串的匹配算法:Brute-Force 与 KMP
串的匹配算法:Brute-Force 与 KMP
串的匹配算法是求子串在主串位置的算法。本次介绍的算法是在指定了从主串特定位置后寻找第一个匹配字串的位置。
在介绍算法前,先定义几个变量:主串 S、字串 T、要求从主串匹配的起始位置 pos、某次匹配时主串的开始位置 start(start 初始化为 pos)。
这里介绍两种算法:Brute-Force(布鲁特-福斯)算法与 KMP 算法。
Brute-Force(布鲁特-福斯)算法[1]
Brute-Force 算法是一种带回溯的匹配算法,其基本思想是:将 S 与 T 进行匹配过程中,成功返回对应的 start,否则 start 加一,重新开始匹配,直至匹配成功或者 start 到了 S 的末尾。
以下是相关实现的 C++、Java 代码:
#include <string>
/**
* @author meyok
* @brief 串的匹配,brute-force算法。
* @param s 主串。
* @param t 子串。
* @param pos 在主串匹配的起始位置,缺省值为 0。
* @note 需要包含头文件 string。
* @return 匹配到的主串位置,-1 为未匹配成功。
*/
int bruteForce(const std::string & s, const std::string & t, int pos = 0);
int bruteForce(const std::string & s, const std::string & t, int pos)
{
if (pos < 0) { pos = 0; }
// 比较时,i 为主串的索引,j 为子串的索引。start 为每次匹配时子串在主串比较的起始位置。
int i, j, start;
i = start = pos;
j = 0;
// 初始化主串与字串的长度
int sLen = s.length();
int tLen = t.length();
// 开始循环比较
while (start <= sLen - tLen && j < tLen)
{
if (s[i] == t[j]) { ++i; ++j; }
else { i = ++start; j = 0;}
}
// j 到达子串长度说明比较成功
return j >= tLen ? start : -1;
}
public class ... {
/**
* 串的匹配,brute-force算法。
* @author meyok
* @param s 主串。
* @param t 子串。
* @param pos 在主串匹配的起始位置。
* @return 匹配到的主串位置,-1 为未匹配成功。
*/
public static int bruteForce(String s, String t, int pos) {
if (pos < 0) { pos = 0; }
int start = pos;
int sLen = s.length();
int tLen = t.length();
while (start <= sLen - tLen) {
if (s.substring(start, start + tLen).equals(t)) { return start; }
