Spark Application在yarn-cluster模式下的运行流程
Spark on YARN模式的核心实现有2个类,分别是Client(org.apache.spark.deploy.yarn.Client.scala)和ApplicationMaster(org.apache.spark.deploy.yarn.ApplicationMaster.scala)。Client的作用是向YARN申请资源(容器)来运行ApplicationMaster。
一、Spark客户端操作
1、输入提交命令
spark-submit --master yarn \ --deploy-mode cluster \ --driver-memory 512m \ --driver-cores 1 \ --executor-memory 1G \ --executor-cores 1 \ --queue default \ --class org.apache.spark.examples.SparkPi /usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.7.jar 10
1.1、参数说明
源码:https://github.com/apache/spark/blob/v2.4.7/core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala
--num-executors:设置Spark作业要运行的总executor数,默认为2。如果开启动态资源分配时,初始executor数至少为该值。 --executor-cores:设置每个executor使用的CPU core数。在YARN模式下为1,在standalone模式下为Worker节点的所有可用CPU核心数。 --executor-memory:设置每个executor使用的内存,默认为1G。
1.1.1、注意
2、spark-submit脚本
上述命令使用${SPARK_HOME}/bin/spark-submit脚本提交了SparkPi作业,我们发现脚本的最后一行才是提交代码的地方。
# 真正提交命令运行的地方是在最后一行($@表示所有参数)
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
不难发现,spark-submit脚本的作用是把SparkSubmit类全称和$@参数传递到spark-class类中。
3、spark-class脚本
其实,spark-class脚本的主要作用有4点:
1、Find the java binary(找到$JAVA_HOME/bin/java)
