python selenium-webdriver 元素定位(三)
上两篇的博文中介绍了python selenium的环境搭建和编写的第一个自动化测试脚本,从第二篇的例子中看出来再做UI级别的自动化测试的时候,有一个至关重要的因素,那就是元素的定位,只有从页面上找到这个元素,我们从能对这个元素进行操作,那么我们下来看看如何来定位元素。
selenium 提供了8中元素定位的方法(大家要学习元素的定位,首先可以学习下前端的基础知识,这样有利于我们学习自动化测试,大家可以看一下:http://www.runoob.com/)
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
下面我们详细的介绍一下,每个方法的含义以及每个方法的使用。
1.find_element_by_id 根据标签id定位
示例HTML代码:
<html> <body> <input id="kw" name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> </body> <html>
网页需要通过开发者工具,打开浏览器按F12获取页面元素,我们已经看到上述的页面html代码,我们现在要查找id="kw"的元素
driver.find_element_by_id('kw') #通过id定位
2.find_element_by_name 根据标签的name定位
driver.find_element_by_name('username') #通过name定位
3.find_element_by_xpath 根据xpath定位
driver.find_element_by_xpath('//*[@id="kw"]')
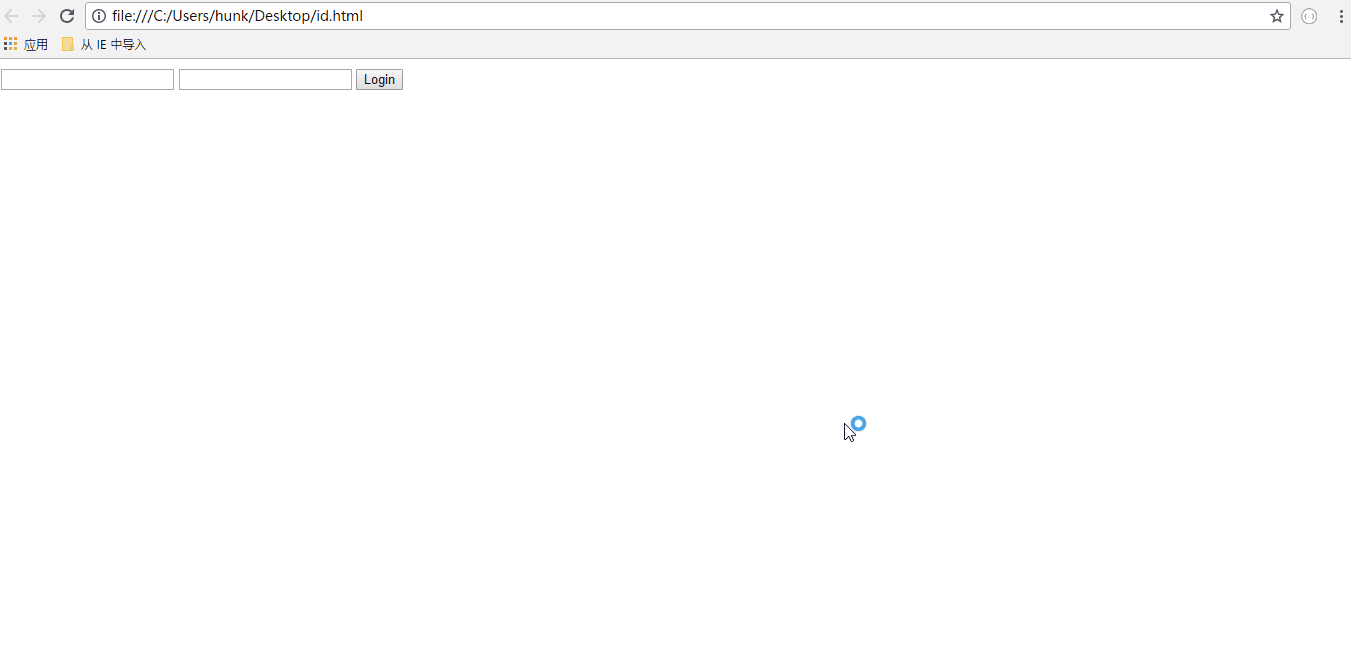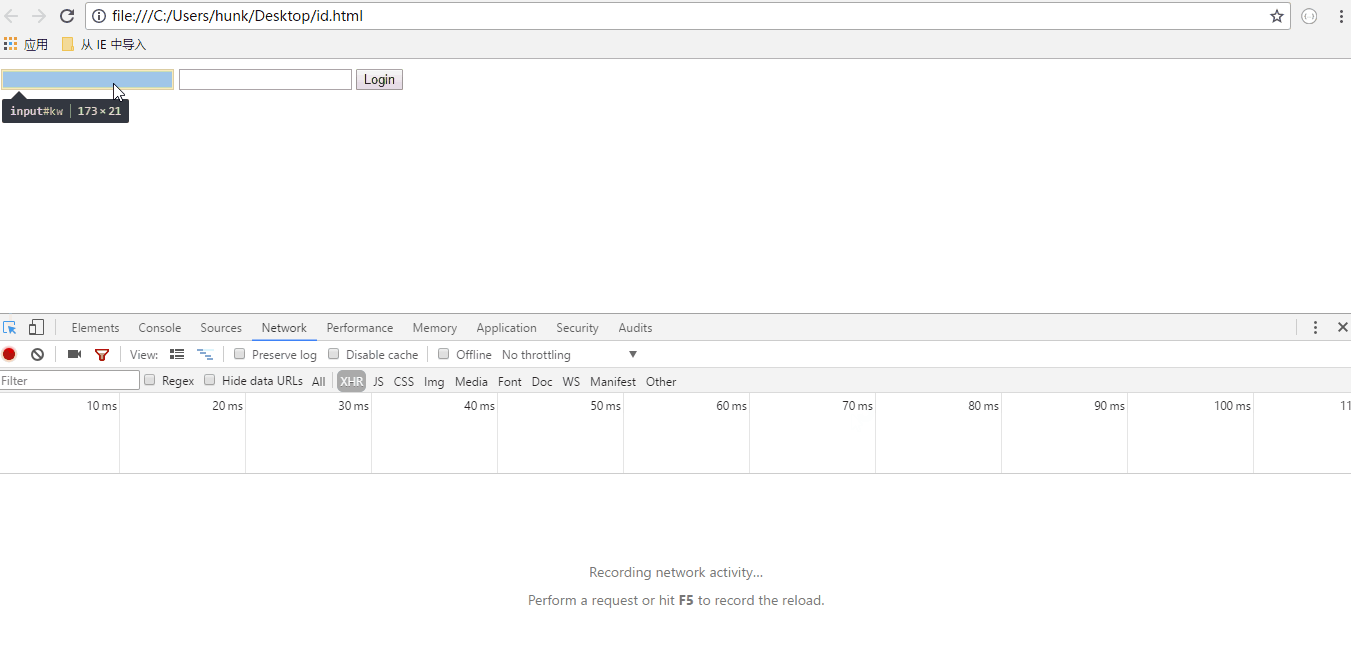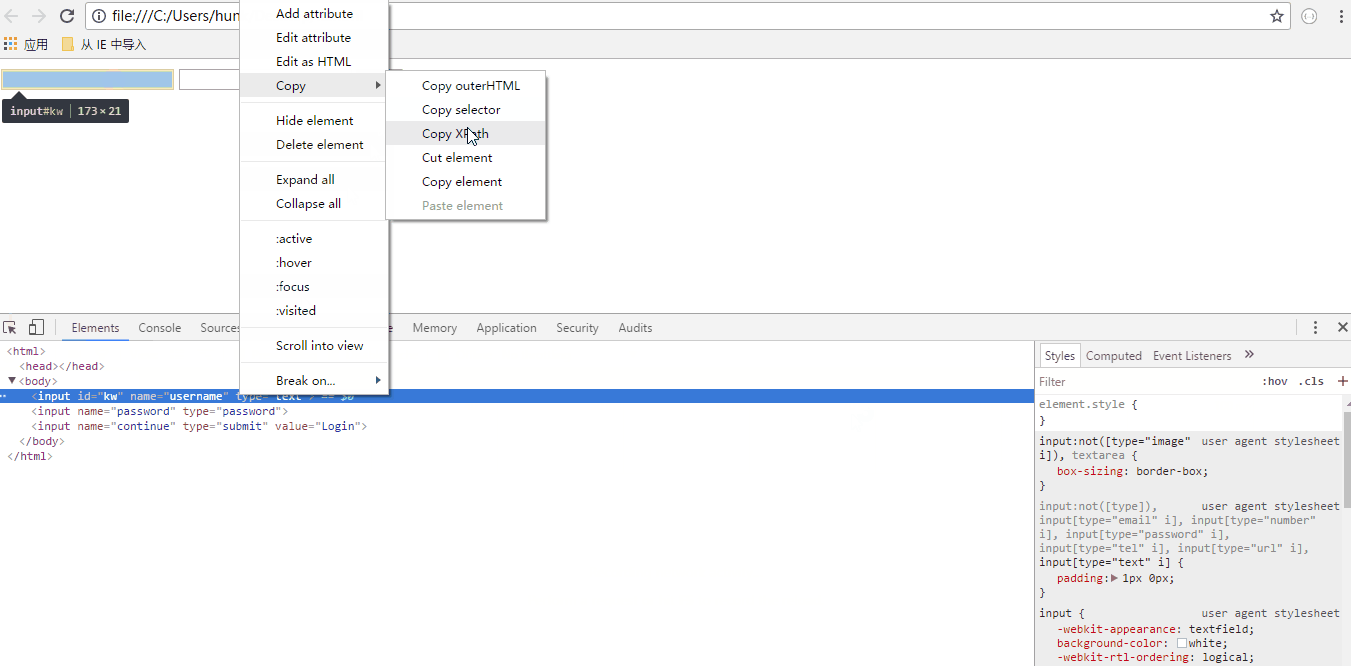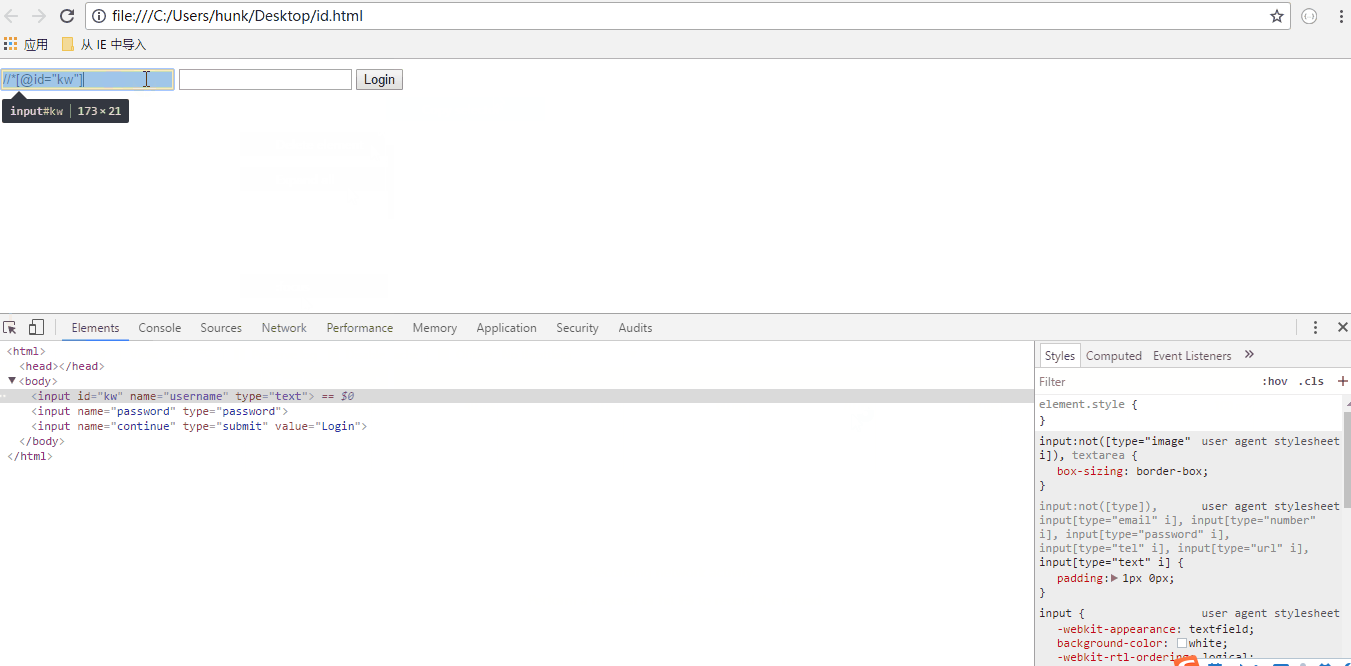
