的一开始就会被解析,并将所有的配置信息封装到Configuration.java对象中。
SqlSessionFactory通过SqlSessionFactoryBuilder.java工具类构建而成的,在SqlSessionFactoryBuilder.java中先通过XMLConfigBuilder.java工具类解析上面mybatis的配置文件后,会得到一个Configuration对象,里面包含所有的配置信息,然后创建一个SqlSessionFactory接口实现类的对象,并且将Configuration传递到SqlSessionFactory接口实现类的对象中去。
通过SqlSessionFactory创建sqlSession会话,程序员就是通过sqlsession会话接口对数据库进行增删改查操作,这个是mybatis对外提供的操作接口。
mybatis底层定义了Executor执行器接口来具体操作数据库, 而上面的对外接口sqlsession底层就是通过executor接口操作数据库的。Executor接口有两个实现, 一个是基本执行器BaseExecutor(是一个抽象类,采用模板方法设计模式,基本执行器下面又分为简单执行器、可重用执行器、批量执行器…)、一个是缓存执行器 CachingExecutor,Executor是mybatis内部的执行接口,四大组件之一。
MappedStatement是mybatis一个底层封装对象,它包装了mybatis配置信息及sql映射信等。映射文件中每一个select\insert\update\delete标签都对应一个Mapped Statement对象,select\insert\update\delete标签的id即是Mapped statement的id,此外还封装了标签中的sql语句(SqlSource),参数类型,结果集类型,statment类型等(JDBC中,有三种Statement类型,Statement,PreparedStatment,CallableStatment)。MappedStatement对sql执行的输入参数进行定义,支持HashMap、基本类型、pojo,Executor在MappedStatement执行sql前将输入的java对象映射至sql中,输入参数映 射过程相当于jdbc编程中对preparedStatement设置参数。MappedStatement对sql执行的输出结果进行定义,支持HashMap、基本类型、pojo,Executor在MappedStatemen执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程。
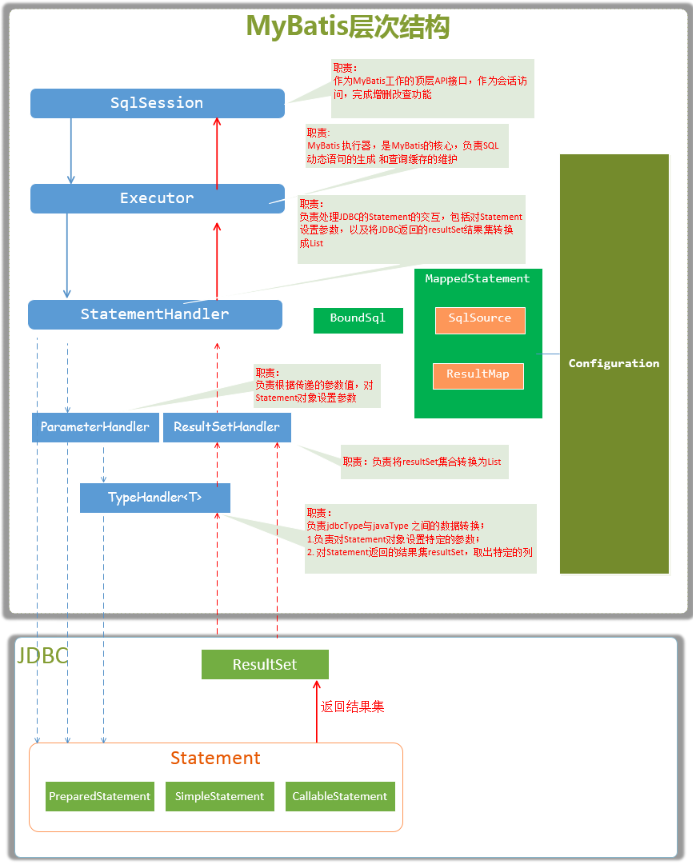
实现
首先需要我们编写核心配置文件sqlMapConfig.xml,其中,需要我们配置数据源,指定加载映射文件:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!--通过properties标签加载外部properties文件--> <properties resource="jdbc.properties"/> <!--当前数据源环境--> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"></transactionManager> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments> <!--加载映射文件--> <mappers> <mapper resource="org/meyok/mybatislearn/mapper/UserMapper.xml"></mapper> </mappers> </configuration>
为了在编写Mapper配置文件时避免实体类名字过长,我们一般也在核心配置文件中给实体类取别名:
<!--自定义别名--> <typeAliases> <typeAlias type="org.meyok.mybatislearn.entity.User" alias="user"/> </typeAliases> <!--也可通过包定义,别名为首字母小写的类名--> <typeAliases> <package name="org.meyok.mybatislearn.entity"/> </typeAliases>
然后,编写Mapper配置文件,需要我们写出SQL语句:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="userMapper"> <!--查询操作--> <select id="findAll" resultType="user"> SELECT * FROM user </select> <!--插入操作--> <insert id="save" parameterType="user"> INSERT INTO user VALUES(#{id}, #{username}, #{password}) </insert> <!--修改操作--> <update id="update" parameterType="user"> UPDATE user SET username = #{username}, password = #{password} WHERE id = #{id} </update> <!--删除操作--> <delete id="delete" parameterType="int"> DELETE FROM user WHERE id = #{id} <!--一个参数可以直接写#{x},x为任意值包括空--> </delete> <!--根据id进行查询操作--> <select id="findById" parameterType="int" resultType="user"> SELECT * FROM user WHERE id = #{id} </select> </mapper>
最后在Java代码内即可执行相应语句:
public void test() throws IOException { // 获得核心配置文件 InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); // 获得session工厂对象 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); // 获得session对话对象 SqlSession sqlSession = sqlSessionFactory.openSession(); // 执行操作 参数:namespace+id List<User> userList = sqlSession.selectList("userMapper.findAll"); // 打印数据 System.out.println(userList); // 释放资源 sqlSession.close(); }
除此之外,我们可以将Java接口中的方法与SQL语句对应,如有如下UserMapper.java接口,它的Mapper.xml配置文件与执行方法可以如下:
public interface UserMapper { List<User> findByCondition(User user); List<User> findByIds(List<Integer> Ids); }
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="org.meyok.mybatislearn.mapper.UserMapper"> <!--sql语句抽取--> <sql id="selectUser">SELECT * FROM user</sql> <select id="findByCondition" parameterType="user" resultType="user"> <include refid="selectUser"/> <where> <if test="id != 0"> AND id = #{id} </if> <if test="username != null"> AND username = #{username} </if> <if test="password != null"> AND password = #{password} </if> </where> </select> <select id="findByIds" parameterType="list" resultType="user"> <include refid="selectUser"/> <where> <foreach collection="list" open="id IN(" close=")" item="id" separator=","> #{id} </foreach> </where> </select> </mapper>
@Test public void test() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession sqlSession = sqlSessionFactory.openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<Integer> ids = new ArrayList<>(); ids.add(1); ids.add(2); List<User> users = mapper.findByIds(ids); System.out.println(users); sqlSession.close(); }
关于自定义类型处理器,我们需要继承BaseTypeHandler,然后在核心配置文件注册即可,如下配置Java的Date与JDBC的Long转换的处理器:
public class DateTypeHandler extends BaseTypeHandler<Date> { //负责将Java类型 转换成 数据库需要的类型 @Override public void setNonNullParameter(PreparedStatement preparedStatement, int i, Date date, JdbcType jdbcType) throws SQLException { long time = date.getTime(); preparedStatement.setLong(i, time); } //将数据库中类型 转换成Java类型 //String参数 要转换的字段名称 //ResultSet 查询出的结果集 @Override public Date getNullableResult(ResultSet resultSet, String s) throws SQLException { //获得结果集中需要的数据(long)转换成Date类型 返回 long aLong = resultSet.getLong(s); Date date = new Date(aLong); return date; } @Override public Date getNullableResult(ResultSet resultSet, int i) throws SQLException { long aLong = resultSet.getLong(i); Date date = new Date(aLong); return date; } @Override public Date getNullableResult(CallableStatement callableStatement, int i) throws SQLException { long aLong = callableStatement.getLong(i); Date date = new Date(aLong); return date; } }
<typeHandlers> <typeHandler handler="org.meyok.mybatislearn.handler.DateTypeHandler"/> </typeHandlers>
配置分页助手:
<!--导入依赖--> <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> </dependency> <dependency> <groupId>com.github.jsqlparser</groupId> <artifactId>jsqlparser</artifactId> </dependency>
<!--配置分页助手插件--> <plugins> <plugin interceptor="com.github.pagehelper.PageHelper"> <property name="dialect" value="mysql"/> </plugin> </plugins>
//设置分页相关参数 当前页+每页显示的条数 PageHelper.startPage(3, 3); //执行保存操作 List<User> users = mapper.findAll(); for (User user : users) { System.out.println(user); } //获得与分页相关的参数 PageInfo<User> pageInfo = new PageInfo<>(users); System.out.println("当前页:"+pageInfo.getPageNum()); System.out.println("每页显示条数:"+pageInfo.getPageSize()); System.out.println("总条数:"+pageInfo.getTotal()); System.out.println("总页数:"+pageInfo.getPages()); System.out.println("上一页:"+pageInfo.getPrePage()); System.out.println("下一页:"+pageInfo.getNextPage()); System.out.println("是否是第一页:"+pageInfo.isIsFirstPage()); System.out.println("是否是最后一页:"+pageInfo.isIsLastPage());