2、Find Spark jars(找到$SPARK_HOME下的jars)
3、build_command
4、执行(最后一行)
# 真正提交命令运行的地方仍然是最后一行 exec "${CMD[@]}"
为了方便理解此行代码,将exec "${CMD[@]}"替换为echo "${CMD[@]}",于是发现最终输出的执行命令如下:
/usr/java/jdk/bin/java -cp /usr/bdp/service/spark/conf/:/usr/bdp/service/spark/jars/*:/usr/bdp/service/hadoop/etc/hadoop/ org.apache.spark.deploy.SparkSubmit --master yarn --deploy-mode cluster --conf spark.driver.memory=512m --class org.apache.spark.examples.SparkPi --driver-cores 1 --executor-memory 1G --executor-cores 1 --queue default /usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.7.jar 10
到此,确定了实际运行的spark类是org.apache.spark.deploy.SparkSubmit,接下来就去看下它是如何实现的。
4、SparkSubmit类
源码:https://github.com/apache/spark/blob/v2.4.7/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala
4.1、在object SparkSubmit(伴生类)中
在object SparkSubmit的main方法中,创建了class SparkSubmit对象,并调用其doSubmit方法。
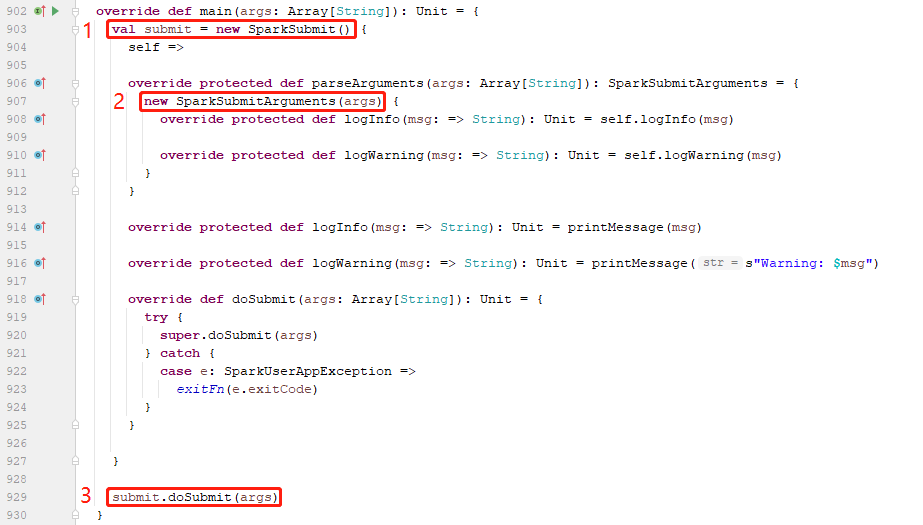
4.2、在class SparkSubmit类中
在class SparkSubmit类的doSubmit方法中,先调用parseArguments方法来返回一个appArgs对象(SparkSubmitArguments类型),而在该对象创建的过程中,就已经将
作业的行为设置为了SUBMIT枚举类型(因为注释说的很明白:没有指定时默认为submit)。

于是在对appArgs.action进行模式匹配后调用了submit(appArgs, uninitLog)方法。
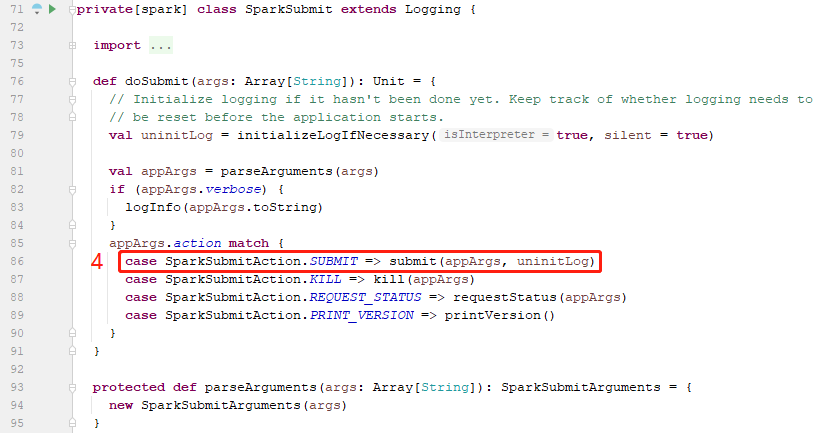
