spark-sql基于Clickhouse的DataSourceV2数据源扩展
在使用DSL方式(DataFrame/DataSet)编写时Spark SQL时,会通过SparkSession.read.format(source: String)或SparkSession.write.format(source: String)来指定要读写的数据源,常见的有jdbc、parquet、json、kafka、kudu等,但实际上,这个format(source)的实现是通过DataSourceRegister类(trait)的shortName方法定义的。同时,如果Spark自身未提供相应的数据源时,则需要我们自行实现。
目前引入了Clickhouse作为AD-HOC的数据库管理系统,同时,要对现有的Spark ETL程序进行扩展以支持对Clickhouse进行相应的读写操作,为此,提供了一个基于Clickhouse实现自定义数据源。
首先,Spark的数据源分为DataSourceV1(旧版)和DataSourceV2(新版),两者的区别如下:
| 特性 | DataSourceV1 | DataSourceV2 |
| 引入版本 | Spark-1.3 | Spark-2.3 |
| 上层API的依赖 | 依赖SQLContext | 不依赖 |
| 分区 | 不支持 | 支持 |
| 列裁剪 | 支持 | 支持 |
| 谓词下推 | 不支持 | 支持 |
| Stream Source | 不支持 | 支持 |
| Stream Sink | 不支持 | 支持 |
1、编写基于Clickhouse的DataSourceV2实现
package com.mengyao.spark.datasourcev2.ext.example1 import java.io.Serializable import java.sql.{Connection, Date, PreparedStatement, ResultSet, SQLException, Statement} import java.text.SimpleDateFormat import java.util import java.util.Optional import cn.itcast.logistics.etl.Configure import org.apache.commons.lang3.{StringUtils, SystemUtils} import org.apache.spark.internal.Logging import org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.catalyst.expressions.GenericInternalRow import org.apache.spark.sql.catalyst.util.DateTimeUtils import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.sources.{DataSourceRegister, EqualTo, Filter} import org.apache.spark.sql.sources.v2.reader.{DataSourceReader, InputPartition, InputPartitionReader, SupportsPushDownFilters, SupportsPushDownRequiredColumns} import org.apache.spark.sql.sources.v2.writer.streaming.StreamWriter import org.apache.spark.sql.sources.v2.writer.{DataSourceWriter, DataWriter, DataWriterFactory, WriterCommitMessage} import org.apache.spark.sql.sources.v2.{DataSourceOptions, DataSourceV2, ReadSupport, StreamWriteSupport, WriteSupport} import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.types.{StructType, _} import org.apache.spark.unsafe.types.UTF8String import org.javatuples.Triplet import ru.yandex.clickhouse.domain.ClickHouseDataType import ru.yandex.clickhouse.response.{ClickHouseResultSet, ClickHouseResultSetMetaData} import ru.yandex.clickhouse.settings.ClickHouseProperties import ru.yandex.clickhouse.{ClickHouseConnection, ClickHouseDataSource, ClickHouseStatement} import scala.collection.mutable.ArrayBuffer /** * @ClassName CKTest * @Description 测试ClickHouse的DataSourceV2实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ object CKTest { private val APP_NAME: String = CKTest.getClass.getSimpleName private val master: String = "local[2]" def main(args: Array[String]) { if (SystemUtils.IS_OS_WINDOWS) System.setProperty("hadoop.home.dir", Configure.LOCAL_HADOOP_HOME) val spark = SparkSession.builder() .master(master) .appName(APP_NAME).getOrCreate(); val df = spark.read.format(Configure.SPARK_CLICKHOUSE_FORMAT) .option("driver", Configure.clickhouseDriver) .option("url", Configure.clickhouseUrl) .option("user", Configure.clickhouseUser) .option("password", Configure.clickhousePassword) .option("table", "tbl_address") .option("use_server_time_zone", "false") .option("use_time_zone", "Asia/Shanghai") .option("max_memory_usage", "2000000000") .option("max_bytes_before_external_group_by", "1000000000") .load().coalesce(1) df.show(1000, false) import spark.implicits._ df.where($"id"===328).distinct().coalesce(1).write.format(Configure.SPARK_CLICKHOUSE_FORMAT) .option("driver", Configure.clickhouseDriver) .option("url", Configure.clickhouseUrl) .option("user", Configure.clickhouseUser) .option("password", Configure.clickhousePassword) .option("table", "tbl_address") .option("use_server_time_zone", "false") .option("use_time_zone", "Asia/Shanghai") .option("max_memory_usage", "2000000000") .option("max_bytes_before_external_group_by", "1000000000") .mode(SaveMode.Append) .save(); } } /** * @ClassName ClickHouseDataSourceV2 * @Description 扩展SparkSQL DataSourceV2的ClickHouse数据源实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class ClickHouseDataSourceV2 extends DataSourceV2 with DataSourceRegister with ReadSupport with WriteSupport with StreamWriteSupport { /** 声明ClickHouse数据源的简称,使用方式为spark.read.format("clickhouse")... */ override def shortName(): String = "clickhouse" /** 批处理方式下的数据读取 */ override def createReader(options: DataSourceOptions): DataSourceReader = new CKReader(new CKOptions(options.asMap())) /** 批处理方式下的数据写入 */ override def createWriter(writeUUID: String, schema: StructType, mode: SaveMode, options: DataSourceOptions): Optional[DataSourceWriter] = Optional.of(new CKWriter(writeUUID, schema, mode, null, new CKOptions(options.asMap()))) /** 流处理方式下的数据写入 */ override def createStreamWriter(queryId: String, schema: StructType, mode: OutputMode, options: DataSourceOptions): StreamWriter = new CKWriter(queryId, schema, null, mode, new CKOptions(options.asMap())) } /** * @ClassName CKReader * @Description 基于批处理方式的ClickHouse数据读取(此处只使用1个分区实现) * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKReader(options: CKOptions) extends DataSourceReader { //with SupportsPushDownRequiredColumns with SupportsPushDownFilters { private val customSchema: java.lang.String = options.getCustomSchema private val helper = new CKHelper(options) import collection.JavaConversions._ private val schema = if(StringUtils.isEmpty(customSchema)) { helper.getSparkTableSchema() } else { helper.getSparkTableSchema(new util.LinkedList[String](asJavaCollection(customSchema.split(",")))) } override def readSchema(): StructType = schema override def planInputPartitions(): util.List[InputPartition[InternalRow]] = util.Arrays.asList(new CKInputPartition(schema, options)) } /** * @ClassName CKInputPartition * @Description 基于批处理方式的ClickHouse分区实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKInputPartition(schema: StructType, options: CKOptions) extends InputPartition[InternalRow] { override def createPartitionReader(): InputPartitionReader[InternalRow] = new CKInputPartitionReader(schema, options) } /** * @ClassName CKInputPartitionReader * @Description 基于批处理方式的ClickHouse分区读取数据实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKInputPartitionReader(schema: StructType, options: CKOptions) extends InputPartitionReader[InternalRow] with Logging with Serializable{ val helper = new CKHelper(options) var connection: ClickHouseConnection = null var st: ClickHouseStatement = null var rs: ResultSet = null override def next(): Boolean = { if (null == connection || connection.isClosed && null == st || st.isClosed && null == rs || rs.isClosed){ connection = helper.getConnection st = connection.createStatement() rs = st.executeQuery(helper.getSelectStatement(schema)) println(/**logInfo**/s"初始化ClickHouse连接.") } if(null != rs && !rs.isClosed) rs.next() else false } override def get(): InternalRow = { val fields = schema.fields val length = fields.length val record = new Array[Any](length) for (i <- 0 until length) { val field = fields(i) val name = field.name val dataType = field.dataType try { dataType match { case DataTypes.BooleanType => record(i) = rs.getBoolean(name) case DataTypes.DateType => record(i) = DateTimeUtils.fromJavaDate(rs.getDate(name)) case