论文笔记 - SELECTION VIA PROXY: EFFICIENT DATA SELECTION FOR DEEP LEARNING
motivation
现存的 data selection 效率不高的主要原因是模型过大,获取数据表征进行数据选择效果并不高(例如大模型进行反向传播本身就比较耗时,想要靠梯度进行数据选择效率是很低的,虽然有了用随最后一个隐藏层的梯度代替整体的梯度的,但是最后一个隐藏层的梯度的代表性尚不可知);
因此可以考虑训练一个较小的模型,用这个较小的模型计算样本表征,最后进行数据选择。
个人感觉不太靠谱,因为原模型的能力随着训练不停变化,适应性的样本选择要求我们不断更新 coreset,因此 proxy 模型也得不断训练适应原模型的能力,效率真的有提高吗?
analysis
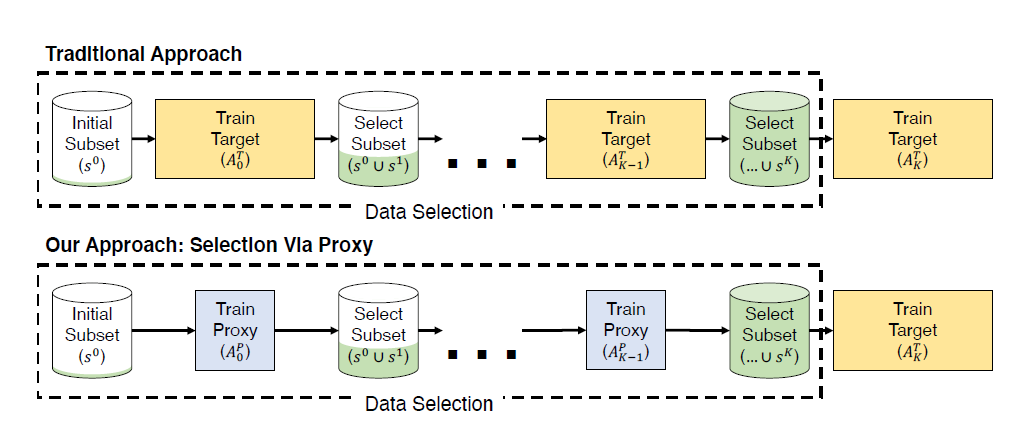
SVP 应用在 active learning 中
如上图可见,与传统方法相比,AL 每次的数据选择都在 proxy model 上进行,最后把挑选好的数据放在原模型上训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号