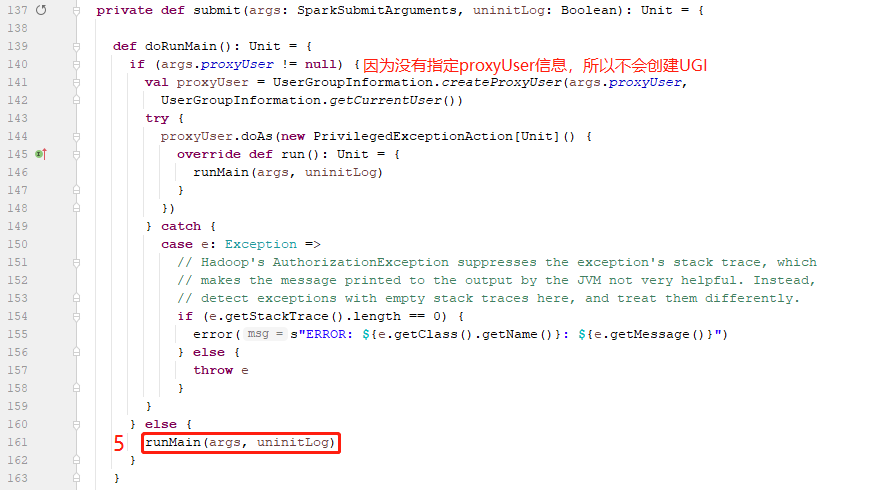
在submit方法中,可以看到,判断是否指定代理用户,如果指定则创建代理用的UGI并通过UGI的run调用runMain方法,否则直接调用runMain方法(我们并未指定代理用户信息,所以是直接调用的runMain方法)。
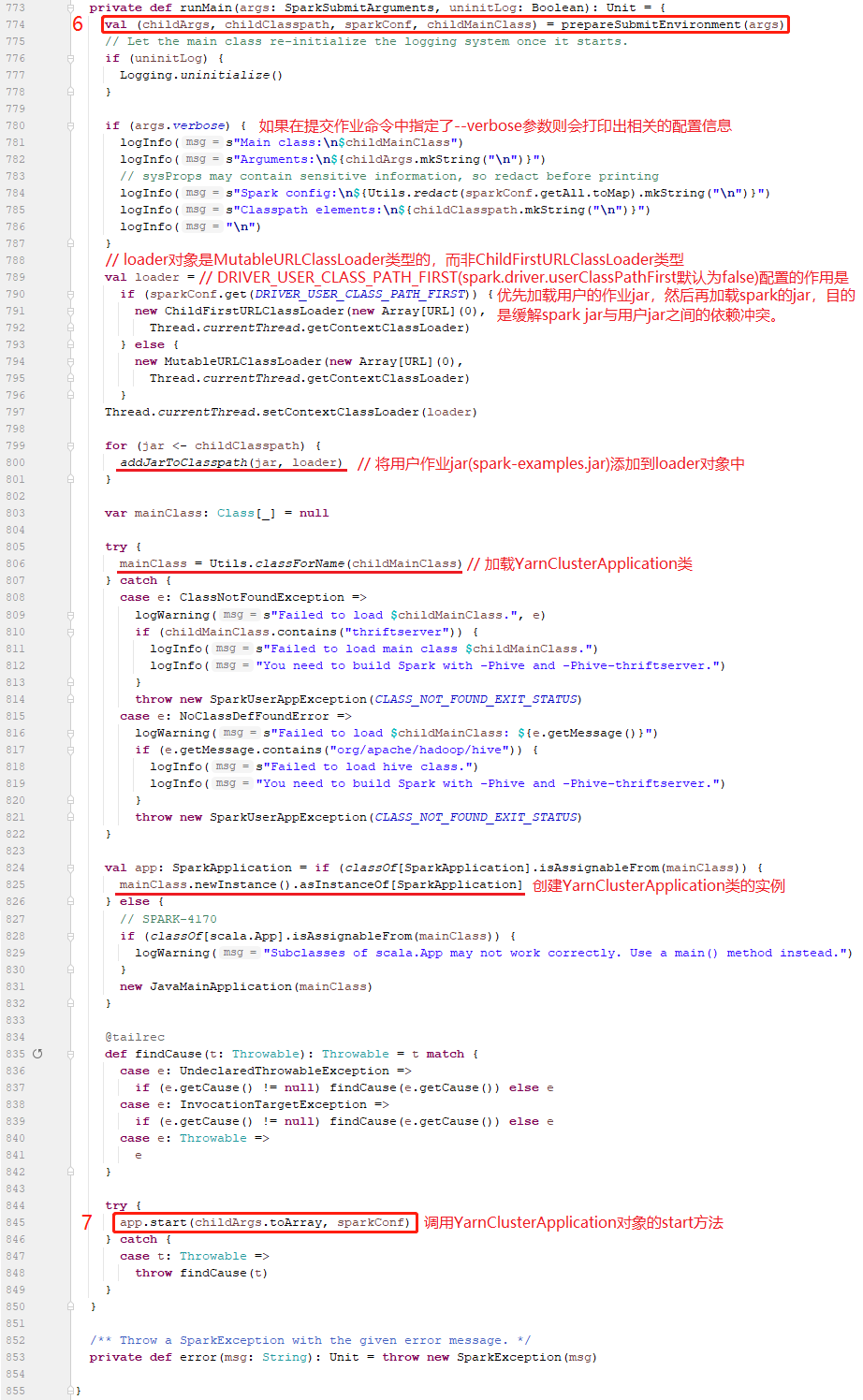
来到runMain方法中,映入眼帘的第一行代码是调用prepareSubmitEnvironment(args)返回了一个四元组对象(childArgs,childClasspath,sparkConf,childMainCllass),这几个变量非常重要,它们的作用如下:
childArgs:实际上是 Seq("--jar","file:/usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.7.jar","--class","org.apache.spark.examples.SparkPi","--arg","10")
childClasspath:实际上是 Seq("file:/usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.7.jar")
sparkConf:实际上是 参数中的指定的配置 + spark-defaults.properties
childMainCllass:实际上是 org.apache.spark.deploy.yarn.YarnClusterApplication(因为参数中的--master是yarn,--deploy-mode是cluster)
5、在YarnClusterApplication类中
到了YarnClusterApplication类中,可以看到它继承自SparkApplication接口,并实现了start方法,当调用YarnClusterApplication.start方法时,其内部实际上只做了两件
事,分别是:
1、创建了Client类(org.apache.spark.deploy.yarn.Client)的实例。
2、调用其run方法。
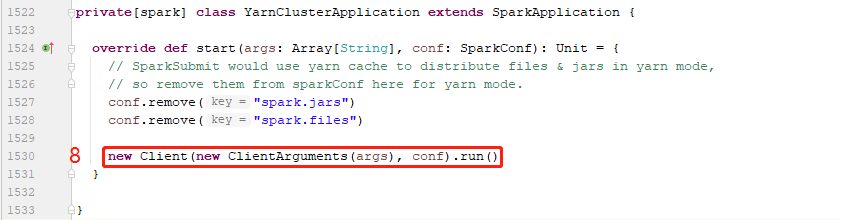
6、在Client类(org.apache.spark.deploy.yarn.Client)中
在Client的内部,初始化了一个YarnClientImpl类型的yarnClient对象,它是Yarn的客户端API(如果想在YARN上运行Application,就必须通过YarnClient来提交),主要用来与Yarn的ResourceManager交互,包括创建作业、申请资源、运行作业、监控作业等。