DataTypes.DoubleType => record(i) = rs.getDouble(name) case DataTypes.FloatType => record(i) = rs.getFloat(name) case DataTypes.IntegerType => record(i) = rs.getInt(name) case DataTypes.LongType => record(i) = rs.getLong(name) case DataTypes.ShortType => record(i) = rs.getShort(name) case DataTypes.StringType => record(i) = UTF8String.fromString(rs.getString(name)) case DataTypes.TimestampType => record(i) = DateTimeUtils.fromJavaTimestamp(rs.getTimestamp(name)) case DataTypes.BinaryType => record(i) = rs.getBytes(name) case DataTypes.NullType => record(i) = StringUtils.EMPTY } } catch { case e: SQLException => logError(e.getStackTrace.mkString("", scala.util.Properties.lineSeparator, scala.util.Properties.lineSeparator)) } } new GenericInternalRow(record) } override def close(): Unit = {helper.closeAll(connection, st, null, rs)} } /** * @ClassName CKWriter * @Description 支持Batch和Stream的数据写实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKWriter(writeUuidOrQueryId: String, schema: StructType, batchMode: SaveMode, streamMode: OutputMode, options: CKOptions) extends StreamWriter { private val isStreamMode:Boolean = if (null!=streamMode&&null==batchMode) true else false override def useCommitCoordinator(): Boolean = true override def onDataWriterCommit(message: WriterCommitMessage): Unit = {} override def createWriterFactory(): DataWriterFactory[InternalRow] = new CKDataWriterFactory(writeUuidOrQueryId, schema, batchMode, streamMode, options) /** Batch writer commit */ override def commit(messages: Array[WriterCommitMessage]): Unit = {} /** Batch writer abort */ override def abort(messages: Array[WriterCommitMessage]): Unit = {} /** Streaming writer commit */ override def commit(epochId: Long, messages: Array[WriterCommitMessage]): Unit = {} /** Streaming writer abort */ override def abort(epochId: Long, messages: Array[WriterCommitMessage]): Unit = {} } /** * @ClassName CKDataWriterFactory * @Description 写数据工厂,用来实例化CKDataWriter * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKDataWriterFactory(writeUUID: String, schema: StructType, batchMode: SaveMode, streamMode: OutputMode, options: CKOptions) extends DataWriterFactory[InternalRow] { override def createDataWriter(partitionId: Int, taskId: Long, epochId: Long): DataWriter[InternalRow] = new CKDataWriter(writeUUID, schema, batchMode, streamMode, options) } /** * @ClassName CKDataWriter * @Description ClickHouse的数据写实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKDataWriter(writeUUID: String, schema: StructType, batchMode: SaveMode, streamMode: OutputMode, options: CKOptions) extends DataWriter[InternalRow] with Logging with Serializable { val helper = new CKHelper(options) val opType = options.getOpTypeField private val sqls = ArrayBuffer[String]() private val autoCreateTable: Boolean = options.autoCreateTable private val init = if (autoCreateTable) { val createSQL = helper.createTable(options.getFullTable, schema) println(/**logInfo**/s"==== 初始化表SQL:$createSQL") helper.executeUpdate(createSQL) } val fields = schema.fields override def commit(): WriterCommitMessage = { helper.executeUpdateBatch(sqls) val batchSQL = sqls.mkString("\n") // logDebug(batchSQL) println(batchSQL) new WriterCommitMessage{override def toString: String = s"批量插入SQL: $batchSQL"} } override def write(record: InternalRow): Unit = { if(StringUtils.isEmpty(opType)) { throw new RuntimeException("未传入opTypeField字段名称,无法确定数据持久化类型!") } var sqlStr: String = helper.getStatement(options.getFullTable, schema, record) logDebug(s"==== 拼接完成的INSERT SQL语句为:$sqlStr") try { if (StringUtils.isEmpty(sqlStr)) { val msg = "==== 拼接INSERT SQL语句失败,因为该语句为NULL或EMPTY!" logError(msg) throw new RuntimeException(msg) } Thread.sleep(options.getInterval()) // 在流处理模式下操作 if (null == batchMode) { if (streamMode == OutputMode.Append) { sqls += sqlStr // val state = helper.executeUpdate(sqlStr) // println(s"==== 在OutputMode.Append模式下执行:$sqlStr\n状态:$state") } else if(streamMode == OutputMode.Complete) {logError("==== 未实现OutputMode.Complete模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} else if(streamMode == OutputMode.Update) {logError("==== 未实现OutputMode.Update模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} else {logError(s"==== 未知模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} // 在批处理模式下操作 } else { if (batchMode == SaveMode.Append) { sqls += sqlStr //val state = helper.executeUpdate(sqlStr) //println(s"==== 在SaveMode.Append模式下执行:$sqlStr\n状态:$state") } else if(batchMode == SaveMode.Overwrite) {logError("==== 未实现SaveMode.Overwrite模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} else if(batchMode == SaveMode.ErrorIfExists) {logError("==== 未实现SaveMode.ErrorIfExists模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} else if(batchMode == SaveMode.Ignore) {logError("==== 未实现SaveMode.Ignore模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} else {logError(s"==== 未知模式下的写入操作,请在CKDataWriter.write方法中添加相关实现!")} } } catch { case e: Exception => logError(e.getMessage) } } override def abort(): Unit = {} } /** * @ClassName CKOptions * @Description 从SparkSQL中DataSourceOptions中提取适用于ClickHouse的参数(spark.[read/write].options参数) * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKOptions(var originalMap: util.Map[String, String]) extends Logging with Serializable { val DRIVER_KEY: String = "driver" val URL_KEY: String = "url" val USER_KEY: String = "user" val PASSWORD_KEY: String = "password" val DATABASE_KEY: String = "database" val TABLE_KEY: String = "table" val AUTO_CREATE_TABLE = "autoCreateTable".toLowerCase val PATH_KEY = "path" val INTERVAL = "interval" val CUSTOM_SCHEMA_KEY: String = "customSchema".toLowerCase val WHERE_KEY: String = "where" val OP_TYPE_FIELD = "opTypeField".toLowerCase val PRIMARY_KEY = "primaryKey".toLowerCase def getValue[T](key: String, `type`: T): T = (if (originalMap.containsKey(key)) originalMap.get(key) else null).asInstanceOf[T] def getDriver: String = getValue(DRIVER_KEY, new String) def getURL: String = getValue(URL_KEY, new String) def getUser: String = getValue(USER_KEY, new String) def getPassword: String = getValue(PASSWORD_KEY, new String) def getDatabase: String = getValue(DATABASE_KEY, new String) def getTable: String = getValue(TABLE_KEY, new String) def autoCreateTable: Boolean = { originalMap.getOrDefault(AUTO_CREATE_TABLE, "false").toLowerCase match { case "true" => true case "false" => false case _ => false } } def getInterval(): Long = {originalMap.getOrDefault(INTERVAL, "200").toLong} def getPath: String = if(StringUtils.isEmpty(getValue(PATH_KEY, new String))) getTable else getValue(PATH_KEY, new String) def getWhere: String = getValue(WHERE_KEY, new String) def getCustomSchema: String = getValue(CUSTOM_SCHEMA_KEY, new String) def getOpTypeField: String = getValue(OP_TYPE_FIELD, new String) def getPrimaryKey: String = getValue(PRIMARY_KEY, new String) def getFullTable: String = { val database = getDatabase val table = getTable if (StringUtils.isEmpty(database) && !StringUtils.isEmpty(table)) table else if (!StringUtils.isEmpty(database) && !StringUtils.isEmpty(table)) database+"."