spark源码编译
默认情况下,spark官方提供了针对hadoop和hive的预编译发行版,但这可能跟我们的期望的有些差异。比如说,与实际生产环境中的hadoop或hive版本不同可能会导致兼容性问题,也可能是官方使用的版本陈旧而我们想体验新特性等,又或者是我们想增加某些功能而调整源码。因此,面对各种不同的需求,就需要对源码进行二次编译。
1、配置环境
虽然spark官网提示不同版本的spark对maven版本要求不同,实际上,它取决于源码包spark-x.y.z.tgz/build/mvn脚本(他会从根目录的pom文件中查找maven.version属性来校验当前所用的maven版本,如果不匹配时会通过install_mvn方法自动去https://archive.apache.org/dist中下载)。因此,你可以改park-x.y.z.tgz/pom.xml中的maven.version成你自己已安装的maven,这样就OK了。
1.1、spark-2.x的必要配置
java8 scala-2.11.x apache-maven-3.5.4
1.2、spark-3.x的必要配置
java8 scala-2.12.x apache-maven-3.6.3
1.3、配置maven
// 在bin/mvn中新增 export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"
// 在settings.xml的mirrors标签中新增阿里云仓库 <mirrors> <mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> </mirrors>
1.4、配置环境变量
这里使用的jdk版本是8u211,scala版本为2.11.12,maven版本是3.5.4
// 编辑系统全局配置文件(也可以是用户的bash_profile) vim /etc/profile // 新增如下内容 export JAVA_HOME=/usr/java/jdk PATH=.:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export SCALA_HOME=/usr/scala/scala PATH=.:$SCALA_HOME/bin:$PATH export M2_HOME=/usr/bdp/service/maven PATH=.:$M2_HOME/bin:$PATH
2、修改spark源码
2.1、修改make-distribution.sh脚本
vim /usr/bdp/service/spark-2.4.7/dev/make-distribution.sh 1、注释掉144~162行 144 # VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null\ 145 # | grep -v "INFO"\ 146 # | grep -v "WARNING"\ 147 # | tail -n 1) 148 # SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\ 149 # | grep -v "INFO"\ 150 # | grep -v "WARNING"\ 151 # | tail -n 1) 152 # SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\ 153 # | grep -v "INFO"\ 154 # | grep -v "WARNING"\ 155 # | tail -n 1) 156 # SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\ 157 # | grep -v "INFO"\ 158 # | grep -v "WARNING"\ 159 # | fgrep --count "<id>hive</id>";\ 160 # # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\ 161 # # because we use "set -o pipefail" 162 # echo -n) 2、新增 VERSION=2.4.7 SCALA_VERSION=2.11 SPARK_HADOOP_VERSION=3.1.1 SPARK_HIVE=3
2.2、设置mvn和zinc权限
chmod 777 /usr/bdp/service/spark-2.4.7/build/mvn chmod 777 -R /usr/bdp/service/spark-2.4.7/build/zinc-0.3.15
3、仅编译特定模块
# 仅编译spark-network-shuffle_2.11模块(使用模块pom中的ArtifactId) mvn -pl :spark-network-shuffle_2.11 clean install -DskipTests -X
4、编译为tar包
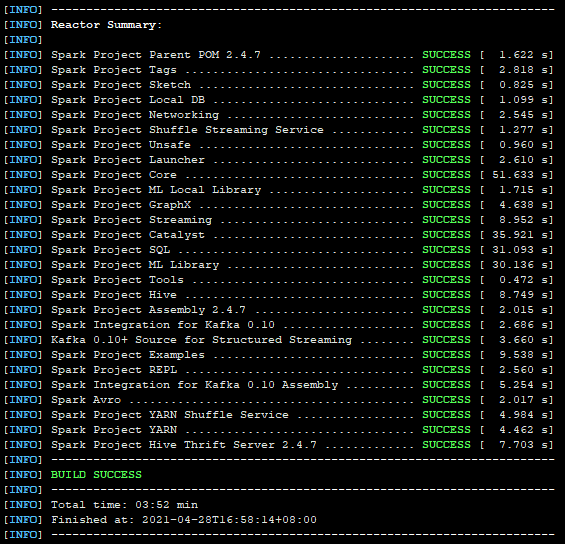
// 进入spark的dev路径下 cd /usr/bdp/service/spark-2.4.7/dev // 运行编译命令 ./make-distribution.sh --name 3.1.0 --tgz -Pyarn -Phadoop-3.1 -Phadoop-provided -Phive -Phive-thriftserver -Dscala-2.11 -DskipTests
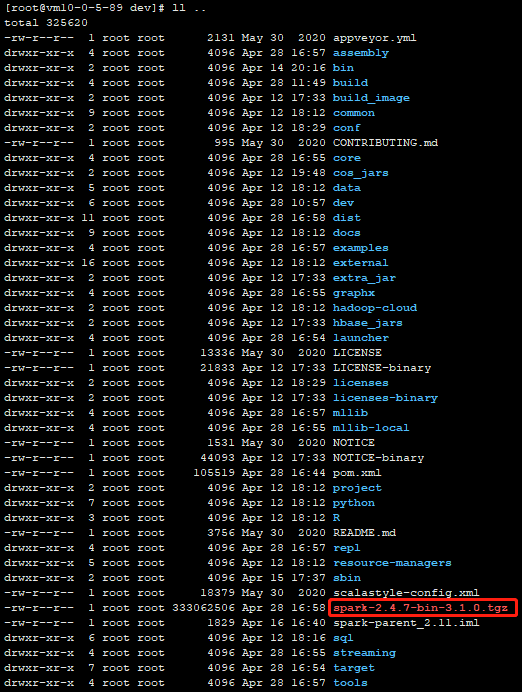
// 如果编译成功后,会在/usr/bdp/service/spark-2.4.7/目录下多出一个spark-2.4.7-bin-3.1.0.tgz
ll /usr/bdp/service/spark-2.4.7/
5、编译为rpm
// 编译出各个子模块的jar包 ./build/mvn -Pyarn -Phadoop-3.1 -Phive -Phive-thriftserver -DskipTests clean package // 然后进入dist模块下开始打rpm包 cd ./dist/ mvn package -DskipTests // 最后输出的结果如下 ===========================================================================
./dist/target/rpms spark-2.4.7 RPMS noarch spark-2.4.7.noarch.rpm spark-2.4.7-master RPMS noarch spark-master-2.4.7.noarch.rpm spark-2.4.7-worker RPMS noarch spark-worker-2.4.7.noarch.rpm spark-2.4.7-python RPMS noarch spark-python-2.4.7.noarch.rpm spark-2.4.7-yarn-shuffle RPMS noarch spark-yarn-shuffle-2.4.7.noarch.rpm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号