Mapper.xml中,封装返回数据时,可指定数据库中字段与entity的元素映射:
<resultMap id="orderMap" type="order"> <!-- 手动指定字段与实体关系,column:数据表的字段名称,property:实体的属性名称 --> <id column="oid" property="id" /> <result column="orderTime" property="orderTime"/> <result column="total" property="total"/> <!-- 封装类包含其它类,下面方法二选一 --> <!-- 1. --> <result column="uid" property="user.id"/> <result column="username" property="user.username"/> <result column="password" property="user.password"/> <result column="birthday" property="user.birthday"/> <!-- 2. --> <!-- property:当前实体(order)中的属性名称(private User user),javaType:当前实体(order)中的属性名称(User) --> <association property="user" javaType="user"> <id column="uid" property="id"/> <id column="username" property="username"/> <id column="password" property="password"/> <id column="birthday" property="birthday"/> </association> </resultMap> <select id="findAll" resultMap="orderMap"> SELECT *, o.id oid FROM orders o, user u WHERE o.uid = u.id </select> <resultMap id="userMap" type="user"> <id column="uid" property="id"/> <result column="username" property="username"/> <result column="password" property="password"/> <result column="birthday" property="birthday"/> <!-- 配置集合信息,property:集合名称,ofType:当前集合中的数据类型 --> <collection property="orderList" ofType="order"> <!--封装order的数据--> <id column="oid" property="id"/> <result column="orderTime" property="orderTime"/> <result column="total" property="total"/> </collection> </resultMap> <select id="findAll" resultMap="userMap"> SELECT *, o.id oid FROM user u, orders o WHERE o.uid = u.id </select>
若使用注解方法,可直接在对应的Mapper接口的方法上标注,而不用编写Mapper文件,但也需要在核心配置文件中指明mapper包:
<mappers> <package name="org.meyok.mybatislearn.mapper"/> </mappers>
public interface OrderMapper { @Select("SELECT * FROM orders") @Results({ @Result(id = true, column = "oid", property = "id"), @Result(column = "orderTime", property = "orderTime"), @Result(column = "total", property = "total"), @Result( property = "user", // 要封装的属性名称是谁 column = "uid", // 根据哪个字段去查询user表中的数据 javaType = User.class, // 要封装的实体类型 //select属性 代表查询那个接口的方法获得数据 one = @One(select = "org.meyok.mybatislearn.mapper.UserMapper.findById") ) }) List<Order> findAll(); @Select("SELECT * FROM orders WHERE uid = #{uid}") List<Order> findByUid(int uid); }
public interface UserMapper { @Select("SELECT * FROM user") @Results({ @Result(id = true, column = "id", property = "id"), @Result(column = "username", property = "username"), @Result(column = "password", property = "password"), @Result( property = "roleList", column = "id", javaType = List.class, many = @Many(select = "org.meyok.mybatislearn.mapper.RoleMapper.findByUid") ) }) List<User> findUserAndRoleAll(); }
PS:
将Mybatis整合到Spring中,需要额外导入依赖:
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>2.0.7</version> </dependency>
然后,在spring配置文件中,进行相关Mybatis配置(dataSource为配置的数据库连接池bean。// TODO mybatis还是否需要配置):
<!--配置sessionFactory--> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <!--加载mybatis核心文件--> <property name="configLocation" value="classpath:sqlMapConfig-spring.xml"/> </bean> <!--扫描mapper所在包 为mapper创建实现类--> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="org.meyok.mybatislearn.mapper"/> </bean> <!--声明式事务控制--> <!--平台事务管理器--> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> </bean>