+table else table } def asMap(): util.Map[String, String] = this.originalMap override def toString: String = originalMap.toString } /** * @ClassName CKHelper * @Description ClickHouse的JDBCHelper实现 * @Created by MengYao * @Date 2020/5/17 16:34 * @Version V1.0 */ class CKHelper(options: CKOptions) extends Logging with Serializable { private val opType: String = options.getOpTypeField private val id: String = options.getPrimaryKey private var connection: ClickHouseConnection = getConnection def getConnection: ClickHouseConnection = { val url = options.getURL val ds = new ClickHouseDataSource(url, new ClickHouseProperties()) ds.getConnection(options.getUser, options.getPassword) } def createTable(table: String, schema: StructType): String = { val cols = ArrayBuffer[String]() for (field <- schema.fields) { val dataType = field.dataType val ckColName = field.name if (ckColName!=opType) { var ckColType = getClickhouseSqlType(dataType) if (!StringUtils.isEmpty(ckColType)) { if (ckColType.toLowerCase=="string") {ckColType="Nullable("+ckColType+")"} } cols += ckColName+" "+ ckColType } } s"CREATE TABLE IF NOT EXISTS $table(${cols.mkString(",")},sign Int8,version UInt64) ENGINE=VersionedCollapsingMergeTree(sign, version) ORDER BY $id" } def getSparkTableSchema(customFields: util.LinkedList[String] = null): StructType = { import collection.JavaConversions._ val list: util.LinkedList[Triplet[String, String, String]] = getCKTableSchema(customFields) var fields = ArrayBuffer[StructField]() for(trp <- list) { fields += StructField(trp.getValue0, getSparkSqlType(trp.getValue1)) } StructType(fields) } private def getFieldValue(fieldName: String, schema: StructType, data:InternalRow): Any = { var flag = true var fieldValue:String = null val fields = schema.fields for(i <- 0 until fields.length if flag) { val field = fields(i) if(fieldName==field.name) { fieldValue = field.dataType match { case DataTypes.BooleanType => if (data.isNullAt(i)) "NULL" else s"${data.getBoolean(i)}" case DataTypes.DoubleType => if (data.isNullAt(i)) "NULL" else s"${data.getDouble(i)}" case DataTypes.FloatType => if (data.isNullAt(i)) "NULL" else s"${data.getFloat(i)}" case DataTypes.IntegerType => if (data.isNullAt(i)) "NULL" else s"${data.getInt(i)}" case DataTypes.LongType => if (data.isNullAt(i)) "NULL" else s"${data.getLong(i)}" case DataTypes.ShortType => if (data.isNullAt(i)) "NULL" else s"${data.getShort(i)}" case DataTypes.StringType => if (data.isNullAt(i)) "NULL" else s"${data.getUTF8String(i).toString.trim}" case DataTypes.DateType => if (data.isNullAt(i)) "NULL" else s"'${new SimpleDateFormat("yyyy-MM-dd").format(new Date(data.get(i, DateType).asInstanceOf[Date].getTime / 1000))}'" case DataTypes.TimestampType => if (data.isNullAt(i)) "NULL" else s"${new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(data.getLong(i) / 1000))}" case DataTypes.BinaryType => if (data.isNullAt(i)) "NULL" else s"${data.getBinary(i)}" case DataTypes.NullType => "NULL" } flag = false } } fieldValue } def getStatement(table: String, schema: StructType, record: InternalRow): String = { val opTypeValue: String = getFieldValue(opType, schema, record).toString if (opTypeValue.toLowerCase()=="insert") {getInsertStatement(table, schema, record)} else if (opTypeValue.toLowerCase()=="delete") {getUpdateStatement(table, schema, record)} else if (opTypeValue.toLowerCase()=="update") {getDeleteStatement(table, schema, record)} else {""} } def getSelectStatement(schema: StructType):String = { s"SELECT ${schema.fieldNames.mkString(",")} FROM ${options.getFullTable}" } def getInsertStatement(table:String, schema: StructType, data:InternalRow):String = { val fields = schema.fields val names = ArrayBuffer[String]() val values = ArrayBuffer[String]() // 表示DataFrame中的字段与数据库中的字段相同,拼接SQL语句时使用全量字段拼接 if (data.numFields==fields.length) { } else {// 表示DataFrame中的字段与数据库中的字段不同,拼接SQL时需要仅拼接DataFrame中有的字段到SQL中 } for(i <- 0 until fields.length) { val field = fields(i) val fieldType = field.dataType val fieldName = field.name if (fieldName!