
使用Azure SQL Data Sync在Azure 上实现蓝绿部署
通过敏捷开发自动化部署实现产品的快速发布已经成为大多数产品团队的共识。然而每次谈到用蓝绿部署来实现部署自动化的时候,开发和运维团队都会提出同样的疑问,系统的web层和app层可以很容易地利用已有产品合技术部署成互相独立的两套系统来实现减少业务中断快速发布产品,那应用升级常见的数据库schema的升级以及data convention,这时候蓝绿部署又该如何实现呢?这里我们用Azure上的SQL PaaS为例来说明整个实现
如上所说,蓝绿部署通常是指同一系统的两个并行并且完全独立的生产环境, 接受真实用户流量的环境为蓝栈。另一环境为绿栈。通常绿栈上承载着系统的最新版本,在测试通过后蓝栈流量切换到绿栈,绿栈运行稳定后会成为新的生产蓝栈。 而原来的蓝栈则被销毁从而达到节约成本的目的。
我们先看一下最常见的发布流程:
- 触发CD 的task创建和生产环境基础架构相同的绿栈(staging)
- 触发CD 的task在绿栈部署新版本应用
- 触发CD的task在绿栈做自动化测试
- 触发CD的task把流量从蓝栈平滑切换到绿栈,绿栈成为新的蓝栈
- 新蓝栈运行稳定后,绿栈(原蓝栈staging)被销毁
整个流程如下图所示:
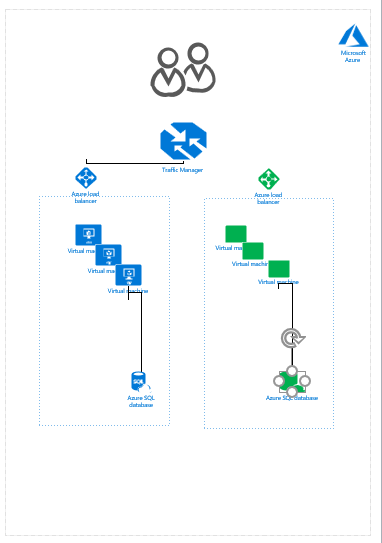
这个方案虽然满足了零宕机的需求但是存在以下问题
1. 新版本应用部署时数据库的升级是从版本零到最新版本,以上step3测试没有覆盖到生产环境数据库版本到最新版本的路径测试,这样新版本在生产环境顺利运行是存在隐患的
2. 同样,step3的测试是基于一个干净的空的数据库,没有在真实或类真实数据之上做新版本测试
针对以上的问题,我们再看一下第二种常见的发布流程
- 触发CD 的task创建和生产环境基础架构相同的绿栈(staging)
该环境不含数据库
- 触发CD的task把绿栈应用指向生产环境数据库并执行所需的schema升级等事务
- 触发CD 的task在绿栈部署新版本应用
- 触发CD的task在绿栈做自动化测试
- 触发CD的task把流量从蓝栈平滑切换到绿栈,绿栈成为新的蓝栈
- 新蓝栈运行稳定后,绿栈(原蓝栈staging)被销毁
整个流程如下图所示。

这个方案存在以下问题
1. 虽然测试基于真实数据,但是也存在在生产环境上直接测试导致宕机的风险
2. 发布的回滚只能回滚到step2这个节点之前的数据库备份点,step2到回滚前的事务数据无法保留
好,我们再看一下第三种常见的发布流程
1. 触发CD 的task创建和生产环境基础架构相同的绿栈(staging)