Spring Boot整合
依赖:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency>
HikariCP是一种数据库连接池,mybatis-spring-boot-starter集合了该数据库连接池(如果添加了druid依赖,spring会使用druid而不是hikari)。在配置文件中编写好连接配置后,如果完全使用注解方式,在对应的Mapper接口上添加Mapper注解,方法上添加相应的注解即可。如果使用Mapper配置文件,application中相关配置如下:
# 配置 MyBatis mybatis: mapper-locations: classpath:mapper/* # 用来指定 mapper.xml 文件的路径。 type-aliases-package: org.meyok.mybatislearn.entity # 用来设置别名。 configuration: map-underscore-to-camel-case: true # 用来开启驼峰命名自动映射,如将数据表中的字段user_name映射到实体对象的属性userName。
PS:
- Alias注解可设置entity的别名。
MyBatis-Plus
依赖:
<dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> </dependency>
MyBatis-Plus在MyBatis的基础上,已封装好dao和service基本的CRUD等方法。
在dao上extends对应的BaseMapper,service接口上extends对应的IService,serviceImpl上extends对应的ServiceImpl。以下示例展示了分页查询,需要额外配置分页拦截器:
@Mapper public interface IBookDao extends BaseMapper<Book>{ }
public interface IBookService extends IService<Book> { IPage<Book> getPage(int currentPage, int pageSize); IPage<Book> getPage(int currentPage, int pageSize, Book book); }
@Service public class BookServiceImpl extends ServiceImpl<BookDao, Book> implements IBookService { @Resource private IBookDao bookDao; @Override public IPage<Book> getPage(int currentPage, int pageSize) { IPage page = new Page(currentPage, pageSize); bookDao.selectPage(page, null); return page; } @Override public IPage<Book> getPage(int currentPage, int pageSize, Book book) { LambdaQueryWrapper<Book> lambdaQueryWrapper = new LambdaQueryWrapper<>(); lambdaQueryWrapper.like(Strings.isNotEmpty(book.getType()), Book::getType, book.getType()); lambdaQueryWrapper.like(Strings.isNotEmpty(book.getName()), Book::getName, book.getName()); lambdaQueryWrapper.like(Strings.isNotEmpty(book.getDescription()), Book::getDescription, book.getDescription()); IPage page = new Page(currentPage, pageSize); bookDao.selectPage(page, lambdaQueryWrapper); return page; } }
//mybatis-plus的分页拦截器 @Configuration public class MPConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor()); return interceptor; } }
PS:
- mybatis-plus.global-config.db-config.table-prefix设置表前缀。
- mybatis-plus.configuration.log-impl: org.apache.ibatis.logging.stdout.StdOutImpl开启sql语句打印。
2.2.2.Shiro
Maven依赖:
<!-- 项目依赖,根据情况二选一 --> <!-- 普通项目 --> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-core</artifactId> </dependency> <!-- SpringBoot整合 --> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-spring-boot-starter</artifactId> </dependency> <!-- 缓存依赖,根据情况二选一,第二种是在springboot --> <!-- shiro的默认缓存ehcache --> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-ehcache</artifactId> </dependency> <!-- redis整合springboot --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
核心架构
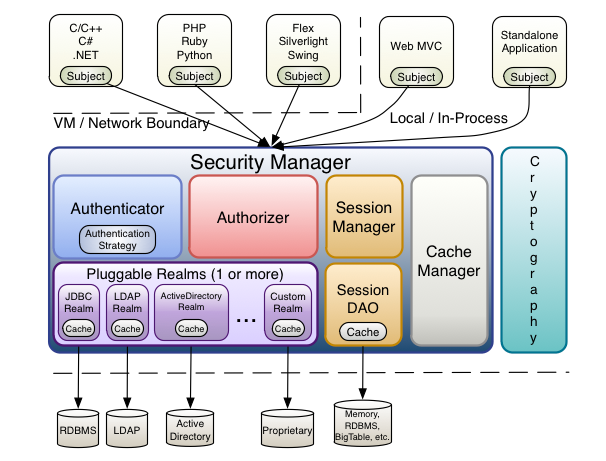
核心为Security Manager,几乎所有功能均为其实现。
- Authenticator:认证。
- Authorizer:授权。
- Session Manager:Web环境下,管理shiro会话。
- Session DAO:对会话数据进行CRUD(对Session Manager中的数据)。
- Cache Manager:缓存认证、授权的数据。
- Realms:域。具体做认证、授权的标配
