


unordered_map(hash_map)和map的比较
测试代码:
#include <iostream>
using namespace std;
#include <string>
#include <windows.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <map>
const int maxval = 2000000 * 5;
#include <unordered_map>
void map_test()
{
printf("map_test\n");
map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval]++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand()%maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
void hash_map_test()
{
printf("hash_map_test\n");
unordered_map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval] ++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand() % maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
int main(int argc, char *argv[])
{
srand(0);
map_test();
Sleep(1000);
srand(0);
hash_map_test();
system("pause");
return 0;
}
详解:
map(使用红黑树)与unordered_map(hash_map)比较
map理论插入、查询时间复杂度O(logn)
unordered_map理论插入、查询时间复杂度O(1)
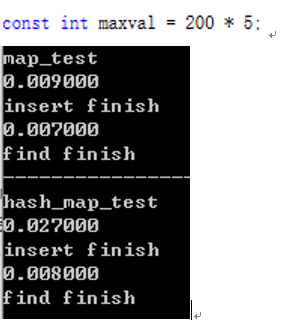
数据量较小时,可能是由于unordered_map(hash_map)初始大小较小,大小频繁到达阈值,多次重建导致插入所用时间稍大。(类似vector的重建过程)。
哈希函数也是有消耗的(应该是常数时间),这时候用于哈希的消耗大于对红黑树查找的消耗(O(logn)),所以unordered_map的查找时间会多余对map的查找时间。
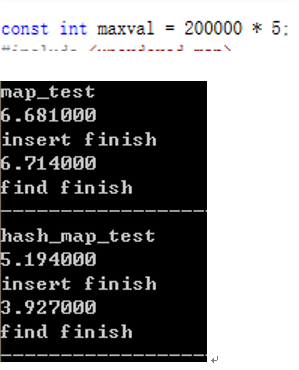
数据量较大时,重建次数减少,用于重建的开销小,unordered_map O(1)的优势开始显现
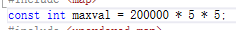
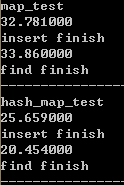
数据量更大,优势更明显
使用空间:


前半部分为map,后半部分为unordered_map
unordered_map占用的空间比map略多,但可以接受。
map和unordered_map内部实现应该都是采用达到阈值翻倍开辟空间的机制(16、32、64、128、256、512、1024……)浪费一定的空间是不可避免的。并且在开双倍空间时,若不能从当前开辟,会在其他位置开辟,开好后将数据移过去。数据的频繁移动也会消耗一定的时间,在数据量较小时尤为明显。
一种方法是手写定长开散列。这样做在数据量较小时有很好地效果(避免了数据频繁移动,真正趋近O(1))。但由于是定长的,在数据量较大时,数据重叠严重,散列效果急剧下降,时间复杂度趋近O(n)。
一种折中的方法是自己手写unordered_map(hash_map),将初始大小赋为一个较大的值。扩张可以模仿STL的双倍扩张,也可以自己采用其他方法。这样写出来的是最优的,但是实现起来极为麻烦。
综合利弊,我们组采用unordered_map。
附:使用Dev测试与VS2017测试效果相差极大???
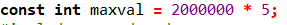
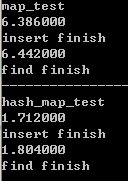
效率差了10倍???
原因:
Dev

VS2017

在Debug下,要记录断点等调试信息,的确慢。
Release:不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。
VS2017切到release后,还更快

除了前面说的Debug与release导致效率差异外,编译器的不同也会导致效率差异。
学到了。

