Spark核心工作机制
1.1、RDD的分区
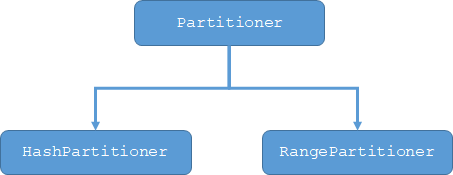
Spark对RDD提供了两种分区方式,分别是基于哈希(HashPartitioner)和基于范围排序的(RangePartitioner)的分区器,实现类来自https://github.com/apache/spark/blob/v2.4.7/core/src/main/scala/org/apache/spark/Partitioner.scala
基于Hash的分区器(HashPartitioner):
定义:使用Java的Object.hashCode方法对传入的任意类型的Key进行非负数取模。
1、如果传入的Key是null时则返回0;
2、如果传入的Key是数组时可能会产生不正确的数据分区(因为Java调用数组.hashCode方法返回的是数组对象的哈希值而非数组内容的哈希值),
可能还会报错(不用担心,因为调用PiarRDDFunctions的groupByKey、reduceByKey、combineByKey、aggregateByKey时,其内部会调用combineByKeyWithClassTag方法,其中有对keyClass.isArray的校验,也就是说当key是Array类型时就报错了,根本就无法将Array类型的key传递进来);
基于范围排序的(RangePartitioner):
定义:使用
1.2、RDD的依赖关系
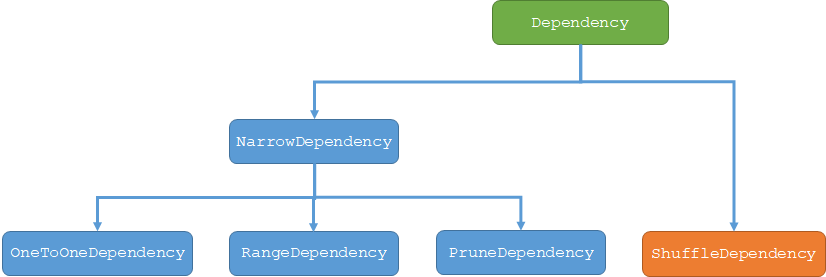
Spark对父子RDD之间的依赖关系定义有两类,即窄依赖(NarrowDependency)和宽依赖(ShuffleDependency),其实现类来自:https://github.com/apache/spark/blob/v2.4.7/core/src/main/scala/org/apache/spark/Dependency.scala
窄依赖(NarrowDependency,抽象类)
实现:3种,分别如下
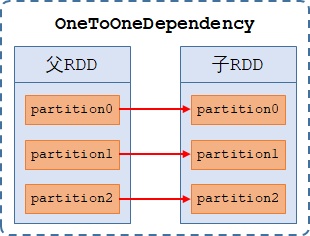
1、一对一依赖(OneToOneDependency):【1-to-1的依赖】,指父RDD和子RDD分区之间是一对一的依赖关系且父RDD与子RDD的分区数量相同,如map、filter算子。
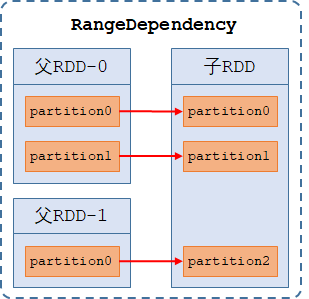
2、范围依赖(RangeDependency):【n-to-1的依赖】,指父RDD和子RDD之间属于某个范围的依赖关系(当2个父RDD拼接成一个子RDD时,子RDD的分区分别依赖于父RDD0的所有分区、父RDD1的所有分区)且子RDD的分区数量=所有父RDD的分区数之和,仅被UnionRDD使用,如union算子。
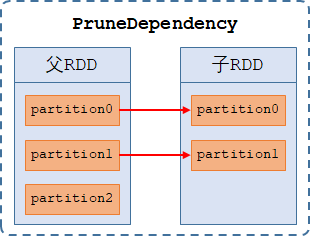
3、剪枝依赖(PruneDependency):【1-to-部分 的依赖】,指子RDD仅依赖部分父RDD的分区,是一种数据过滤优化,仅被PartitionPruningRDD使用。
宽依赖(ShuffleDependency):
实现:1种,如下
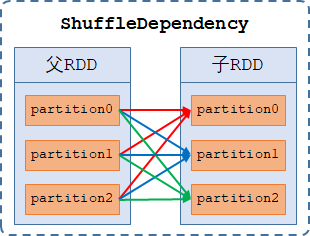
1、Shuffle依赖(ShuffleDependency):【n-to-n的依赖】,指子RDD的每一个分区都依赖父RDD的多个分区或全部分区,仅K-V类型的RDD才会使用宽依赖,如reduce、groupBy、reduceByKey等算子。
1.3、RDD的Stage划分
插入一段测试的WordCount代码
======================================== Java版 ========================================
package com.mengyao.spark.guide;
import org.apache.commons.lang3.StringUtils; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.storage.StorageLevel; import scala.Tuple2; import java.util.Arrays; /** * Spark WordCount应用(Java版) * @ClassName WordCountApp * @Description * @Created by: MengYao * @Date: 2020-09-13 15:49:47 * @Version V1.0 */ public class WordCountApp { private static final String APP_NAME = WordCountApp.class.getSimpleName(); public static void main(String[] args) throws Exception { // 初始化SparkConf SparkConf conf = new SparkConf() .setAppName(APP_NAME); // 初始化SparkContext JavaSparkContext jsc = new JavaSparkContext(conf); // 禁用日志 jsc.setLogLevel("OFF"); // 从输入文件中进行单词计数并输出到文件中 jsc.textFile(args[0]) .persist(StorageLevel.NONE()) .flatMap(line -> Arrays.asList(line.split(",")).iterator()) .mapToPair(word -> new Tuple2<>(word, 1L)) .filter(cs -> StringUtils.isNotEmpty(cs._1)) .reduceByKey(Long::sum) .saveAsTextFile(args[1]); // 停止SparkContext jsc.stop(); } }
======================================== Scala版 ========================================
package com.mengyao.spark.guide
import org.apache.commons.lang3.StringUtils
import org.apache.spark.{SparkConf, SparkContext}
/** * Spark WordCount应用(Scala版) * @ClassName WordCountApp * @Description * @Created by: MengYao * @Date: 2020-09-13 15:49:01 * @Version V1.0 */ object WordCountApp_ { private val APP_NAME: String = WordCountApp_.getClass.getSimpleName def main(args: Array[String]): Unit = { // 初始化SparkConf val conf = new SparkConf() .setAppName(APP_NAME) // 初始化SparkContext val sc = new SparkContext(conf) // 禁用日志 sc.setLogLevel("OFF") // 从输入文件中进行单词计数并输出到文件中 sc.textFile(args(0)) .flatMap(_.split(",")) .map(word => (word, 1L)) .filter(cs => StringUtils.isNotEmpty(cs._1)) .reduceByKey(_+_) .saveAsTextFile(args(1)) // 停止SparkContext sc.stop() } }