6.1、实例化Client对象,从sparkConf中初始化yarnClient(以便于后面与YARN的ResourceManager进程交互)
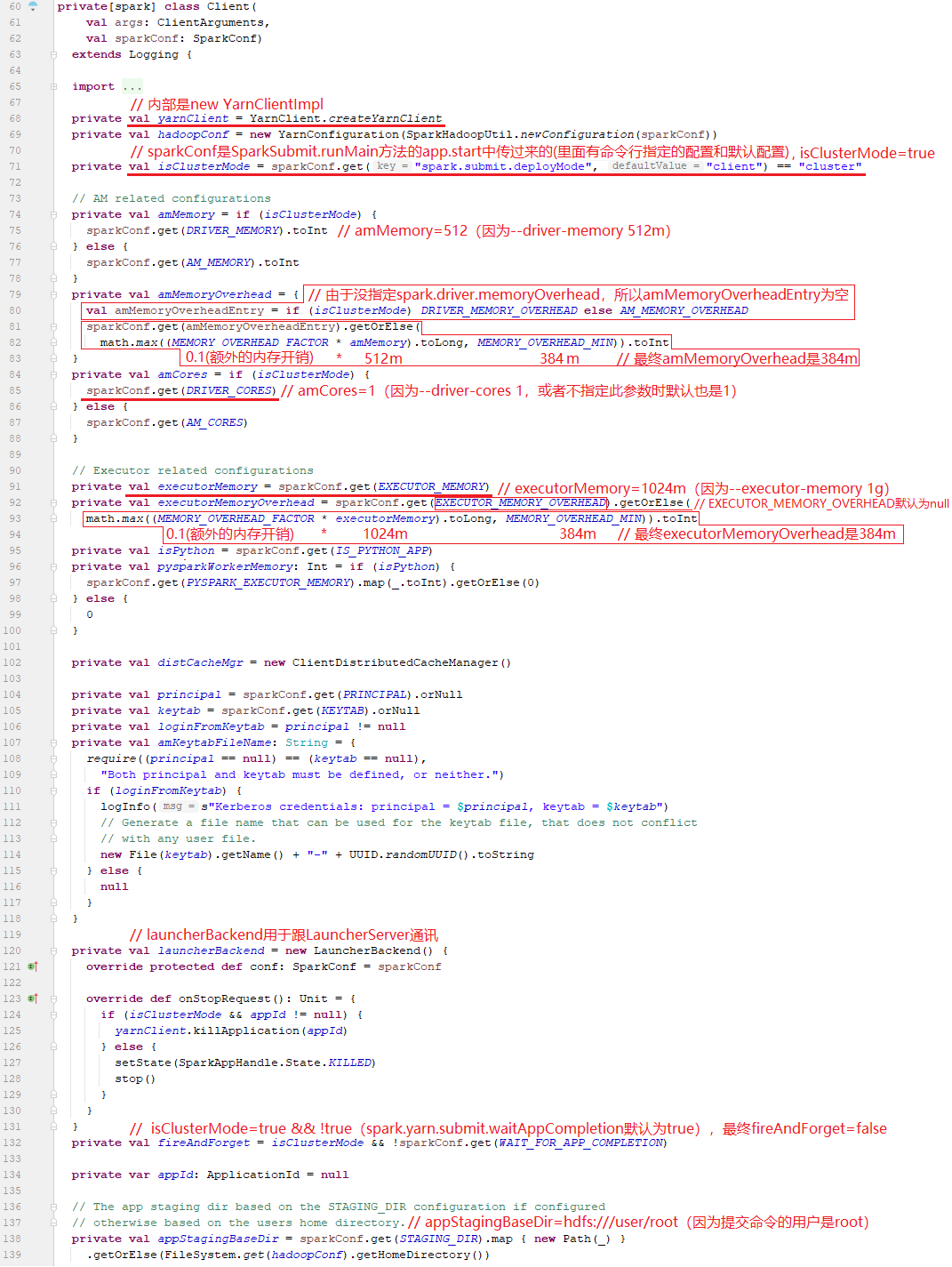
6.2、调用Client对象的run方法
其实,整个run方法的主要作用是提交作业、监控作业,分别对应图中的9和10。

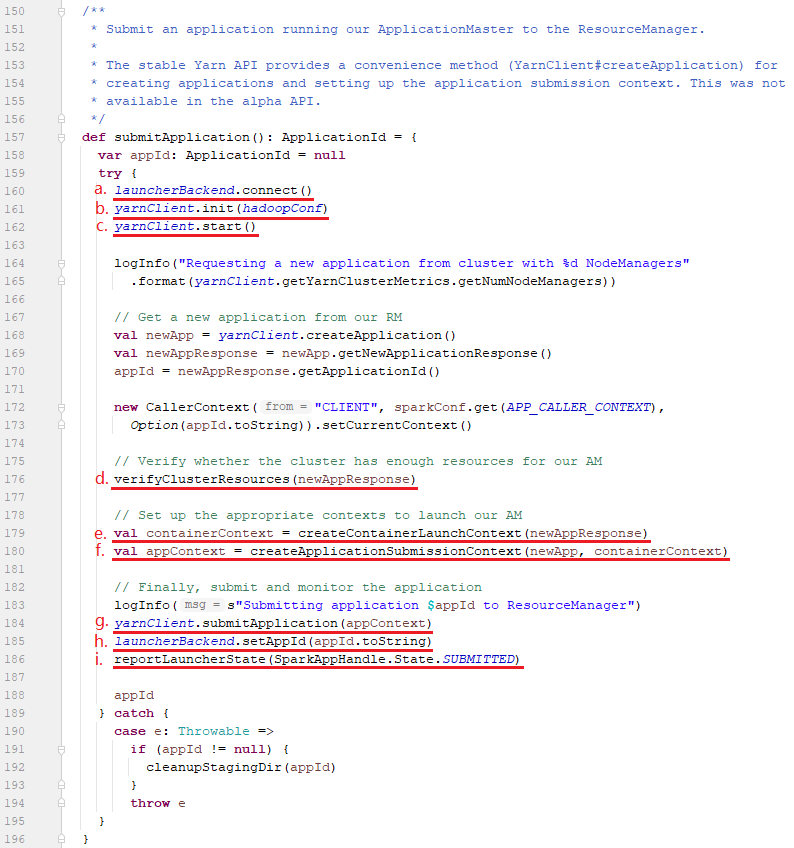
6.3、调用Client对象的submitApplication方法
其实,submitApplication主要是向YARN集群申请一个Container来运行ApplicationMaster,这里面它做的事情主要有几个:
a、通过launcherBackend客户端连接到LauncherServer服务端;
b、初始化yarnClient对象提交作业启动ApplicationMaster所在Container所需的配置;
c、启动yarnClient对象(内部初始化ApplicationClientProtocol类型的rmClient对象),
d、校验Driver内存和Executors内存是否超过YARN集群中Container的最大内存;
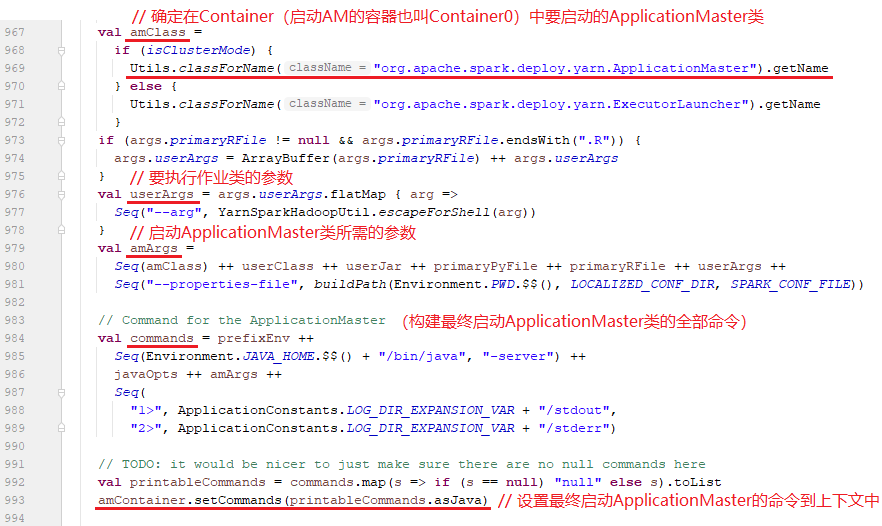
e、设置启动ApplicationMaster所在Container的上下文信息,包括构建amEnv、amArgs参数、javaOpts命令信息,最终保存在该上下文对象(amContainer)中如下:
e1.ApplicationMaster的Env信息 Map(CLASSPATH -> {{PWD}}<CPS>{{PWD}}/__spark_conf__<CPS>{{PWD}}/__spark_libs__/*<CPS>$HADOOP_CONF_DIR<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/*<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/lib/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*<CPS>{{PWD}}/__spark_conf__/__hadoop_conf__, SPARK_YARN_STAGING_DIR -> hdfs://node01:9820/user/root/.sparkStaging/application_1612767624707_0033, SPARK_USER -> root, PYTHONHASHSEED -> 0) e2.ApplicationMaster的Args信息 List(org.apache.spark.deploy.yarn.ApplicationMaster, --class, 'org.apache.spark.examples.SparkPi', --jar, file:/usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.6.jar, --arg, '10', --properties-file, {{PWD}}/__spark_conf__/__spark_conf__.properties) e3.javaOpts信息 ListBuffer(-Xmx512m, -Djava.io.tmpdir={{PWD}}/tmp, -Dspark.yarn.app.container.log.dir=<LOG_DIR>) e4. 最终启动ApplicationMaster的命令 {{JAVA_HOME}}/bin/java -server -Xmx512m -Djava.io.tmpdir={{PWD}}/tmp -Dspark.yarn.app.container.log.dir=<LOG_DIR> org.apache.spark.deploy.yarn.ApplicationMaster --class 'org.apache.spark.examples.SparkPi' --jar file:/usr/bdp/service/spark/examples/jars/spark-examples_2.11-2.4.6.jar --arg '10' --properties-file {{PWD}}/__spark_conf__/__spark_conf__.properties 1> <LOG_DIR>/stdout 2> <LOG_DIR>/stderr
e5. 非常关键的类(后面再讲):
org.apache.spark.deploy.yarn.ApplicationMaster
e6. 将最终启动ApplicationMaster的命令set到amContainer中
f、设置提交ApplicationMaster的上下文信息,如下:
设置作业名称(提交作业命令中的--class后面的值,我们指定的就是org.apache.spark.examples.SparkPi):
org.apache.spark.examples.SparkPi
设置作业所用的YARN队列(提交作业命令中的--queue参数后面的值,默认是default)
default