这里要介绍一下如何获取页面元素的xpath路径的方法,如果你是大神可以自己写,如果跟作者一样很喽,可以通过开发者工具获取,选择元素右击->Copy->Copy Xpath,可以直接拷贝到xpath路径.
4.find_element_by_link_text和find_element_by_partial_link_text 通过文字链接来定位元素,他们两个很相像,功能也很类似,但是他们一个是匹配全部,一个是匹配部分。
给我们之前的示例代码增加一段,我们来看看如何定位
<html> <body> <input id="kw" name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <div id="u1"> <a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a> <a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a> <a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a> <a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a> <a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a> <a href="http://xueshu.baidu.com" name="tj_trxueshu" class="mnav">学术</a> </body> <html>
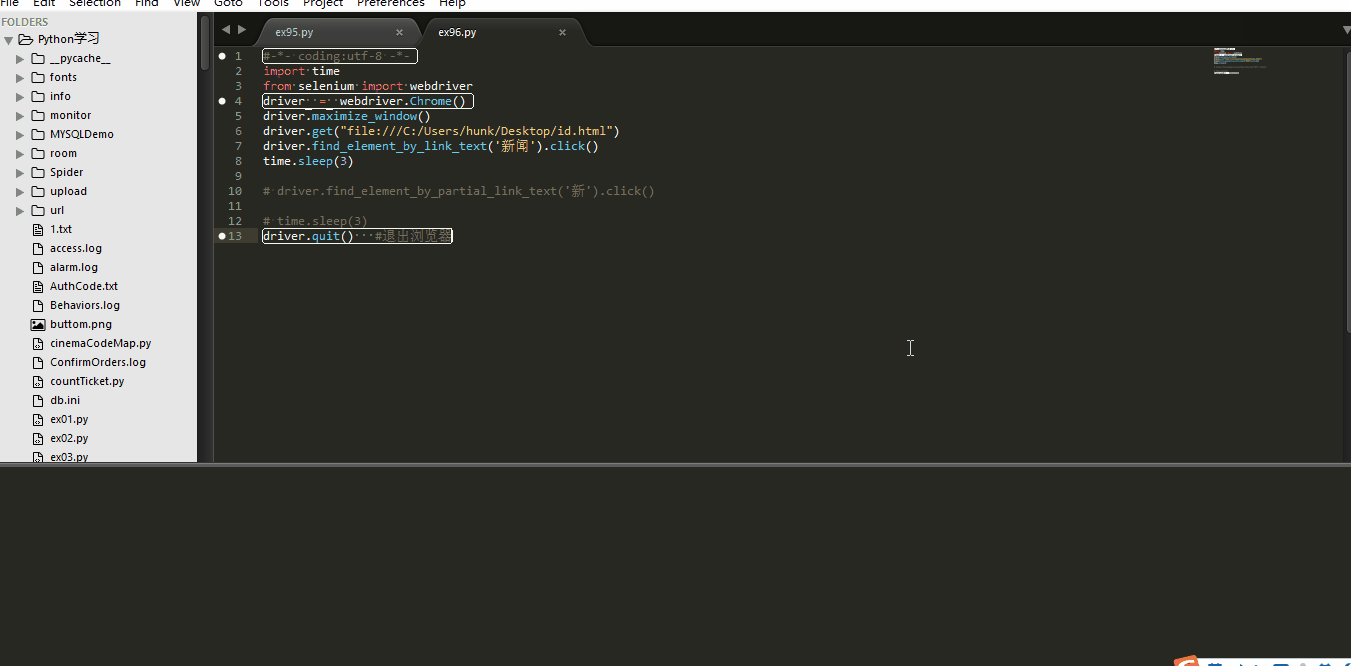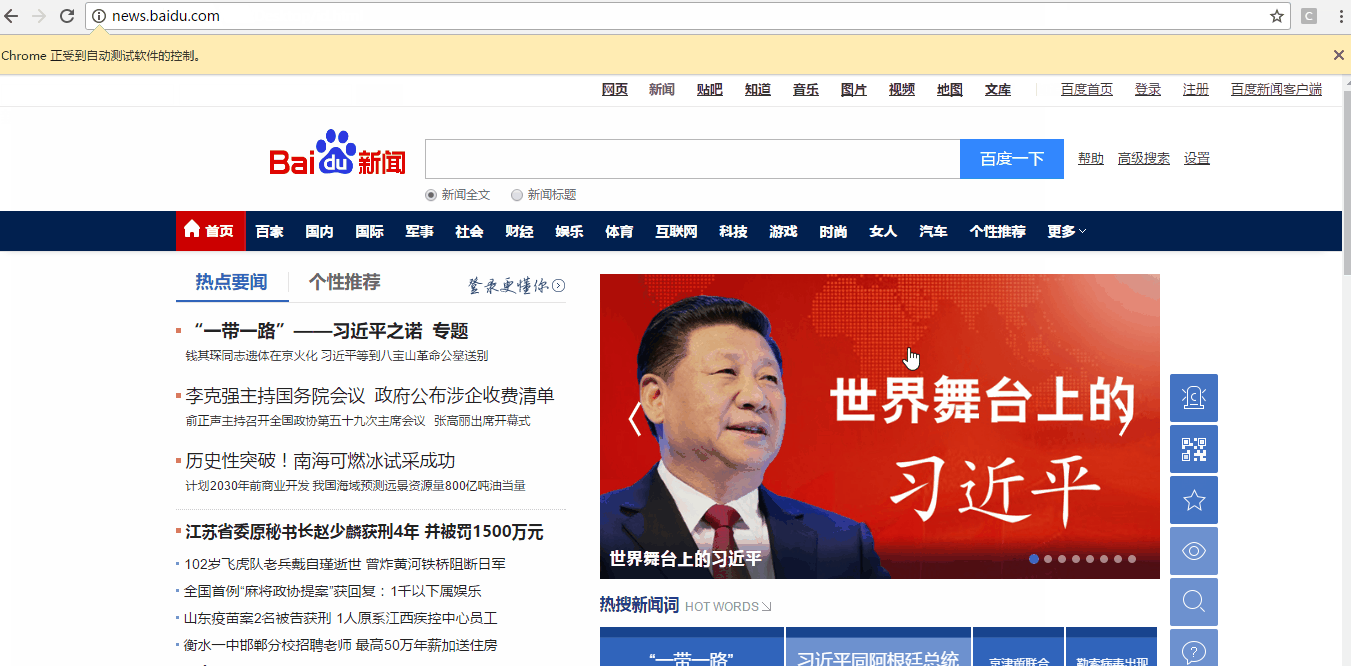