论文笔记 - GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning
analysis
通常的 data selection 算法的 bi-level 形式:
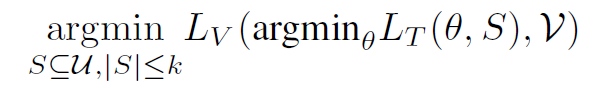
写成对数似然的形式也是可以的:
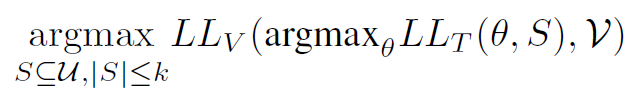
(我的评价是:也就少了一步求交叉熵的过程)
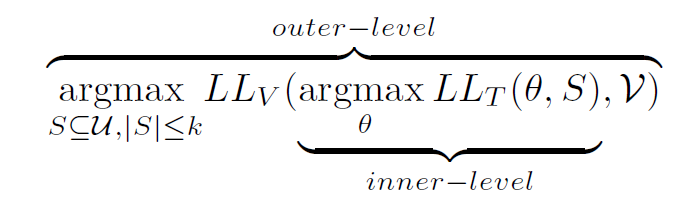
如上图:双层优化是 NP-hard 的,因此在 inner-level 里面,我们可以考虑:在一个 coreset 中,不一次把模型优化到收敛,而是边优化,边调整 coreset(适应性的数据选择)。每 L 个 epoch 更新一次 coreset。
定义![]() ,优化目标变成
,优化目标变成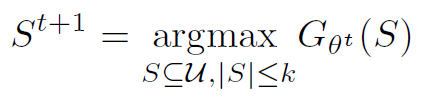 。
。
有点贪心那味儿了,每次挑选数据不针对整体模型性能的最佳,而是模型经过下次迭代后的最佳。
当 $LL_V$ 是负交叉熵形式的时候,这个问题问题就是个次模函数的优化问题,可以用贪心算法解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号