=opType) { val fieldValue = fieldType match { case DataTypes.BooleanType => if(data.isNullAt(i)) "NULL" else s"${data.getBoolean(i)}" case DataTypes.DoubleType => if(data.isNullAt(i)) "NULL" else s"${data.getDouble(i)}" case DataTypes.FloatType => if(data.isNullAt(i)) "NULL" else s"${data.getFloat(i)}" case DataTypes.IntegerType => if(data.isNullAt(i)) "NULL" else s"${data.getInt(i)}" case DataTypes.LongType => if(data.isNullAt(i)) "NULL" else s"${data.getLong(i)}" case DataTypes.ShortType => if(data.isNullAt(i)) "NULL" else s"${data.getShort(i)}" case DataTypes.StringType => if(data.isNullAt(i)) "NULL" else s"'${data.getUTF8String(i).toString.trim}'" case DataTypes.DateType => if(data.isNullAt(i)) "NULL" else s"'${new SimpleDateFormat("yyyy-MM-dd").format(new Date(data.get(i, DateType).asInstanceOf[Date].getTime/1000))}'" case DataTypes.TimestampType => if(data.isNullAt(i)) "NULL" else s"'${new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(data.getLong(i)/1000))}'" case DataTypes.BinaryType => if(data.isNullAt(i)) "NULL" else s"${data.getBinary(i)}" case DataTypes.NullType => "NULL" } names += fieldName values += fieldValue } } if (names.length > 0 && values.length > 0) { names += ("sign","version") values += ("1", System.currentTimeMillis().toString) } s"INSERT INTO $table(${names.mkString(",")}) VALUES(${values.mkString(",")})" } def getDeleteStatement(table:String, schema: StructType, data:InternalRow):String = { val fields = schema.fields val primaryKeyFields = if(options.getPrimaryKey.isEmpty) {fields.filter(field => field.name=="id")} else {fields.filter(field => field.name==options.getPrimaryKey)} if (primaryKeyFields.length>0) { val primaryKeyField = primaryKeyFields(0) val primaryKeyValue = getFieldValue(primaryKeyField.name, schema, data) s"ALTER TABLE $table DELETE WHERE ${primaryKeyField.name} = $primaryKeyValue" } else { logError("==== 找不到主键,无法生成删除SQL!") "" } } def getUpdateStatement(table:String, schema: StructType, data:InternalRow):String = { val fields = schema.fields val primaryKeyFields = if(options.getPrimaryKey.isEmpty) {fields.filter(field => field.name=="id")} else {fields.filter(field => field.name==options.getPrimaryKey)} if (primaryKeyFields.length>0) { val primaryKeyField = primaryKeyFields(0) val primaryKeyValue = getFieldValue(primaryKeyField.name, schema, data) val noPrimaryKeyFields = fields.filter(field=>field.name!=primaryKeyField.name) var sets = ArrayBuffer[String]() for(i <- 0 until noPrimaryKeyFields.length) { val noPrimaryKeyField = noPrimaryKeyFields(i) val set = noPrimaryKeyField.name+"="+getFieldValue(noPrimaryKeyField.name, schema, data).toString sets += set } sets.remove(sets.length-1) s"ALTER TABLE $table UPDATE ${sets.mkString(" AND ")} WHERE ${primaryKeyField.name}=$primaryKeyValue" } else { logError("==== 找不到主键,无法生成修改SQL!") "" } } def getCKTableSchema(customFields: util.LinkedList[String] = null): util.LinkedList[Triplet[String, String, String]] = { val fields = new util.LinkedList[Triplet[String, String, String]] var connection: ClickHouseConnection = null var st: ClickHouseStatement = null var rs: ClickHouseResultSet = null var