


加速计算技术-- OpenMP
转
https://www.cnblogs.com/lfri/p/10111315.html
https://www.cnblogs.com/lfri/p/10111466.html
https://www.cnblogs.com/lfri/p/10117193.html
OpenMP - Coding Change The World (hz-bin.cn)
OpenMP API 由3部分组成,包括
1. 编译器指令
2. 运行时库函数
3. 环境变量
1.编译器指令
编译器指令用于各种目的
- 生成一个并行区域
- 在线程之间划分代码块
- 在线程之间分配循环迭代
- 序列化代码段
- 线程之间的工作同步
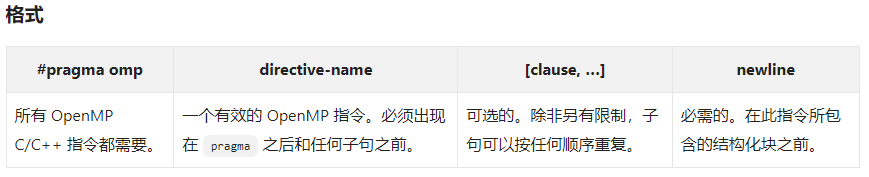

1 //并行区域 2 void test_parallel() 3 { 4 //格式说明 5 //#pragma omp parallel [clause ...] newline 6 // if (scalar_expression) 7 // private (list) 8 // shared(list) 9 // default (shared | none) 10 // firstprivate(list) 11 // reduction(operator: list) 12 // copyin(list) 13 // num_threads(integer - expression) 14 // 15 //structured_block 16 17 int pid; 18 int threads; 19 20 //当一个线程执行到一个并行指令时,它创建一个线程组并成为该线程组的主线程。主线程是该团队的成员,在该团队中线程号为0 21 //从这个并行区域开始,代码被复制,所有线程都将执行该代码 22 //在并行区域的末端有一个隐含的屏障。只有主线程在此之后继续执行 23 //如果任何线程在一个并行区域内终止,则团队中的所有线程都将终止,并且在此之前所做的工作都是未定义的 24 25 #pragma omp parallel private(pid) num_threads(8) 26 { 27 //private(pid) 指定每个线程对于变量pid有一个单独的拷贝 28 pid = omp_get_thread_num();//会打印8次 因为 num_threas指定了线程数 包含了主线程在内 29 std::cout << " 当前线程PID:" << pid << std::endl; 30 31 //线程的编号从0(主线程)到N-1, 0为主线程 32 //IF 子句的计算 33 //NUM_THREADS 子句的设置 34 //使用 omp_set_num_threads() 库函数 35 //设置 OMP_NUM_THREADS 环境变量 36 //实现缺省值 通常是一个节点上的 cpu 数量,尽管它可以是动态的 37 if (pid == 0) 38 { 39 threads = omp_get_num_threads(); 40 std::cout << " 线程数:" << threads << std::endl; 41 } 42 43 } 44 } 45 46 47 48 //工作共享结构类型,不会创建新的线程 49 //DO / for - 整个团队的循环迭代。表示一种“数据并行性” 50 //SECTIONS - 把工作分成单独的、不连续的部分。每个部分由一个线程执行。可以用来实现一种“函数并行性” 51 //SINGLE - 序列化一段代码 52 void test_DoFor() 53 { 54 //格式说明 55 //#pragma omp for [clause ...] newline 56 // schedule(type[, chunk]) 57 // ordered 58 // private (list) 59 // firstprivate(list) 60 // lastprivate(list) 61 // shared(list) 62 // reduction(operator: list) 63 // collapse(n) 64 // nowait 65 // for_loop 66 67 //Do/for 指令指定紧随其后的循环迭代必须由团队并行执行。这假定已经启动了并行区域,否则它将在单个处理器上串行执行 68 69 70 int i, checkSize; 71 float a[100], b[100], c[100]; 72 for (i = 0; i < 100; i++) 73 { 74 a[i] = 1.0 * i; 75 b[i] = i + 25; 76 } 77 checkSize = 10; 78 79 #pragma omp parallel shared(a, b, c, checkSize) private(i)//共享不共享,放在并行区即可 80 { 81 //schedule 描述循环迭代如何在团队中的线程之间进行分配 82 //static 循环迭代被分成固定小块,然后分配给固定的线程。如果没有指定循环迭代块的大小,则迭代是均匀地(如果可能)在线程之间连续地划分 83 //dynamic 循环迭代被分成固定小块,并在线程之间动态调度;当一个线程完成一个块时,它被动态地分配给另一个块。默认块大小为1 84 //guided 循环迭代分成小块,小块的大小会逐步减小,动态分配给空闲线程使用 85 //runtime 环境变量 OMP_SCHEDULE 将调度决策延迟到运行时。