2. 触发CD的task在绿栈的数据导入生产环境数据库的最新备份
3. 触发CD 的task在绿栈部署新版本应用
4. 触发CD的task在绿栈做自动化测试
5. 触发CD的task把绿栈数据库指向生产数据库并执行所需的schema升级等事务
6. 触发CD的task把流量从蓝栈平滑切换到绿栈,绿栈成为新的蓝栈
7. 新蓝栈运行稳定后,绿栈(原蓝栈staging)被销毁
整个流程如下图所示。

这个方案还是存在以下问题
1. 虽然不再有污染真实环境数据的风险,但是发布回滚的时候依然会丢失相应时间段的事务数据
2. 一旦发生回滚,业务无法满足零宕机的需要
总结以上三种蓝绿部署的流程和已知问题,可以得出蓝绿部署的主要需求点是:
- 应用发布零宕机
- 真实数据测试
- 事务数据无丢失
- 应用回滚零宕机
我们以一个Azure SQL PaaS的系统为例看一下是如何满足需求解决以上三种方案存在的问题
1. 触发CD 的task创建和生产环境基础架构相同的绿栈(staging)
2. 触发CD的task在绿栈的数据导入生产环境数据库的最新备份
3. Enable从蓝栈数据库到绿栈数据库Azure Sql PaaS的Data Sync功能使得生产数据库实时re复制到绿栈
4. 触发CD 的task在绿栈部署新版本应用
5. 触发CD的task在绿栈做自动化测试
6. 触发CD的task把流量从蓝栈平滑切换到绿栈,绿栈成为新的蓝栈
7. Enable从新蓝栈数据库到新绿栈数据库Azure Sql PaaS的Data Sync功能
8. 新蓝栈运行稳定后,绿栈(原蓝栈staging)被销毁
整个流程如下图所示。
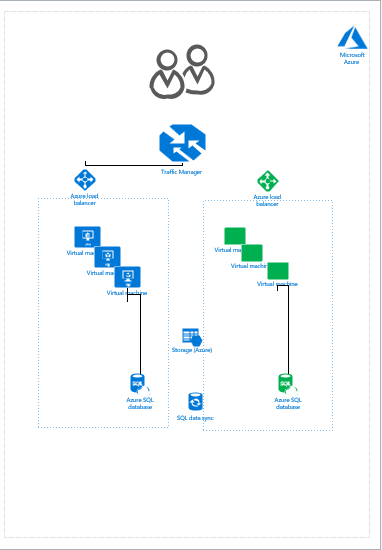
可以看到step3加入Data Sync功能后,应用的测试是在非生产环境但是和生产环境数据又是实时同步的真实的数据上进行,不存在测试路径覆盖不全的问题也不存在会导致生产环境宕机的风险。同时,在step7加入另外一个方向的Data Sync功能后,终端用户在新蓝栈发生的任何事务数据被回写到原有蓝栈中。一旦需要回滚,不再需要花时间创建新数据库并导入备份,只需要由CD task把流量从新蓝栈切换到原来的蓝栈即可,回滚也能实现零宕机。
那接下来我们就看一下如何配置Data Sync来实现以上的功能(Data Sync的原理可查阅https://docs.microsoft.com/en-us/azure/sql-database/sql-database-sync-data)
- 首先创建2个Azure的Sql PaaS,其中一个生产环境的数据库含有真实的数据,另外一个我们会用空的数据库以便展示Data Sync的功能