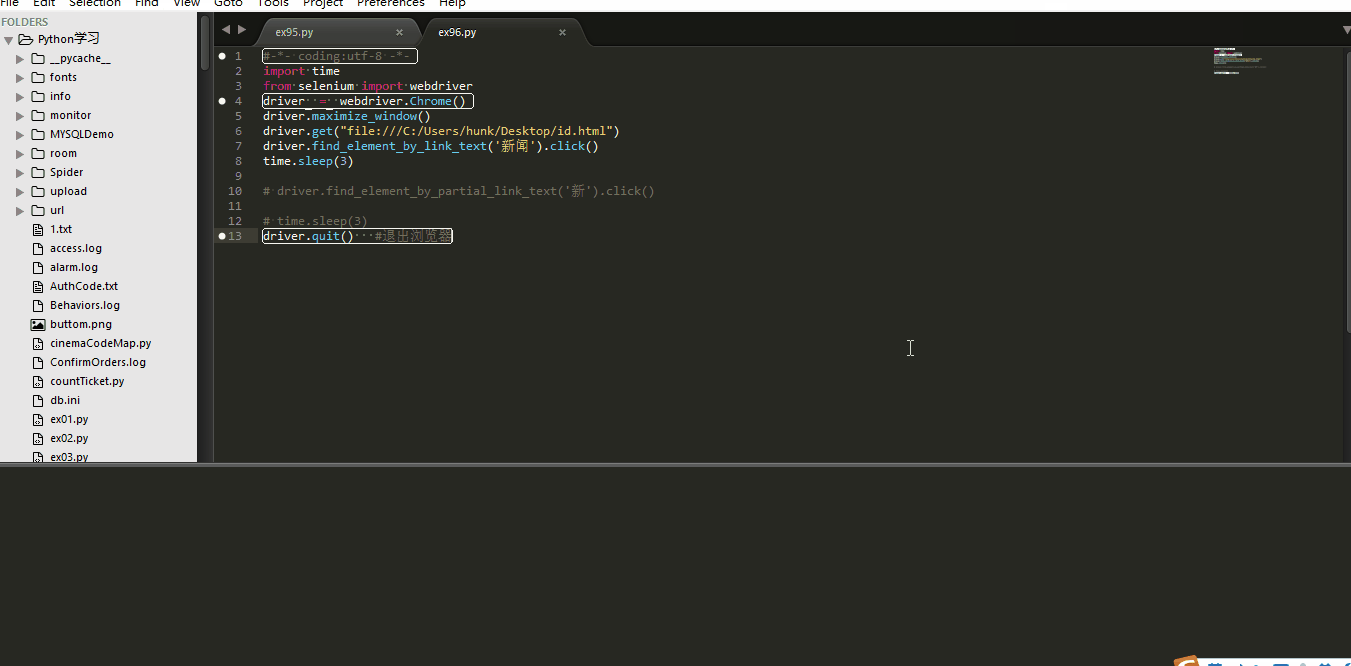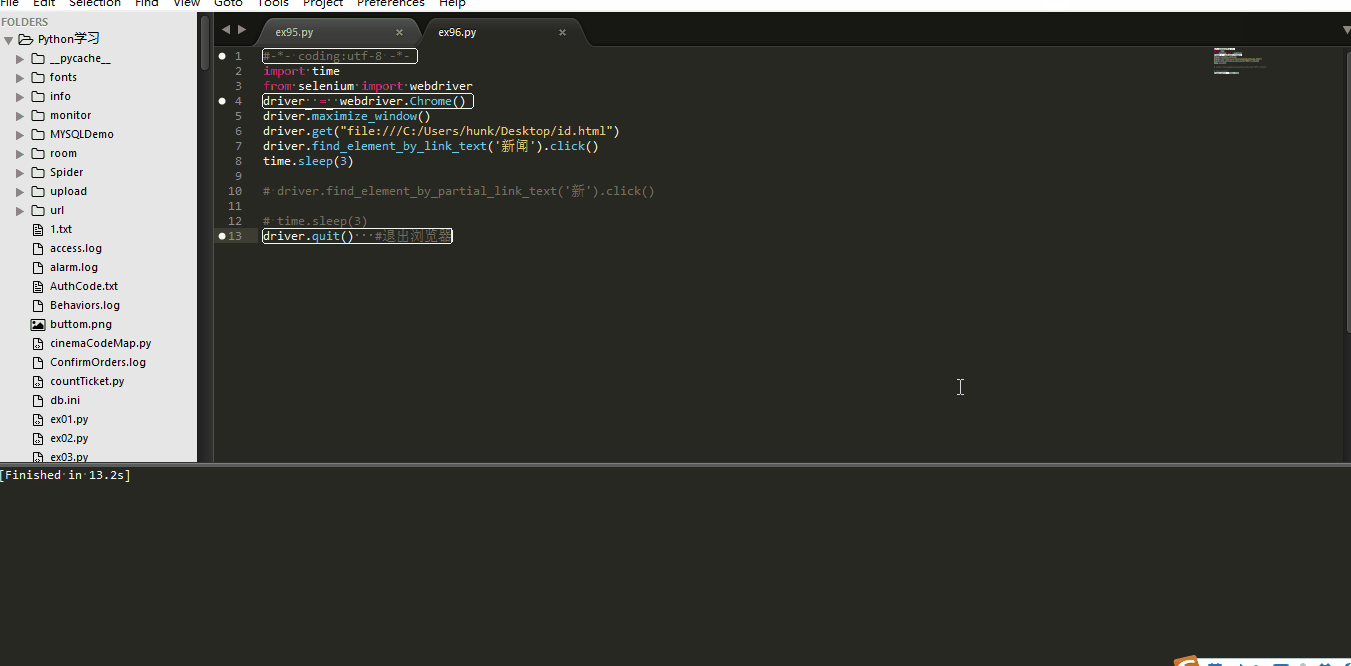
下面我们用两种方法来定位一下《新闻》这个元素
通过来find_element_by_link_text定位
#-*- coding:utf-8 -*- import time from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.get("file:///C:/Users/hunk/Desktop/id.html") driver.find_element_by_link_text('新闻').click() time.sleep(3) driver.quit() #退出浏览器
定位效果:
通过来find_element_by_partial_link_text定位

5.find_element_by_tag_name根据标签的名字定位,这种方法很不使用,因为一个页面的中的标签的名字重复度太早,定位起来太不容易。
