Python pycharm(windows版本)部署spark环境
参考博文:
https://www.cnblogs.com/nucdy/p/6776187.html
一、 部署本地spark环境
1.下载并安装好jdk1.8,配置完环境变量。
2.Spark环境变量配置
- 下载:http://spark.apache.org/downloads.html
我下载的是spark-2.3.0-bin-hadoop2.7.tgz,spark版本是2.3,对应的hadoop版本是2.7.
- 解压
- 配置系统环境变量:
将F:\spark-2.3.0-bin-hadoop2.7\bin添加到系统Path变量,同时新建SPARK_HOME变量,变量值为:F:\spark-2.3.0-bin-hadoop2.7
3.Hadoop相关包的安装(参考:https://www.cnblogs.com/wuxun1997/p/6847950.html ;https://blog.csdn.net/kaluoye/article/details/77984882)
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
我下载的是hadoop-2.7.6.tar.gz.
- 解压
- 配置系统环境变量:
将相关库添加到系统Path变量中:F:\hadoop-2.7.6\bin;同时新建HADOOP_HOME变量,变量值为:F:\hadoop-2.7.6。
下载window下适应的包,包含了hadoop.dll和winutils。资源:http://pan.baidu.com/s/1jHVuaxg,下载解压后全部拷贝到hadoop解压后对应的bin文件夹。
- 配置hadoop的四个XML文件,我的路径为F:\hadoop-2.7.6\etc目录下
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 启动windows命令行窗口,进入hadoop-2.7.6\bin目录,执行下面2条命令,先格式化namenode再启动hadoop
F:\hadoop-2.7.6\bin>hadoop namenode -format
此步会报错:Hadoop Error: JAVA_HOME is incorrectly set.
原因:由于我的jdk安装在c盘的programe files 目录下,JAVA_HOME 的值有空格,启动不了,可以把JAVA_HOME 改成C:\progra~1\XXX
(参考:https://blog.csdn.net/wen3011/article/details/54907731)
- 进入hadoop的sbin目录,运行start-all.cmd
F:\hadoop-2.7.6\sbin>start-all.cmd
F:\hadoop-2.7.6\sbin>jps 4944 DataNode 5860 NodeManager 3532 Jps 7852 NameNode 7932 ResourceManager
通过jps命令可以看到4个进程都拉起来了,到这里hadoop的安装启动已经完事了。