设置ApplicationMaster所在Container的上下文信息到ApplicationMaster上下文中(在Client类的241行)
appContext.setAMContainerSpec(ContainerContext); 设置作业类型为(Spark在YARN中运行的Application都是SPARK,这是Client类242行中写死的):
SPARK 设置作业标签(取决于spark.yarn.tags参数的值,该参数默认为空):
无 设置作业最大尝试次数(由spark.yarn.maxAppAttempts参数决定,该参数的默认值是yarn.resourcemanager.am.max-attempts,如果设置的话不能大于yarn.resourcemanager.am.max-attempts的值):
0 设置AM的内存和CPU核数(其实AM所需的内存和CPU核数来自于Driver的内存与核数):
AM-内存=896m(提交作业命令中的--driver-memory后面的值,我们指定的是512m,还要加上一个叫做额外内存开销因子的东西,它取决于driver内存的10%是否<384m时,如果小于384m时就默认为384m,否则就取driver内存的10%)
AM-CPU虚拟核数=1(提交作业命令中的--driver-cores后面的值,我们指定的是1) 设置日志聚合信息
无
g、这里就跟Spark没啥关系了,是真正由yarnClient通过submitApplication提交到YARN的ResourceManager来启动作业的ApplicationMaster的地方,逻辑如下:
在Yarn的Client端发生的行为:
i1. yarnClient对象实际上是YarnClientImpl类型;
i2. yarnClient调用了submitApplication方法来提交ApplicationMaster到YARN的Container0中运行;
i3. 内部则是通过rmClient对象(在上面c部分讲过,就是yarnClient.start时初始化的rmClient对象)调用submitApplication方法来提交;
i4. 重点来了,rmClient对象是ApplicationClientProtocol类型的接口(实际上它是该接口的实现类,即ApplicationClientProtocolPBClientImpl类)
i5. rmClient内部持有一个proxy对象(是通过ApplicationClientProtocolPBClientImpl类的构造方法初始化的,实际上是客户端的代理对象,它可以通过RPC协议与来自YARN ResourceManager通信),而它又是通过proxy.submitApplication方法提交;