Cryptography:密码生成器,封装好了相应算法,用于对密码加密。SHA256、MD5等。一般采用MD5做哈希散列。
认证流程
主体(Subject)将身份信息(Principal)和凭证信息(Credential)传给shiro,shiro将其封装为token,token通过Security Manager进行验证(调用Authenticator,Authenticator调用Realm)。
1.基本Demo示例
核心代码:
// 1.创建安全管理器 DefaultSecurityManager securityManager = new DefaultSecurityManager(); // 2.给安全管理器设置Realm securityManager.setRealm(new IniRealm("classpath:shiro.ini")); // 3.SecurityUtils 给全局安全工具类设置安全管理器 SecurityUtils.setSecurityManager(securityManager); // 4.关键对象 subject 主体 Subject subject = SecurityUtils.getSubject(); // 5.创建令牌 UsernamePasswordToken token = new UsernamePasswordToken("xiaochen", "123456"); // 6.用户认证 try { //System.out.println("用户认证前状态:" + subject.isAuthenticated()); subject.login(token); //System.out.println("用户认证后状态:" + subject.isAuthenticated()); } catch (Exception e) { e.printStackTrace(); }
ps:login认证失败时,若为无当前账户会报UnknownAccountException,否则密码错误会报IncorrectCredentialsException。
2.主要源码解析
最终执行用户名比较是SimpleAccountRealm的doGetAuthenticationInfo方法,完成用户名校验。最终密码校验是在AuthenticatingRealm中的assertCredentialsMatch方法(SimpleCredentialsMatcher的doCredentialsMatch方法,拿到token和account的credentials后默认equal比较,后面需要修改为密码比较方法)。(重写Realm,需要我们实现doGetAuthenticationInfo方法,而密码不需要我们实现。)
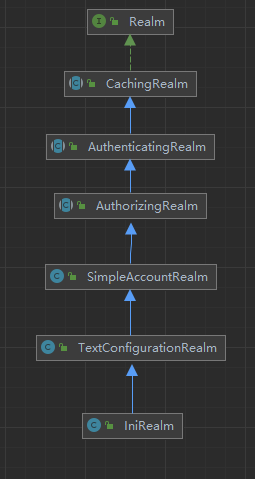
AuthenticatingRealm中doGetAuthenticationInfo方法认证realm,AuthorizingRealm中doGetAuthorizationInfo方法授权realm。
3.自定义realm
实现AuthorizingRealm抽象类doGetAuthenticationInfo方法和doGetAuthorizationInfo方法。
- doGetAuthenticationInfo方法实现
可返回SimpleAuthenticationInfo或者SimpleAccount。
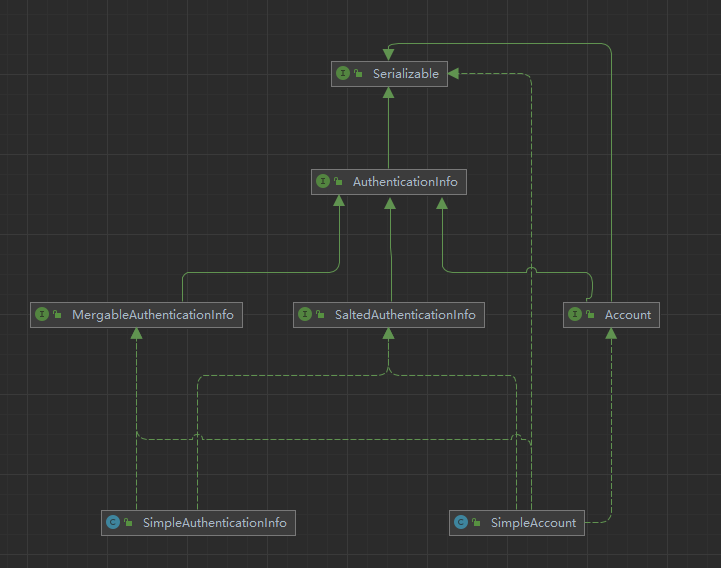
返回null,login时报UnknownAccountException;返回空参SimpleAuthenticationInfo,login时报AuthenticationException。
举例实现:
/** * 认证 * @param authenticationToken * @return * @throws AuthenticationException */ @Override protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException { // 在token中获取用户名 String principal = (String) authenticationToken.getPrincipal(); // 根据身份信息使用jdbc mybatis查询相关数据库 if ("xiaochen".equals(principal)) { // 参数1数据库中正确的用户名 参数2数据库中的正确密码 参数3当前realm的名字 SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(principal, "123", this.getName()); return simpleAuthenticationInfo; } return null; }
- 密码加密
AuthenticatingRealm的credentialsMatcher属性为比较方法,默认equals,可以通过realm的setCredentialsMatcher方法进行设置,可设置以下凭证匹配器:
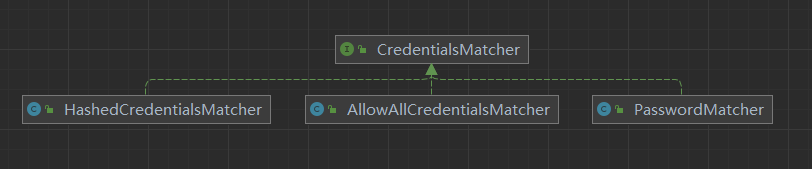
以下,实现对密码进行MD5+salt+hash散列存储(salt默认拼接在原字符串后面;hash散列默认1次,一般设置为1024或者2048次):
- 修改凭证匹配器
// 新建hash凭证匹配器 HashedCredentialsMatcher hashedCredentialsMatcher = new HashedCredentialsMatcher(); // 设置算法 hashedCredentialsMatcher.setHashAlgorithmName("md5"); // 设置realm使用hash凭证匹配器 realm.setCredentialsMatcher(hashedCredentialsMatcher);
- 添加随机盐salt
添加随机盐(随机盐保存至数据库,以下举例耦合死)需要在自定义realm当中,对返回的AuthenticationInfo设置credentialsSalt,即在第三个参数添加盐值,添加方法举例如下:
SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(principal, "c15be9a15a0a238084e0c5a846f3a7b4", ByteSource.Util.bytes("x0*7ps"), // 盐值 this.getName());
- 添加散列次数
调用hash凭证匹配器的setHashIterations方法进行设置。
hashedCredentialsMatcher.setHashIterations(1024);
ps:shiro集成了获得md5加密后的值的算法,如下:
// 参数1加密明文,参数2盐,参数3散列次数 Md5Hash md5Hash = new Md5Hash("123", "x0*7ps", 1024); // toHex 转为String System.out.println(md5Hash.toHex());
授权流程