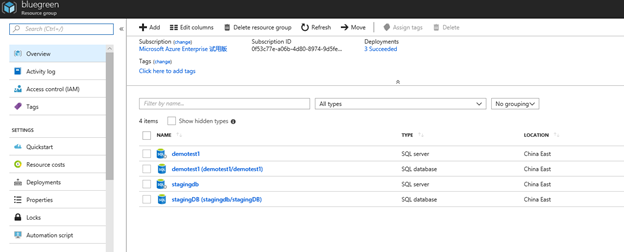
Demotest1是生产库蓝栈
StagingDB是绿栈
2. 在Demotest1里enable Sync to other databases功能
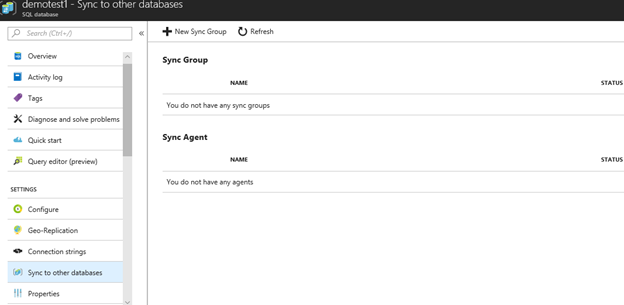
Demotest1做为data sync的hub,每300秒会把数据从hub同步到member数据库StagingDB
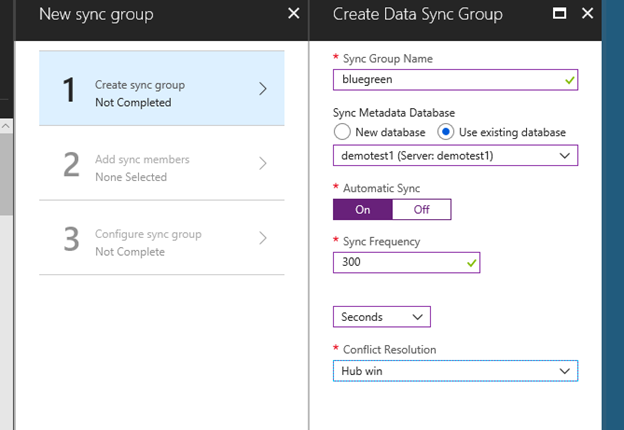
3. 配置data sync group的member数据库stagingdb
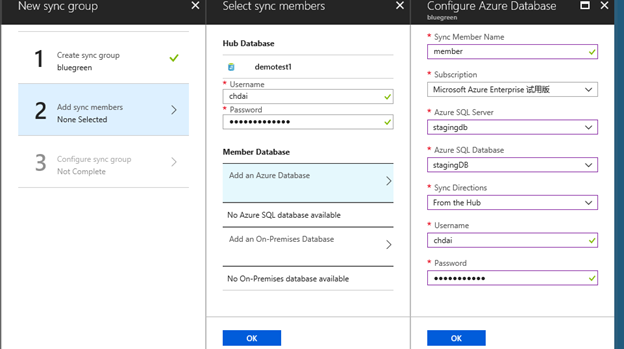
4. 接下来,配置需要同步到绿栈的表和列,这里我们选择全部的表和列
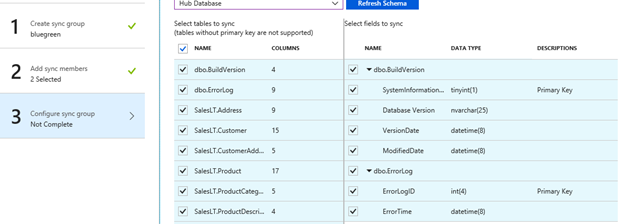
5. 我们先看一下生产数据库内,现在使用azure portal的query editor功能就可以直接查询数据库
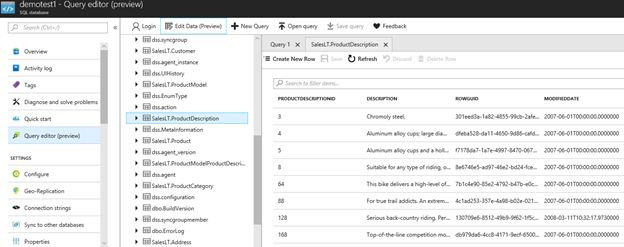
6. 接着查询一下绿栈数据库,此时绿栈只有数据库元数据

7. 5分钟后,再做一次查询,这时可以看到数据开始逐步同步到绿栈数据库。新版应用可以开始测试
· 8. 测试完成后即可平滑迁移生产环境流量
9. 此时需要删除原有data sync group,并配置从新的生产数据库(hub)往旧生产数据库(member)的data sync用于回滚切换
在整个流程中,需要注意以下几点:
1, 配置data sync时,冲突解决必须以承载生产环境的Hub数据库为主,以免出现sequence 冲突
2, 在蓝绿部署的流程里,无需配置所有表的data sync,考虑到member数据库是采用生产数据库中最近的备份为source,类似audit tail之类的系统table无需配置sync,有安全审核要求的除外。
3, 在配置新的生产数据库到旧生产数据库的data sync时候,不能把新升级的Schema直接sync回旧生产库,复杂的schema升级的场景建议采用data sync,需要采用支持table mapping和transformation rule的第三方软件。
4, 另外, data sync也有一些限制https://docs.microsoft.com/en-us/azure/sql-database/sql-database-sync-data,含有不适用于data sync的数据表和列的数据库也不建议采用data sync来做蓝绿部署