为这个子句指定块大小是非法的 86 //auto 调度决策被委托给编译器或运行时系统 87 88 #pragma omp for schedule(dynamic, checkSize)//以10个为一小块,动态分配给空闲线程 89 for (i = 0; i < 100; i++) 90 { 91 c[i] = a[i] + b[i]; 92 } 93 } 94 } 95 96 //sections 指令是一个非迭代的工作共享结构,适用于非循环结构。它指定所包含的代码段将被分配给团队中的各个线程 97 //独立的 section 指令嵌套在 sections 指令中。每个section由团队中的一个线程执行一次。不同的section可以由不同的线程执行。 98 //如果一个线程执行多个section的速度足够快,并且实现允许这样做,那么它就可以执行多个section 99 void test_Sections() 100 { 101 //#pragma omp sections [clause ...] newline 102 // private (list) 103 // lastprivate(list) 104 // firstprivate(list) 105 // reduction(operator: list) 106 // nowait 107 //{ 108 //#pragma omp section newline 109 // structured_block 110 //#pragma omp section newline 111 // structured_block 112 //} 113 int i = 0; 114 float a[1000], b[1000], c[1000], d[1000]; 115 for (i = 0; i < 1000; i++) 116 { 117 a[i] = i * 1.5; 118 b[i] = i + 22.35; 119 } 120 121 #pragma omp parallel shared(a,b,c,d) private(i) 122 { 123 #pragma omp sections nowait 124 { 125 #pragma omp section // 单独由一个线程完成 126 for (i = 0; i < 1000; i++) 127 { 128 c[i] = a[i] + b[i]; 129 } 130 131 #pragma omp section // 单独由一个线程完成 132 for (i = 0; i < 1000; i++) 133 { 134 d[i] = a[i] * b[i]; 135 } 136 } 137 } 138 } 139 140 //SINGLE 指定所包含的代码仅由团队中的一个线程执行 141 //在处理非线程安全的代码段(如 I / O)时可能很有用 142 //#pragma omp single [clause ...] newline 143 // private (list) 144 // firstprivate(list) 145 // nowait 146 // 147 //structured_block 148 149 150 //合并并行工作共享结构 151 //OpenMP提供了三个简单的指令 152 //paramllel for 153 //paramller sections 154 //PARALLEL WORKSHARE (fortran only) 155 //在大多数情况下,这些指令的行为与单独的并行指令完全相同,并行指令后面紧跟着一个单独的工作共享指令 156 void test_parallelfor() 157 { 158 int i; 159 float a[1000], b[1000], c[1000]; 160 for (i = 0; i < 1000; i++) 161 { 162 a[i] = b[i] = i * 1.0; 163 } 164 165 #pragma omp parallel for shared(a,b,c) private(i) schedule(dynamic, 100) 166 for (i = 0; i < 1000; i++) 167 { 168 c[i] = a[i] * b[i]; 169 } 170 } 171 172 //reduction子句 173 void test_reduction() 174 { 175 //reduction (operator: list) 176 //对出现在其列表中的变量执行operator操作 177 //为每个线程创建并初始化每个列表变量的私有副本。 178 //在约简结束时,将约简变量应用于共享变量的所有私有副本,并将最终结果写入全局共享变量 179 180 //计算a和b对应元素乘积的和 181 int i, n, chunk; 182 float a[100], b[100], result; 183 184 /* Some initializations */ 185 n = 100; 186 chunk = 10; 187 result = 0.0; 188 for (i = 0; i < n; i++) { 189 a[i] = i * 1.0; 190 b[i] = i * 2.0; 191 } 192 193 #pragma omp parallel for default(shared) private(i) \ 194 schedule(static,chunk) reduction(+:result)//对所有线程的result副本进行相加操作 195 for (i = 0; i < n; i++) 196 result = result + (a[i] * b[i]); 197 198 printf("Final result= %f\n", result); 199 }