i6. proxy.submitApplication后,就会通过
在Yarn的Server端发生的行为
i7. ApplicationClientProtocolPBServiceImpl的submitApplication方法提交(其内部有个ClientRMService类型的real对象)
i8. real.submitApplication即ClientRMService.submitApplication提交(通过内部的RMAppManager类型的rmAppManager对象提交);
h、通过launcherBackend客户端内部的launcherConnection对象发送appId信息到LauncherServer服务端;
i、通过launcherBackend客户端内部的launcherConnection对象发送作业状态(SparkAppHandle.State.SUBMITTED枚举)到LauncherServer服务端;
6.3、调用Client对象的monitorApplication方法
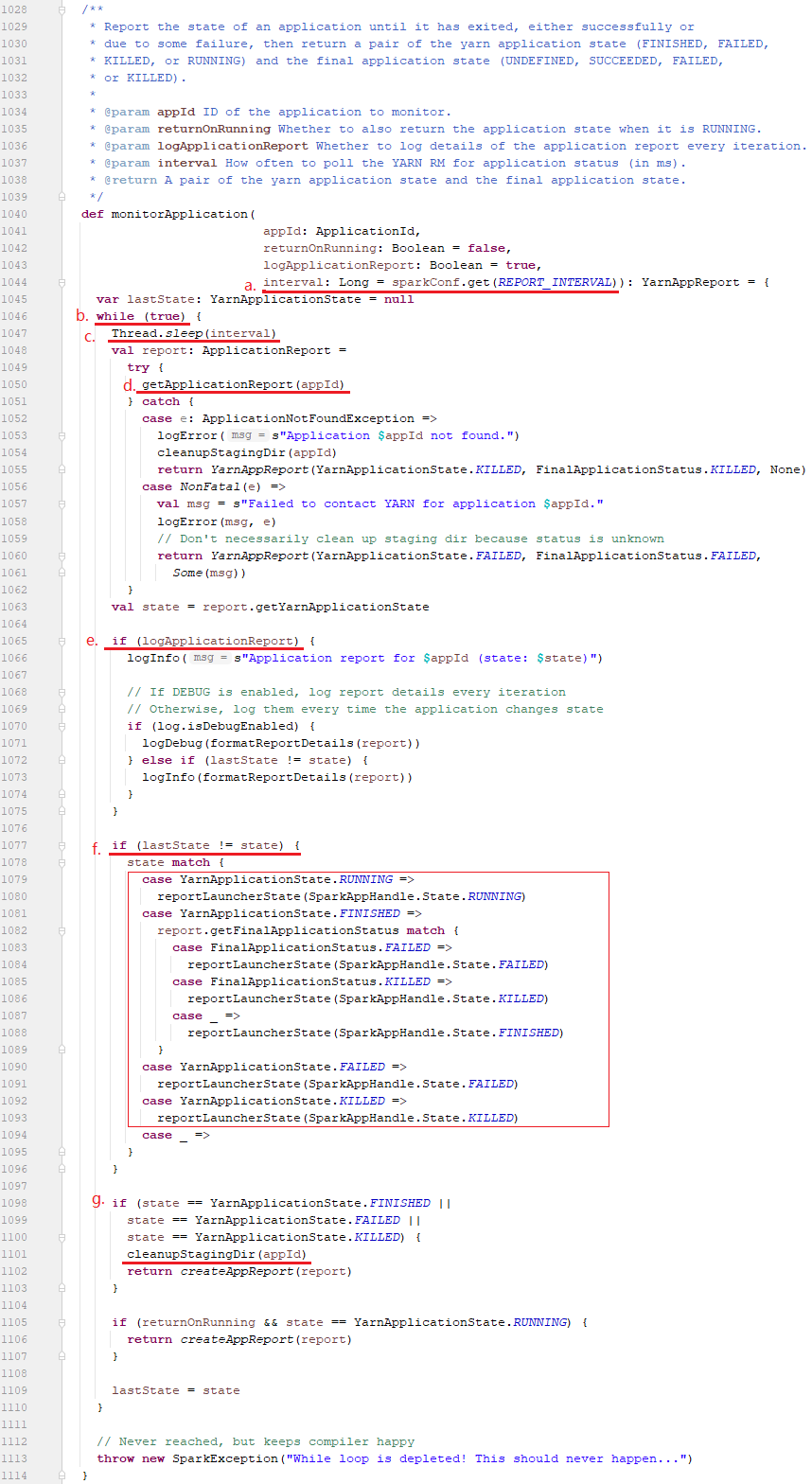
monitorApplication方法的作用是监控作业执行状态,它的执行逻辑如下:
a、从sparkConf中获取spark.yarn.report.interval(默认1秒)作为获取状态更新的间隔时间;
b、它是在一个while循环中,
c、每间隔1秒
d、调用一次getApplicationReport方法获取作业的运行状态;
e、将作业的运行状态并打印在info级别的日志中;
f、如果作业状态发生变化的时候就会调用reportLauncherState方法(内部是launcherBackend发送更新状态请求到LauncherServer端)更新服务端状态;
g、如果作业状态变成FINISHED、FAILED、KILLED时表示作业运行完成,然后调用cleanupStagingDir方法清除作业在执行时生成的数据,至于是否清除数据取决于配置项spark.yarn.preserve.staging.files(该配置默认值为false,表示删除的意思);
二、Yarn RM服务端操作
SparkSubmit类的主要作用就是将作业提交到yarn中,同时接收yarn中运行作业的状态。然后,作业真正运行的地方是在YARN的各个NodeManager节点中,而作业中的第一个Container则是运行ApplicationMaster类(运行AM节点的容器也叫做Container0),他负责运行Spark作业的Driver端,并启动后续任务所需的N个Container来执行真正干活的代码。