++start;
}
return -1;
}
}
该算法思路比较简单,但时间复杂度高,最坏情况下为\(O(s.len \times t.len)\)。
KMP 算法[2]
Brute-Force 算法末次匹配失败时,start 加一。KMP 算法改进了这种方式,其改进的思想是:在匹配失败时,“会从中吸取信息”,得到主串中 start 位置后面某些位肯定无法匹配上的位置,跳过这些位置,start 加到下次可能会匹配的上的位置。
如何获得下次 start 的位置?首先先看以下某次匹配的示例:
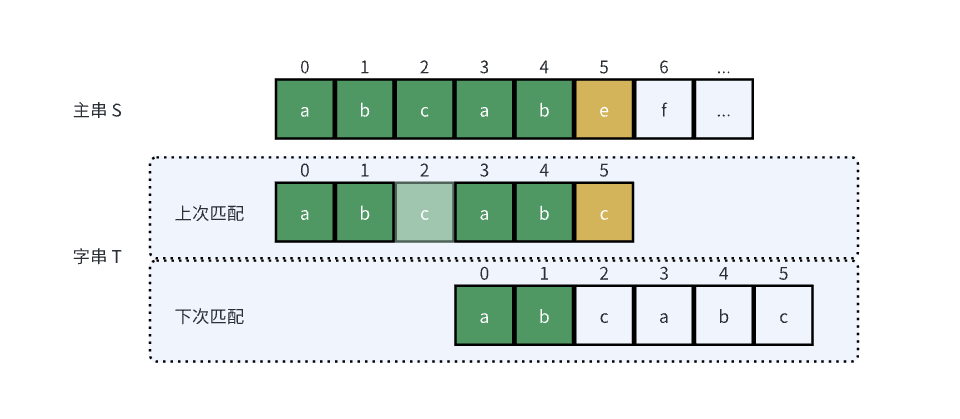
对于该示例,S[5] 与 T[5] 未匹配时,Brute-Force 算法的 start 会向后移动一步。但仔细观察 T,在已经匹配成功的 T[0]-T[4] 中,有相同的内容 “ab”,它也匹配了主串上的内容,其实下次匹配时,start 可以移动更多,将字串的前缀“ab”移动到后缀“ab”匹配到的主串位置。
可能你会有疑问,如果中间也有相同的前后缀怎么办?比如以下例子:
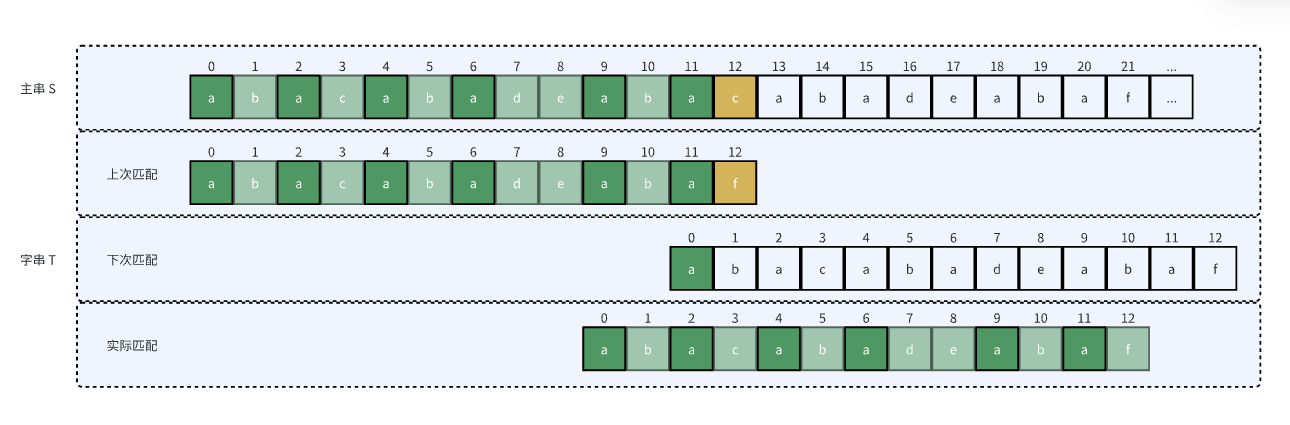
这时就错误了。KMP 算法考虑到这一点,所以它要求的是“最大的”前后缀(本身与本身相等,所以以本身为最大前后缀没意义)。上述例子的最大前后缀是“aba”,实际匹配应该是这样:
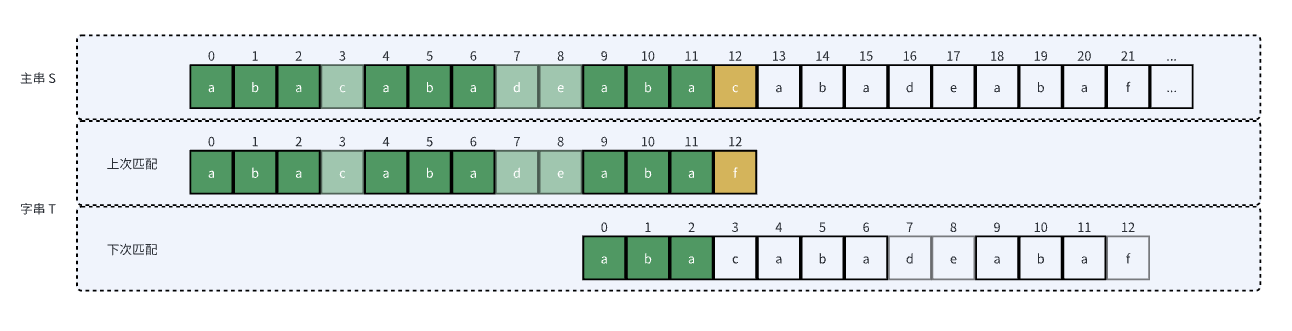
这时中间依然有相同的前后缀“aba”,但把前缀“aba”对应到中间的“aba”是肯定匹配不上的,因为如果把前缀“aba”对应到中间的“aba”时成功匹配了字串,那么对于上述例子来说,T[4]-T[11] 和 T[0]-T[7] 的内容相同,“aba” 就不是最大前后缀,与假设相悖。
理解了 KMP 算法改进的原理,我们就只需要建立一个保存 T 最大前后缀的数组,回溯失败时 start 移动步数根据该数组添加相应值就行,我们暂且把这个数组取名为 next。KMP 算法难点不在其思想,而是它快速求 next 数组的方式。
它求 next 数组的思想其实是利用了数学归纳法。已知 next[0]、next[1]、……、next[i-1],根据它们求 next[i]。
比如有以下字串 T,并且也知道了一些对应的 next 数组值:
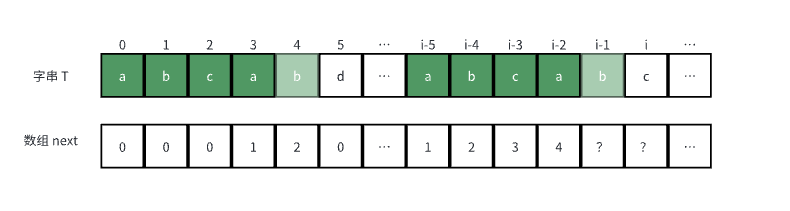
求 next[i - 1] 时,发现 T[4] 与 T[i - 1] 相等,也就是 T[next[i - 2]] 与 T[i - 1] 相等,那么 next[i - 1] 其实就等于 next[i - 1] + 1。那么如果不等呢?如求 next[i] 时:
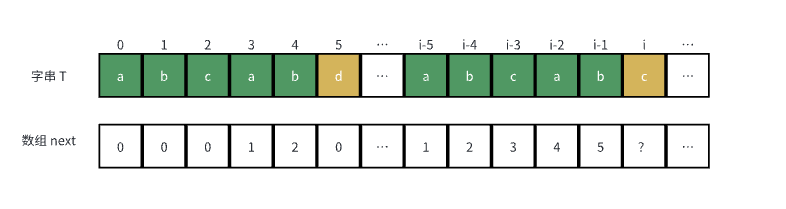
要想能让 T[0]-T[i] 的前缀与后缀匹配,对于上述例子,就是要让 T[0]-T[4] 的某个前缀与 T[i - 5]-T[i-1] 的某个后缀匹配的同时,让该前缀的后一个字符与 T[i] 匹配。前者条件很容易实现,因为 T[0]-T[4] 与 T[i - 5]-T[i-1] 相同,前者条件就是找 T[0]-T[4]/T[i - 5]-T[i-1] 的最大前后缀,该值就是 next[next[i -1] - 1],即 next[2] 为 2。然后实现后一个条件,比较 T[2] 与 T[i],这里相等,就为 next[next[i -1] - 1] + 1,即 next[2] + 1 为 3。如果不相等,则继续匹配“最大前后缀的最大前后缀”,即 “ab” 的最大前后缀,继续执行上述步骤,直到找到相等的位置而至。