在完成shiro鉴权之后,就可进行授权了。
- 授权的关键对象:
- 主体(Subject)
- 资源(Resource):包括资源类型(一类资源)和资源实例(一类资源中的某一个)。
- 权限/许可(Permission)
- 授权方式:
- RBAC基于角色的访问控制(Role-Based Access Control)是以角色为中心进行访问控制
if (subject.hasRole("admin")) { // 操作什么资源 }
- RBAC基于资源的访问控制(Resource-Based Access Control)是以资源为中心进行访问控制
if (subject.isPermission("user:update:01")) { // 资源实例 // 对01用户进行修改 } if (subject.isPermission("user:update:*")) { // 资源类型 // 对所有用户进行修改 }
ps:权限字符串规则是资源标识符:操作:资源实例标识符,意思是对哪个资源的那个实例有什么操作。
- 实现方式
- 编程式
if (subject.hasRole("admin")) { // 有权限 } else { // 无权限 }
- 注解式
@RequiredRoles("admin") public void hello() { // TODO 实现方法 }
- 标签式
<!- JSP/GSP标签:在JSP/GSP页面通过相应的标签完成 -> <shiro:hasRole name="admin"> <!- 有权限 -> </shiro:hasRole> <!- ps:Thymeleaf中使用shiro需要额外集成!->
1.Demo示例
- realm授权
在realm的doGetAuthorizationInfo方法中,返回AuthorizationInfo。
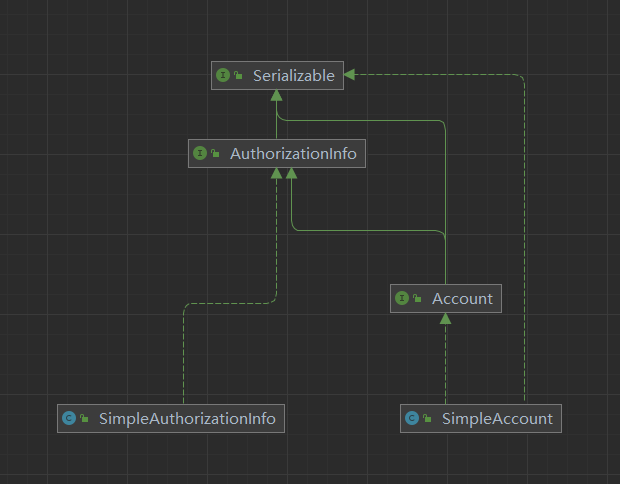
示例代码:
@Override protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) { String primaryPrincipal = (String) principalCollection.getPrimaryPrincipal(); // 根据身份信息获取当前的角色信息,以及权限信息 SimpleAuthorizationInfo simpleAuthorizationInfo = new SimpleAuthorizationInfo(); // 将数据库中查询角色信息赋值给权限对象 // 假设这里xiaochen有admin、user角色信息 simpleAuthorizationInfo.addRole("admin"); simpleAuthorizationInfo.addRole("user"); simpleAuthorizationInfo.addStringPermission("user:*:01"); simpleAuthorizationInfo.addStringPermission("product:create"); return simpleAuthorizationInfo; }
- 核心代码鉴权
// 认证用户进行授权 if (subject.isAuthenticated()) { // 1.基于角色权限控制 // 单角色 System.out.println(subject.hasRole("admin")); // 多角色所有 System.out.println(subject.hasAllRoles(Arrays.asList("admin", "user"))); // 多角色某个 boolean[] booleans = subject.hasRoles(Arrays.asList("admin", "super", "user")); for (boolean aBoolean : booleans) { System.out.println(aBoolean); } // 2.基于权限字符串的访问控制 资源标识符:操作:资源类型 // 单个 System.out.println(subject.isPermitted("user:update:01")); System.out.println(subject.isPermitted("product:update")); // 同时 System.out.println(subject.isPermittedAll("user:*:01", "order:*:10")); // 分别 boolean[] permitted = subject.isPermitted("user:*:01", "order:*:10"); for (boolean b : permitted) { System.out.println(b); } }
Spring Boot整合
1.项目权限管理流程
SpringBoot项目关键加入拦截器ShiroFilter。请求发出,ShiroFilter进行拦截,依赖SecurityManager进行认证,对资源进行相应访问。
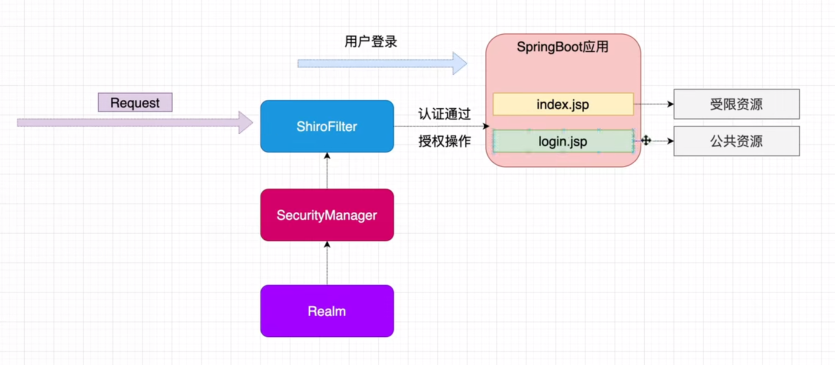
2.Demo示例
首选需要创建自定义Realm,在这里面做我们的认证(登录鉴权)授权规则。随后,设置Shiro配置,主要完成ShiroFilter、SecurityManager、Realm的创建并交给Spring工厂管理。以后的应用就可以设定相应规则来进行鉴权。
具体权限一般保存至数据库之中,一般按照用户<->角色<->权限<->资源进行设计(以下代码示例均通过数据库访问来赋权/鉴权/认证)。
1.自定义Realm
示例如下:
/** * 自定义realm */ public class CustomerRealm extends AuthorizingRealm { @Override protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) { // 获取身份信息 String primaryPrincipal = (String) principalCollection.getPrimaryPrincipal(); UserService userService = (UserService) ApplicationContextUtils.getBean("userService"); List<Role> roles = userService.findRolesByUsername(primaryPrincipal); // 赋值授权角色 if (!CollectionUtils.isEmpty(roles)) { SimpleAuthorizationInfo simpleAuthorizationInfo = new SimpleAuthorizationInfo(); roles.forEach(role -> { // 赋值角色信息 simpleAuthorizationInfo.addRole(role.getName()); // 赋值权限信息 List<Perms> perms = userService.findPermsByRoleId(role.getId()); if (!CollectionUtils.isEmpty(perms)) { perms.forEach(perm -> { simpleAuthorizationInfo.addStringPermission(perm.getName()); }); } }); return simpleAuthorizationInfo; } return null; } @Override protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException { String principal = (String) authenticationToken.getPrincipal(); // 在工厂中获取service对象 UserService userService = (UserService) ApplicationContextUtils.getBean("userService"); User user = userService.findByUsername(principal); if (!ObjectUtils.isEmpty(user)) { return new SimpleAuthenticationInfo(user.getUsername(), user.getPassword(), new MySimpleByteSource(user.getSalt()), this.getName()); } return null; } }
示例与普通项目类似,但存在两点区别:1.自定义realm并未交给Spring工厂管理,获取bean时自己实现了ApplicationContextUtils.getBean(),详情参见其它。2.原本的shiro自带的用于加盐的ByteSource牵涉到使用Redis缓存时序列化问题,不可用,自己实现了MySimpleByteSource,详情参见其它。
2.ShiroConfig
示例代码:
/** * 用来整合shiro框架相关配置类 */ @Configuration public class ShiroConfig { // 1.创建ShiroFilter,负责拦截所有请求 @Bean public ShiroFilterFactoryBean getShiroFilterFactoryBean(DefaultWebSecurityManager defaultWebSecurityManager) { ShiroFilterFactoryBean shiroFilterFactoryBean = new ShiroFilterFactoryBean(); // 给filter设置安全管理器 shiroFilterFactoryBean.setSecurityManager(defaultWebSecurityManager); // 配置系统受限资源 Map<String, String> map = new HashMap<>(); map.put("/user/login", "anon"); map.put("/user/register", "anon"); map.put("/register.jsp", "anon"); map.put("/**", "authc"); // 默认认证界面路径 shiroFilterFactoryBean.setLoginUrl("/login.jsp"); shiroFilterFactoryBean.setFilterChainDefinitionMap(map); return shiroFilterFactoryBean; } // 2.创建安全管理器 @Bean public DefaultWebSecurityManager getDefaultWebSecurityManager(Realm realm) { DefaultWebSecurityManager defaultWebSecurityManager = new DefaultWebSecurityManager(); // 给安全管理器设置realm defaultWebSecurityManager.setRealm(realm); return defaultWebSecurityManager; } // 3.创建自定义realm @Bean public Realm getRealm() { CustomerRealm customerRealm = new CustomerRealm(); // 修改凭证校验匹配器 HashedCredentialsMatcher hashedCredentialsMatcher = new HashedCredentialsMatcher(); hashedCredentialsMatcher.setHashAlgorithmName("Md5"); hashedCredentialsMatcher.setHashIterations(1024); customerRealm.setCredentialsMatcher(hashedCredentialsMatcher); // 开启缓存管理 Redis customerRealm.setCacheManager(new RedisCacheManager()); customerRealm.setCachingEnabled(true); // 开启全局缓存 customerRealm.setAuthenticationCachingEnabled(true); // 开启认证缓存 customerRealm.setAuthorizationCachingEnabled(true); // 开启授权缓存 customerRealm.setAuthenticationCacheName("authenticationCache"); // 设置缓存在内存的名字,不设置默认为当前realm+.authentication customerRealm.setAuthorizationCacheName("authorizationCache"); return customerRealm; } }
spring-boot-shiro的ShiroFilter依赖SecurityManager,SecurityManager依赖Realm。
对于Realm,配置为自定义CustomerRealm,与凭证校验匹配器修改普通项目类似,不同的是使用了缓存管理。shiro默认的缓存管理为EhCache,为是本地缓存,即在应用内部缓存,当前应用停止/宕机等,依然会重查数据库,不符合现实需求。所以,这里我使用了Redis(如果依旧使用EhCache只需将customerRealm.setCacheManager(new RedisCacheManager())改为customerRealm.setCacheManager(new EhCacheManager()))。RedisCacheManager为自己实现,需要实现CacheManager接口,其中getCache方法,需要返回Cache,这里也是自己实现RedisCache。RedisCache需要实现Cache接口,其中get方法实现从redis中获取值;put方法实现填入值到redis;remove在用户logout时调用,清理缓存;clear为清理所有缓存……