7、在ApplicationMaster(object)的伴生类
7.1、main方法
7.2、在run方法
发现其调用了runImpl方法
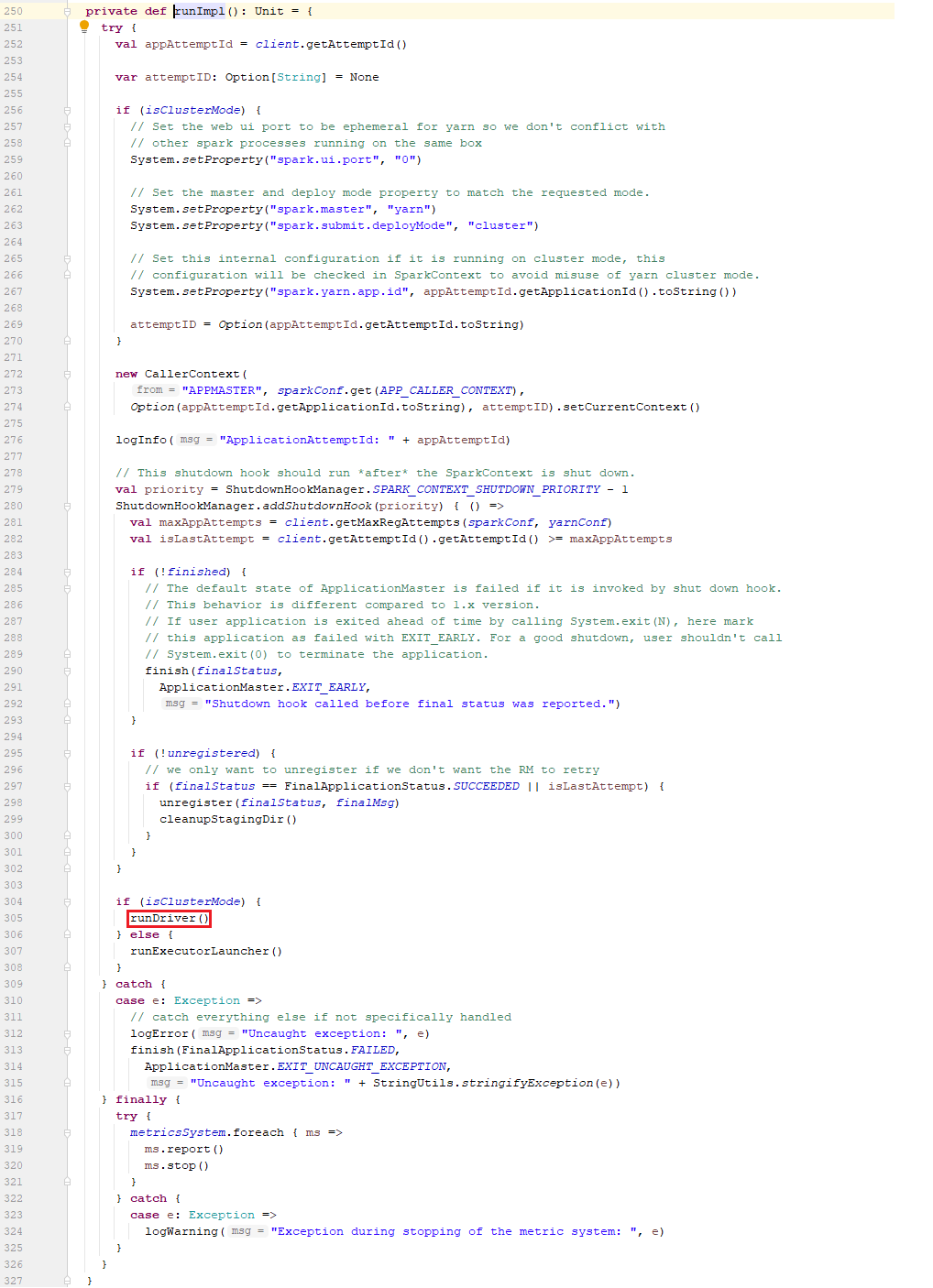
7.3、在runImpl方法
可以看到如果是cluster模式时,设置jre的系统属性:
1、设置spark.ui.port=0到系统属性,即不启动spark ui了。
2、设置spark.master=yarn到系统属性;
3、设置spark.submit.deployMode=cluster到系统属性;
4、设置spark.yarn.app.id=application_clusterTimestamp_id到系统属性;
5、new CallerContext()的作用是将spark app信息写入hdfs/yarn的日志中,如果在hdfs中运行时则写入hdfs-audit.log,如果在yarn上运行时则写入rs.log
6、使用ShutdownHookManager添加钩子,确保在应用程序的SparkContext退出后执行清除操作。
7、最后调用runDriver方法。
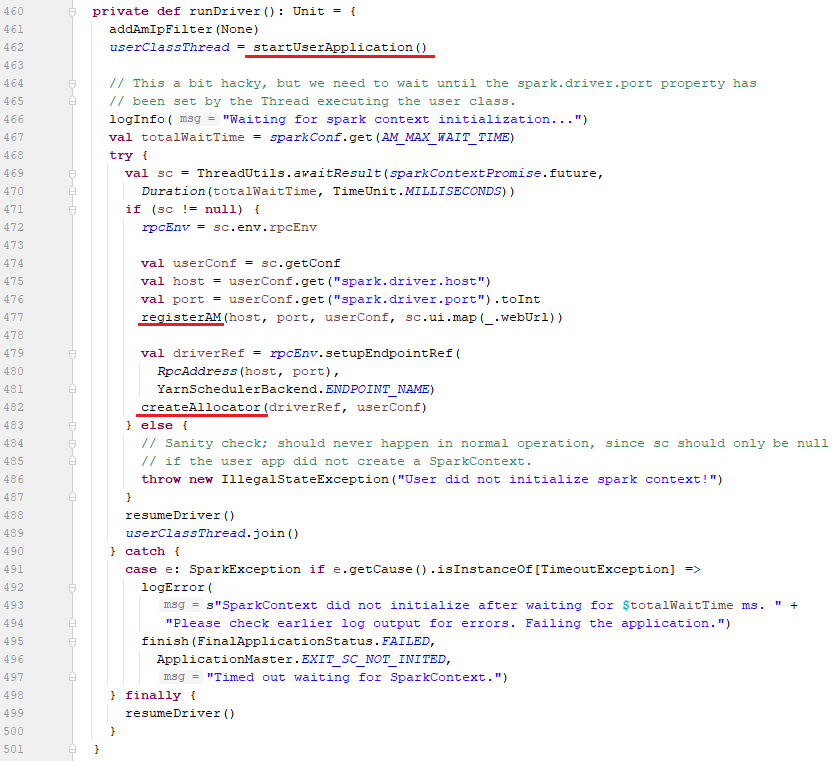
7.4、在runDriver方法中
有3个关键方法,分别是:
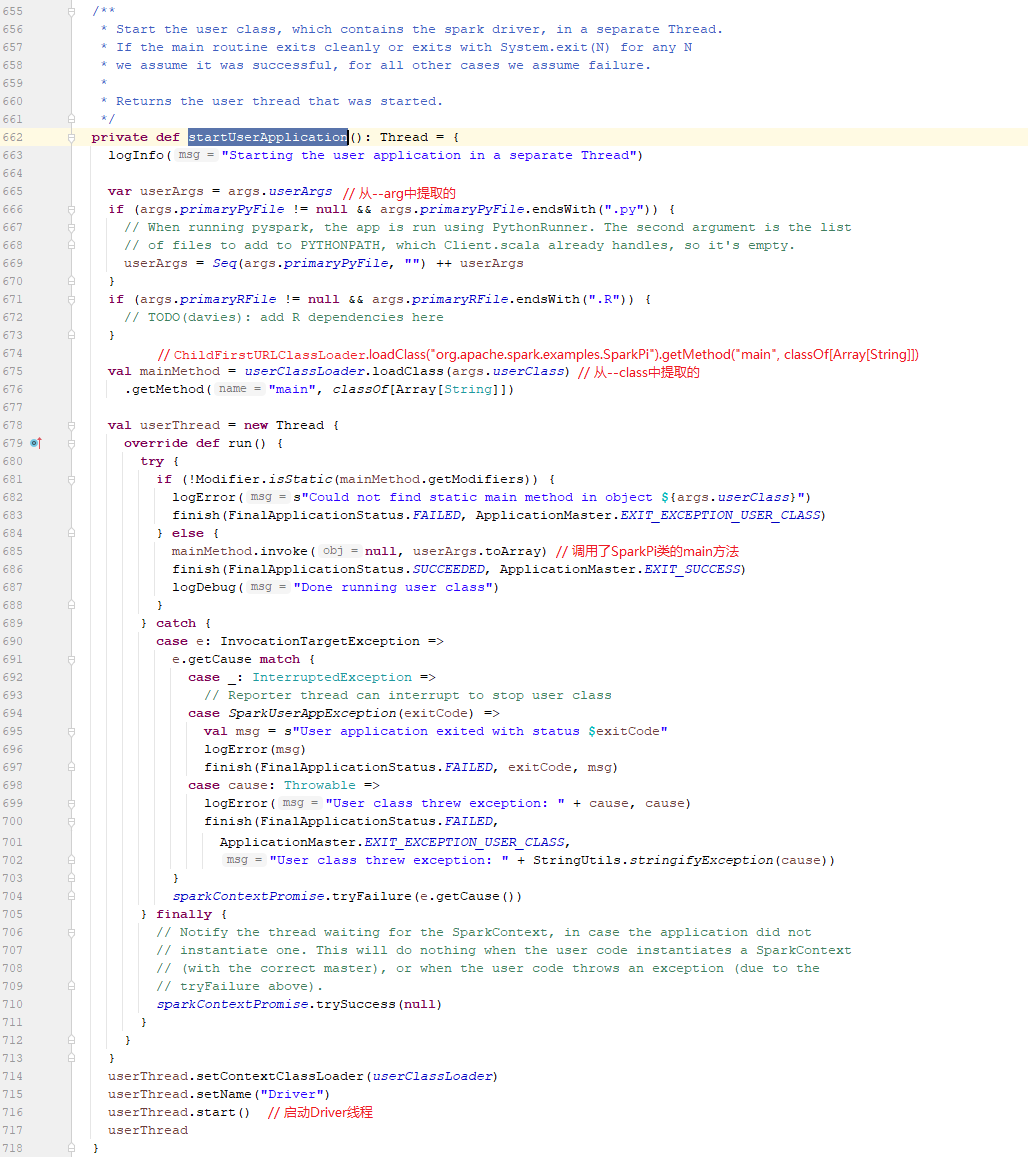
1、startUserApplication方法: 在单独的线程中启动包含火花驱动程序的用户类(就是我们前面命令中的org.apache.spark.examples.SparkPi)。
2、registerAM方法: 向YARN RM注册ApplicationMaster
3、createAllocator方法:创建YarnAllocator来申请Container并运行Executor
7.4.1、在startUserApplication方法中
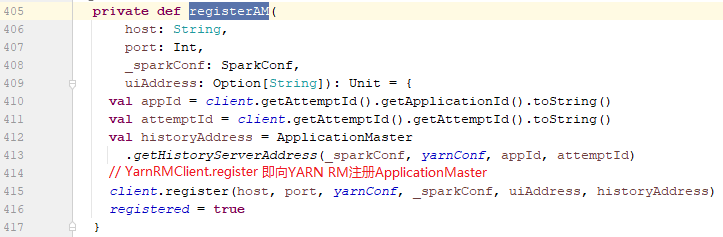
7.4.2、registerAM方法
registerAM方法的作用是将当前作业要运行的ApplicationMaster向YARN RM注册。
client对象是通过doAsUser { new YarnRMClient() }得到的,YarnRMClient类内部维护了YARN的AMRMClient类型的amClient实例,而client.register则是通过内部的amClient实例的registerApplicationMaster方法来向YARN ResourceManager注册ApplicationMaster。
7.4.3、createAllocator方法