接着我们可以用浏览器到localhost:8088看mapreduce任务,到localhost:50070->Utilites->Browse the file system看hdfs文件。
如果重启hadoop无需再格式化namenode,只要stop-all.cmd再start-all.cmd就可以了。
上面拉起4个进程时会弹出4个窗口:DataNode;NameNode;NodeManager;ResourceManager,可以查看详细。
二、Python环境
Spark提供了2个交互式shell, 一个是pyspark(基于python), 一个是spark_shell(基于Scala). 这两个环境其实是并列的, 并没有相互依赖关系, 所以如果仅仅是使用pyspark交互环境, 而不使用spark-shell的话, 甚至连scala都不需要安装.
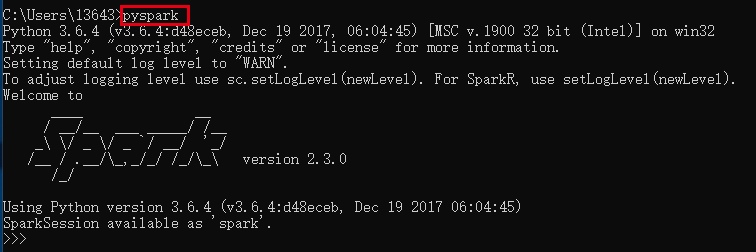
- 启动pyspark验证
在windows下命令行中启动pyspark,如图:
三、在pycharm中配置开发环境
1.配置Pycharm
打开PyCharm,创建一个Project。然后选择“Run” ->“Edit Configurations”
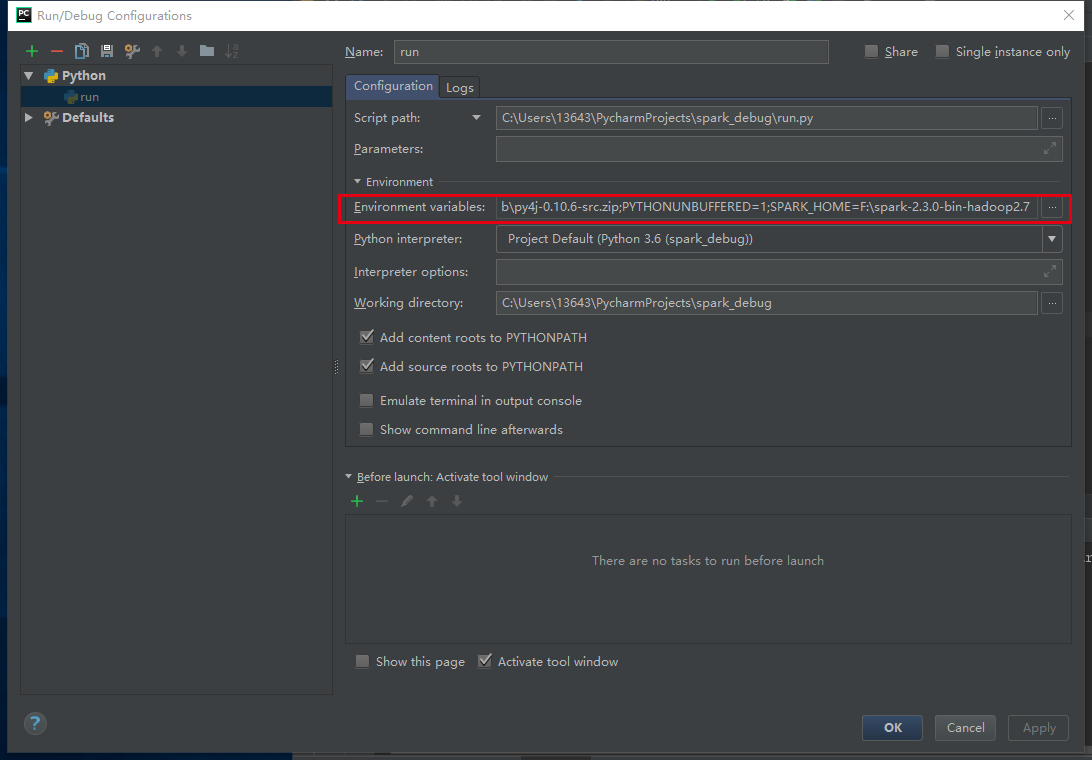
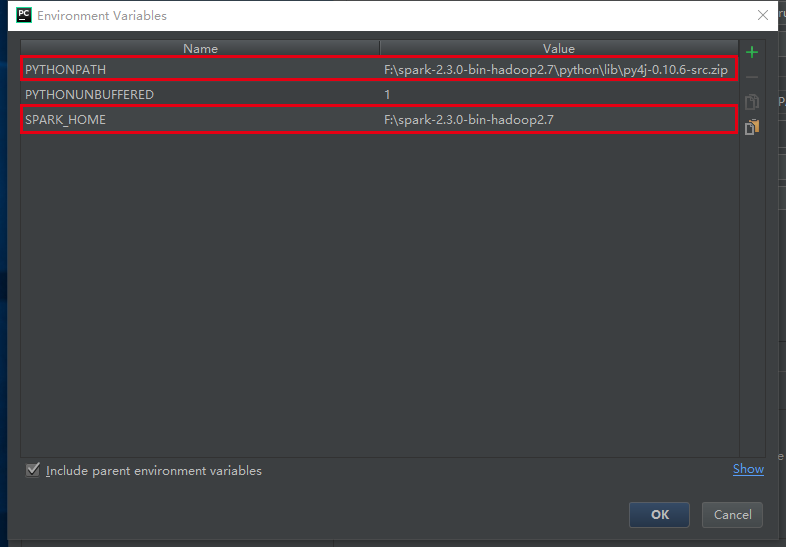
选择 “Environment variables” 增加SPARK_HOME目录与PYTHONPATH目录。
-
SPARK_HOME:Spark安装目录
-
PYTHONPATH:Spark安装目录下的Python目录
2.测试程序
# -*- coding: utf-8 -*-
__author__ = 'kaylee'
import os
import sys
os.environ['SPARK_HOME']="F:\spark-2.3.0-bin-hadoop2.76"
sys.path.append("F:\spark-2.3.0-bin-hadoop2.7\python")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print('Successfully imported Spark Modules')
except ImportError as e:
print('Can not import Spark Modules', e)
sys.exit(1)
如果程序可以正常输出: "Successfully imported Spark Modules"就说明环境已经可以正常执行。
注意,有一步很容易漏:
Settings->Project Structure->Add Content Root->F:\spark-2.3.0-bin-hadoop2.7\python\lib\py4j-0.10.6-src.zip

注意:
可能会报没有 py4j ( 它是python用来连接java的中间件)
可以用命令安装:pip install py4j

 浙公网安备 33010602011771号
浙公网安备 33010602011771号