metaData: ClickHouseResultSetMetaData = null try { connection = getConnection st = connection.createStatement val sql = s"SELECT * FROM ${options.getFullTable} WHERE 1=0" rs = st.executeQuery(sql).asInstanceOf[ClickHouseResultSet] metaData = rs.getMetaData.asInstanceOf[ClickHouseResultSetMetaData] val columnCount = metaData.getColumnCount for (i <- 1 to columnCount) { val columnName = metaData.getColumnName(i) val sqlTypeName = metaData.getColumnTypeName(i) val javaTypeName = ClickHouseDataType.fromTypeString(sqlTypeName).getJavaClass.getSimpleName if (null != customFields && customFields.size > 0) { if(fields.contains(columnName)) fields.add(new Triplet(columnName, sqlTypeName, javaTypeName)) } else { fields.add(new Triplet(columnName, sqlTypeName, javaTypeName)) } } } catch { case e: Exception => e.printStackTrace() } finally { closeAll(connection, st, null, rs) } fields } def executeUpdateBatch(sqls: ArrayBuffer[String]): Unit = { // 拼接Batch SQL:VALUES()()... val batchSQL = new StringBuilder() for(i <- 0 until sqls.length) { val line = sqls(i) var offset: Int = 0 if (!StringUtils.isEmpty(line) && line.contains("VALUES")) { val offset = line.indexOf("VALUES") if(i==0) { val prefix = line.substring(0, offset+6) batchSQL.append(prefix) } val suffix = line.substring(offset+6) batchSQL.append(suffix) } } var st: ClickHouseStatement = null; try { if(null==connection||connection.isClosed) {connection = getConnection} st = connection createStatement() st.executeUpdate(batchSQL.toString()) } catch { case e: Exception => logError(s"执行异常:$sqls\n${e.getMessage}") } finally { //closeAll(connection, st) } } def executeUpdate(sql: String): Int = { var state = 0; var st: ClickHouseStatement = null; try { if(null==connection||connection.isClosed) {connection = getConnection} st = connection createStatement() state = st.executeUpdate(sql) } catch { case e: Exception => logError(s"执行异常:$sql\n${e.getMessage}") } finally { //closeAll(connection, st) } state } def close(connection: Connection): Unit = closeAll(connection) def close(st: Statement): Unit = closeAll(null, st, null, null) def close(ps: PreparedStatement): Unit = closeAll(null, null, ps, null) def close(rs: ResultSet): Unit = closeAll(null, null, null, rs) def closeAll(connection: Connection=null, st: Statement=null, ps: PreparedStatement=null, rs: ResultSet=null): Unit = { try { if (rs != null && !rs.isClosed) rs.close() if (ps != null && !ps.isClosed) ps.close() if (st != null && !st.isClosed) st.close() if (connection != null && !connection.isClosed) connection.close() } catch { case e: Exception => e.printStackTrace() } } /** * IntervalYear (Types.INTEGER, Integer.class, true, 19, 0), * IntervalQuarter (Types.INTEGER, Integer.class, true, 19, 0), * IntervalMonth (Types.INTEGER, Integer.class, true, 19, 0), * IntervalWeek (Types.INTEGER, Integer.class, true, 19, 0), * IntervalDay (Types.INTEGER, Integer.class, true, 19, 0), * IntervalHour (Types.INTEGER, Integer.class, true, 19, 0), * IntervalMinute (Types.INTEGER, Integer.class, true, 19, 0), * IntervalSecond (Types.INTEGER, Integer.class, true, 19, 0), * UInt64 (Types.BIGINT, BigInteger.class, false, 19, 0), * UInt32 (Types.INTEGER, Long.class, false, 10, 0), * UInt16 (Types.SMALLINT, Integer.class, false, 5, 0), * UInt8 (Types.TINYINT, Integer.class, false, 3, 0), * Int64 (Types.BIGINT, Long.class, true, 20, 0, "BIGINT"), * Int32 (Types.INTEGER, Integer.class, true, 11, 0, "INTEGER", "INT"), * Int16 (Types.SMALLINT, Integer.class, true, 6, 0, "SMALLINT"), * Int8 (Types.TINYINT, Integer.class, true, 4, 