/** * 自定义shiro缓存管理器 */ public class RedisCacheManager implements CacheManager { /** * * @param cacheName 认证或者授权缓存的统一名称 * @return * @param <K> * @param <V> * @throws CacheException */ @Override public <K, V> Cache<K, V> getCache(String cacheName) throws CacheException { return new RedisCache<>(cacheName); } } /** * 自定义redis缓存的实现 */ public class RedisCache<K, V> implements Cache<K, V> { private String cacheName; public RedisCache() { } public RedisCache(String cacheName) { this.cacheName = cacheName; } @Override public V get(K k) throws CacheException { return (V) getRedisTemplate().opsForHash().get(this.cacheName, k.toString()); } @Override public V put(K k, V v) throws CacheException { getRedisTemplate().opsForHash().put(this.cacheName, k.toString(), v); return null; } @Override public V remove(K k) throws CacheException { return (V) getRedisTemplate().opsForHash().delete(this.cacheName, k.toString()); } @Override public void clear() throws CacheException { getRedisTemplate().delete(this.cacheName); } @Override public int size() { return getRedisTemplate().opsForHash().size(this.cacheName).intValue(); } @Override public Set<K> keys() { return getRedisTemplate().opsForHash().keys(this.cacheName); } @Override public Collection<V> values() { return getRedisTemplate().opsForHash().values(this.cacheName); } private RedisTemplate getRedisTemplate() { RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate"); // 修改key的序列化方式为String方式 redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); return redisTemplate; } }
PS:
- Ehcache为应用缓存,导入依赖即可使用,Redis需要开启服务并做相应配置才可使用。
- 对于安全管理器SecurityManager,这里是Web项目,实现的是DefaultWebSecurityManager。
- 对于ShiroFilter,设置安全管理器、配置系统受限资源。
注意:
- shiro配置文件以.ini结尾(.ini文件一般作为Windows操作系统中的配置文件),.ini结尾文件类似.txt结尾文件。.ini文件可以写一些复杂数据格式。shiro配置文件放在resources下及其子目录下都行。在学习shiro中,这里.ini文件用来写权限信息等,真实场景在数据库中,这里是减少学习成本才使用.ini文件的。
- 常用shiro默认过滤器简写
- anon(AnonymousFilter):过滤器允许立即访问路径而不执行任何类型的安全检查,用于公共资源。
- authc(FormAuthenticationFilter):需要对请求用户进行身份验证才能继续请求,如果不是,则重定向到配置的URL强制用户登录。
- perms(PermissionsAuthorizationFilter):如果当前用户具有映射值指定的权限,则过滤器允许访问,如果用户没有指定的所有权限,则拒绝访问。
- roles(RolesAuthorizationFilter):如果当前用户具有映射值指定的角色,则允许访问;如果用户没有指定的所有角色,则拒绝访问。
- shiro项目重启,shiro缓存依然会重新加载,上次未退出的用户依然未退出。
- 默认认证界面URL为/login.jsp,可通过ShiroFilterFactoryBean的setLoginUrl方法进行设置。
- 设置/**为authc时,需要在其前面设置认证请求的url为anon,如/user/login(除认证页面,其他页面访问不到),否则永远无权。
- 可以在方法上添加@RequiresRoles("admin") 或@RequiresPermissions("user:update:01")来限制主体对方法的调用,值可设为value = {“admin”, "user"}多个值,都具有才能调用。@RequiresRoles与@RequiresPermissions同时标注时需要同时具有权限。(上述无权会报AuthorizationException)
- shiro在每次鉴权时都要调用doGetAuthorizationInfo,可设置缓存防止多次从数据库查询权限影响效率。
- Redis缓存相关问题
- 在对密码加盐时使用了ByteSource,其使用了SimpleByteSource,无法序列化,需要我们自己实现。实现方法,照搬SimpleByteSource并实现接口Serializable,并添加无参构造(反序列化需要使用)。
- 在对Redis缓存时,SimpleAuthenticationInfo和AuthorizationInfo都会缓存,认证时先缓存SimpleAuthenticationInfo,授权时缓存AuthorizationInfo,需要使用hash存而不是string,否则后者覆盖前者,会报类型无法转换错误。
- (待解决)AuthorizingRealm.setAuthorizationCacheName()使用无效。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律