pytorch训练笔记
深度学习新手,该贴子用于记录一些训练时遇到的问题
-
batch size 和 learning rate的关系
一般来说,我们batch size 大一些,则learning rate也要大一些。数学关系:
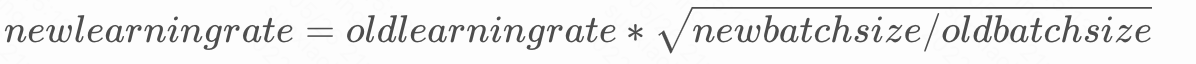
-
查看模型和数据是否在GPU上
data.is_cuda/data.device/next(model.parameters()).device -
pytorch_tensorboard使用指南
- 安装:
pip install tensorboard - 在登录远程服务器的时候使用命令:
ssh -L 16006:127.0.0.1:6006 account@server.address
(代替一般ssh远程登录命令:ssh account@server.address) - 训练完模型之后使用如下命令:
tensorboard --logdir="/path/to/log-directory"
(其中,/path/to/log-directory为自己设定的日志存放路径,因人而异) - 最后,在本地访问地址:http://127.0.0.1:16006/
原理:建立ssh隧道,实现远程端口到本地端口的转发 具体来说就是将远程服务器的6006端口(tensorboard默认将数据放在6006端口)转发到本地的16006端口,在本地对16006端口的访问即是对远程6006端口的访问,当然,转发到本地某一端口不是限定的,可自由选择。
- Tensorboard + Logger 日志记录
https://blog.csdn.net/ViatorSun/article/details/122665433
关闭logger
logger.handlers.clear()
logging.shutdown()
- 模板
import logging
def get_logger(log_dir, name, log_filename='info.log', level=logging.INFO):
logger = logging.getLogger(name)
# logger.propagate = False # avoid printing duplicate logs in console
logger.setLevel(level)
# Add file handler and stdout handler
if not logger.handlers: # avoid printing duplicate logs in console
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler(os.path.join(log_dir, log_filename))
file_handler.setFormatter(formatter)
# Add console handler.
console_formatter = logging.Formatter(
'%(asctime)s - %(levelname)s - %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(console_formatter)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
# Add google cloud log handler
logger.info('Log directory: %s', log_dir)
return logger
- pytorch报错CUDA out of memory错误
- 最终采用方案:降低batch size
- 其他方案:尝试最开始不将全部数据加载到gpu上(
data = data.to(device)),而是在分别将每个batch内的数据加载的gpu上,虽然能至少扩大一倍batch size,但是因为多次加载操作,使得速度明显变慢,因此不推荐用该办法解决。
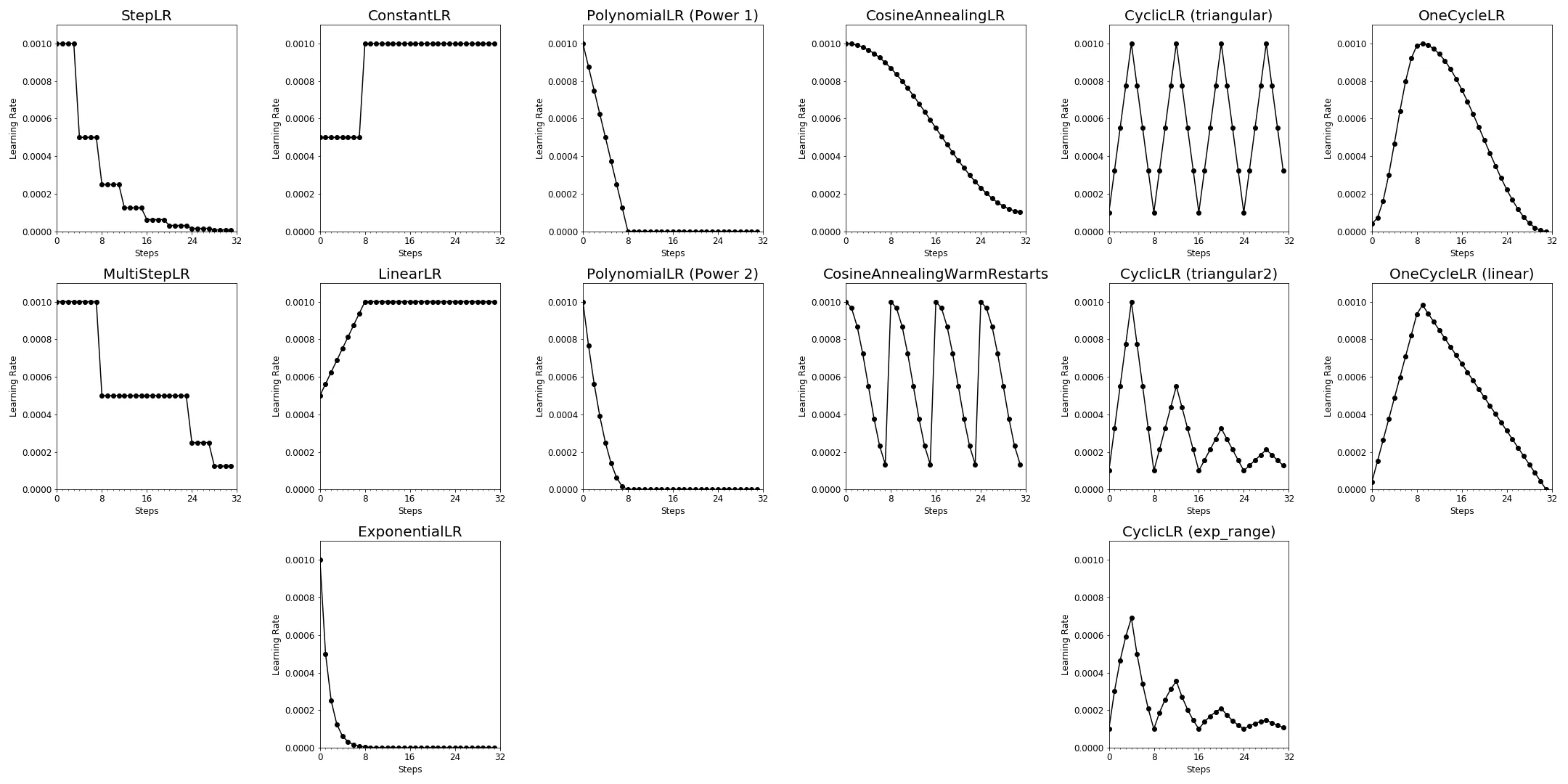
- Learning Rate Schedulers in PyTorch 可视化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号