0, "TINYINT"), * Date (Types.DATE, Date.class, false, 10, 0), * DateTime (Types.TIMESTAMP, Timestamp.class, false, 19, 0, "TIMESTAMP"), * Enum8 (Types.VARCHAR, String.class, false, 0, 0), * Enum16 (Types.VARCHAR, String.class, false, 0, 0), * Float32 (Types.FLOAT, Float.class, true, 8, 8, "FLOAT"), * Float64 (Types.DOUBLE, Double.class, true, 17, 17, "DOUBLE"), * Decimal32 (Types.DECIMAL, BigDecimal.class, true, 9, 9), * Decimal64 (Types.DECIMAL, BigDecimal.class, true, 18, 18), * Decimal128 (Types.DECIMAL, BigDecimal.class, true, 38, 38), * Decimal (Types.DECIMAL, BigDecimal.class, true, 0, 0, "DEC"), * UUID (Types.OTHER, UUID.class, false, 36, 0), * String (Types.VARCHAR, String.class, false, 0, 0, "LONGBLOB", "MEDIUMBLOB", "TINYBLOB", "MEDIUMTEXT", "CHAR", "VARCHAR", "TEXT", "TINYTEXT", "LONGTEXT", "BLOB"), * FixedString (Types.CHAR, String.class, false, -1, 0, "BINARY"), * Nothing (Types.NULL, Object.class, false, 0, 0), * Nested (Types.STRUCT, String.class, false, 0, 0), * Tuple (Types.OTHER, String.class, false, 0, 0), * Array (Types.ARRAY, Array.class, false, 0, 0), * AggregateFunction (Types.OTHER, String.class, false, 0, 0), * Unknown (Types.OTHER, String.class, false, 0, 0); * * @param clickhouseDataType * @return */ private def getSparkSqlType(clickhouseDataType: String) = clickhouseDataType match { case "IntervalYear" => DataTypes.IntegerType case "IntervalQuarter" => DataTypes.IntegerType case "IntervalMonth" => DataTypes.IntegerType case "IntervalWeek" => DataTypes.IntegerType case "IntervalDay" => DataTypes.IntegerType case "IntervalHour" => DataTypes.IntegerType case "IntervalMinute" => DataTypes.IntegerType case "IntervalSecond" => DataTypes.IntegerType case "UInt64" => DataTypes.LongType //DataTypes.IntegerType; case "UInt32" => DataTypes.LongType case "UInt16" => DataTypes.IntegerType case "UInt8" => DataTypes.IntegerType case "Int64" => DataTypes.LongType case "Int32" => DataTypes.IntegerType case "Int16" => DataTypes.IntegerType case "Int8" => DataTypes.IntegerType case "Date" => DataTypes.DateType case "DateTime" => DataTypes.TimestampType case "Enum8" => DataTypes.StringType case "Enum16" => DataTypes.StringType case "Float32" => DataTypes.FloatType case "Float64" => DataTypes.DoubleType case "Decimal32" => DataTypes.createDecimalType case "Decimal64" => DataTypes.createDecimalType case "Decimal128" => DataTypes.createDecimalType case "Decimal" => DataTypes.createDecimalType case "UUID" => DataTypes.StringType case "String" => DataTypes.StringType case "FixedString" => DataTypes.StringType case "Nothing" => DataTypes.NullType case "Nested" => DataTypes.StringType case "Tuple" => DataTypes.StringType case "Array" => DataTypes.StringType case "AggregateFunction" => DataTypes.StringType case "Unknown" => DataTypes.StringType case _ => DataTypes.NullType } private def getClickhouseSqlType(sparkDataType: DataType) = sparkDataType match { case DataTypes.ByteType => "Int8" case DataTypes.ShortType => "Int16" case DataTypes.IntegerType => "Int32" case DataTypes.FloatType => "Float32" case DataTypes.DoubleType => "Float64" case DataTypes.LongType => "Int64" case DataTypes.DateType => "DateTime" case DataTypes.TimestampType => "DateTime" case DataTypes.StringType => "String" case DataTypes.NullType => "String" } }
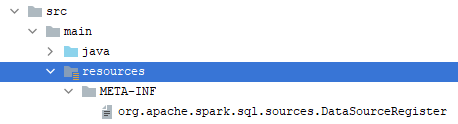
2、使用SPI机制加载自定义的数据源实现类
SPI(Service Provider Interface)是JDK内置的服务发现机制,主要由工具类java.util.ServiceLoader(位于rt.jar中)提供相应的支持。ServiceLoader最常见的例子是数据库的Driver类(MySQL、Oracle等),它会去加载位于jar包中META-INF/services/路径下的全限定类名文件(此文件必须是UTF8编码,允许使用#作为注释),因为该文件包含了提供服务的全限定类全名。