以下是一个 C++、Java 代码实现:
#include <string>
#include <vector>
/**
* @author meyok
* @brief 用于初始化 next 数组。这是个递归函数,初始化第 i 项时,前面的项需要被初始化。
* @param T 串。
* @param next next 数组。
* @param i next 数组的第 i 项。
* @param j 本次寻找最长前后缀的串的位数,第一次调用时被初始化为 i。
* @note 需要包含头文件 string、vector。
* @return next 第 i 项应该被初始化的值。
*/
int nextInit(const std::string & T, std::vector<int> & next, int i, int j);
/**
* @author meyok
* @brief 串的匹配,kmp算法。
* @param s 主串。
* @param t 子串。
* @param pos 在主串匹配的起始位置,缺省值为 0。
* @note 需要包含头文件 string、vector。
* @return 匹配到的主串位置,-1 为未匹配成功。
*/
int kmp(const std::string & s, const std::string & t, int pos = 0);
int nextInit(const std::string & T, std::vector<int> & next, int i, int j)
{
if (i == 0) { return 0; }
j = next[j - 1];
return T[i] == T[j] ? j + 1
: j == 0 ? 0
: nextInit(T, next, i, j);
}
int kmp(const std::string & s, const std::string & t, int pos)
{
if (pos < 0) { pos = 0; }
// 比较时,i 为主串的索引,j 为子串的索引。start 为每次匹配时子串在主串比较的起始位置。
int i, j, start;
i = start = pos;
j = 0;
// 初始化主串与字串的长度
int sLen = s.length();
int tLen = t.length();
// 初始化 next 数组
std::vector<int> next(tLen, 0);
for (int m = 0; m < tLen; m++) { next[m] = nextInit(t, next, m, m); }
// 比较字串,注意与 Brute-Force 不一样的是,当匹配不一致时,start、i、j 的修改。
while (i < sLen && j < tLen)
{
if (s[i] == t[j]) { ++i; ++j; }
else
{
if (j == 0) { i = ++start; j = 0; }