driver.find_element_by_tag_name("input")
6.find_element_by_class_name通过class name 定位
<html> <body> <p class="content">Site content goes here.</p> </body> <html>
driver.find_element_by_class_name('content') #通过class name 定位
7.find_element_by_css_selector 根据元素属性来定位,这个方法在实际过程中比较实用,而且很简单,下面我们先看一下语法,这里有一个比较关键点就是,在这个定位的方法是可以写正则表达式来定位元素,然后在写一个实例来定位,实例我们采用百度网站来定位,然后搜索selenium关键字。
<html> <body> <p class="content">Site content goes here.</p> </body> <html>
定位语法
driver.find_element_by_css_selector("p[class=\"content\"]") #根据元素属性
示例:
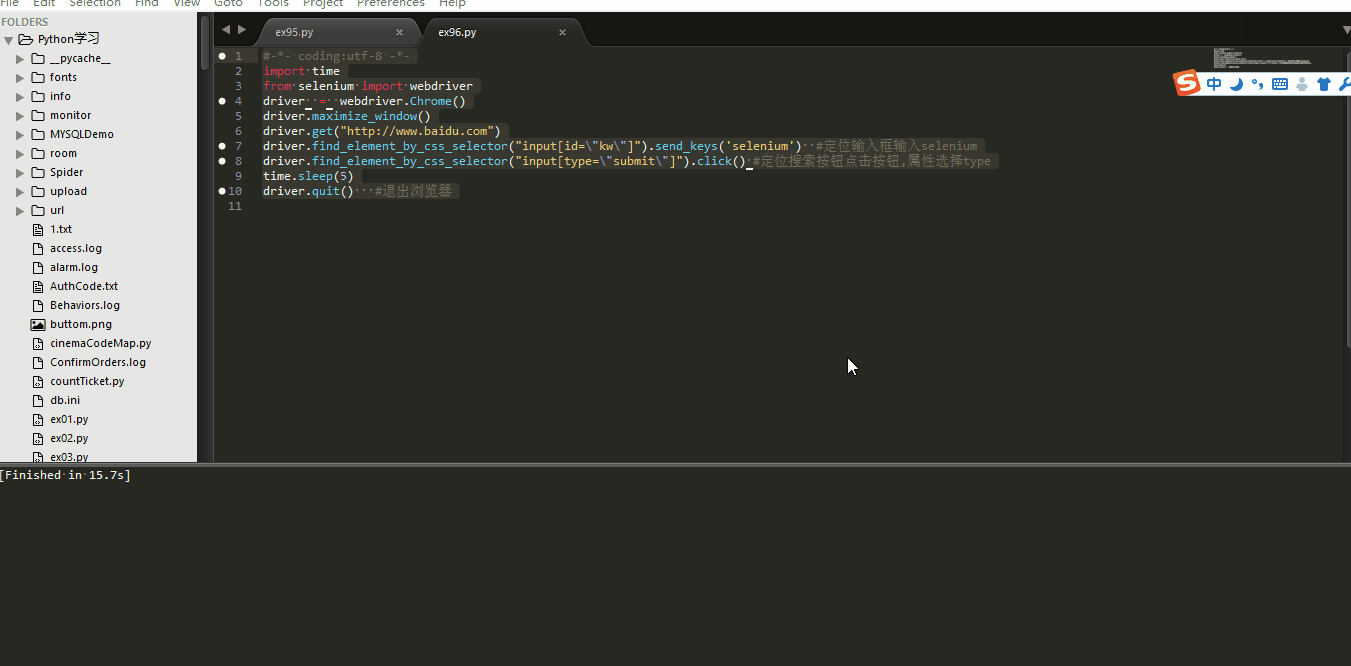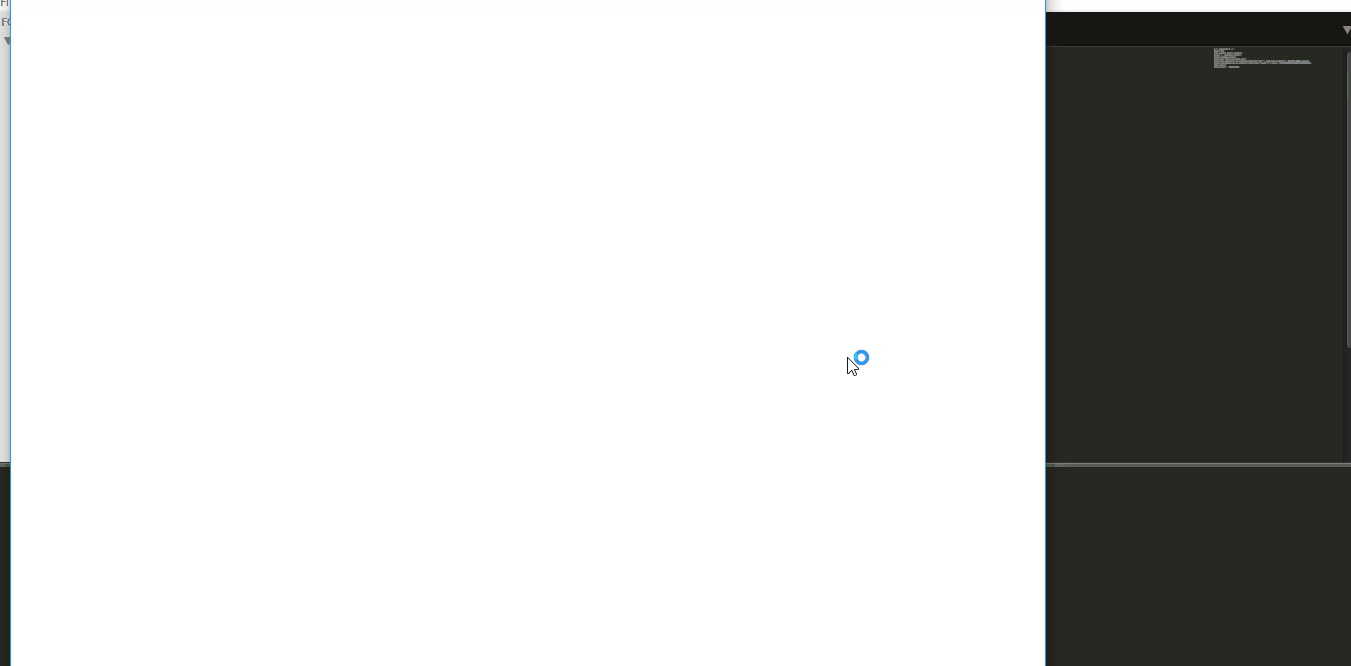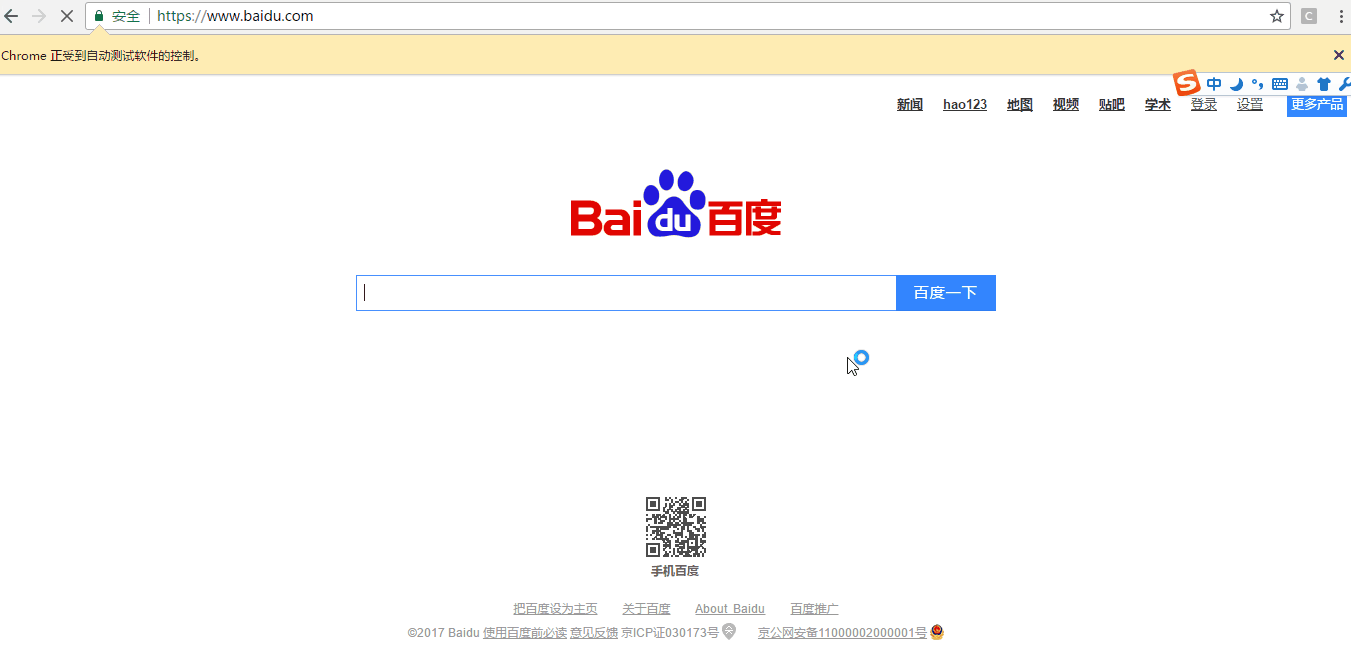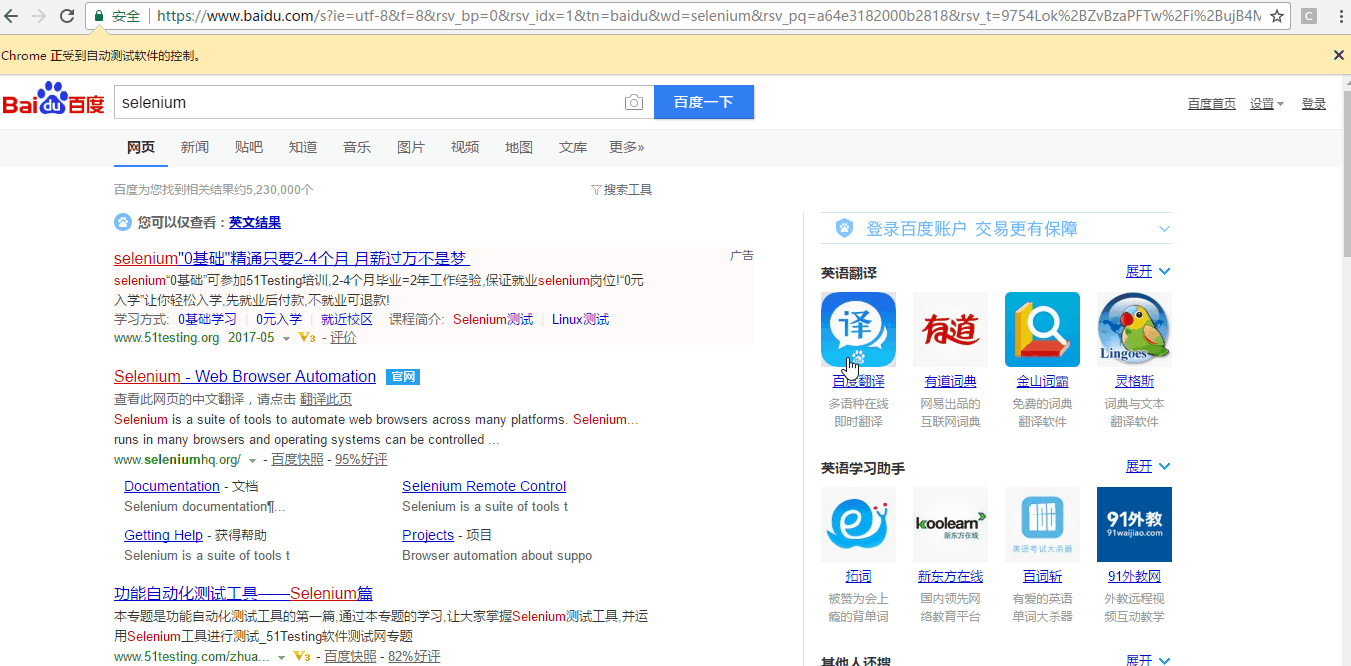
#-*- coding:utf-8 -*- import time from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.get("http://www.baidu.com") driver.find_element_by_css_selector("input[id=\"kw\"]").send_keys('selenium') #定位输入框输入selenium driver.find_element_by_css_selector("input[type=\"submit\"]").click() #定位搜索按钮点击按钮,属性选择type time.sleep(5) driver.quit() #退出浏览器
来看一下动画效果吧
其实元素的定位很简单,只是实际过程中定位的html页面有一些特殊的地方,只要我们拆解分析,自然也难不倒我们。
下面这几个方法返回的结果是列表,跟单个元素定位一样,只是返回的结果不同,这里就不详细介绍了。
- find_elements_by_id
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector


 浙公网安备 33010602011771号
浙公网安备 33010602011771号