
Hadoop技巧(02):时间同步
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
在实际部署过程中,Hadoop中服务器节点之间需要时间同步,但Hadoop集群可能需要和其他业务系统的时间进行同步,那么就会存在其他偶尔发生的问题。
下面就这种场景进行描述。
时间同步
一:说明
在实际部署过程中,Hadoop集群需要跟业务系统的服务器集群需要时间同步,如果时间跳动较小,娜ntp会自己纠正过来,但时间一下变化很大,可能短时间内就纠正不过来了,这样可能会照成solr,hbase等组件不能使用,照成不可能。所以我们还是需要处理这样比较少出现的情况。
二:处理
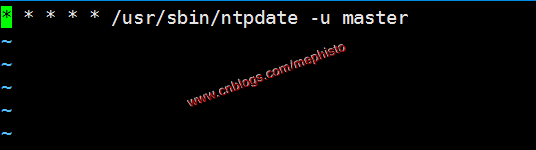
在每个slave节点加入定时任务,每分钟进行时间同步。
crontab -e输入
* * * * * /usr/sbin/ntpdate -u master
:qw保存
三:crond表达式
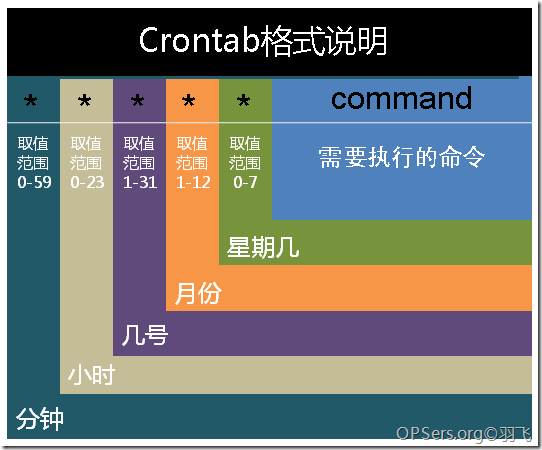
crond是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
从图中可以看出,他的最小单位是分钟,所以这里我们定为每分钟执行一次时间同步。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink


博文作者:mephisto
本文版权归作者和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作!
如果阅读了本文章,觉得有帮助,您可以选择捐助我:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号