else
{
start += j - next[j - 1];
j = next[j - 1];
}
}
}
// j 到达子串长度说明比较成功
return j >= tLen ? start : -1;
}
import java.util.ArrayList;
import java.util.List;
public class ... {
/**
* 用于初始化 next 数组。这是个递归函数,初始化第 i 项时,前面的项需要被初始化。
* @param T 串
* @param next next 数组
* @param i next 数组的第 i 项
* @param j 本次寻找最长前后缀的串的位数,第一次调用时被初始化为 i。
* @return next 第 i 项应该被初始化的值
*/
private static int nextInit(String T, List<Integer> next, int i, int j) {
if (i == 0) { return 0; }
j = next.get(j - 1);
return T.charAt(j) == T.charAt(i) ? j + 1
: j == 0 ? 0
: nextInit(T, next, i, j);
}
/**
* 串的匹配,kmp算法。
* @param s 主串
* @param t 子串
* @param pos 在主串匹配的起始位置
* @return 匹配到的主串位置,-1 为未匹配成功。
*/
public static int kmp(String s, String t, int pos) {
if (pos < 0) { pos = 0; }
int i = pos, j = 0;
int start = pos;
int sLen = s.length();
int tLen = t.length();
List<Integer> next = new ArrayList<>();
for (int m = 0; m < tLen; m++) { next.add(nextInit(t, next, m, m)); }
while (i < sLen && j < tLen) {
if (s.charAt(i) == t.charAt(j)) { ++i; ++j; }
else
{
if (j == 0) { i = ++start; }
else
{
start += j - next.get(j - 1);
j = next.get(j - 1);
}
}
}
return j >= tLen ? start : -1;
}
}
KMP 算法相较于 Brute-Force 算法,它以空间复杂度换取了时间复杂度。它的时间复杂度为\(O(s.len + t.len)\)
耿国华,张德同,周明全等.数据结构——用 C 语言描述(第 2 版)[M].北京:高等教育出版社,2015-07:117-119. ↩︎
阮行止.如何更好地理解和掌握 KMP 算法?[EB/OL].[2020-02-23](2023-08-25).https://www.zhihu.com/question/21923021. ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号